C
MDMS Messages
ABORT
request aborted by operator
Explanation: The request issued an OPCOM message that has been aborted by an operator. This message can also occur if no terminals are enabled for the relevant OPCOM classes on the node.
User Action: Either nothing or enable an OPCOM terminal, contact the operator and retry.
ACCCTRLONLY
updated access control only
Explanation: You entered a SET command and you only had CONTROL access to the object, so only the access control information (if any) was updated.
User Action: If this is what was intended no action is needed. If you wish to update other fields in the object, you require SET access control. See your administrator.
ACCVIO
access violation
Explanation:
The MDMS software caused an access violation. This is an internal error.
User Action:
Provide copies of the MDMS command issued, the database files and the server's logfile for further analysis.
ALLOCDRIVE
drive !AD allocated
Explanation:
The named drive was successfully allocated.
User Action:
None.
ALLOCDRIVEDEV
drive !AD allocated as device !AD
Explanation:
The named drive was successfully allocated, and the drive may be accessed with DCL commands using the device name shown.
User Action:
None.
ALLOCVOLUME
volume !AD allocated
Explanation:
The named volume was successfully allocated.
User Action:
None.
ALTSUCCESS
alternative success
Explanation:
The request was successful, but extended status contains information.
User Action:
Examine the extended status, and retry command as needed.
APIBUGCHECK
internal inconsistency in API
Explanation:
The MDMS API (MDMS$SHR.EXE) detected an inconsistency. This is an internal error.
User Action:
Provide copies of the MDMS command issued, the database files and the server's logfile for further analysis.
APIUNEXP
unexpected error in API !AZ line !UL
Explanation:
The shareable image MDMS$SHR detected an internal inconsistency.
User Action:
Provide copies of the MDMS command issued, the database files and the server's logfile for further analysis.
ARCUNDEFINED
referenced archive(s) !AZ undefined
Explanation:
When creating or modifying a valid object, the object's record contains a reference to a archive name that does not exist. One or more of the specified archives may be undefined.
User Action:
Check spelling of the archive names and retry, or create the archive objects in the database.
ATTRINMAG
onsite/offsite attributes invalid for magazine-based volumes
Explanation:
You attempted to specify offsite or onsite dates or locations for a volume whose placement is in a magazine. These attributes are controlled by the magazine and are not valid for individual volumes.
User Action:
Specify the dates and locations in the magazine object, or do not use magazines for volumes if you want the individual offsite/onsite dates to be different for each volume.
BINDVOLUME
volume !AD bound to set !AD
Explanation:
The specified volume (or volume set) was successfully bound to the end of the named volume set.
User Action:
None.
BUGCHECK
internal inconsistency
Explanation:
The server software detected an inconsistency. This is an internal error.
User Action:
Provide copies of the MDMS command issued, the database files and the server's logfile for further analysis. Restart the server.
CANCELLED
request cancelled by user
Explanation:
The request was cancelled by a user issuing a cancel request command.
User Action:
None, or retry command.
CLEANVOL
cleaning volume loaded
Explanation:
During a load of a volume, a cleaning volume was loaded.
User Action:
During an inventory this message can be ignored. During a load of a requested volume or a scratch load on a drive, or an initialize command, a cleaning volumes was loaded. Check location of the cleaning volume, update database as needed, and re-issue command using a non-cleaning volume.
CONFLITEMS
conflicting item codes specified
Explanation:
The command cannot be completed because there are conflicting item codes in the command. This is an internal error.
User Action:
Provide copies of the MDMS command issued, the database files and the server's logfile for further analysis.
CREATVOLUME
volume !AD created
Explanation:
The named volume was successfully created.
User Action:
None.
DBLOCACC
local access to database
Explanation:
This node has the database files open locally.
User Action:
None.
DBRECERR
error !AZ !AZ record for !AZ:
Explanation:
The search for a database server received an error from a remote server.
User Action:
Check the logfile on the remote server for more information. Check the logical name MDMS$DATABASE_SERVERS for correct entries of database server node.
DBREMACC
access to remote database server on node !AZ
Explanation:
This node has access to a remote database server.
User Action:
None.
DBREP
Database server on node !AZ reports:
Explanation:
The remote database server has reported an error condition. The next line contains additional information.
User Action:
Depends on the additional information.
DCLARGLSOVR
DCL extended status format, argument list overflow
Explanation:
During formating of the extended status, the number of arguments exceeded the allowable limit. This is an internal error.
User Action:
Provide copies of the MDMS command issued, the database files and the server's logfile for further analysis.
DCLBUGCHECK
internal inconsistency in DCL
Explanation:
The MDMS comand line software (MDMS$DCL.EXE) detected an inconsistency. This is an internal error.
User Action:
Provide copies of the MDMS command issued, the database files and the server's logfile for further analysis.
DCSCERROR
error accessing jukebox with DCSC
Explanation:
MDMS encountered an error when performing a jukebox operation. An accompanying message gives more detail.
User Action:
Examine the accompanying message and perform corrective actions to the hardware, the volume or the database, and optionally retry the operation.
DCSCMSG
!AZ
Explanation:
This is a more detailed DCSC error message which accompanies DCSCERROR.
User Action:
Check the DCSC error message file.
DECNETLISEXIT
DECnet listener exited
Explanation:
The DECnet listener has exited due to an internal error condition or because the user has disabled the DECNET transport for this node. The DECnet listener is the server's routine to receive requests via DECnet (Phase IV and Phase V).
User Action:
The DECnet listener should be automatically restarted unless the DECNET transport has been disabled for this node. Provide copies of the MDMS command issued, the database files and the server's logfile for further analysis if the transport has not been disabled by the user.
DECNETLISRUN
listening on DECnet node !AZ object !AZ
Explanation:
The server has successfully started a DECnet listener. Requests can now be sent to the server via DECnet.
User Action:
None.
DEVNAMICM
device name item code missing
Explanation:
During the allocation of a drive, the drive name was not returned by the server. This is an internal error.
User Action:
Provide copies of the MDMS command issued, the database files and the server's logfile for further analysis.
DRIVEEXISTS
specified drive already exists
Explanation:
The specified drive already exists and cannot be be created.
User Action:
Use a set command to modify the drive, or create a new drive with a different name.
DRVACCERR
error accessing drive
Explanation:
MDMS could not access the drive.
User Action:
Verify the VMS device name, node names and/or group names specified in the drive record. Fix if necessary. Verify MDMS is running on a remote node. Check status of the drive, correct and retry.
DRVALRALLOC
drive is already allocated
Explanation:
An attempt was made to allocate a drive that was already allocated.
User Action:
Wait for the drive to become deallocated, or if the drive is allocated to you, use it.
DRVEMPTY
drive is empty or volume in drive is unloaded
Explanation: The specified drive is empty, or the volume in the drive is unloaded, spun-down and inaccessible.
User Action:
Check status of drive, correct and retry.
DRVINITERR
error initializing drive on platform
Explanation:
MDMS could not initialize a volume in a drive.
User Action:
There was a system error initializing the volume. Check the log file.
DRVINUSE
drive is currently in use
Explanation:
The specified drive is already in use.
User Action:
Wait for the drive to free up and re-enter command, or try to use another drive.
DRVLOADED
drive is already loaded
Explanation:
A drive unload appeared to succeed, but the specified volume was still detected in the drive.
User Action:
Check the drive and check for duplicate volume labels, or if the volume was reloaded.
DRVLOADING
drive is currently being loaded or unloaded
Explanation:
The operation cannot be performed because the drive is being loaded or unloaded.
User Action:
Wait for the drive to become available, or use another drive. If the drive is stuck in the loading or unloading state, check for an outstanding request on the drive and cancel it. If all else fails, manually adjust the drive state.
DRVNOTALLOC
drive is not allocated
Explanation:
The specified drive could not be allocated.
User Action:
Check again if the drive is allocated. If it is, wait until it is deallocated. Otherwise there was some other reason the drive could not be allocated. Check the log file.
DRVNOTALLUSER
drive is not allocated to user
Explanation:
You cannot perform the operation on the drive because the drive is not allocated to you.
User Action:
Either defer the operation or (in some cases) you may be able to perform the operation specifying a user name.
DRVNOTAVAIL
drive is not available on system
Explanation:
The specified drive was found on the system, but is not available for use.
User Action:
Check the status of the drive and correct.
DRVNOTDEALLOC
drive was not deallocated
Explanation:
MDMS could not deallocate a drive.
User Action:
Either the drive was not allocated or there was a system error deallocating the drive. Check the log file.
DRVNOTFOUND
drive not found on system
Explanation:
The specified drive cannot be found on the system.
User Action:
Check that the OpenVMS device name, node names and/or group names are correct for the drive. Verify MDMS is running on a remote node. Re-enter command when corrected.
DRVNOTSPEC
drive not specified or allocated to volume
Explanation:
When loading a volume a drive was not specified, and no drive has been allocated to the volume.
User Action:
Retry the operation and specify a drive name.
DRVREMOTE
drive is remote
Explanation:
The specified drive is remote on a node where it is defined to be local.
User Action:
Check that the OpenVMS device name, node names and/or group names are correct for the drive. Verify MDMS is running on a remote node. Re-enter command when corrected.
DRVSINUSE
all drives are currently in use
Explanation:
All of the drives matching the selection criteria are currently in use.
User Action:
Wait for a drive to free up and re-enter command.
DRVUNDEFINED
referenced drive !AZ undefined
Explanation:
When creating or modifying a valid object, the object's record contains a reference to a drive name that does not exist.
User Action:
Check spelling of the drive name and retry, or create the drive object in the database.
ENVUNDEFINED
referenced environment(s) !AZ undefined
Explanation:
When creating or modifying a valid object, the object's record contains a reference to a environment name that does not exist. One or more of the specified environments may be undefined.
User Action:
Check spelling of the environment names and retry, or create the environment objects in the database.
ERROR
error
Explanation:
A general internal MDMS error occurred.
User Action:
Provide copies of the MDMS command issued, the database files and the server's logfile for further analysis.
EXECOMFAIL
execute command failed, see log file for more explanation
Explanation:
While trying to execute a command during scheduled activities, a system service called failed.
User Action:
Check the log file for the failure code from the system server call.
EXIT
MDMS server exiting with fatal error, restarting
Explanation:
The MDMS server has encountered a fatal error and is exiting. The server will be restarted.
User Action:
Report incident to hp.
EXSCHED
internal schedules are inoperable; external scheduler in use
Explanation:
You have created or modified an MDMS schedule object. This is allowed, but since the domain scheduler type is set up to an external scheduler product, this schedule object will never be executed.
User Action:
If you are not planning ot change the scheduler type to INTERNAL or EXTERNAL, you should modify the associated save or restore request to use a standard frequency or an explicit frequency.
EXTRAVOL
extra volume(s) processed
Explanation:
One or more volumes unknown to MDMS have been processed by this command.
User Action:
See next message line(s) for more details. Use MDMS or jukebox utility programs (MRU or CARTRIDGE) to correct the problem.
FAILALLOCDRV
failed to allocate drive
Explanation:
Failed to allocate drive.
User Action:
The previous message is the error that caused the failure.
FAILCONSVR
failed connection to server
Explanation:
The connection to an MDMS server either failed or could not be established. See additional message lines and/or check the server's logfile.
User Action:
Depends on additional information.
FAILCONSVRD
failed connection to server via DECnet
Explanation:
The DECnet connection to an MDMS server either failed or could not be established. See additional message lines and/or check the server's logfile.
User Action:
Depends on additional information.
FAILCONSVRT
failed connection to server via TCP/IP
Explanation:
The TCP/IP connection to an MDMS server either failed or could not be established. See additional message lines and/or check the server's logfile.
User Action:
Depends on additional information.
FAILCREATE
failed to create !AZ
Explanation:
The reported file or object could not be created. The next line contains additional information.
User Action:
Depends on the additional information.
FAILDEALLOCDRV
failed to deallocate drive
Explanation:
Failed to deallocate drive.
User Action:
The previous message is the error that caused the failure.
FAILDELETE
failed to delete !AZ
Explanation:
The reported file or object could not be deleted. The next line contains additional information.
User Action:
Depends on the additional information.
FAILEDMNTVOL
failed to mount volume
Explanation:
MDMS was unable to mount the volume.
User Action:
The error above this contains the error that cause the volume not to be mounted.
FAILICRES
failed item code restrictions
Explanation:
The command cannot be completed because there are conflicting item codes in the command. This is an internal error.
User Action:
Provide copies of the MDMS command issued, the database files and the server's logfile for further analysis.
FAILINIEXTSTAT
failed to initialize extended status buffer
Explanation:
The API could not initialze the extended status buffer. This is an internal error.
User Action:
Provide copies of the MDMS command issued, the database files and the server's logfile for further analysis.
FAILLOOKUP
failed to lookup !AZ
Explanation:
The reported file or object could not be looked up. The next line contains additional information.
User Action:
Depends on the additional information.
FAILURE
fatal error
Explanation:
The MDMS server encountered a fatal error during the processing of a request.
User Action:
Provide copies of the MDMS command issued, the database files and the server's logfile for further analysis.
FILOPNERR
file !AZ could not be opened
Explanation:
An MDMS database file could not be opened.
User Action:
Check the server's logfile for more information.
FIRSTVOLUME
specified volume is first in set
Explanation:
The specified volume is the first volume in a volume set.
User Action:
You cannot deallocate or unbind the first volume in a volume set. However, you can unbind the second volume and then deallocate the first, or unbind and deallocate the entire volume set.
FUNCFAILED
Function !AZ failed with:
Explanation:
An internal call to a system function has failed. The following lines identify the function called and the failure status.
User Action:
Depends on information following this message.
GRPUNDEFINED
referenced group(s) !AZ undefined
Explanation:
When creating or modifying a valid object, the object's record contains a reference to a group name that does not exist. One or more of the specified groups may be undefined.
User Action:
Check spelling of the group names and retry, or create the group objects in the database.
ILLEGALOP
illegal move operation
Explanation:
You attempted to move a volume within a DCSC jukebox, and this is not supported.
User Action:
None.
INCOMFREQ
incompatible frequency for !AZ !AZ
Explanation:
After changing the domain scheduler type, MDMS has detemined that this save or restore request has a frequency that is incompatible with the new scheduler type. The frequencies that are not valid for the given scheduler types are:
-
INTERNAL and EXTERNAL: Explicit
-
DECSCHEDULER and SCHEDULER: Custom
User Action:
Modify the frequency to a valid one for this scheduler type.
INCOMPATMED
volume's media type incompatible with the drive
Explanation:
The media type for the volume is incompatible with the media type(s) for the drive on a load operation.
User Action:
Verify that the volume can be physically loaded and used in the specified drive. If not, select another drive. If so, then add the volume's media type to the drive or otherwise aligned the media types of the volume and the drive.
INCOMPATOPT
incompatible options specified
Explanation:
You entered a command with incompatible options.
User Action:
Examine the command documentation and re-enter with allowed combinations of options.
INCOMPATTR
attributes incompatible with archive type
Explanation:
You attempted to create or set an attribute which is incompatible with the archive type. The following attributes are incompatible for archive types:
-
DISK: CONSOLIDATION, DRIVES, MEDIA_TYPE, POOL, VOLUME_SETS
-
TAPE: DESTINATION
User Action:
Do not specify these attributes if they are incompatible with the archive type.
INCOMPATVOL
volume is incompatible with volumes in set
Explanation:
You cannot bind the volume to the volume set because some of the volume's attributes are incompatible with the volumes in the volume set.
User Action:
Check that the new volume's media type, onsite location and offsite location are compatible with those in the volume set. Adjust attributes and retry, or use another volume with compatible attributes.
INSCMDPRIV
insufficient privilege to execute request
Explanation:
You do not have sufficient privileges to enter the request.
User Action:
Contact your system administrator and request additional privileges, or give yourself privs and retry.
INSOPTPRIV
insufficient privilege for request option
Explanation:
You do not have sufficient privileges to enter a privileged option of this request.
User Action:
Contact your system administrator and request additional privileges, or give yourself privs and retry. Alternatively, retry without using the privileged option.
INSSHOWPRIV
some volumes not shown due to insufficient privilege
Explanation:
Not all volumes were shown because of restricted privilege.
User Action:
None if you just want to see volumes you own. You need MDMS_SHOW_ALL privilege to see all volumes.
INSSVRPRV
insufficient server privileges
Explanation:
The MDMS server is running with insufficient privileges to perform system functions.
User Action:
Refer to the Installation Guide to determine the required privileges. Contact your system administrator to add these privileges in the MDMS$SERVER account.
INTBUFOVR
internal buffer overflow
Explanation:
The MDMS software detected an internal buffer overflow. This an internal error.
User Action:
Provide copies of the MDMS command issued, the database files and the server's logfile for further analysis. Restart the server.
INTINVMSG
internal invalid message
Explanation:
An invalid message was received by a server. This could be due to a network problem or, a remote non-MDMS process sending messages in error or, an internal error.
User Action:
If the problem persists and no non-MDMS process can be identified then provide copies of the MDMS command issued, the database files and the server's logfile for further analysis.
INTSCHEDULE
cannot modify or delete internal schedule
Explanation:
You attempted to modify or delete a schedule object that was internally generated for a save or restore request. This is not allowed.
User Action:
Modify or delete the associated save or restore request instead, and the schedule will be updated accordingly.
INVABSTIME
invalid absolute time
Explanation:
The item list contained an invalid absolute date and time. Time cannot be earlier than 1-Jan-1970 00:00:00 and cannot be greater than 7-Feb-2106 06:28:15
User Action:
Check that the time is between these two times.
INVALIDRANGE
invalid volume ID or invalid range specified
Explanation:
The specified volume ID, volume range, slot range or space range is invalid.
User Action:
A volume ID may contain up to 6 characters. A volume range may contain up to 1000 volume IDs where the first 3 characters must be alphabetic and the last 3 may be alphanumeric. Only the numeric portions may vary in the range. Examples are ABC000-ABC999, or ABCD01-ABCD99. A slot range can contain up to 1000 slots and must be numeric. Also, all slots in the range must be less than the slot count for the jukebox or magazine. Example: 0-255 for a slot count of 256. A space range can contain up to1000 spaces where the first and last spaces must have the same number of characters. Spaces must be within the range defined for the location. Examples: 000-999, or Space A1-Space C9
INVCONSOLVAL
invalid value for consolidation savesets or volumes
Explanation:
You specified an invalid value for consolidation savesets or volumes.
User Action:
Use a value in the range 0 to maximum integer.
INVDBSVRLIS
invalid database server search list
Explanation:
The logical name MDMS$DATABASE_SERVERS contains invalid network node names or is not defined.
User Action:
Correct the node name(s) in the logical name MDMS$DATABASE_SERVERS in file MDMS$SYSTARTUP.COM. Redefine the logical name in the current system. Then start the server.
INVDELSTATE
object is in invalid state for delete
Explanation:
The specified object cannot be deleted because its state indicates it is being used.
User Action:
Defer deletion until the object is no longer being used, or otherwise change its state and retry.
INVDELTATIME
invalid delta time
Explanation:
The item list contained an invalid delta time.
User Action:
Check that the item list has a correct delta time.
INVDFULLNAM
invalid DECnet fullname
Explanation:
A node full name for a DECnet-Plus (Phase V) node specification has an invalid syntax.
User Action:
Correct the node name and retry.
INVDRVCOUNT
invalid value for drive count, use 1-32
Explanation:
You specified an invalid value for drive count.
User Action:
Use a value in the range 1-32.
INVEXTSTS
invalid extended status item desc/buffer
Explanation:
The error cannot be reported in the extended status item descriptor. This error can be caused by on of the following:
-
Not being able to read any one of the item descriptors in the item list
-
Not being able to write to the buffer in the extended status item descriptor
-
Not being able to write to the return length in the extended status item descriptor
-
Not being able to initialize the extended status buffer
User Action:
Check for any of the errors stated above in your program and fix the error.
INVFREQUENCY
invalid frequency for domain scheduler type
Explanation:
You specified an invalid save or restore frequency the scheduler type specified in the domain. Invalid combinations include: CUSTOM, with NONE, DECSCHEDULER, SCHEDULER or LOCAL EXPLICIT, with NONE, INTERNAL, EXTERNAL, or SINGLE
User Action:
Specify a valid frequency for the scheduler type specified in the domain.
INVINITOPT
invalid initialize options specified
Explanation:
You attempted initialize volumes in a jukebox by specifying a slot range and the jukebox is not a vision-equipped, MRD-controlled jukebox.
User Action:
Specify a volume range instead of a slot range to initialize volumes in a DCSC jukebox or an MRD jukebox without a vision system.
INVITCODE
invalid item code for this function
Explanation:
The item list had an invalid item code. The problem could be one of the following:
-
Item codes do not meet the restrictions for that function.
-
An item code cannot be used in this function.
User Action:
Refer to the API specification to find out which item codes are restricted for each function and which item codes are allowed for each function.
INVITDESC
invalid item descriptor, index !@UL
Explanation:
The item descriptor is in error. The previous message gives gives the error. Included is the index of the item descriptor in the item list.
User Action:
Refer to the index number and the previous message to indicate the error and which item descriptor is in error.
INVITLILENGTH
invalid item list buffer length
Explanation:
The item list buffer length is zero. The item list buffer length cannot be zero for any item code.
User Action:
Refer to the API specification to find an item code that would be used in place of an item code that has a zero buffer length.
INVMAXSAVES
invalid value for maximum saves, use 1-36
Explanation:
You specified an invalid value for maximum saves.
User Action:
Use a value in the range 1-36.
INVMEDIATYPE
media type is invalid or not supported by volume
Explanation:
The specified volume supports multiple media types where a single media type is required, or the volume does not support the specified media type.
User Action:
Re-enter the command specifying a single media type that is already supported by the volume.
INVMSG
invalid message via !AZ
Explanation:
An invalid message was received MDMS software. This could be due to a network problem or, a non-MDMS process sending messages in error or, an internal error.
User Action:
If the problem persists and no non-MDMS process can be identified then provide copies of the MDMS command issued, the database files and the server's logfile for further analysis.
INVNODNAM
invalid node name specification
Explanation:
A node name for a DECnet (Phase IV) node specification has an invalid syntax.
User Action:
Correct the node name and retry.
INVPORTS
invalid port number specification
Explanation:
The MDMS server did not start up because the logical name MDMS$TCPIP_SND_PORTS in file MDMS$SYSTARTUP.COM specifies and illegal port number range. A legal port number range is of the form "low_port_number-high_port_number".
User Action:
Correct the port number range for the logical name MDMS$TCPIP_SND_PORTS in file MDMS$SYSTARTUP.COM. Then start the server.
INVPOSITION
invalid jukebox position
Explanation:
The position specified is invalid.
User Action:
Position is only valid for jukeboxes with a topology defined. Check that the position is within the topology ranges, correct and retry. Example: /POSITION=(1,2,1)
INVRETDAYS
invalid retention days specified
Explanation:
You entered an invalid value for the retention days. Valid values are 0 to 9999 days. If you wish for no expiration of volumes, specify /NOEXPIRATION_DATE.
User Action:
Enter a value between 0 and 9999.
INVRETRY
invalid value for retry count or interval
Explanation:
You specified an invalid value for either or both the retry count or interval. In addition, it is invalid to specify an interval with a retry limit of zero or nolimit.
User Action:
Use values within the following ranges:
-
RETRY_LIMIT: 0 - 10000 or NOLIMIT
-
INTERVAL: 00:01:00 - 01:00:00 (1 - 60 mins)
INVRETRYINTERVAL
invalid value for retry interval
Explanation:
You specified an invalid value for retry interval. In addition, it is invalid to specify an interval with a retry limit of zero.
User Action:
Use a value within the following range only if retry limit is non-zero: 00:01:00 - 01:00:00 (1 - 60 mins)
INVRETRYLIMIT
invalid value for retry limit
Explanation:
You specified an invalid value for retry limit.
User Action:
Use a value in the range 0 to maximum integer or use /NORETRY_LIMIT
INVSCHEDENUM
invalid scheduling translation defined
Explanation:
An invalid parameter translation was entered for a scheduling option.
User Action:
Report the incident to hp.
INVSCHEDOPT
invalid schedule options entered
Explanation:
You entered invalid schedule date/time options for a schedule object. The following values are allowed:
-
DATES: List of values or ranges, values 1 - 31
-
DAYS: List of values or ranges, values MON - SUN
-
MONTHS: List of values or ranges, values JAN - DEC
-
TIMES: List of values, 00:00 - 23:59
-
INCLUDE: List of dates 01-Jan-yyyy - 31-Dec-yyyy
-
EXCLUDE: List of dates 01-Jan-yyyy - 31-Dec-yyyy
The yyyy for INCLUDE and EXCLUDE must be between the current year and up to 9 years into the future (e.g. 2001-2010). If omitted, the current year is used.
User Action:
Re-enter the command with valid values.
INVSCHEDPARAM
inavlid scheduling parameter defined
Explanation:
An invalid parameter was entered for a scheduling option.
User Action:
Report the incident to hp.
INVSELECT
invalid selection criteria
Explanation:
The selection criteria specified on an allocate command are invalid.
User Action:
Check the command with the documentation and re-enter with a valid combination of selection criteria.
INVSLOT
invalid slot or slot range specified
Explanation:
The slot or slot range specified when moving volumes into a magazine or jukebox was invalid, or the specified slots were already occupied.
User Action:
Specify valid empty slots and re-enter.
INVSLOTRANGE
invalid slot range
Explanation:
The slot range was invalid. It must be of the form: 1-100 1,100-200,300-400 The only characters allowed are comma, dash, and numbers (0-9).
User Action:
Check that you are using the correct form.
INVSPACE
invalid space or space range specified
Explanation:
The space or space range specified when moving volumes into a location was invalid.
User Action:
Specify valid spaces already defined for the location, or specify a space range for the location
INVSRCDEST
invalid source or destination for move
Explanation:
Either the source or destination of a move operation was invalid (does not exist).
User Action:
If the destination is invalid, enter a correct destination and retry. If a source is invalid, either create the source or correct the current placement of the affected volumes or magazines.
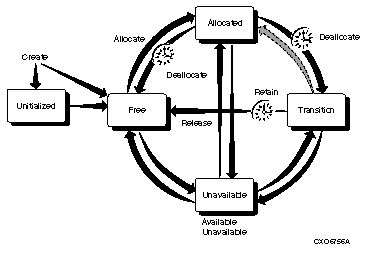
INVSTATE
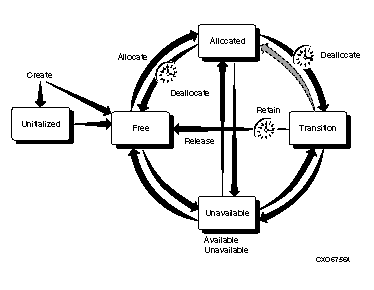
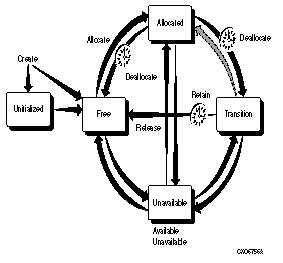
volume !AZ is in an invalid state for initialization
Explanation:
The volume loaded in the drive for initialization was either allocated or in the transition state and cannot be initialized.
User Action:
Either the wrong volume was loaded, or the requested volume was in an invalid state. If the wrong volume was loaded, perform an inventory on the jukebox and retry. If the volume is allocated or in transition, you should not try to initialize the volume.
INVTFULLNAM
invalid TCP/IP fullname
Explanation:
A node full name for a TCP/IP node specification has an invalid syntax.
User Action:
Correct the node name and retry.
INVTOPOLOGY
invalid jukebox topology
Explanation:
The specified topology for a jukebox is invalid.
User Action:
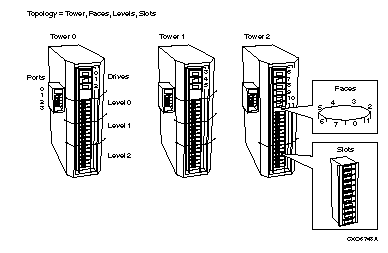
Check topology definition; the towers must be sequentially increasing from 0; there must be a face, level and slot definition for each tower. Example: /TOPOLOGY=(TOWER=(0,1,2), FACES=(8,8,8), - LEVELS=(2,3,2), SLOTS=(13,13,13))
INVVOLPLACE
invalid volume placement for operation
Explanation:
The volume has an invalid placement for a load operation.
User Action:
Re-enter the command and use the move option.
INVVOLSTATE
volume in invalid state for operation
Explanation:
The operation cannot be performed on the volume because of the volume state does not allow it.
User Action:
Defer the operation until the volume changes state. If the volume is stuck in a transient state (e.g. moving), check for an outstanding request and cancel it. If all else fails, manually change the state.
JUKEBOXEXISTS
specified jukebox already exists
Explanation:
The specified jukebox already exists and cannot be created.
User Action:
Use a set command to modify the jukebox, or create a new jukebox with a different name.
JUKENOTINIT
jukebox could not be initialized
Explanation:
An operation on a jukebox failed because the jukebox could not be initialized.
User Action:
Check the control, robot name, node name and group name of the jukebox, and correct as needed. Check access path to jukebox (HSJ etc), correct as needed. Verify MDMS is running on a remote node. Then retry operation.
JUKETIMEOUT
timeout waiting for jukebox to become available
Explanation:
MDMS timed out waiting for a jukebox to become available. The timeout value is 10 minutes.
User Action:
If the jukebox is in heavy use, try again later. Otherwise, check requests for a hung request - cancel it. Set the jukebox state to available if all else fails.
JUKEUNAVAIL
jukebox is currently unavailable
Explanation:
The jukebox is disabled.
User Action:
Re-enable the jukebox.
JUKUNDEFINED
referenced jukebox !AZ undefined
Explanation:
When creating or modifying a valid object, the object's record contains a reference to a jukebox name that does not exist.
User Action:
Check spelling of the jukebox name and retry, or create the jukebox object in the database.
LOCATIONEXISTS
specified location already exists
Explanation:
The specified location already exists and cannot be created.
User Action:
Use a set command to modify the location, or create a new location with a different name.
LOCUNDEFINED
referenced location !AZ undefined
Explanation:
When creating or modifying a valid object, the object's record contains a reference to a location name that does not exist.
User Action:
Check spelling of the location name and retry, or create the location object in the database.
LOGRESET
Log file !AZ by !AZ on node !AZ
Explanation:
The server logfile has been closed and a new version has been created by a user.
User Action:
None.
MAGAZINEEXISTS
specified magazine already exists
Explanation:
The specified magazine already exists and cannot becreated.
User Action:
Use a set command to modify the magazine, or create a new magazine with a different name.
MAGUNDEFINED
referenced magazine !AZ undefined
Explanation:
When creating or modifying a valid object, the object's record contains a reference to a magazine name that does not exist.
User Action:
Check spelling of the magazine name and retry, or create the magazine object in the database.
MBLISEXIT
mailbox listener exited
Explanation:
The mailbox listener has exited due to an internal error condition. The mailbox listener is the server's routine to receive local user requests through mailbox MDMS$MAILBOX.
User Action:
The mailbox listener should be automatically restarted. Provide copies of the MDMS command issued, the database files and the server's logfile for further analysis.
MBLISRUN
listening on mailbox !AZ logical !AZ
Explanation:
The server has successfully started the mailbox listener. MDMS commands can now be entered on this node.
User Action:
None.
MEDIATYPEEXISTS
specified media type already exists
Explanation:
The specified media type already exists and cannot be created.
User Action:
Use a set command to modify the media type, or create a new media type with a different name.
MEDUNDEFINED
referenced media type(s) !AZ undefined
Explanation:
When creating or modifying a valid object, the object's record contains a reference to a media type that does not exist. One or more of the specified media types may be undefined.
User Action:
Check spelling of the media types and retry, or create the media type objects in the database.
MOVEINCOMPL
move is incomplete
Explanation:
When moving volumes into and out of a jukebox, some of the volumes were not moved.
User Action:
Check that there are enough empty slots in the jukebox when moving in and retry. On a move out, examine the cause of the failure and retry.
MRDERROR
error accessing jukebox with MRD
Explanation:
MDMS encountered an error when performing a jukebox operation. An accompanying message gives more detail.
User Action:
Examine the accompanying message and perform corrective actions to the hardware, the volume or the database, and optionally retry the operation.
MRDMSG
!AZ
Explanation:
This is a more detailed MRD error message which accompanies MRDERROR.
User Action:
Check the MRU error message file.
NOACCESS
no user access to object for operation
Explanation:
You attempted to perform an operation on an object for which you have no access.
User Action:
You need an authorized user to add you to the access control list, otherwise you cannot perform the requested operation.
NOBINDSELF
volume is already in volume set
Explanation:
You cannot bind this volume into this volume set because it already a member of the volume set.
User Action:
Use another volume.
NOCHANGES
no attributes were changed in the database
Explanation:
Your set command did not change any attributes in the database because the attributes you entered were already set to those values.
User Action:
Double-check your command, and re-enter if necessary. Otherwise the database is already set to what you entered.
NOCHANGESOBJ
no attributes were changed for !AZ !AZ
Explanation:
Your set command did not change any attributes in the database because the attributes you entered were already set to those values. The message indicates which object was not changed.
User Action:
Double-check your command, and re-enter if necessary. Otherwise the database is already set to what you entered.
NOCHECK
drive not accessible, check not performed
Explanation:
The specified drive could not be physically accessed and the label check was not performed. The displayed attributes are taken from the database.
User Action:
Verify the VMS device name, node name or group name in the drive object. Check availability on system. Verify MDMS is running on a remote node. Determine the reason the drive was not accessible, fix it and retry.
NODBACC
no access to database server
Explanation:
This server has no access to a database server.
User Action:
Verify the setting of logical name MDMS$DATABASE_SERVERS. Check each node listed using MDMS SHOW SERVER/NODE=... for connectivity and database access status. Check the servers logfiles for more information.
NODCSC
DCSC not running
Explanation:
DCSC has not been started.
User Action:
Execute command procedure SYS$STARTUP:DCSC$STARTUP.COM and retry command.
NODEDISABLED
node disabled
Explanation:
The server failed to start up because it is disabled in the database.
User Action:
If necessary correct the setting and start the server again.
NODEEXISTS
specified node already exists
Explanation:
The specified node already exists and cannot be created.
User Action:
Use a set command to modify the node, or create a new node with a different name.
NODENOPRIV
node is not privileged to access database server
Explanation:
A remote server access failed because the user making the DECnet connection is not MDMS$SERVER or the remote port number is not less than 1024.
User Action:
Verify with DCL command SHOW PROCESS that the remote MDMS server is running under a username of MDMS$SERVER and/or, verify that logical name MDMS$TCPIP_SND_PORTS on the remote server node specifies a port number range between 0-1023.
NODENOTENA
node not in database or not fully enabled
Explanation:
The server was not allowed to start up because there is no such node object in the database or its node object in the database does not specify all network full names correctly.
User Action:
For a node running DECnet (Phase IV) the node name has to match logical name SYS$NODE on that node. For a node running DECnet-Plus (Phase V) the node's DECNET_PLUS_FULLNAME has to match the logical name SYS$NODE_FULLNAME on that node. For a node running TCP/IP the node's TCPIP_FULLNAME has to match the full name combined from logical names *INET_HOST and *INET_DOMAIN.
NODENOTINDB
no node object with !AZ name !AZ in database
Explanation:
The current server could not find a node object in the database with a matching DECnet (Phase IV) or DECnet-Plus (Phase V) or TCP/IP node full name.
User Action:
Use SHOW SERVER/NODES=(...) to see the exact naming of the server's network names. Correct the entry in the database and restart the server.
NODRIVES
no drives match selection criteria
Explanation:
When allocating a drive, none of the drives match the specified selection criteria.
User Action:
Check spelling and re-enter command with valid selection criteria.
NODRVACC
access to drive disallowed
Explanation:
You attempted to allocate, load or unload a drive from a node that is not allowed to access it.
User Action:
The access field in the drive object allows local, remote or all access, and your attempted access did not conform to the attribute. Use another drive.
NODRVSAVAIL
no drives are currently available
Explanation:
All of the drives matching the selection criteria are currently in use or otherwise unavailable.
User Action:
Check to see if any of the drives are disabled or inaccessible. Re-enter command when corrected.
NODRVSGRP
no drives in the specified group were found
Explanation:
When allocating a drive, no drives on nodes in the specified group were found.
User Action:
Check group name and retry command.
NODRVSJUKE
no drives in the specified jukebox were found
Explanation:
When allocating a drive, no drives in the specified jukebox were found.
User Action:
Check jukebox name and retry command.
NODRVSLOC
no drives in the specified location were found
Explanation:
When allocating a drives, no drives in the specified location were found.
User Action:
Check location name and retry command.
NODRVSMED
no drives with the specified media type were found
Explanation:
When allocating a drive, no drives with the specified media type were found.
User Action:
Check media type and retry command, or specify the media type for more drives.
NODRVSNOD
no drives on the specified node were found
Explanation:
When allocating a drive, no drives on the specified node were found.
User Action:
Check the node name and retry command.
NODRVSVOL
no drives that can support the specified volume were found
Explanation:
When allocating a drive, no drives that could support the specified volume were found.
User Action:
Check the volume ID and retry command, or check and adjust volume attributes to match a valid drive.
NODUNDEFINED
referenced node(s) !AZ undefined
Explanation:
When creating or modifying a valid object, the object's record contains a reference to a node name that does not exist. One or more of the specified nodes may be undefined.
User Action:
Check spelling of the node names and retry, or create the node objects in the database.
NOFIELDS
no fields specified for report
Explanation:
A REPORT VOLUME command was entered with no fields to select or display.
User Action:
Enter at least one field for the report.
NOINCLUDE
selection attributes not set with no include data
Explanation:
You specified one or more of the following attributes which are not valid unless an include specification is present: DATA_TYPE, INCREMENTAL, NODES, GROUPS The save or restore object was updated, but selection attributes were not set.
User Action:
These attributes are applicable only when an INCLUDE statement is present. Re-enter the command with an INCLUDE qualifier.
NOINCLUDES
no include specification for selection
Explanation:
A save or restore object had some selection attributes specified, but no include file specification. The following attributes require an include specification:
-
Data type
-
Incremental
-
Groups
-
Nodes
User Action:
Re-enter the command with an include specification.
NOINTSCHED
internal scheduling not enabled
Explanation:
You attempted to create a schedule object but the domain's scheduler option is set to an external scheduler. The MDMS schedule object is valid only with scheduler options INTERNAL, EXTERNAL and SINGLE_SCHEDULER.
User Action:
Schedule your request using the specified external scheduler product and interface.
NOJUKEACC
access to jukebox disallowed
Explanation:
You attempted to use a jukebox from a node that is not allowed to access it.
User Action:
The access field in the jukebox object allows local, remote or all access, and your attempted access did not conform to the attribute. Use another jukebox.
NOJUKESPEC
jukebox required on vision option
Explanation:
The jukebox option is missing on a create volume request with the vision option.
User Action:
Re-enter the request and specify a jukebox name and slot range.
NOLICENSE
your current license does not support this operation
Explanation:
The requested operation is not licensed. If you are licensed for ABS_OMT only, you have attempted to perform an operation that requires a full ABS license.
User Action:
Use an alternative mechanism to perform the operation. If this is not possible, you cannot perform the operation with your current license. You may purchase an upgrade ABS license to enable full ABS functionality. Contact hp for details.
NOMAGAZINES
no magazines match selection criteria
Explanation:
On a move magazine request using the schedule option, no magazines were scheduled to be moved.
User Action:
None.
NOMAGSMOVED
no magazines were moved
Explanation:
No magazines were moved for a move magazine operation. An accompanying message gives a reason.
User Action:
Check the accompanying message, correct and retry.
NOMEDIATYPE
no media type specified when required
Explanation:
An allocation for a volume based on node, group or location also requires the media type to be specified.
User Action:
Re-enter the command with a media type specification.
NOMEMORY
not enough memory
Explanation:
The MDMS server failed to allocate enough virtual memory for an operation. This is an internal error.
User Action:
Provide copies of the MDMS command issued, the database files and the server's logfile for further analysis. Restart the server.
NOOBJECTS
no such objects currently exist
Explanation:
On a show command, there are no such objects currently defined.
User Action:
None.
NOPARAM
required parameter missing
Explanation:
A required input parameter to a request or an API function was missing.
User Action:
Re-enter the command with the missing parameter, or refer to the API specification for required parameters for each function.
NOPOOLSPEC
no free volumes with no pool or your default pool were found
Explanation:
When allocating a volume, no free volumes that do no have a pool defined or that are in your default pool were found.
User Action:
Add a pool specification to the command, or define more free volumes with no pool or your default pool.
NORANGESUPP
slot or space ranges not supported with volset option
Explanation:
On a set volume, you entered the volset option and specified either a slot range or space range.
User Action:
If you want to assign slots or spaces to volumes directly, do not use the volset option.
NORECVPORTS
no available receive port numbers for incoming connections
Explanation:
The MDMS could not start the TCP/IP listener because none of the receive ports specified with this node's TCPIP_FULLNAME are currently available.
User Action:
Use a suitable network utility to find a free range of TCP/IP ports which can be used by the MDMS server. Use the MDMS SET NODE command to specify the new range with the /TCPIP_FULLNAME then restart the server.
NOREMCONNECT
unable to connect to remote node
Explanation:
The server could not establish a connection to a remote node. See the server's logfile for more information.
User Action:
Depends on information in the logfile.
NOREQUESTS
no such requests currently exist
Explanation:
No requests exist on the system.
User Action:
None.
NORESEFN
not enough event flags
Explanation:
The server ran out of event flags. This is an internal error.
User Action:
Provide copies of the MDMS command issued, the database files and the server's logfile for further analysis. Restart the server.
NORIGHTS
no rights are shown
Explanation:
When showing a domain, the rights are not shown because you don't have privilege to see the rights.
User Action:
Nothing. To see rights you need MDMS_SHOW_RIGHTS.
NOSCHEDULE
schedule object invalid for scheduler type or frequency
Explanation:
You specified a schedule object for a non-custom frequency or for an external scheduler option. A schedule object can only be specified for frequency CUSTOM with domain scheduler type of INTERNAL, EXTERNAL or SINGLE.
User Action:
Do not specify a schedule name.
NOSCRATCH
scratch loads not supported for jukebox drives
Explanation:
You attempted a load drive command for a jukebox drive.
User Action:
Scratch loads are not supported for jukebox drives. You must use the load volume command to load volumes in jukebox drives.
NOSENDPORTS
no available send port numbers for outgoing connection
Explanation:
The server could not make an outgoing TCP/IP connection because none of the send ports specified for the range in logical name MDMS$TCPIP_SND_PORTS are currently available.
User Action:
Use a suitable network utility to find a free range of TCP/IP ports which can be used by the MDMS server. Change the logical name MDMS$TCPIP_SND_PORTS in file MDMS$SYSTARTUP.COM. Then restart the server.
NOSLOT
not enough slots defined for operation
Explanation:
The command cannot be completed because there are not enough slots specified in the command, or because there are not enough empty slots in the jukebox.
User Action:
If the jukebox is full, move some other volumes out of the jukebox and retry. If there are not enough slots specified in the command, re-enter with a larger slot range.
NOSTATUS
no status defined
Explanation:
An uninitialized status has been reported. This an internal error.
User Action:
Provide copies of the MDMS command issued, the database files and the server's logfile for further analysis.
NOSUCHDEST
specified destination does not exist
Explanation:
In a move command, the specified destination does not exist.
User Action:
Check spelling or create the destination as needed.
NOSUCHDRIVE
specified drive does not exist
Explanation:
The specified drive does not exist.
User Action:
Check spelling or create drive as needed.
NOSUCHGROUP
specified group does not exist
Explanation:
The specified group does not exist.
User Action:
Check spelling or create group as needed.
NOSUCHINHERIT
specified inherited object does not exist
Explanation:
On a create of an object, the object specified for inherit does not exist.
User Action:
Check spelling or create the inherited object as needed.
NOSUCHJUKEBOX
specified jukebox does not exist
Explanation:
The specified jukebox does not exist.
User Action:
Check spelling or create jukebox as needed.
NOSUCHLOCATION
specified location does not exist
Explanation:
The specified location does not exist.
User Action:
Check spelling or create location as needed.
NOSUCHMAGAZINE
specified magazine does not exist
Explanation:
The specified magazine does not exist.
User Action:
Check spelling or create magazine as needed.
NOSUCHMEDIATYPE
specified media type does not exist
Explanation:
The specified media type does not exist.
User Action:
Check spelling or create media type as needed.
NOSUCHNODE
specified node does not exist
Explanation:
The specified node does not exist.
User Action:
Check spelling or create node as needed.
NOSUCHOBJECT
specified object does not exist
Explanation:
The specified object does not exist.
User Action:
Check spelling or create the object as needed.
NOSUCHPOOL
specified pool does not exist
Explanation:
The specified pool does not exist.
User Action:
Check spelling or create pool as needed.
NOSUCHREQUESTID
specified request does not exist
Explanation:
The specified request does not exist on the system.
User Action:
Check the request id again, and re-enter if incorrect.
NOSUCHUSER
no such user on system
Explanation:
The username specified in the command does not exist.
User Action:
Check spelling of the username and re-enter.
NOSUCHVOLUME
specified volume(s) do not exist
Explanation:
The specified volume or volumes do not exist.
User Action:
Check spelling or create volume(s) as needed.
NOSVRACCOUNT
username !AZ does not exist
Explanation:
The server cannot startup because the username MDMS$SERVER is not defined in file SYSUAF.DAT.
User Action:
Enter the username of MDMS$SERVER (see Installation manual for account details) and then start the server.
NOSVRMB
no server mailbox or server not running
Explanation:
The MDMS server is not running on this node or the server is not servicing the mailbox via logical name MDMS$MAILBOX.
User Action:
Use the MDMS$STARTUP procedure with parameter RESTART to restart the server. If the problem persists, check the server's logfile and file SYS$MANAGER:MDMS$SERVER.LOG for more information.
NOSYMBOLS
symbols not supported for multiple volumes
Explanation:
A SHOW VOLUME/SYMBOLS command was entered for multiple volumes. The /SYMBOLS qualifier is only supported for a single volume.
User Action:
Re-enter command with a single volume ID, or don't use the /SYMBOLS qualifier.
NOTALLOCUSER
volume is not allocated to user
Explanation:
You cannot perform the operation on the volume because the volume is not allocated to you.
User Action:
Either use another volume, or (in some cases) you may be able to perform the operation specifying a user name.
NOTSCHEDULED
specified save or restore is not scheduled for execution
Explanation:
The save or restore request did not contain enough information to schedule the request for execution. The request requires the definition of an archive, an environment and a start time.
User Action:
If you wish this request to be scheduled, enter a SET SAVE or SET RESTORE and enter the required information.
NOUNALLOCDRV
no unallocated drives found for operation
Explanation:
On an initialize volume request, MDMS could not locate an unallocated drive for the operation.
User Action:
If you had allocated a drive for the operation, deallocate it and retry. If all drives are currently in use, retry the operation later.
NOVOLSJUKE
no free volumes in the specified jukebox were found
Explanation:
When allocating a volume, no free volumes in the specified jukebox were found.
User Action:
Check jukebox name and retry command, or move some free volumes into the jukebox.
NOVOLSLOC
no free volumes in the specified location were found
Explanation:
When allocating a volume, no free volumes in the specified location were found.
User Action:
Check location name and retry command, or move some free volumes into the location.
NOVOLSMED
no free volumes with the specified media type were found
Explanation:
When allocating a volume, no free volumes with the specified media type were found.
User Action:
Check media type and retry command, or specify the media type for more free volumes.
NOVOLSMOVED
no volumes were moved
Explanation:
No volumes were moved for a move volume operation. An accompanying message gives a reason.
User Action:
Check the accompanying message, correct and retry.
NOVOLSPOOL
no free volumes in the specified pool were found
Explanation:
When allocating a volume, no free volumes in the specified pool were found.
User Action:
Check pool name and retry command, or specify the pool for more free volumes (add them to the pool).
NOVOLSPROC
no volumes were processed
Explanation:
In a create, set or delete volume command, no volumes were processed.
User Action:
Check the volume identifiers and re-enter command.
NOVOLSVOL
no free volumes matching the specified volume were found
Explanation:
When allocating a volume, no free volumes matching the specified volume were found.
User Action:
Check the volume ID and retry command, or add more free volumes with matching criteria.
NOVOLUMES
no volumes match selection criteria
Explanation:
When allocating a volume, no volumes match the specified selection criteria.
User Action:
Check the selection criteria. Specifically check the relevant volume pool. If free volumes are in a volume pool, the pool name must be specified in the allocation request, or you must be a default user defined in the pool. You can re-enter the command specifying the volume pool as long as you are an authorized user. Also check that newly-created volumes are in the FREE state rather than the UNITIALIZED state.
OBJECTEXISTS
specified object already exists
Explanation:
The specified object already exists and cannot be created.
User Action:
Use a set command to modify the object, or create a new object with a different name.
OBJNOTEXIST
referenced object !AZ does not exist
Explanation:
When attempting to allocate a drive or volume, you specified a selection object that does not exist.
User Action:
Check spelling of selection criteria objects and retry, or create the object in the database.
OBJREFZERO
dereferenced object with zero count
Explanation:
The MDMS server software detected an internal inconsistency. This is an internal error.
User Action:
Provide copies of the MDMS command issued, the database files and the server's logfile for further analysis.
PARTIALSUCCESS
some volumes in range were not processed
Explanation:
On a command using a volume range, some of the volumes in the range were not processed.
User Action:
Verify the state of all objects in the range, and issue corrective commands if necessary.
POLUNDEFINED
referenced pool !AZ undefined
Explanation:
When creating or modifying a valid object, the object's record contains a reference to a pool name that does not exist.
User Action:
Check spelling of the pool name and retry, or create the pool object in the database.
POOLEXISTS
specified pool already exists
Explanation:
The specified pool already exists and cannot be be created.
User Action:
Use a set command to modify the pool, or create a new pool with a different name.
PROFERROR
profile specification error
Explanation:
You specified an invalid user profile for the environment. Verify that the user name specified (default is ABS) exists on the specified node or cluster.
User Action:
Re-enter with a valid combination of node or cluster name and user name.
QUEUED
operation is queued for processing
Explanation:
The asynchronous request you entered has been queued for processing.
User Action:
You can check on the state of the request by issuing a show requests command.
RDFERROR
error allocating or deallocating RDF device
Explanation:
During an allocation or deallocation of a drive using RDF, the RDF software returned an error.
User Action:
The error following this error is the RDF error return.
REQUESTID
request ID is !@UL
Explanation:
The number is the request ID for the command just queued.
User Action:
None
RESUNDEFINED
referenced restore(s) !AZ undefined
Explanation:
When creating or modifying a valid object, the object's record contains a reference to a restore name that does not exist. One or more of the specified restores may be undefined.
User Action:
Check spelling of the restore names and retry, or create the restore objects in the database.
SAVUNDEFINED
referenced save(s) !AZ undefined
Explanation:
When creating or modifying a valid object, the object's record contains a reference to a save name that does not exist. One or more of the specified saves may be undefined.
User Action:
Check spelling of the save names and retry, or create the save objects in the database.
SCHEDCREATEERR
failed to create a scheduling job
Explanation:
MDMS failed to create a scheduling job.
User Action:
Report the incident to hp.
SCHEDDELETEERR
failed to delete a scheduling job
Explanation:
MDMS failed to delete a scheduling job.
User Action:
Report the incident to hp.
SCHEDDISCONNECT
scheduler disconnected from mailbox
Explanation:
The scheduler was disconnected from a mailbox
User Action:
Report the incident to hp.
SCHEDDUPJOB
duplicate scheduler job found
Explanation:
MDMS found a duplicate scheduling job
User Action:
Report the incident to hp.
SCHEDEXTSTATUS
external schedule job exited with bad status
Explanation:
An external schedule job exited with bad status
User Action:
Report the incident to hp.
SCHEDLOOPERR
schedule thread terminating with fatal error, restarting
Explanation:
The MDMS internal schedule thread encountered an error and terminated. The thread is restarted.
User Action:
Report the problem to hp.
SCHEDMODIFYERR
failed to modify a scheduling job
Explanation:
MDMS failed to modify a scheduling job.
User Action:
Report the incident to hp.
SCHEDNOJOBCOMPLETE
no job complete time was returned from a scheduled job
Explanation:
No job complete time was returned from a scheduled job.
User Action:
Report the incident to hp.
SCHEDNOJOBEXISTS
no job exists was returned from a scheduled job
Explanation:
No job exists was returned from a scheduled job.
User Action:
Report the incident to hp.
SCHEDNOJOBNUM
no job number was returned from a scheduled job
Explanation:
No job number was returned from a scheduled job.
User Action:
Report the incident to hp.
SCHEDNOJOBSTART
no job start time was returned from a scheduled job
Explanation:
No job start time was returned from a scheduled job.
User Action:
Report the incident to hp.
SCHEDNOJOBSTATUS
no job status was returned from a scheduled job
Explanation:
No job status was returned from a scheduled job.
User Action:
Report the incident to hp.
SCHEDNOSUCHJOB
failed to find a scheduling job
Explanation:
MDMS failed to find a scheduling job.
User Action:
Report the incident to hp.
SCHEDSHOWERR
failed to show a scheduling job
Explanation:
MDMS failed to show a scheduling job.
User Action:
Report the incident to hp.
SCHEDSYSTEMERR
failed to access the internal scheduler queue
Explanation:
An MDMS call to a system service failed in the scheduler functions.
User Action:
Report the incident to hp.
SCHEDULECONFL
schedule qualifier and novolume qualifier are incompatible
Explanation:
The /SCHEDULE and /NOVOLUME qualifiers are incompatible for this command.
User Action:
Use the /SCHEDULE and /VOLSET qualifiers for this command.
SCHEDVOLCONFL
schedule qualifier and volume parameter are incompatible
Explanation:
The /SCHEDULE and the volume parameter are incompatible for this command.
User Action:
Use the /SCHEDULE qualifier and leave the volume parameter blank for this command.
SCHEDULECONFL
schedule qualifier and novolume qualifier are incompatible
Explanation:
The /SCHEDULE and /NOVOLUME qualifiers are incompatible for this command.
User Action:
Use the /SCHEDULE and /VOLSET qualifiers for this command.
SCHEDVOLCONFL
schedule qualifier and volume parameter are incompatible
Explanation:
The /SCHEDULE and the volume parameter are incompatible for this command.
User Action:
Use the /SCHEDULE qualifier and leave the volume parameter blank for this command.
SCHUNDEFINED
referenced schedule(s) !AZ undefined
Explanation:
When creating or modifying a valid object, the object's record contains a reference to a schedule name that does not exist. One or more of the specified schedules may be undefined.
User Action:
Check spelling of the schedule names and retry, or create the schedule objects in the database.
SELUNDEFINED
referenced selection(s) !AZ undefined
Explanation:
When creating or modifying a valid object, the object's record contains a reference to a selection name that does not exist. One or more of the specified selections may be undefined.
User Action:
Check spelling of the selection names and retry, or create the selection objects in the database.
SETLOCALEFAIL
an error occurred when accessing locale information
Explanation:
When executing the SETLOCALE function an error occurred.
User Action:
A user should not see this error.
SETPROTECTED
protected field(s) set, verify consistency
Explanation:
You have directly set a protected field with this command. Normally these fields are maintained by MDMS. This has the potential to make the database inconsistent and cause other operations to fail.
User Action:
Do a SHOW /FULL on the object(s) you have just modified and verify that your modifications leave the object(s) in a consistent state.
SLSDBINUSE
SLS$DB network object in use
Explanation:
The MDMS server could not be started because it could not declare the network task SLS$DB. The network task SLS$DB is already in use.
User Action:
Check the server's logfile for more information.Check the logical MDMS$SUPPORT_PRE_V3 in the system table. If this is TRUE and the SLS$TAPMGRDB process is running the server cannot be started. Shut down the SLS$TAPMGRDB process by shutting down SLS. Restart MDMSV3.0 server and then restart SLS.
SNDMAILFAIL
send mail failed, see log file for more explanation
Explanation:
While sending mail during the scheduled activities, a call to the mail utility failed.
User Action:
Check the log file for the failure code from the mail utility.
SOMESUCCESS
some objects in list were not processed
Explanation:
The request was partially successful, but some of the objects were not processed as shown in the extended status.
User Action:
Examine the extended status, and retry command as needed.
SPAWNCMDBUFOVR
spawn command buffer overflow
Explanation:
During the mount of a volume, the spawned mount command was too long for the buffer. This is an internal error.
User Action:
Provide copies of the MDMS command issued, the database files and the server's logfile for further analysis.
SVRBUGCHECK
internal inconsistency in SERVER
Explanation:
The MDMS server software (MDMS$SERVER.EXE) detected an inconsistency. This is an internal error.
User Action:
Provide copies of the MDMS command issued, the database files and the server's logfile for further analysis. Restart the server.
SVRDISCON
server disconnected
Explanation:
The server disconnected from the request because of a server problem or a network problem.
User Action:
Check the server's logfile and file SYS$MANAGER:MDMS$SERVER.LOG for more information. Provide copies of the MDMS command issued, the database files and the server's logfile for further analysis.
SVREXIT
server exited
Explanation:
Server exited. Check the server logfile for more information.
User Action:
Depends on information in the logfile.
SVRLOGERR
server logged error
Explanation:
The server failed to execute the request. Additional information is in the server's logfile.
User Action:
Depends on information in the logfile.
SVRRUN
server already running
Explanation:
The MDMS server is already running.
User Action:
Use the MDMS$SHUTDOWN procedure with parameter RESTART to restart the server.
SVRSTART
Server !AZ!UL.!UL-!UL started
Explanation:
The server has started up identifying its version and build number.
User Action:
None.
SVRSTARTSTRING
Server !AZ started
Explanation:
The server has started up identifying its version and build number.
User Action:
None.
SVRTERM
Server terminated abnormally
Explanation:
The MDMS server was shut down. This could be caused by a normal user shutdown or it could be caused by an internal error.
User Action:
Check the server's logfile for more information. If the logfile indicates an error has caused the server to shut down then provide copies of the MDMS command issued, the database files and the server's logfile for further analysis.
SVRUNEXP
unexpected error in SERVER !AZ line !UL
Explanation:
The server software detected an internal inconsistency.
User Action:
Provide copies of the MDMS command issued, the database files and the server's logfile for further analysis.
TCPIPLISEXIT
TCP/IP listener exited
Explanation:
The TCP/IP listener has exited due to an internal error condition or because the user has disabled the TCPIP transport for this node. The TCP/IP listener is the server's routine to receive requests via TCP/IP.
User Action:
The TCP/IP listener should be automatically restarted unless the TCPIP transport has been disabled for this node. Provide copies of the MDMS command issued, the database files and the server's logfile for further analysis if the transport has not been disabled by the user.
TCPIPLISRUN
listening on TCP/IP node !AZ port !AZ
Explanation:
The server has successfully started a TCP/IP listener. Requests can now be sent to the server via TCP/IP.
User Action:
None.
TOOLARGE
entry is too large
Explanation:
Either entries cannot be added to a list of an MDMS object or existing entries cannot be renamed because the maximum list size would be exceeded.
User Action:
Remove other elements from list and try again.
TOOMANY
too many objects generated
Explanation:
You attempted to perform an operation that generated too many objects.
User Action:
There is a limit of 1000 objects that may be specified in any volume range, slot range or space range. Re-enter command with a valid range.
TOOMANYSELECTS
too many selections for a field, use only one
Explanation:
More than one selection was specified for a particular field.
User Action:
Specify only one field to select on.
TOOMANYSORTS
too many sort qualifiers, use only one
Explanation:
When specify more than one field to sort on.
User Action:
Specify only one field to sort on.
UNDEFINEDREFS
success, but object references undefined objects
Explanation:
The command was successful, but the object being created or modified has references to undefined objects. Subsequent messages indicate which objects are undefined.
User Action:
This allows objects to be created in any order, but some operations may not succeed until the objects are defined. Verify/correct the spelling of the undefined objects or create the objects if needed.
UNKVOLENT
unknown volume !AZ entered in jukebox !AZ
Explanation:
A volume unknown to MDMS has been entered into a jukebox.
User Action:
Use the INVENTORY command to make the volume known to MDMS or use a jukebox utility program (CARTRIDGE or MRU) to eject the volume from the jukebox.
UNSUPPORTED
unsupported function
Explanation:
You attempted to perform an unsupported function.
User Action:
None.
UNSUPPORTED1
unsupported function !AZ
Explanation:
You attempted to perform an unsupported function.
User Action:
None.
UNSUPRECVER
unsupported version for record !AZ in database !AZ
Explanation:
The server has detected unsupported records in a database file. These records will be ignored.
User Action:
Consult the documentation about possible conversion procedures provided for this version of MDMS.
USERNOTAUTH
user is not authorized for volume pool
Explanation:
When allocating a volume, you specified a pool for which you are not authorized.
User Action:
Specify a pool for which you are authorized, or add your name to the list of authorized users for the pool. Make sure the authorized user includes the node name or group name in the pool object.
VISIONCONFL
vision option and volume parameter are incompatible
Explanation:
You attempted to create volumes with the vision option and the volume parameter. This is not supported.
User Action:
The vision option is used to create volumes with the volume identifiers read by the vision system on a jukebox. Re-enter the command with either the vision option (specifying jukebox and slot range), or with volume identifier(s), but not both.
VOLALRALLOC
specified volume is already allocated
Explanation:
You attempted to allocate a volume that is already allocated.
User Action:
Use another volume.
VOLALRINIT
volume is already initialized and contains data
Explanation:
When initializing a volume, MDMS detected that the volume is already initialized and contains data.
User Action:
If you are sure you still want to initialize the volume, re-enter the command with the overwrite option.
VOLIDICM
volume ID code missing
Explanation:
The volume ID is missing in a request.
User Action:
Provide voluem ID and retry request.
VOLINDRV
volume is currently in a drive
Explanation:
When allocating a volume, the volume is either moving or in a drive, and nopreferred was specified.
User Action:
Wait for the volume to be moved or unloaded, or use the preferred option.
VOLINJUKE
volume is in a jukebox
Explanation:
You attempted load a volume that is currently in a jukebox into a drive that is not in the jukebox.
User Action:
Load the volume into a drive within the current jukebox, or check the jukebox name for the drive.
VOLINSET
volume is already bound to a volume set
Explanation:
You cannot bind this volume because it is already in a volume set and is not the first volume in the set.
User Action:
Use another volume, or specify the first volume in the volume set.
VOLLOST
volume location is unknown
Explanation:
The volume's location is unknown.
User Action:
Check if the volume's placement is in a magazine, and if so if the magazine is defined. If not, create the magazine. Also check the magazine's placement.
VOLMOVE
volume cannot be loaded but can be moved to jukebox or drive
Explanation:
The volume is not currently in a placement where it can be loaded, but can be moved there.
User Action:
Move the volume to the drive, or use the automatic move option on the load and retry.
VOLMOVING
volume is currently being moved
Explanation:
In a move, load or unload command, the specified volume is already being moved.
User Action:
Wait for volume to come to a stable placement and retry. If the volume is stuck in the moving placement, check for an outstanding request and cancel it. If all else fails, manually change volume state.
VOLNOTALLOC
specified volume is not allocated
Explanation:
You attempted to bind or deallocate a volume that is not allocated.
User Action:
None for deallocate. For bind, allocate the volume and then bind it to the set, or use another volume.
VOLNOTBOUND
volume is not bound to a volume set
Explanation:
You attempted to unbind a volume that is not in a volume set.
User Action:
None.
VOLNOTINACS
one or more volumes are not in this ACS
Explanation:
One or more volumes for the command are not in this ACS.
User Action:
Verify that all volumes are in the same ACS and that the ACS id is correct.
VOLNOTINJUKE
volume is not in a jukebox
Explanation:
When loading a volume into a drive, the volume is not in a jukebox.
User Action:
Use the move option and retry the load. This will issue OPCOM messages to move the volume into the jukebox.
VOLNOTINPOOL
loaded volume is not in the specified pool
Explanation:
During a scratch load of a volume in a drive, the volume loaded was not in the requested pool.
User Action:
Load another volume that is in the requested pool. A recommended volume is printed in the OPCOM message. Note that if no pool was specified, the volume must have no pool defined.
VOLNOTLOADED
the volume is not loaded in a drive
Explanation:
On an unload request, the volume is not recorded as loaded in a drive.
User Action:
If the volume is not in a drive, none. If it is, issue an unload drive command to unload it.
VOLONOTHDRV
volume is currently in another drive
Explanation:
When loading a volume, the volume was found in another drive.
User Action:
Wait for the volume to be unloaded, or unload the volume and retry.
VOLSALLOC
!AZ volumes were successfully allocated
Explanation:
When attempting to allocate multiple volumes using the quantity option, some but not all of the requested quantity of volumes were allocated.
User Action:
See accompanying message as to why not all volumes were allocated.
VOLSDRIVES
one or more of the volumes are in drives or are moving
Explanation:
One or more of the volumes in the move request are in drives and cannot be moved. A show volume /brief will identify which volumes are in drives.
User Action:
Unload the volume(s) in drives and retry, or retry without specifying the volumes in drives.
VOLUMEEXISTS
specified volume(s) already exist
Explanation:
The specified volume or volumes already exist and cannot be be created.
User Action:
Use a set command to modify the volume(s), or create new volume(s) with different names.
VOLUNDEFINED
referenced volume !AZ undefined
Explanation:
When creating or modifying a valid object, the object's record contains a reference to a volume ID that does not exist.
User Action:
Check spelling of the volume ID and retry, or create the volume object in the database.
VOLWRTLCK
volume loaded with hardware write-lock
Explanation:
The requested volume was loaded in a drive, but is hardware write-locked when write access was requested.
User Action:
If you need to write to the volume, unload it, physically enable it for write, and re-load it.
WRONGLABEL
initializing volume !AZ as !AZ is disallowed
Explanation:
The label of the volume loaded in the drive for initialization does not match the requested volume label and there is data on the volume. Or initializing the volume with the requested label causes duplicate volumes in the same jukebox or location.
User Action:
If you wish to overwrite the volume label, re-issue the command with the overwrite qualifier. If there are duplicate volumes in the same location or jukebox you need to move the other volume from the jukebox or location before retrying.
WRONGVOLUME
wrong volume label or unlabelled volume was loaded
Explanation:
On a load volume command, MDMS loaded a volume with the wrong volume label or a blank volume label into the drive.
User Action:
Check the volume, and optionally perform an initialization of the volume and retry. If this message is displayed in an OPCOM message, you will need another free drive to perform the initialization. The volume has been unloaded.
 Guide to Operations
Guide to Operations