![[Compaq]](../../images/hp.gif)
![[Go to the documentation home page]](../../images/buttons/hp_bn_site_home.gif)
![[How to order documentation]](../../images/buttons/hp_bn_order_docs.gif)
![[Help on this site]](../../images/buttons/hp_bn_site_help.gif)
![[How to contact us]](../../images/buttons/hp_bn_comments.gif)
![[OpenVMS documentation]](../../images/hp_ovmsdoc_sec_head.gif)
| Document revision date: 24 June 2002 | |
|
|
|
|
|
|
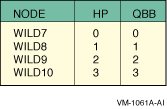
SCM_E0> power off -all SCM_E0> set hp_count 4 SCM_E0> set hp_qbb_mask0 1 SCM_E0> set hp_qbb_mask1 2 SCM_E0> set hp_qbb_mask2 4 SCM_E0> set hp_qbb_mask3 8 SCM_E0> set hp_qbb_mask4 0 SCM_E0> set hp_qbb_mask5 0 SCM_E0> set hp_qbb_mask6 0 SCM_E0> set hp_qbb_mask7 0 SCM_E0> power on -all
SCM_E0> power off -all SCM_E0> set hp_count 4 SCM_E0> set hp_qbb_mask0 1 SCM_E0> set hp_qbb_mask1 2 SCM_E0> set hp_qbb_mask2 4 SCM_E0> set hp_qbb_mask3 8 SCM_E0> set hp_qbb_mask4 0 SCM_E0> set hp_qbb_mask5 0 SCM_E0> set hp_qbb_mask6 0 SCM_E0> set hp_qbb_mask7 0 SCM_E0> power on -partition 0 SCM_E0> power on -partition 1 SCM_E0> power on -partition 2 SCM_E0> power on -partition 3
P00>>>show bootdef_dev bootdef_dev dkb0.0.0.3.0 P00>>>show boot_osflags boot_osflags 0,0 P00>>>show os_type os_type OpenVMS
P00>>>show bootdef_dev bootdef_dev dkb0.0.0.3.0 P00>>>show boot_osflags boot_osflags 1,0 P00>>>show os_type os_type OpenVMS
P00>>>show bootdef_dev bootdef_dev dkb0.0.0.3.0 P00>>>show boot_osflags boot_osflags 2,1 P00>>>show os_type os_type OpenVMS
P00>>>show bootdef_dev bootdef_dev dka0.0.0.1.16 P00>>>show boot_osflags boot_osflags A P00>>>show os_type os_type UNIX
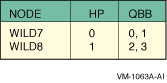
SCM_E0> power off -all SCM_E0> set hp_count 2 SCM_E0> set hp_qbb_mask0 3 SCM_E0> set hp_qbb_mask1 c SCM_E0> set hp_qbb_mask2 0 SCM_E0> set hp_qbb_mask3 0 SCM_E0> set hp_qbb_mask4 0 SCM_E0> set hp_qbb_mask5 0 SCM_E0> set hp_qbb_mask6 0 SCM_E0> set hp_qbb_mask7 0 SCM_E0> power on -all
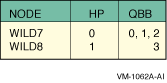
SCM_E0> power off -all SCM_E0> set hp_count 2 SCM_E0> set hp_qbb_mask0 7 SCM_E0> set hp_qbb_mask1 8 SCM_E0> set hp_qbb_mask2 0 SCM_E0> set hp_qbb_mask3 0 SCM_E0> set hp_qbb_mask4 0 SCM_E0> set hp_qbb_mask5 0 SCM_E0> set hp_qbb_mask6 0 SCM_E0> set hp_qbb_mask7 0 SCM_E0> power on -all
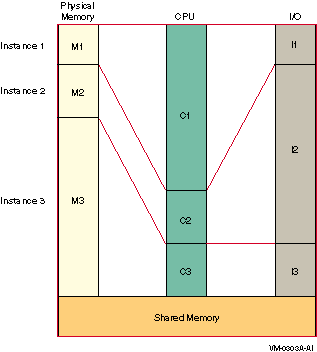
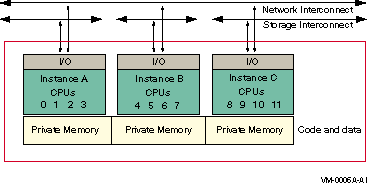
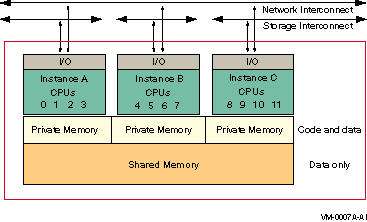
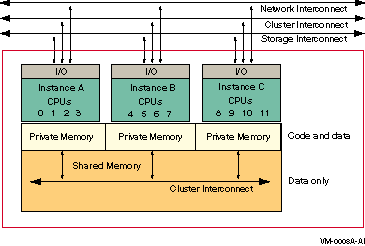
Will this system be a member of an OpenVMS cluster? (Yes/No)
Will this system be an instance in an OpenVMS Galaxy? (Yes/No)
For compatibility with an OpenVMS Galaxy, any systems in the OpenVMS
cluster which are running versions of OpenVMS prior to V7.1-2 must
have a remedial kit installed. The appropriate kit from the following
list must be installed on all system disks used by these systems.
(Later versions of these remedial kits may be used if available.)
Alpha V7.1 and V7.1-1xx ALPSYSB02_071
Alpha V6.2 and V6.2-1xx ALPSYSB02_062
VAX V7.1 VAXSYSB01_071
VAX V6.2 VAXSYSB01_062
PKA0 (embedded SCSI for CDROM) PKB0 (UltraSCSI controller KZPxxx) PKC0 (UltraSCSI controller)
Instance 0 PKA0 (UltraSCSI controller) Instance 1 PKA0 (embedded SCSI for CDROM) PKB0 (UltraSCSI controller)
$ LIBRARY/EXTRACT=STARLET SYS$LIBRARY:SYS$STARLET_C.TLB/OUTPUT=FILENAME
System
Service |
Description |
|---|---|
$ACQUIRE_GALAXY_LOCK |
Acquires
ownership of an OpenVMS Galaxy lock. |
$CREATE_GALAXY_LOCK |
Allocates
an OpenVMS Galaxy lock block from a lock table created with the $CREATE_GALAXY_LOCK
service. |
$CREATE_GALAXY_LOCK_TABLE |
Allocates
an OpenVMS Galaxy lock table. |
$DELETE_GALAXY_LOCK |
Invalidates
an OpenVMS Galaxy lock and deletes it. |
$DELETE_GALAXY_LOCK_TABLE |
Deletes
an OpenVMS Galaxy lock table. |
$GET_GALAXY_LOCK_INFO |
Returns "interesting"
fields from the specified lock. |
$GET_GALAXY_LOCK_SIZE |
Returns
the minimum and maximum size of an OpenVMS Galaxy lock. |
$RELEASE_GALAXY_LOCK |
Releases
ownership of an OpenVMS Galaxy lock. |
System
Service |
Description |
|---|---|
$CLEAR_SYSTEM_EVENT |
Removes
one or more notification requests previously established by a call to $SET_SYSTEM_EVENT. |
$SET_SYSTEM_EVENT |
Establishes
a request for notification when an OpenVMS system event occurs. |
Bit |
Value |
Description |
|---|---|---|
0 |
1 |
0
= Full dump. The entire contents of physical memory are written to the dump
file. 1 = Selective dump. The contents of memory are written to the dump file selectively to maximize the usefulness of the dump file while conserving disk space. (Only pages that are in use are written). |
1 |
2 |
0
= Minimal console output. This consists of the bugcheck code; the identity
of the CPU, process, and image where the crash occurred; the system date and
time; plus a series of dots indicating progress writing the dump. 1 = Full console output. This includes the minimal output described above plus stack and register contents, system layout, and additional progress information such as the names of processes as they are dumped. |
2 |
4 |
0
= Dump to system disk. The dump are written to SYS$SYSDEVICE:[SYSn.SYSEXE]SYSDUMP.DMP,
or in its absence, SYS$SYSDEVICE:[SYSn.SYSEXE]PAGEFILE.SYS. 1 = Dump to alternate disk. The dump are written to dump_dev:[SYSn.SYSEXE]SYSDUMP.DMP, where dump_dev is the value of the console environment variable DUMP_DEV. |
3 |
8 |
0
= Uncompressed dump. Pages are written directly to the dump file. 1 = Compressed dump. Each page is compressed before it is written, providing a saving in space and in the time taken to write the dump, at the expense of a slight increase in time taken to access the dump. |
4 |
16 |
0
= Dump shared memory. 1 = Do not dump shared memory. |
$ INITIALIZE/QUEUE/ON=QUEBIT::/BATCH/RAD=0 BATCHQ1 $ SHOW QUEUE/FULL BATCHQ1 Batch queue BATCHQ1, stopped, QUEBIT:: /BASE_PRIORITY=4 /JOB_LIMIT=1 /OWNER=[SYSTEM] /PROTECTION=(S:M,O:D,G:R,W:S) /RAD=0
$ START/QUEUE/RAD=1 BATCHQ1 $ SHOW QUEUE/FULL BATCHQ1 Batch queue BATCHQ1, idle, on QUEBIT:: /BASE_PRIORITY=4 /JOB_LIMIT=3 /OWNER=[SYSTEM] /PROTECTION=(S:M,O:D,G:R,W:S) /RAD=1
$ SET/QUEUE/RAD=0 BATCHQ1 $ SHOW QUEUE/FULL BATCHQ1 Batch queue BATCHQ1, idle, on QUEBIT:: /BASE_PRIORITY=4 /JOB_LIMIT=3 /OWNER=[SYSTEM] /PROTECTION=(S:M,O:D,G:R,W:S) /RAD=0
$ SET/QUEUE/NORAD BATCHQ1 $ SHOW QUEUE/FULL BATCHQ1 Batch queue BATCHQ1, idle, on QUEBIT:: /BASE_PRIORITY=4 /JOB_LIMIT=3 /OWNER=[SYSTEM] /PROTECTION=(S:M,O:D,G:R,W:S)
$ WRITE SYS$OUTPUT F$GETQUI("DISPLAY_QUEUE","RAD","BATCHQ1")
-1$ SUBMIT/HOLD/QUEUE=ANYRADQ /RAD=1 TEST.COM
Job TEST (queue ANYRADQ, entry 23) holding
$ SHOW ENTRY/FULL 23
Entry Jobname Username Blocks Status
----- ------- -------- ------ ------
23 TEST SYSTEM Holding
On idle batch queue ANYRADQ
Submitted 24-JUL-2001 14:19:37.44 /KEEP /NOPRINT /PRIORITY=100
/RAD=0
File: _$1$DKB200:[SWEENEY.CLIUTL]TEST.COM;1$ SUBMIT/HOLD/QUEUE=BATCHQ1 /RAD=1 TEST.COM
Job TEST (queue BATCHQ1, entry 24) holding
$ SHOW ENTRY 24/FULL
Entry Jobname Username Blocks Status
----- ------- -------- ------ ------
24 TEST SYSTEM Holding
On idle batch queue BATCHQ1
Submitted 24-JUL-2001 14:23:10.37 /KEEP /NOPRINT /PRIORITY=100
/RAD=0
File: _$1$DKB200:[SWEENEY.CLIUTL]TEST.COM;2SYSTEM@QUEBIT> SUBMIT/NONOTIFY/NOLOG/QUEUE=BATCHQ1 TEST.COM
Job TEST (queue BATCHQ1, entry 30) started on BATCHQ1
OPCOM MESSAGES
SYSTEM@QUEBIT> START/QUEUE BATCHQ1
%%%%%%%%%%% OPCOM 25-JUL-2001 16:15:48.52 %%%%%%%%%%%
Message from user SYSTEM on QUEBIT
%JBC-E-FAILCREPRC, job controller could not create a process
%%%%%%%%%%% OPCOM 25-JUL-2001 16:15:48.53 %%%%%%%%%%%
Message from user SYSTEM on QUEBIT
-SYSTEM-E-BADRAD, bad RAD specified
%%%%%%%%%%% OPCOM 25-JUL-2001 16:15:48.54 %%%%%%%%%%%
Message from user SYSTEM on QUEBIT
%QMAN-E-CREPRCSTOP, failed to create a batch process, queue BATCHQ1 will be stopped
$SYSTEM@QUEBIT> WRITE SYS$OUTPUT -
_$ F$message(%x’F$GETQUI("DISPLAY_ENTRY","CONDITION_VECTOR","30")’)
%SYSTEM-E-BADRAD, bad RAD specifiedSystem
Service |
RAD
Information |
|---|---|
$CREATE_GDZRO |
Argument:
rad_mask
Flag: SEC$M_RAD_HINT Error status: SS$_BADRAD |
$CREPRC |
Argument:
home_rad
Status flag bit: stsflg Symbolic name: PRC$M_HOME_RAD Error status: SS$_BADRAD |
$CRMPSC_GDZRO_64 |
Argument:
rad_mask
Flag: SEC$M_RAD_MASK Error status: SS$_BADRAD |
$GETJPI |
Item
code: JPI$_HOME_RAD |
$GETSYI |
Item
codes: RAD_MAX_RADS, RAD_CPUS, RAD_MEMSIZE, RAD_SHMEMSIZE, GALAXY_SHMEMSIZE |
$SET_PROCESS_PROPERTIESW |
Item
code: PPROP$C_HOME_RAD |
DCL
Command/Lexical |
RAD
Information |
|---|---|
SET
PROCESS |
Qualifier:
/RAD=HOME=n |
SHOW
PROCESS |
Qualifier:
/RAD |
F$GETJPI |
Item
code: HOME_RAD |
F$GETSYI |
Item
codes: RAD_MAX_RADS, RAD_CPUS, RAD_MEMSIZE, RAD_SHMEMSIZE |
SHOW RAD [number|/ALL]
SDA> SHOW RAD
Resource Affinity Domains
-------------------------
RAD information header address: FFFFFFFF.82C2F940
Maximum RAD count: 00000008
RAD containing SYS$BASE_IMAGE: 00000000
RAD support flags: 0000000F
3 2 2 1 1
1 4 3 6 5 8 7 0
+-----------+-----------+-----------+-----------+
|..|..| skip|ss|gg|ww|pp|..|..|..|..|..|fs|cr|ae|
+-----------+-----------+-----------+-----------+
|..|..| 0| 0| 0| 0| 0|..|..|..|..|..|00|11|11|
+-----------+-----------+-----------+-----------+
Bit 0 = 1: RAD support is enabled
Bit 1 = 1: Soft RAD affinity support is enabled
(Default scheduler skip count of 16 attempts)
Bit 2 = 1: System-space replication support is enabled
Bit 3 = 1: Copy on soft fault is enabled
Bit 4 = 0: Default RAD-based page allocation in use
Allocation Type RAD choice
--------------- ----------
Process-private pagefault Home
Process creation or inswap Random
Global pagefault Random
System-space page allocation Current
Bit 5 = 0: RAD debug feature is disabled)
SDA> SHOW RAD 2
Resource Affinity Domain 0002
-----------------------------
CPU sets:
Active 08 09 10 11
Configure 08 09 10 11
Potential 08 09 10 11
PFN ranges:
Start PFN End PFN PFN count Flags
--------- -------- --------- -----
01000000 0101FFFF 00020000 000A OpenVMS Base
01020000 0103FFFF 00020000 0010 Galaxy_Shared
SYSPTBR: 01003C00)
http://ftp.digital.com/pub/DEC/Alpha/firmware/
 Note
Note
P00>>> SET ARC_ENABLE ON P00>>> INITIALIZE P00>>> RUN ECU
P00>>> boot
$ @SYS$SYSTEM:SHUTDOWN
P00>>> SET ARC_ENABLE OFF
P00>>> INITIALIZE
P00>>> LPINIT%SYSTEM-I-NOCONFIGDATA, IRQ Configuration data for EISA slot xxx was not found, please run the ECU and reboot.
P00>>> SET LP_COUNT 0 P00>>> INIT
http://ftp.digital.com/pub/DEC/Alpha/firmware/.
P00>>> create -nv lp_count 2 P00>>> create -nv lp_cpu_mask0 1 P00>>> create -nv lp_cpu_mask1 fe P00>>> create -nv lp_io_mask0 100 P00>>> create -nv lp_io_mask1 80 P00>>> create -nv lp_mem_size0 10000000 P00>>> create -nv lp_mem_size1 10000000 P00>>> create -nv lp_shared_mem_size 20000000 P00>>> init
TipsP00>>> SHOW LP* lp_count 2 lp_shared_mem_size 20000000 (512 MB) lp_mem_size0 10000000 (256 MB) lp_mem_size1 10000000 (256 MB) lp_cpu_mask0 1 (CPU 0) lp_cpu_mask1 fe (CPUs 1-7) lp_io_mask0 100 (I/O module in slot 8) lp_io_mask1 80 (I/O module in slot 7) P00>>
P00>>> SET CONSOLE SERIAL
P00>>> SHOW NETWORK P00>>> SET EWA0_MODE TWISTED
P00>>> INIT
P00>>> SHOW DEVICE
P00>>> SHOW NETWORK
P00>>> LPINIT
Partition 0: Primary CPU = 0 Partition 1: Primary CPU = 2 Partition 0: Memory Base = 000000000 Size = 010000000 Partition 1: Memory Base = 010000000 Size = 010000000 Shared Memory Base = 020000000 Size = 010000000 LP Configuration Tree = 12c000 starting cpu 1 in Partition 1 at address 01000c001 starting cpu 2 in Partition 1 at address 01000c001 starting cpu 3 in Partition 1 at address 01000c001 starting cpu 4 in Partition 1 at address 01000c001 starting cpu 5 in Partition 1 at address 01000c001 starting cpu 6 in Partition 1 at address 01000c001 starting cpu 7 in Partition 1 at address 01000c001 P00>>>
P00>>> B -FL 0,1 DKA100 // or whatever your boot device is. SYSBOOT> SET GALAXY 1 SYSBOOT> CONTINUE
P08>>> SET ARC_ENABLE ON P08>>> INITIALIZE P08>>> RUNECU
P08>>> boot
$ @SYS$SYSTEM:SHUTDOWN
P08>>> SET ARC_ENABLE OFF
P08>>> INITIALIZE
P08>>> LPINIT%SYSTEM-I-NOCONFIGDATA, IRQ Configuration data for EISA slot xxx was not found, please run the ECU and reboot.
P08>>> SET LP_COUNT 0 P08>>> INIT
P08>>> create -nv lp_count 2 P08>>> create -nv lp_cpu_mask0 100 P08>>> create -nv lp_cpu_mask1 e00 P08>>> create -nv lp_io_mask0 100 P08>>> create -nv lp_io_mask1 80 P08>>> create -nv lp_mem_size0 10000000 P08>>> create -nv lp_mem_size1 10000000 P08>>> create -nv lp_shared_mem_size 20000000 P08>>> init
TipsP08>>> SHOW LP* lp_count 2 lp_shared_mem_size 20000000 (512 MB) lp_mem_size0 10000000 (256 MB) lp_mem_size1 10000000 (256 MB) lp_cpu_mask0 100 (CPU 0) lp_cpu_mask1 e00 (CPUs 1-3) lp_io_mask0 100 (I/O module in slot 8) lp_io_mask1 80 (I/O module in slot 7) P08>>>
P08>>> SET CONSOLE SERIAL
P08>>> SHOW NETWORK P08>>> SET EWA0_MODE TWISTED
P08>>> INIT
P08>>> SHOW DEVICE
P08>>> SHOW NETWORK
P08>>> LPINIT
Partition 0: Primary CPU = 0 Partition 1: Primary CPU = 2 Partition 0: Memory Base = 000000000 Size = 010000000 Partition 1: Memory Base = 010000000 Size = 010000000 Shared Memory Base = 020000000 Size = 010000000 LP Configuration Tree = 12c000 starting cpu 1 in Partition 1 at address 01000c001 starting cpu 2 in Partition 1 at address 01000c001 starting cpu 3 in Partition 1 at address 01000c001 P08>>>
P08>>> B -FL 0,1 DKA100 // or whatever your boot device is. SYSBOOT> SET GALAXY 1 SYSBOOT> CONTINUE
P00>>>show config
Console G53_75 OpenVMS PALcode V1.19-16, Compaq UNIX PALcode V1.21-24 Module Type Rev Name System Motherboard 0 0000 mthrbrd0 Memory 512 MB EDO 0 0000 mem0 Memory 256 MB EDO 0 0000 mem1 CPU (Uncached) 0 0000 cpu0 CPU (Uncached) 0 0000 cpu1 Bridge (IOD0/IOD1) 600 0021 iod0/iod1 PCI Motherboard 8 0000 saddle0 CPU (Uncached) 0 0000 cpu2 CPU (Uncached) 0 0001 cpu3 Bus 0 iod0 (PCI0) Slot Option Name Type Rev Name 1 PCEB 4828086 0005 pceb0 4 DEC KZPSA 81011 0000 pks1 5 DECchip 21040-AA 21011 0023 tulip1 Bus 1 pceb0 (EISA Bridge connected to iod0, slot 1) Slot Option Name Type Rev Name Bus 0 iod1 (PCI1) Slot Option Name Type Rev Name 1 NCR 53C810 11000 0002 ncr0 2 DECchip 21040-AA 21011 0024 tulip0 3 DEC KZPSA 81011 0000 pks0
P00>>> create -nv lp_count 2 P00>>> create -nv lp_cpu_mask0 1 P00>>> create -nv lp_cpu_mask1 6 P00>>> create -nv lp_io_mask0 10 P00>>> create -nv lp_io_mask1 20 P00>>> create -nv lp_mem_size0 10000000 P00>>> create -nv lp_mem_size1 c000000 P00>>> create -nv lp_shared_mem_size 4000000 P00>>> set auto_action halt
P00>>> init P00>>> galaxy
CPU0 would not join
IOD0 and IOD1 did not pass the power-up self-test
P01>>> create -nv lp_cpu_mask0 1 P01>>> create -nv lp_cpu_mask1 6 P01>>> create -nv lp_io_mask0 10 P01>>> create -nv lp_io_mask1 20 P01>>> create -nv lp_mem_size0 10000000 P01>>> create -nv lp_mem_size1 c000000 P01>>> create -nv lp_count 2 P01>>> create -nv lp_shared_mem_size 4000000 P01>>> set auto_action halt
P00>>> init
Do you REALLY want to reset the Galaxy (Y/N)
P00>>> set boot_osflags 12,0 P00>>> set bootdef_dev dka0 P00>>> set boot_reset off !!! must be OFF !!! P00>>> set ewa0_mode twisted P01>>> set boot_osflags 11,0 P01>>> set bootdef_dev dkb200 P01>>> set boot_reset off !!! must be OFF !!! P01>>> set ewa0_mode twisted
P01>>> boot
GALAXY=1
$ @SYS$UPDATE:AUTOGEN GETDATA SHUTDOWN INITIAL
P00>>> boot
Add the line GALAXY=1
$ @SYS$UPDATE:AUTOGEN GETDATA SHUTDOWN INITIAL
P00>>> set auto_action restart P01>>> set auto_action restart
P00>>> init
Do you REALLY want to reset the Galaxy (Y/N)
http://ftp.digital.com/pub/DEC/Alpha/firmware/
P00>>>show config
Firmware
SRM Console: X5.6-2323
ARC Console: v5.70
PALcode: OpenVMS PALcode V1.61-2, Tru64 UNIX PALcode V1.54-2
Serial Rom: V2.2-F
RMC Rom: V1.0
RMC Flash Rom: T2.0
Processors
CPU 0 Alpha 21264-4 500 MHz 4MB Bcache
CPU 1 Alpha 21264-4 500 MHz 4MB Bcache
CPU 2 Alpha 21264-4 500 MHz 4MB Bcache
CPU 3 Alpha 21264-4 500 MHz 4MB Bcache
Core Logic
Cchip DECchip 21272-CA Rev 9(C4)
Dchip DECchip 21272-DA Rev 2
Pchip 0 DECchip 21272-EA Rev 2
Pchip 1 DECchip 21272-EA Rev 2
TIG Rev 10
Memory
Array Size Base Address Intlv Mode
--------- ---------- ---------------- ----------
0 4096Mb 0000000000000000 2-Way
1 4096Mb 0000000100000000 2-Way
2 1024Mb 0000000200000000 2-Way
3 1024Mb 0000000240000000 2-Way
10240 MB of System Memory
Slot Option Hose 0, Bus 0, PCI
1 DAPCA-FA ATM622 MMF
2 DECchip 21152-AA Bridge to Bus 2, PCI
3 DEC PCI FDDI fwb0.0.0.3.0 00-00-F8-BD-C6-5C
4 DEC PowerStorm
7 Acer Labs M1543C Bridge to Bus 1, ISA
15 Acer Labs M1543C IDE dqa.0.0.15.0
dqb.0.1.15.0
dqa0.0.0.15.0 TOSHIBA CD-ROM XM-6302B
19 Acer Labs M1543C USB
Option Hose 0, Bus 1, ISA
Floppy dva0.0.0.1000.0
Slot Option Hose 0, Bus 2, PCI
0 NCR 53C875 pkd0.7.0.2000.0 SCSI Bus ID 7
1 NCR 53C875 pke0.7.0.2001.0 SCSI Bus ID 7
dke100.1.0.2001.0 RZ1BB-CS
dke200.2.0.2001.0 RZ1BB-CS
dke300.3.0.2001.0 RZ1CB-CS
dke400.4.0.2001.0 RZ1CB-CS
2 DE500-AA Network Con ewa0.0.0.2002.0 00-06-2B-00-0A-58
Slot Option Hose 1, Bus 0, PCI
1 NCR 53C895 pka0.7.0.1.1 SCSI Bus ID 7
dka100.1.0.1.1 RZ2CA-LA
dka300.3.0.1.1 RZ2CA-LA
2 Fore ATM 155/622 Ada
3 DEC PCI FDDI fwa0.0.0.3.1 00-00-F8-45-B2-CE
4 QLogic ISP10x0 pkb0.7.0.4.1 SCSI Bus ID 7
dkb100.1.0.4.1 HSZ50-AX
dkb101.1.0.4.1 HSZ50-AX
dkb200.2.0.4.1 HSZ50-AX
dkb201.2.0.4.1 HSZ50-AX
dkb202.2.0.4.1 HSZ50-AX
5 QLogic ISP10x0 pkc0.7.0.5.1 SCSI Bus ID 7
dkc100.1.0.5.1 RZ1CB-CS
dkc200.2.0.5.1 RZ1CB-CS
dkc300.3.0.5.1 RZ1CB-CS
dkc400.4.0.5.1 RZ1CB-CS
6 DECchip 21154-AA Bridge to Bus 2, PCI
Slot Option Hose 1, Bus 2, PCI
4 DE602-AA eia0.0.0.2004.1 00-08-C7-91-0A-AA
5 DE602-AA eib0.0.0.2005.1 00-08-C7-91-0A-AB
6 DE602-TA eic0.0.0.2006.1 00-08-C7-66-80-9E
7 DE602-TA eid0.0.0.2007.1 00-08-C7-66-80-5E
P00>>> boot -fl 0,0 ewa0 -fi {firmware filename}
UPD> update srm*
power-cycle systemP00>>> BOOT -FLAGS 0,A0 cd_device_name
.
.
.
Bootfile: {firmware filename}
.
.
.P00>>> set lp_count 2 P00>>> set lp_cpu_mask0 1 P00>>> set lp_cpu_mask1 6 P00>>> set lp_io_mask0 1 P00>>> set lp_io_mask1 2 P00>>> set lp_mem_size0 10000000 P00>>> set lp_mem_size1 c000000 P00>>> set lp_shared_mem_size 4000000 P00>>> set console_memory_allocation new P00>>> set auto_action halt
Assign secondary CPU 2 with primary CPU 0 and secondary CPU 3 with primary CPU 1. >>>set lp_cpu_mask0 5 >>>set lp_cpu_mask1 A CPU Selection LP_CPU_MASK 0(primary partition 0) 2^0 = 1 1(primary partition 1) 2^1 = 2 2(secondary) 2^2 = 4 3(secondary) 2^3 = 8
P00>>> init ! initialize the system P00>>> lpinit ! start firmware
Instance 0
P00>>> set boot_osflags 12,0
P00>>> set bootdef_dev dka0
P00>>> set boot_reset off !!! must be OFF !!!
P00>>> set ewa0_mode twisted
Instance 1
P01>>> set boot_osflags 11,0
P01>>> set bootdef_dev dkb200
P01>>> set boot_reset off !!! must be OFF !!!
P01>>> set ewa0_mode twistedP01>>> boot
GALAXY=1
$ @SYS$UPDATE:AUTOGEN GETDATA SHUTDOWN INITIAL
P00>>> boot
GALAXY=1
$ @SYS$UPDATE:AUTOGEN GETDATA SHUTDOWN INITIAL
P00>>> set auto_action restart P01>>> set auto_action restart
P00>>> init
Do you REALLY want to reset all partitions? (Y/N)
P00>>>show lp* lp_count 4 lp_cpu_mask0 000F lp_cpu_mask1 00F0 lp_cpu_mask2 0F00 lp_cpu_mask3 F000 lp_cpu_mask4 0 lp_cpu_mask5 0 lp_cpu_mask6 0 lp_cpu_mask7 0 lp_error_target 0 lp_io_mask0 1 lp_io_mask1 2 lp_io_mask2 4 lp_io_mask3 8 lp_io_mask4 0 lp_io_mask5 0 lp_io_mask6 0 lp_io_mask7 0 lp_mem_size0 0=4gb lp_mem_size1 1=4gb lp_mem_size2 2=4gb lp_mem_size3 3=4gb lp_mem_size4 0 lp_mem_size5 0 lp_mem_size6 0 lp_mem_size7 0 lp_shared_mem_size 16gb P00>>>lpinit
P00>>>show lp* lp_count 4 lp_cpu_mask0 000F000F lp_cpu_mask1 00F000F0 lp_cpu_mask2 0F000F00 lp_cpu_mask3 F000F000 lp_cpu_mask4 0 lp_cpu_mask5 0 lp_cpu_mask6 0 lp_cpu_mask7 0 lp_error_target 0 lp_io_mask0 11 lp_io_mask1 22 lp_io_mask2 44 lp_io_mask3 88 lp_io_mask4 0 lp_io_mask5 0 lp_io_mask6 0 lp_io_mask7 0 lp_mem_size0 0=2gb, 4=2gb lp_mem_size1 1=2gb, 5=2gb lp_mem_size2 2=2gb, 6=2gb lp_mem_size3 3=2gb, 7=2gb lp_mem_size4 0 lp_mem_size5 0 lp_mem_size6 0 lp_mem_size7 0 lp_shared_mem_size 16gb P00>>>lpinit
Mask
Value |
QBB
Number |
|---|---|
1 |
QBB
0 |
2 |
QBB
1 |
4 |
QBB
2 |
8 |
QBB
3 |
lp_mem_size0 0=2gb, 1=2gb
Notelp_shared_mem_size 16gb
P00>>> SHOW NETWORK P00>>> SET EWA0_MODE TWISTED
P00>>> LPINIT
P00>>>lpinit lp_count = 2 lp_mem_size0 = 1800 (6 GB) CPU 0 chosen as primary CPU for partition 0 lp_mem_size1 = 1800 (6 GB) CPU 4 chosen as primary CPU for partition 1 lp_shared_mem_size = 1000 (4 GB) initializing shared memory partitioning system QBB 0 PCA 0 Target 0 Interrupt Count = 2 QBB 0 PCA 0 Target 0 Interrupt CPU = 0 Interrupt Enable = 000011110000d05a Sent Interrupts = 0000100000000010 Enabled Sent Interrupts = 0000100000000010 Acknowledging Sent Interrupt 0000000000000010 for CPU 0 QBB 0 PCA 0 Target 0 Interrupt Count = 1 QBB 0 PCA 0 Target 0 Interrupt CPU = 0 Interrupt Enable = 000011110000d05a Sent Interrupts = 0000100000000000 Enabled Sent Interrupts = 0000100000000000 Acknowledging Sent Interrupt 0000100000000000 for CPU 0 OpenVMS PALcode V1.80-1, Tru64 UNIX PALcode V1.74-1 system = QBB 0 1 2 3 + HS (Hard Partition 0) QBB 0 = CPU 0 1 2 3 + Mem 0 + Dir + IOP + PCA 0 1 + GP (Hard QBB 0) QBB 1 = CPU 0 1 2 3 + Mem 0 + Dir + IOP + PCA 0 1 + GP (Hard QBB 1) QBB 2 = CPU 0 1 2 3 + Mem 0 + Dir + IOP + PCA + GP (Hard QBB 4) QBB 3 = CPU 0 1 2 3 + Mem 0 + Dir + IOP + PCA + GP (Hard QBB 5) partition 0 CPU 0 1 2 3 8 9 10 11 IOP 0 2 private memory size is 6 GB shared memory size is 4 GB micro firmware version is T5.4 shared RAM version is 1.4 hose 0 has a standard I/O module starting console on CPU 0 QBB 0 memory, 4 GB QBB 1 memory, 4 GB QBB 2 memory, 4 GB QBB 3 memory, 4 GB total memory, 16 GB probing hose 0, PCI probing PCI-to-ISA bridge, bus 1 bus 1, slot 0 -- dva -- Floppy bus 0, slot 1 -- pka -- QLogic ISP10x0 bus 0, slot 2 -- pkb -- QLogic ISP10x0 bus 0, slot 3 -- ewa -- DE500-BA Network Controller bus 0, slot 15 -- dqa -- Acer Labs M1543C IDE probing hose 1, PCI probing hose 2, PCI bus 0, slot 1 -- fwa -- DEC PCI FDDI probing hose 3, PCI starting console on CPU 1 starting console on CPU 2 starting console on CPU 3 starting console on CPU 8 starting console on CPU 9 starting console on CPU 10 starting console on CPU 11 initializing GCT/FRU at 1fa000 initializing pka pkb ewa fwa dqa Testing the System Testing the Disks (read only) Testing the Network AlphaServer Console X5.8-2842, built on Apr 6 2000 at 01:43:42 P00>>>
P00>>> B -FL 0,1 DKA100 // or whatever your boot device is. SYSBOOT> SET GALAXY 1 SYSBOOT> CONTINUE
>>> B -FL 0,1 device
SYSBOOT> SET GALAXY 1 SYSBOOT> CONTINUE
Note>>> SET LP_COUNT 0 ! Return to monolithic SMP config >>> INIT ! Return to single SMP console >>> B -fl 0,1 device ! Stop at SYSBOOT SYSBOOT> SET GALAXY 0 SYSBOOT> CONTINUE
File |
Description |
SYS$SYSTEM:GCU.EXE |
GCU
executable image |
SYS$MANAGER:GCU.DAT |
Optional
DECwindows resource file |
SYS$MANAGER:GALAXY.GCR |
Galaxy
Configuration Ruleset |
SYS$MANAGER:GCU$ACTIONS.COM |
System
management procedures |
SYS$MANAGER:xxx.GCM |
User-defined
configuration models |
SYS$HELP:GALAXY_GUIDE.DECW$BOOK |
Online
help in Bookreader form |
Function |
Description |
|---|---|
Galactic
zoom |
Zoom
to fit the entire component hierarchy into observation window. |
Zoom
1:1 |
Zoom
to the component normal scale. |
Zoom
to region |
Zoom
to a selected region of the display. |
Zoom
in |
Zoom
in by 10 percent. |
Zoom
out |
Zoom
out by 10 percent. |
Chart
Name |
Shows |
|---|---|
Logical
Structure |
Dynamic
resource assignments |
Physical
Structure |
Nonvolatile
hardware relationships |
CPU
Assignment |
Simplified
view of CPU assignments |
Memory
Assignment |
Memory
subsystem components |
IOP
Assignment |
I/O
module relationships |
Failover
Targets |
Processor
failover assignments |
$ SET DEFAULT SYS$SYSTEM $ RUN AUTHORIZE
UAF> CREATE/PROXY UAF> ADD/PROXY instance::SYSTEM SYSTEM UAF> EXIT
Tip TipFORMAT EXAMPLE:
MENU "Menu-Name" "Entry-Name" Procedure-type "DCL-command"
* Menu-Name - A quoted string representing the name of the
pulldown menu to add or extend.
* Entry-Name - A quoted string representing the name of the
menu entry to add.
* Procedure-type - A keyword describing the type of procedure
to invoke when the menu entry is selected.
Valid Procedure-type keywords include:
COMMAND_PROCEDURE - Executes a DCL command or command file.
SUBPROC_PROCEDURE - Executes a DCL command in subprocess context.
* DCL-command - A quoted string containing a DCL command statement
consisting of an individual command or invokation
of a command procedure.EXAMPLE MENU STATEMENTS (place in SYS$MANAGER:GCU$CUSTOM.GCR): // GCU$CUSTOM.GCR - GCU menu customizations // Note that the file must end with the END-OF-FILE statement. // MENU "Tools" "Availability Manager" SUBPROC_PROCEDURE "AVAIL/GROUP=DECamds" MENU "Tools" "Create DECterm" COMMAND_PROCEDURE "CREATE/TERM/DETACH" MENU "DCL" "Show CPU" COMMAND_PROCEDURE "SHOW CPU" MENU "DCL" "Show Memory" COMMAND_PROCEDURE "SHOW MEMORY" MENU "DCL" "Show System" COMMAND_PROCEDURE "SHOW SYSTEM" MENU "DCL" "Show Cluster" COMMAND_PROCEDURE "SHOW CLUSTER" END-OF-FILE
$ @SYS$STARTUP:AMDS$STARTUP START
$ @SYS$STARTUP:AMDS$STARTUP STOP
%GCU-E-SUBPROCHALT, Subprocess halted; See GCU.LOG.
The GCU has launched a user-defined subprocess which has terminated
with error status. Details may be found in the file GCU.LOG.
%GCU-S-SUBPROCTERM, Subprocess terminated
The GCU has launched a user-defined subprocess which has terminated.
%GCU-I-SYNCMODE, XSynchronize activated
The GCU has been invoked with X-windows synchronous mode enabled.
This is a development mode which is not generally used.
%GCU-W-NOCPU, Unable to locate CPU
A migration action was initiated which involved an unknown CPU. This
can result from engaging a model which contains invalid CPU identifiers
for the current system.
%GCU-E-NORULESET, Ruleset not found:
The GCU was unable to locate the Galaxy Configuration Ruleset in
SYS$MANAGER:GALAXY.GCR. New versions of this file can be downloaded
from the OpenVMS Galaxy web page.
%GCU-E-NOMODEL, Galaxy configuration model not found:
The specified Galaxy Configuration Model was not found. Check your
command line model file specification.
%GCU-W-XTOOLKIT, X-Toolkit Warning:
The GCU has intercepted an X-Toolkit warning. You may or may not be
able to continue, depending on the type of warning.
%GCU-S-ENGAGED, New Galaxy configuration model engaged
The GCU has successfully engaged a new Galaxy Configuration Model.
%GCU-E-DISENGAGED, Unable to engage Galaxy configuration model
The GCU has failed to engage a new Galaxy Configuration Model. This
can happen when a specified model is invalid for the current system, or
when other system activities prevent the requested resource assignments.
%GCU-E-NODECW, DECwindows is not installed.
The current system does not have the required DECwindows support.
%GCU-E-HELPERROR Help subsystem error.
The DECwindows Help system (Bookreader) encountered an error.
%GCU-E-TOPICERROR Help topic not found.
The DECwindows Help system could not locate the specified topic.
%GCU-E-INDEXERROR Help index not found.
The DECwindows Help system could not locate the specified index.
%GCU-E-UNKNOWN_COMPONENT: {name}
The current model contains reference to an unknown component. This
can result from model or ruleset corruption. Search for the named
component in the ruleset SYS$MANAGER:GALAXY.GCR. If it is not found,
download a new one from the OpenVMS Galaxy web site. If the problem
persists, delete and recreate the offending model.
%GCU-I-UNASSIGNED_HW: Found unassigned {component}"
The GCU has detected a hardware component which is not currently
assigned to any Galaxy instance. This may result from intentionally
leaving unassigned resources. Note the message and continue or
assign the hardware component from the primary Galaxy console and
reboot.
%GCU-E-UNKNOWN_KEYWORD: {word}
The GCU has parsed an unknown keyword in the current model file. This
can only result from model file format corruption. Delete and
recreate the offending model.
%GCU-E-NOPARAM: Display field {field name}
The GCU has parsed an incomplete component statement in the current
model. This can only result from model file format corruption.
Delete and recreate the offending model.
%GCU-E-NOEDITFIELD: No editable field in display.
The GCU has attempted to edit a component parameter which is undefined.
This can only result from model file format corruption. Delete and
recreate the offending model.
%GCU-E-UNDEFTYPE, Undefined Parameter Data Type: {type}
The GCU has parsed an unknown data type in a model component parameter.
This can result from model file format corruption or incompatible
ruleset for the current model. Search the ruleset SYS$MANAGER:GALAXY.GCR
for the offending datatype. If not found, download a more recent
ruleset from the OpenVMS Galaxy web site. If found, delete and
recreate the offending model.
%GCU-E-INVALIDMODEL, Invalid model structure in: {model file}
The GCU attempted to load an invalid model file. Delete and recreate
the offending model.
%GCU-F-TERMINATE Unexpected termination.
The GCU encountered a fatal DECwindows event.
%GCU-E-GCTLOOP: Configuration Tree Parser Loop
The GCU has attempted to parse a corrupt configuration tree. This
may be a result of console firmware or operating system fault.
%GCU-E-INVALIDNODE: Invalid node in Configuration Tree
The GCU has parsed an invalid structure within the configuration tree.
This can only result from configuration tree corruption or revision
mismatch between the ruleset and console firmware.
%GCU-W-UNKNOWNBUS: Unknown BUS subtype: {type}
The GCU has parsed an unknown bus type in the current configuration
tree. This can only result from revision mismatch between the
ruleset and console firmware.
%GCU-W-UNKNOWNCTRL, Unknown Controller type: {type}
The GCU has parsed an unknown controller type in the current configuration
tree. This can only result from revision mismatch between the
ruleset and console firmware.
%GCU-W-UNKNOWNCOMP, Unknown component type: {type}
The GCU has parsed an unknown component type in the current configuration
tree. This can only result from revision mismatch between the
ruleset and console firmware.
%GCU-E-NOIFUNCTION, Unknown internal function
The user has modified the ruleset file and specified an unknown
internal GCU function. Correct the ruleset or download a new one
from the OpenVMS Galaxy web page.
%GCU-E-NOEFUNCTION, Missing external function
The user has modified the ruleset file and specified an unknown
external function. Correct the ruleset or download a new one
from the OpenVMS Galaxy web page.
%GCU-E-NOCFUNCTION, Missing command function
The user has modified the ruleset file and specified an unknown
command procedure. Correct the ruleset or download a new one
from the OpenVMS Galaxy web page.
%GCU-E-UNKNOWN_COMPONENT: {component}
The GCU has parsed an unknown component. This can result from
ruleset corruption or revision mismatch between the ruleset and
console firmware.
%GCU-E-BADPROP, Invalid ruleset DEVICE property
The GCU has parsed an invalid ruleset component statement. This can
only result from ruleset corruption. Download a new one from the
OpenVMS Galaxy web page.
%GCU-E-BADPROP, Invalid ruleset CHART property
The GCU has parsed an invalid chart statement. This can
only result from ruleset corruption. Download a new one from the
OpenVMS Galaxy web page.
%GCU-E-BADPROP, Invalid ruleset INTERCONNECT property
The GCU has parsed an invalid ruleset interconnect statement. This can
only result from ruleset corruption. Download a new one from the
OpenVMS Galaxy web page.
%GCU-E-INTERNAL Slot {slot detail}
The GCU has encountered an invalid datatype from a component parameter.
This can result from ruleset or model corruption. Download a new one
from the OpenVMS Galaxy web page. If the problem persists, delete and
recreate the offending model.
%GCU-F-PARSERR, {detail}
The GCU encountered a fatal error while parsing the ruleset. Download
a new one from the OpenVMS Galaxy web page.
%GCU-W-NOLOADFONT: Unable to load font: {font}
The GCU could not locate the specified font on the current system.
A default font will be used instead.
%GCU-W-NOCOLORCELL: Unable to allocate color
The GCU is unable to access a colormap entry. This can result from
a system with limited color support or from having an excessive number
of graphical applications open at the same time.
GCU-E-NOGALAXY, This system is not configured as a Galaxy.
Description:
The user has issued the CONFIGURE GALAXY/ENGAGE command on a
system which is not configured for Galaxy operation.
User Action:
Configure your system for Galaxy operation using the procedures
described in the OpenVMS Galaxy Guide. If you only want to run a
single-instance Galaxy, enter CONFIGURE GALAXY without the
/ENGAGE qualifier and follow the instructions provided by the
Galaxy Configuration Utility.
%GCU-E-ACTIONNOTALPHA GCU actions require OpenVMS Alpha
A GCU user has attempted to invoke a Galaxy configuration operation
on an OpenVMS VAX system.
%GCU-I-ACTIONBEGIN at {time}, on {instance} {mode}
This informational message indicates the start of a configuration
action on the specified Galaxy instance. Note that many actions
require collaboration between command environments on two separate
Galaxy instances, thus, you may encounter two of these messages, one
per instance involved in the operation. The mode argument indicates
which instance is local versus remote.
%GCU-S-ACTIONEND at {time}, on {nodename}
This is the normal successful completion message following a Galaxy
configuration action. Note that many actions require collaboration
between command environments on two separate Galaxy instances, thus, you
may encounter two of these messages, one per instance involved in the
operation.
%GCU-S-ACTIONEND, Exiting GCU$ACTIONS on ^Y
Indicates that the user has aborted a Galaxy configuration action
using Control-Y.
%GCU-S-ACTIONEND, Exiting GCU$ACTIONS on error {message}
Indicates that a Galaxy configuration action terminated with error
status as indicated by the message argument.
%GCU-E-ACTIONUNKNOWN no action specified
Indicates that the GCU$ACTIONS.COM procedure was called improperly.
It is possible that the command procedure has been corrupted or is
out of revision for the current system.
%GCU-E-ACTIONNOSIN no source instance name specified
Indicates that the GCU$ACTIONS.COM procedure was called improperly.
It is possible that the command procedure has been corrupted or is
out of revision for the current system.
%GCU-E-ACTIONBAD failed to execute the specfied action
Indicates that a Galaxy configuration action aborted due to an
indeterminate error condition. Review related screen messages and
verify that the necessary proxy accounts have been established.
%GCU-E-INSFPRIVS, Insufficient privileges for attempted operation
An underprivileged user has attempted to perform a Galaxy configuration
action. Typically, these actions are performed from within the system
managers account. OPER and SYSPRV privileges are required.
%GCU-E-NCF network connect to {instance} failed
An error has occurred trying to open a DECnet task-to-task connection
between the current and specified instances. Review related screen
messages and verify that the necessary proxy accounts have been
established. Note Notehttp://www.openvms.compaq.com
$ PRODUCT INSTALL GCM_SERVER
The following product has been selected:
CPQ AXPVMS GCM_SERVER V1.0 Layered Product
Do you want to continue? [YES]
Configuration phase starting . . .
You will be asked to choose options, if any, for each selected product
and for any selected products that may be installed to satisfy software
dependency requirements.
CPQ AXPVMS GCM_SERVER V1.0: Graphical Configuration Manager V1.0
COPYRIGHT (C) 2002 -- All rights reserved
Compaq Computer Corporation
License and Product Authorization Key (PAK) Information
* This product does not have any configuration options.
Copying GCM Release Notes to SYS$HELP
Will install the GCM Server V1.0.
GCM Startup File
Execution phase starting . . .
The following product will be installed to destination:
CPQ AXPVMS GCM_SERVER V1.0 DISK$WFGLX5_X931:[VMS$COMMON.]
Portion done: 0%...10%...20%...30%...90%...100%
The following product has been installed:
CPQ AXPVMS GCM_SERVER V1.0 Layered Product
$
$ SET DEFAULT SYS$COMMON:[SYS$CONFIG] $ DIRECTORY Directory SYS$COMMON:[SYS$CONFIG] GCM$SETUP.EXE;1 GCM_BANNER.JPG;1 GCM_CERT.PEM;1 GCM_CUSTOM.XML;1 GCM_NOTICE.HTML;1 GCM_PRIVKEY.PEM;1 GCM_RULESET.XML;1 GCM_SERVER.COM;1
$ PRODUCT INSTALL GCM_CLIENT
The following product has been selected:
CPQ AXPVMS GCM_CLIENT V1.0 Layered Product
Do you want to continue? [YES]
Configuration phase starting . . .
You will be asked to choose options, if any, for each selected product
and for any selected products that may be installed to satisfy software
dependency requirements.
CPQ AXPVMS GCM_CLIENT V1.0: Graphical Configuration Manager V1.0 Client
COPYRIGHT (C) 2002 --- All rights reserved
Compaq Computer Corporation
License and Product Authorization Key (PAK) Information
* This product does not have any configuration options.
Copying GCM Release Notes to SYS$HELP
Will install the GCM Java Client V1.0.
Will install a private copy of the Java JRE V1.2.2-3.
Will install a private copy of the Java Fast VM V1.2.2-1
Execution phase starting . . .
The following product will be installed to destination:
CPQ AXPVMS GCM_CLIENT V1.0 DISK$WFGLX5_X931:[VMS$COMMON.]
Portion done: 0%...10%...20%...30%...90%...100%
The following product has been installed:
CPQ AXPVMS GCM_CLIENT V1.0 Layered Product
$
$ SET DEFAULT SYS$COMMON:[GCM_CLIENT] $ DIRECTORY Directory SYS$COMMON:[GCM_CLIENT] BIN.DIR;1 GCM_CERT.CRT;1 IMAGES.DIR JRE122.DIR;1 LIB.DIR;1 README.TXT;1;1 RUN_GCMCLIENT.COM;1
http://www.openvms.compaq.com/openvms
Note$ SET DEFAULT SYS$CONFIG
$ DIRECTORY
Directory SYS$COMMON:[SYS$CONFIG]
GCM$SETUP.EXE;1 GCM_BANNER.JPG;1 GCM_CERT.PEM;1 GCM_CUSTOM.XML;1
GCM_NOTICE.HTML;1 GCM_PRIVKEY.PEM;1 GCM_RULESET.XML;1
Total of 7 files.
$ RUN GCM$SETUP
OpenVMS GCM-Server Setup Utility
Copyright 2002, Hewlett Packard Corporation
This utility initializes the GCM Administrative Database:
SYS$COMMON:[SYS$CONFIG]GCM_ADMIN.EDB
If you are performing an initial GCM-Server installation that will
create an Association of more than a single server instance, you must
perform the following tasks to assure proper server synchronization:
1) Create the new local database using this utility.
2) Copy the database to all other GCM-Server instances in your
Association.
3) Start each GCM-Server.
You can start servers via $@SYS$STARTUP:GCMSRV$STARTUP.COM or by
invoking this utility on each system. When an existing database is
found, this utility will offer additional server startup options.
Continue (Y/N) {Y}?
Do you prefer full text assistance (Y/N) {N}? y
SERVER DISCOVERY TCP/IP PORT NUMBER:
Use the default Port Number 4100 (Y/N) {Y}? y
CONNECTION BOUNDS:
Use the default concurrent CLIENT limit of 4 (Y/N) {Y}? y
Use the default concurrent SERVER limit of 8 (Y/N) {Y}? y
CONNECTION SECURITY:
WARNING - DISABLING SECURITY COULD POTENTIALLY COMPROMISE THE
INTEGRITY OF YOUR SYSTEM AND IS NOT RECOMMENDED BY HEWLETT PACKARD.
Use SSL Client-Server Security (Y/N) {Y}? y
%SECURITY - WILL BE ENABLED.
SERVER ASSOCIATION RECORD:
Enter the Association Name (use no quotes): GCM Test Association
SYSTEM RECORDS:
Enter a SYSTEM Name (ex: star.zko.hp.com) (RETURN when done):
wfglx4.zko.hp.com
Enter a System IP Address (0 to use DNS): 16.32.112.16
Enter a System Number (range 0-7): 0
Enter a HARD PARTITION Number (range 0-7): 0
Enter a SOFT PARTITION Number (range 0-7): 0
%Define additional system records as needed...
Enter a SYSTEM Name (ex: star.zko.hp.com) (RETURN when done):
wfglx5.zko.hp.com
Enter a System IP Address (0 to use DNS): 16.32.112.17
Enter a System Number (range 0-7): 0
Enter a HARD PARTITION Number (range 0-7): 0
Enter a SOFT PARTITION Number (range 0-7): 1
%Define additional system records as needed...
Enter a SYSTEM Name (ex: star.zko.hp.com) (RETURN when done):
CLIENT AUTHORIZATION RECORDS:
Enter Client’s Full Name or Title (RETURN when done): First Last
Enter Client’s Username: First
Enter initial Password for First: Last
Enter EMAIL Address for First: First.Last@hp.com
Give First CONFIG Privilege (Y/N) {Y}? y
COMMAND privilege allows a user to issue DCL commands.
Give First COMMAND Privilege (Y/N) {Y}? y
Give First USER-COMMAND Privilege (Y/N) {Y}? y
Give First POWER Privilege (Y/N) {Y}? y
Give First ADMIN Privilege (Y/N) {Y}? y
Enable First account now (Y/N) {Y}? y
%Define additional client records as needed...
Enter Client’s Full Name or Title (RETURN when done):
SERVER STARTUP OPTIONS:
Do you want the local GCM-SERVER to start on System Boot (Y/N) {Y}? y
Do you want to start the local GCM-SERVER now (Y/N) {Y}? y
************************ POST SETUP TASKS **************************
This completes the GCM Admin Database initialization.
IMPORTANT:
If you are using multiple GCM-Servers, copy the newly created GCM
Admin Database file: SYS$COMMON:[SYS$CONFIG]GCM_ADMIN.EDB, to the
same location on each system you defined in the Association, then
start or restart each server via $ @SYS$STARTUP:GCMSRV$STARTUP.COM
If the database has been properly defined, each server will detect
the presence of the other servers and form the specified Association.
If the GCM_SERVER process fails to start, examine the server logfile
SYS$COMMON:[SYS$CONFIG]GCM_SERVER.LOG.
When the server has started, you may use the GCM-Client to establish
a connection and further tune the installation.
For maximum security, you may wish to protect or remove this utility.
$
$$ MC SYSMAN STARTUP ADD FILE GCMSRV$STARTUP.COM
$ MC SYSMAN STARTUP REMOVE FILE GCMSRV$STARTUP.COM
$ @SYS$STARTUP:GCMSRV$STARTUP
NotePrivilege |
Description |
|---|---|
Config |
Allows
the user to modify the configuration of the association |
Command |
Allows
the user to define commands for self |
User
Command |
Allows
the user to define commands for all clients |
Admin |
Allows
the user to edit the GCM administration database (GCM$ADMIN.EDB) |
Power |
Allows
the user to power systems and components on and off |
NoteFully
Qualified System Name |
IP
Address1 |
System |
Hard
Partition |
Soft
Partition |
|---|---|---|---|---|
sysnam1.zko.dec.com |
16.32.112.1 |
0 |
0 |
0 |
sysnam2.zko.dec.com |
16.32.112.2 |
0 |
0 |
1 |
sysnam3.zko.dec.com |
16.32.112.3 |
0 |
0 |
2 |
sysnam4.zko.dec.com |
16.32.112.4 |
0 |
0 |
3 |
sysnam5.zko.dec.com |
16.32.112.5 |
0 |
1 |
0 |
sysnam6.zko.dec.com |
16.32.112.6 |
0 |
1 |
1 |
sysnam7.zko.dec.com |
16.32.112.7 |
0 |
1 |
2 |
sysnam8.zko.dec.com |
16.32.112.8 |
0 |
1 |
3 |
Note$ RUN SYS$SYSTEM:GCM_SERVER.EXE
Code (decimal) |
Code (hex) |
Function |
Action |
|---|---|---|---|
0 |
0 |
DIAGNOSTIC_DISABLE |
|
1 |
1 |
HEARTBEAT_TRACE |
(servers
disconnecting) |
2 |
2 |
TRANSACTION_TRACE |
(general
troubleshooting) |
4 |
4 |
XML_TRACE |
(general
troubleshooting) |
8 |
8 |
LOCK_TRACE |
(server
hangs) |
16 |
10 |
COMMAND_TRACE |
(disables
execution and dumps packet) |
32 |
20 |
CRYPTO_DISABLE |
(GCM
administration database troubleshooting) |
Note Caution$ SET DEFAULT SYS$CONFIG
$ DIRECTORY
Directory SYS$COMMON:[SYS$CONFIG]
GCM$SETUP.EXE;1 GCM_BANNER.JPG;1 GCM_CERT.PEM;1 GCM_CUSTOM.XML;1
GCM_NOTICE.HTML;1 GCM_PRIVKEY.PEM;1 GCM_RULESET.XML;1
Total of 7 files.
$ RUN GCM$SETUP
OpenVMS GCM-Server Setup Utility
Copyright 2002, Hewlett Packard Corporation
This utility initializes the GCM Administrative Database:
SYS$COMMON:[SYS$CONFIG]GCM_ADMIN.EDB
If you are performing an initial GCM-Server installation that will
create an Association of more than a single server instance, you must
perform the following tasks to assure proper server synchronization:
1) Create the new local database using this utility.
2) Copy the database to all other GCM-Server instances in your Association.
3) Start each GCM-Server.
You can start servers via $@SYS$STARTUP:GCMSRV$STARTUP.COM or by invoking
this utility on each system. When an existing database is found, this
utility will offer additional server startup options.
Continue (Y/N) {Y}?
Do you prefer full text assistance (Y/N) {N}? y
SERVER DISCOVERY TCP/IP PORT NUMBER:
By default, the GCM-Servers listen for client connections on
TCP/IP Port 4100. This can be changed, but each server will need
to be restarted, and each client will need to specify the new
port number in their "Server Connection Preferences" settings.
Use the default Port Number 4100 (Y/N) {Y}? y
CONNECTION BOUNDS:
By default, the GCM-Servers support up to 4 concurrent clients
and 8 concurrent servers. This can be changed, but each server
will need to be restarted. Be advised that GCM performance may
suffer as these values are increased.
Use the default concurrent CLIENT limit of 4 (Y/N) {Y}? y
Use the default concurrent SERVER limit of 8 (Y/N) {Y}? y
CONNECTION SECURITY:
By default, the GCM-Servers expect that their clients will be
using secure connections (SSL). This can be disabled, but the
servers will need to be restarted, and each client will need
to change their "Server Connection Preferences" settings.
WARNING - DISABLING SECURITY COULD POTENTIALLY COMPROMISE THE
INTEGRITY OF YOUR SYSTEM AND IS NOT RECOMMENDED BY HEWLETT PACKARD.
Use SSL Client-Server Security (Y/N) {Y}? y
%SECURITY - WILL BE ENABLED.
SERVER ASSOCIATION RECORD:
Multiple GCM-Servers can form an "Association" of systems, providing
a wide management scope. This Association may include one server per
soft-partition on one or more hard-partition on one or more physical
system. Regardless of how many servers are in the Association, you
need to define an Association Name that describes the involved systems.
Choose a simple descriptive string such as "Engineering Lab Systems".
Enter the Association Name (use no quotes): GCM Test Association
SYSTEM RECORDS:
Each system in the Association must be uniquely identified by its
IP Address, System Number, Hard-Partition Number, and Soft Partition
Number. At least one system must be defined. You may define multiple
systems now, or define additional systems after establishing your
first client connection.
Enter a fully qualified name for the system running a GCM-Server.
For example: star.zko.hp.com. When you are done entering system
records, enter 0 at the following prompt.
Enter a SYSTEM Name (ex: star.zko.hp.com) (RETURN when done): wfglx4.zko.hp.com
Enter a fully qualified IP Address for the system running a
GCM-Server. For example: 16.32.112.16
If you prefer to use DNS to lookup the address, enter 0
Enter a System IP Address (0 to use DNS): 16.32.112.16
The SYSTEM NUMBER is a simple numeric value that uniquely identifies
soft and hard partitions that reside in a common partitionable
computer. For example, if you have two separate partitionable
computers in your Association, each having its own hard and soft
partitioned instances, enter a SYSTEM NUMBER of 0 for all hard and
soft partitions in the first computer, and enter 1 for those in the
second computer.
Enter a System Number (range 0-7): 0
The HARD PARTITION NUMBER is a numeric value that uniquely identifies
which HARD Partition a GCM-Server resides within. If a system has
only a single HARD Partition, enter 0. If a system has multiple
HARD Partitions, use the appropriate Hard Partition ID. These are
sequential numeric values which were used when creating the system
partitions. You can also obtain these values by running the Galaxy
Configuration Utility via $ CONFIG GALAXY command.
Enter a HARD PARTITION Number (range 0-7): 0
The SOFT PARTITION NUMBER is a numeric value that uniquely identifies
which SOFT Partition a GCM-Server resides within. If a system has
only a single SOFT Partition, enter 0. If a system has multiple
SOFT Partitions, use the appropriate Soft Partition ID. These are
sequential numeric values which were used when creating the system
partitions. You can also obtain these values by running the Galaxy
Configuration Utility via $ CONFIG GALAXY command.
Enter a SOFT PARTITION Number (range 0-7): 0
%Define additional system records as needed...
Enter a fully qualified name for the system running a GCM-Server.
For example: star.zko.hp.com. When you are done entering system
records, enter 0 at the following prompt.
Enter a SYSTEM Name (ex: star.zko.hp.com) (RETURN when done): wfglx5.zko.hp.com
Enter a fully qualified IP Address for the system running a
GCM-Server. For example: 16.32.112.16
If you prefer to use DNS to lookup the address, enter 0
Enter a System IP Address (0 to use DNS): 16.32.112.17
The SYSTEM NUMBER is a simple numeric value that uniquely identifies
soft and hard partitions that reside in a common partitionable
computer. For example, if you have two separate partitionable
computers in your Association, each having its own hard and soft
partitioned instances, enter a SYSTEM NUMBER of 0 for all hard and
soft partitions in the first computer, and enter 1 for those in the
second computer.
Enter a System Number (range 0-7): 0
The HARD PARTITION NUMBER is a numeric value that uniquely identifies
which HARD Partition a GCM-Server resides within. If a system has
only a single HARD Partition, enter 0. If a system has multiple
HARD Partitions, use the appropriate Hard Partition ID. These are
sequential numeric values which were used when creating the system
partitions. You can also obtain these values by running the Galaxy
Configuration Utility via $ CONFIG GALAXY command.
Enter a HARD PARTITION Number (range 0-7): 0
The SOFT PARTITION NUMBER is a numeric value that uniquely identifies
which SOFT Partition a GCM-Server resides within. If a system has
only a single SOFT Partition, enter 0. If a system has multiple
SOFT Partitions, use the appropriate Soft Partition ID. These are
sequential numeric values which were used when creating the system
partitions. You can also obtain these values by running the Galaxy
Configuration Utility via $ CONFIG GALAXY command.
Enter a SOFT PARTITION Number (range 0-7): 1
%Define additional system records as needed...
Enter a fully qualified name for the system running a GCM-Server.
For example: star.zko.hp.com. When you are done entering system
records, enter 0 at the following prompt.
Enter a SYSTEM Name (ex: star.zko.hp.com) (RETURN when done):
CLIENT AUTHORIZATION RECORDS:
At least one client must be defined in order to allow an initial
client-server connection to be established. Additional clients may
be defined now, or at any point using the client application and the
GCM Subscription Procedure. This initial client record must provide
fully privileged access for the specified user so that subsequent
GCM administration functions can be performed.
Enter a string which describes this client.
The string can be the users full name, or job title, etc.
Enter Client’s Full Name or Title (RETURN when done): First Last
Enter the clients USER name. This is a single word that identifies
the user, such as their last name.
Enter Client’s Username: First
Enter the clients PASSWORD. This is a unique GCM password,
unrelated to any system authorization function.
Note: Passwords can be changed by any GCM-Client with Admin privilege.
Enter initial Password for First: Last
Enter the clients EMAIL Address. This is particularly important
for the client that is serving the role of GCM Administrator as
they will receive email subscription requests.
Enter EMAIL Address for First: First.Last@hp.com
CONFIG privilege allows a user to issue commands that alter a system
configuration (if they also have the COMMAND privilege) and to load
and save configuration models.
Give First CONFIG Privilege (Y/N) {Y}? y
COMMAND privilege allows a user to issue DCL commands.
Give First COMMAND Privilege (Y/N) {Y}? y
USER-COMMAND privilege allows a user to create their own command
menu entries. Commands are executed in a privileged context so
use discretion when authorizing this privilege.
Give First USER-COMMAND Privilege (Y/N) {Y}? y
POWER privilege allows a user to issue commands that power on or off
system components for systems that support such operations.
Give First POWER Privilege (Y/N) {Y}? y
ADMIN privilege allows a user to modify the GCM-Server Administration
Database. Use discretion when authorizing this privilege.
Give First ADMIN Privilege (Y/N) {Y}? y
You may choose to ENABLE this client immediately, or enable the
client later once the GCM is fully configured.
IMPORTANT: Be sure to enable the initial administrator client!
Enable First account now (Y/N) {Y}? y
%Define additional client records as needed...
Enter a string which describes this client.
The string can be the users full name, or job title, etc.
Enter Client’s Full Name or Title (RETURN when done):
SERVER STARTUP OPTIONS:
You may choose to have the local GCM-Server started automatically upon
system boot. If you choose this option, the server will be started
during the next system boot. To accomplish this, the startup file
SYS$STARTUP:GCMSRV$STARTUP.COM will be added to the Layered Product
startup database.
Do you want the local GCM-SERVER to start on System Boot (Y/N) {Y}? y
You may choose to start the local GCM-Server now, or you can start
it later via $@SYS$STARTUP:GCMSRV$STARTUP.COM
Do you want to start the local GCM-SERVER now (Y/N) {Y}? y
************************ POST SETUP TASKS **************************
This completes the GCM Admin Database initialization.
IMPORTANT:
If you are using multiple GCM-Servers, copy the newly created GCM
Admin Database file: SYS$COMMON:[SYS$CONFIG]GCM_ADMIN.EDB, to the
same location on each system you defined in the Association, then
start or restart each server via $ @SYS$STARTUP:GCMSRV$STARTUP.COM
If the database has been properly defined, each server will detect
the presence of the other servers and form the specified Association.
If the GCM_SERVER process fails to start, examine the server logfile
SYS$COMMON:[SYS$CONFIG]GCM_SERVER.LOG.
When the server has started, you may use the GCM-Client to establish
a connection and further tune the installation.
For maximum security, you may wish to protect or remove this utility.
$
$ STOP/CPU/MIGRATE=instance-or-id cpu-id
$ STOP/CPU/MIGRATE=0 4 !Reassign CPU 4 to instance 0 $ STOP/CPU/MIGRATE=1 3,4,5 !Reassign CPUs 3,4,5 to instance 1 $ STOP/CPU 7/MIGRATE=BIGBNG !ReassignCPU 7 to instance BIGBNG $ STOP/CPU/ALL/MIGRATE=0 !Reassign all secondary CPUs to instance 0
Command |
Qualifier |
Description |
|---|---|---|
SET
CPU |
/[NO]AUTO_START |
Sets
or clears the instance-specific autostart flag for the specified CPUs. |
/[NO]FAILOVER |
Defines
or removes any instance-specific failover relationship for the specified CPUs. |
|
/MIGRATE |
Transfers
ownership of the CPU from the current instance to another soft partition. |
|
/POWER |
Turns
the power on or off in one or more CPU slots. Valid options are ON and OFF. |
|
/REFRESH |
Examines
and updates the OpenVMS context for the specified CPU or CPUs, using the hardware
configuration tree. |
|
/OVERRIDE_CHECKS |
Bypasses
the series of checks that determine whether the specified processor is eligible
for removal if the SET CPU command is being used to remove the CPU from the
active set. |
|
/START |
Initiates
a request for the specified CPU to join the OpenVMS active set if it is not
already there. |
|
SHOW
CPU |
/ACTIVE_SET |
Selects
as the subject of the display only those processors that are members of the
system’s active set. |
/CONFIGURE_SET |
Selects
as the subject of the display only those processors that are members of the
system’s configure set - those that are actively owned and controlled
by the current instance. |
|
/POTENTIAL_SET |
Selects
as the subject of the display only those processors that are members of the
system’s potential set - those CPUs in the hard partition that meet
the current instance’s requirements to join its active set. Inclusion
in this set does not imply that the CPU is (or ever will be) owned by the
current instance. The potential set only describes those physically existing
CPUs that currently meet the instance-specific hardware and software compatibility
constraints, should they ever become available. |
|
/STANDBY_SET |
Selects
as the subject of the display only those processors that are members of the
system’s standby set - those CPUs in the hard partition that are not
currently owned by soft partitions and may be available for ownership by the
current instance. |
|
/SYSTEM |
Displays
platform-specific hardware information relating to the current instance. |
|
START/CPU |
/POWER[=ON] |
Powers
on the CPU prior to bringing the CPU into the active set. |
STOP/CPU |
/MIGRATE |
Transfers
ownership of the CPU from the current instance to another soft partition. |
/POWER=OFF |
Powers
down the CPU after it is removed from the active set. |
Command |
Description |
|---|---|
INITIALIZE/RAD=n |
Specifies
the RAD number on which to run batch jobs assigned to the queue. |
SET
ENTRY/RAD=n |
Specifies
the RAD number on which the submitted batch job is to execute. |
SET
PROCESS/RAD=HOME=n |
Changes
the home RAD of a process. |
SET
QUEUE/RAD=n |
Specifies
the RAD number on which to run batch jobs assigned to the queue. |
SHOW
PROCESS/RAD |
Displays
the home RAD. |
START
QUEUE/RAD=n |
Specifies
the RAD number on which to run batch jobs assigned to the queue. |
SUBMIT/RAD=n |
Specifies
the RAD number on which the submitted batch job is to execute. |
Command |
Description |
|---|---|
CONFIGURE
GALAXY |
Invokes
the Galaxy Configuration Utility (GCU) to monitor, display, and interact with
an OpenVMS Galaxy system. |
INSTALL/LIST |
Returns
the Galaxywide sections as well as the standard global sections. |
SHOW
MEMORY/PHYSICAL |
Displays
the uses of memory by the system. |
Item
Code |
Type |
Description |
|---|---|---|
GLX_MAX_MEMBERS |
Integer |
Returns
the maximum count of instances that may join the current Galaxy configuration. |
GLX_FORMATION |
String |
Returns
a time-stamp string when the Galaxy configuration, of which this instance
is a member, was created. |
GLX_TERMINATION |
String |
Returns
a time-stamp string when the Galaxy configuration, of which this instance
last was a member, was terminated. |
GLX_MBR_NAME |
String |
Returns
a string indicating the names which are known in the Galaxy membership. |
GLX_MBR_MEMBER |
Integer |
Returns
a 64-byte integer. Each 8 bytes represents a Galaxy member, listed from 7
to 0. The value is 1 if the instance is currently a member, 0 if not a member. |
Item
Code |
Type |
Description |
|---|---|---|
HP_ACTIVE_CPU_CNT |
Integer |
Returns
the count of CPUs in the hard partition that are not currently in firmware
console mode. For OpenVMS this implies that the CPU is in, or in the process
of joining, the active set in one of the instances in the hard partition. |
HP_ACTIVE_SP_CNT |
Integer |
Returns
the count of active operating system instances currently executing within
the hard partition. |
HP_CONFIG_SP_CNT |
Integer |
Returns
the maximum count of soft partitions within the current hard partition. This
count does not imply that an operating system instance is currently running
within any given soft partition. |
HP_CONFIG_SBB_CNT |
Integer |
Returns
a count of the existing system building blocks within the current hard partition. |
Item
Code |
Type |
Description |
|---|---|---|
ACTIVE_CPU_MASK |
Integer |
Returns
a value that represents a CPU-indexed bitvector. When a particular bit position
is set, the processor with that CPU ID value is a member of the instance’s
active set - those currently participating in the OpenVMS SMP scheduling activities. |
AVAIL_CPU_MASK |
Integer |
Returns
a value that represents a CPU-indexed bitvector. When a particular bit position
is set, the processor with that CPU ID value is a member of the instance’s
configure set - those owned by the partition and controlled by the issuing
instance. |
POTENTIAL_CPU_MASK |
Integer |
Returns
a value that represents a CPU-indexed bitvector. When a particular bit position
is set, the processor with that CPU ID value is a member of the instance’s
potential set. A CPU in the potential set implies that it could actively
join the VMS active set for this instance if it is ever owned by it. To meet
this rule the CPU’s characteristics must match hardware and software
compatibility rules defined particularly for that instance. |
POWERED_CPU_MASK |
Integer |
Returns
a value that represents a CPU-indexed bitvector. When a particular bit position
is set, the processor with that CPU ID value is a member of the instance’s
powered set - those CPUs physically existing within the hard partition and
powered up for operation. |
PRESENT_CPU_MASK |
Integer |
Returns
a value that represents a CPU-indexed bitvector. When a particular bit position
is set, the processor with that CPU ID value is a member of the instance’s
present set - those CPUS physically existing within the hard partition. |
CPUCAP_MASK |
String |
Returns
a list of hexadecimal values, separated by commas and indexed by CPU ID.
Each individual value represents a bitvector; when set, the corresponding
user capability is enabled for that CPU. |
PRIMARY_CPUID |
Integer |
Returns
the CPU ID of the primary processor for this OpenVMS instance. |
MAX_CPUS |
Integer |
Returns
the maximum number of CPUs that could be recognized by this instance. |
CPU_AUTOSTART |
Integer |
Returns
a list of zeroes and ones, separated by commands and indexed by CPU ID. Any
entry with a value of one indicates that specific CPU will be brought into
the VMS active set if it transitions into the current instance from outside,
or is powered up while already owned. |
CPU_FAILOVER |
Integer |
Returns
list of numeric partition IDs, separated by commas and indexed by CPU ID,
that define the destination of the processor if the current instance should
crash. |
POTENTIALCPU_CNT |
Integer |
The
count of CPUs in the hard partition that are members of the potential set
for this instance. A CPU in the potential set implies that it could actively
join the VMS active set for this instance if it is ever owned by it. To meet
this rule the CPU’s characteristics must match hardware and software
compatibility rules defined particularly for that instance. |
PRESENTCPU_CNT |
Integer |
The
count of CPUs in the hard partition that physically reside in a hardware slot. |
POWEREDCPU_CNT |
Integer |
The
count of CPUs in the hard partition that are physically powered up. |
Item
Code |
Type |
Description |
|---|---|---|
HOME_RAD |
Integer |
Home
resource affinity domain (RAD). |
Item
Code |
Type |
Description |
|---|---|---|
RAD_CPUS |
Integer |
Returns
list of RAD,CPU pairs, separated by commas. |
RAD_MEMSIZE |
Integer |
Returns
list of RAD,PAGES pairs, separated by commas. |
RAD_MAX_RADS |
Integer |
Returns
the maximum number of RADS possible on this platform. The value is always
8 (regardless of number of quad building blocks (QBBs) physically present). |
RAD_SHMEMSIZE |
Integer |
Returns
list of RAD,PAGES pairs, separated by commas. |
$ STOP/CPU/MIGRATE=GLXSYS 4
%SYSTEM-I-CPUSTOPPING, trying to stop CPU 4 after it reaches quiescent state
%SMP-I-STOPPED, CPU #04 has been stopped.
%SMP-I-SECMSG, CPU #04 message: P04>>>START %SMP-I-CPUTRN, CPU #04 has joined the active set.
$ show cpu
System: GLXSYS, Compaq AlphaServer GS320 6/731
CPU ownership sets:
Active 0-31
Configure 0-31
CPU state sets:
Potential 0-31
Autostart 0-31
Powered Down None
Failover None
$ show cpu/system
System: GLXSYS, Compaq AlphaServer GS320 6/731
SMP execlet = 2 : Enabled : Full checking.
Config tree = Version 6
Primary CPU = 0
HWRPB CPUs = 32
Page Size = 8192
Revision Code =
Serial Number = BUDATEST
Default CPU Capabilities:
System: QUORUM RUN
Default Process Capabilities:
System: QUORUM RUN
CPU ownership sets:
Active 0-31
Configure 0-31
CPU state sets:
Potential 0-31
Autostart 0-31
Powered Down None
Failover None$ SHOW MEMORY/PHYSICAL
System Memory Resources on 5-OCT-2001 20:50:19.03
Physical Memory Usage (pages): Total Free In Use Modified
Main Memory (2048.00Mb) 262144 228183 31494 2467
Of the physical pages in use, 11556 pages are permanently allocated to OpenVMS.
$ SHOW MEMORY/PHYSICAL
System Memory Resources on 5-OCT-2001 07:55:14.68
Physical Memory Usage (pages): Total Free In Use Modified
Private Memory (512.00Mb) 65536 56146 8875 515
Shared Memory (1024.00Mb) 131072 130344 728
Of the physical pages in use, 6421 pages are permanently allocated to OpenVMS.
$$ create shoglx.com
$ write sys$output ""$ write sys$output "Instance = ",f$getsyi("scsnode")
$ write sys$output "Platform = ",f$getsyi("galaxy_platform")
$ write sys$output "Sharing Member = ",f$getsyi("galaxy_member")
$ write sys$output "Galaxy ID = ",f$getsyi("galaxy_id")
$ write sys$output "Community ID = ",f$getsyi("community_id")
$ write sys$output "Partition ID = ",f$getsyi("partition_id")
$ write sys$output ""$ exit
$ ^Z$ @SHOGLX Instance = COBRA2 Platform = 1 Sharing Member = 1 Galaxy ID = 5F5F30584C47018011D3CC8580F40383 Community ID = 0 Partition ID = 0 $
GALAXY [model.GCM]
$ CONFIGURE GALAXY
$ CONFIGURE GALAXY model.GCM
$ CONFIGURE GALAXY/ENGAGE model.GCM
$ CONFIGURE GALAXY/ENGAGE/VIEW model.GCM
MILKY WAY
PBA0: PBA1:
PBA1: <-------> PBA0:$ MCR SYMAN SYSMAN> CONFIGURATION SHOW CLUSTER_AUTHORIZATION Node: MILKY Cluster group number: 0 Multicast address: xx-xx-xx-xx-xx-xx SYSMAN>
$ MCR SYSMAN SYSMAN> CONFIGURATION SET CLUSTER_AUTHORIZATION/GROUP_NUMBER=222/PASSWORD=xxxx SYSMAN>
Bit |
Mask |
Description |
|---|---|---|
0 |
0 |
0
= Do not create local communications channels (SYSGEN default). Local SCS
communications are primarily used in test situations and not needed for normal
operations. Leaving this bit off saves resources and overhead. 1 = Create local communications channels. |
1 |
2 |
0
= Load SYS$PBDRIVER if booting into both a Galaxy and a Cluster (SYSGEN Default). 1 = Load SYS$PBDRIVER if booting into a Galaxy. |
2 |
4 |
0
= Minimal console output (SYSGEN default) 1 = Full console output, SYS$PBDRIVER displays console messages when creating communication channels and tearing down communication channels. |
$ MCR SYSMAN SYSMAN> IO CONN EBA/DRIVER=SYS$EBDRIVER/NOADAPTER
Shared
Page Tables |
Read
Only |
Read
and Write |
|---|---|---|
None
created |
Do
not set the SEC$M_WRT flag in the map request. Private page tables
are always used, even if you specify a shared page table region into which
to map the section. |
Set
the SEC$M_WRT flag in the map request. Private page tables are used, even if you specify
a shared page table region into which to map the section. |
Write
access |
Do
not set the SEC$M_WRT flag in the map request. Ensure that private
page tables are used. Do not specify a shared page table region into which
to map the section. If you do, the error status SS$_IVSECFLG is returned. |
Set
the SEC$M_WRT flag in the map request. The shared page table section is used for mapping
if you specify a shared page table region into which to map the section. |
Read
access |
Do
not set the SEC$M_WRT flag in the map request. The shared page table section
is used for mapping if you specify a shared page table region into which to
map the section. |
Set
the SEC$M_WRT flag in the map request. Ensure that private page tables is
used. Do not specify a shared page table region into which to map the section.
If you do, the error status SS$_IVSECFLG is returned. |
NotesStatus
Code |
Description |
|---|---|
SS$_INV_SHMEM |
Shared
memory is not valid. |
SS$_INSFRPGS |
Insufficient
free shared pages or private pages. |
SS$_NOBREAK |
A
Galaxy lock is held by another node and was not broken. |
SS$_LOCK_TIMEOUT |
A
Galaxy lock timed out. |
[47] |
(only
for group global sections) Identifies the UIC group of the section creator. |
WAY____D99DDB03_0$ |
An
identifier for the sharing community. |
MY_SECTION |
The
name of the section as specified by the user. |
Object
class name: |
GLXSYS_GLOBAL_SECTION |
Object
name: |
WAY____D99DDB03_0$SYSTEM_SECTION |
Important
Security Notes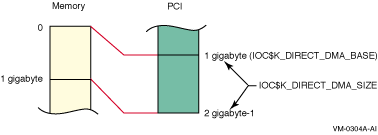
Code |
Description |
|---|---|
IOC$K_DIRECT_DMA_BASE |
This
is the base address on the PCI side, or bus address. There is a synonym for
this function code called IOC$K_DDMA_BASE_BA. A 32-bit result will be returned. |
IOC$DIRECT_DMA_SIZE |
On
non-Galaxy machines, this returns the size of the direct-mapped DMA window
(in megabytes). On a system where the direct-mapped DMA window does not start
at zero, the data returned is zero, implying that no direct-mapped DMA windows
exist. A 32-bit result will be returned. |
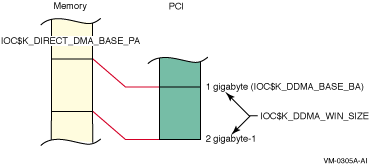
IOC$K_DDMA_WIN_SIZE |
On
all systems, this will always return the size of the direct-mapped DMA window
(in megabytes). A 32-bit result will be returned. |
IOC$K_DIRECT_DMA_BASE_PA |
This
is the base physical address in memory of the direct-mapped DMA window. A
32-bit result will be returned. |
Service |
Description |
|---|---|
SYS$CPU_TRANSITION |
CPU
reassignment |
SYS$CRMPSC_GDZRO_64 |
Shared
memory creation |
SYS$SET_SYSTEM_EVENT |
OpenVMS
Galaxy event notification |
SYS$*_GALAXY_LOCK_* |
OpenVMS
Galaxy locking |
$ CC GCU$BALANCER.C+SYS$LIBRARY:SYS$LIB_C/LIBRARY $ LINK/SYSEXE GCU$BALANCER
$ SET COMMAND/TABLE=SYS$LIBRARY:DCLTABLES - _$ /OUT=SYS$COMMON:[SYSLIB]DCLTABLES GCU$BALANCER.CLD
$ INSTALL REPLACE SYS$COMMON:[SYSLIB]DCLTABLES.EXE
$ SET COMMAND GCU$BALANCER.CLD
$ CONFIG BAL 3 1 00:00:05.00
$ CONFIGURE GALAXY
** SYSHUTDWN.COM EXAMPLE - Paste into SYS$MANAGER:SYSHUTDWN.COM
**
** $!
** $! If the GCU$BALANCER image is running, stop it to release shmem.
** $!
** $ procctx = f$context("process",ctx,"prcnam","GCU$BALANCER","eql")
** $ procid = f$pid(ctx)
** $ if procid .NES. "" then $ stop/id=’procid’1
MB |
0x
10 0000 |
2
MB |
0x
20 0000 |
4
MB |
0x
40 0000 |
8
MB |
0x
80 0000 |
16
MB |
0x
100 0000 |
32
MB |
0x
200 0000 |
64
MB |
0x
400 0000 |
128
MB |
0x
800 0000 |
256
MB |
0x
1000 0000 |
448
MB |
0x1C00
0000 |
512
MB |
0x
2000 0000 |
1
GB |
0x
4000 0000 |
2
GB |
0x
8000 0000 |
4
GB |
0x
1 0000 0000 |
8
GB |
0x
2 0000 0000 |
16
GB |
0x
4 0000 0000 |
32
GB |
0x
8 0000 0000 |
64
GB |
0x
10 0000 0000 |
128
GB |
0x
20 0000 0000 |
256
GB |
0x
40 0000 0000 |
512
GB |
0x
80 0000 0000 |
1
TB |
0x
100 0000 0000 |
|
|
| privacy and legal statement | ||
| 6512PRO.HTML | ||