| ΝΑΛΊ | ΦΓΛΊ | ΧήΦΓ | ΚςΑζ |
Λ≥ΛΈΨœΛ«ΛœΓΛΤϋΥήΗλΞΫΓΦΞ»/ΞόΓΦΞΗ (SORT/MERGE) ΛΥΛΡΛΛΛΤάβΧάΛΖΛόΛΙΓΘ
3.1 ΒΓ«Ϋ≥ΒΆΉ
ΤϋΥήΗλΞΫΓΦΞ»/ΞόΓΦΞΗΛœ¥ΝΜζΛ§ΜΐΛΡ¬Αά≠(≤ΜΤ…ΛΏΓΛΖ±Τ…ΛΏΓΛ…τΦσΓΛΝμ≤ηΩτ)ΛΣΛηΛ”ΩΕΛξ≤ΨΧΨΞ’ΞΘΓΦΞκΞ…ΛΥΛηΛκΙώΗλΦ≠≈Β ΐΦΑΛΥΛΖΛΩΛ§ΛΟΛΤΞΫΓΦΞ»/ΞόΓΦΞΗΫηΆΐΛρΙ‘ΛΠΛβΛΈΛ«ΛΙΓΘ
ΥήΫώΛœ Compaq OpenVMS ΞΣΞΎΞλΓΦΞΤΞΘΞσΞΑΓΠΞΖΞΙΞΤΞύΛΈ SORT/MERGE ΛΈΞόΞΥΞεΞΔΞκΛρΤ…ΛσΛ«ΛΛΛκΛ≥Λ»ΛρΝΑΡσΛΥΛΖΛΤΒ≠Ϋ“ΛΒΛλΛΤΛΛΛόΛΙΛΈΛ«ΓΛ…§ΆΉΛΥ±ΰΛΗΛΤΦΓΛΈΞόΞΥΞεΞΔΞκΛρΜ≤Ψ»ΛΖΛΤΛ·ΛάΛΒΛΛΓΘ
Compaq OpenVMS …ΗΫύ»«SORT/MERGEΛœΦΓΛΈΤϋΥήΗλΆ―ΒΓ«ΫΛβ«ßΦ±ΛΙΛκΛηΛΠΛΥΛ ΛΟΛΤΛΛΛόΛΙΓΘ
Λ≥ΛλΛιΛΈΒΓ«ΫΛœΓΛOpenVMS ΛΈ SORT/MERGE ΛΈ¥ΝΜζ¬Αά≠Τβ…τΦ≠ΫώΛρΜ»ΛΠΛ≥Λ»ΛΥΛηΛξΙ‘ΛοΛλΛόΛΙΓΘ
Ωό 3-1 ΤϋΥήΗλΞΫΓΦΞ» /ΞόΓΦΞΗΫηΆΐΞ’ΞμΓΦ
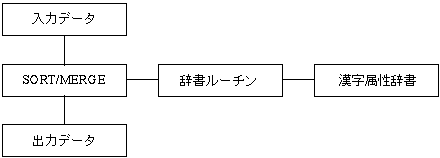
ΛΡΛόΛξΤϋΥήΗλΞΫΓΦΞ»/ΞόΓΦΞΗΛœΓΛ…ΗΫύ»«SORT/MERGEΛΥΤϋΥήΗλΆ―ΛΈΞβΞΗΞεΓΦΞκΛρΡ…≤ΟΛΖΛΩΛβΛΈΛ«ΛΔΛξΓΛ…ΗΫύ»«SORT/MERGEΛΈ DCL Ξ≥ΞόΞσΞ…Λ«ΛΔΛκ SORTΓΛMERGE ΛΥΛηΛξΓΛΤϋΥήΗλΞ«ΓΦΞΩΛβΤϋΥήΗλΑ ≥ΑΛΈΞ«ΓΦΞΩΛ»Τ±ΛΗΛηΛΠΛΥΫηΆΐΛ«Λ≠ΛκΛηΛΠΛΥΛ ΛΟΛΤΛΛΛόΛΙΓΘ
3.2 ΤϋΥήΗλΞΫΓΦΞ»ΒΓ«ΫΛΈ ΐΦΑ
3.2.1 ¥πΥή ΐΦΑ
KEY Ξ’ΞΘΓΦΞκΞ…ΛΥΛηΛΟΛΤΜΊΡξΛΒΛλΛΩΞ’ΞΘΓΦΞκΞ…Λρ¥ΝΜζΛΈ≤ΜΤ…ΛΏΓΛΖ±Τ…ΛΏΓΛ…τΦσΞ≥ΓΦΞ…ΓΛΝμ≤ηΩτΛΔΛκΛΛΛœΓΛJIS Ξ≥ΓΦΞ…ΓΠΞΤΓΦΞ÷ΞκΛΈΫγΛΥ ¬ΛΌΛΪΛ®ΛκΛ≥Λ»Λ§Λ«Λ≠ΛόΛΙΓΘ
| ≤ΜΤ…ΛΏ | ¥ΝΜζ¬Αά≠Φ≠ΫώΛΈ¬η1≤ΜΤ…ΛΏΛΥΛηΛκΓΘ |
| Ζ±Τ…ΛΏ | ¥ΝΜζ¬Αά≠Φ≠ΫώΛΈ¬η1Ζ±Τ…ΛΏΛΥΛηΛκΓΘ |
| …τΦσΞ≥ΓΦΞ… | JIS …τΦσΞ≥ΓΦΞ…ΛΥΛηΛκΓΘ |
| Νμ≤ηΩτ | ≤ηΩτΛΥΛηΛκΓΘ |
| JIS Ξ≥ΓΦΞ…ΓΠΞΤΓΦΞ÷Ξκ | JIS X 0208 Ξ≥ΓΦΞ…ΓΠΞΤΓΦΞ÷ΞκΛΥΛηΛκΓΘ |
ΞφΓΦΞΕΛ§ΜΊΡξΛΖΛΩΝ¥≥―(Λ“ΛιΛ§Λ ΛΪΓΛΞΪΞΩΞΪΞ )ΛόΛΩΛœ»Ψ≥―(ΞΪΞΩΞΪΞ )ΛΈΩΕΛξ≤ΨΧΨΞ’ΞΘΓΦΞκΞ…ΛρΦΓΛΈΨ»ΙγΫγΫχΛΥΛηΛΟΛΤ ¬ΛΌΛΪΛ®ΛκΛ≥Λ»Λ§Λ«Λ≠ΛόΛΙΓΘ
ΛόΛΩΓΛΖΪΛξ ÷ΛΖΒ≠ΙφΛœΓΛ1 ΗΜζΝΑΛΈ ΗΜζΛρΜ»ΛΛΓΛΡΙ≤Μ…δΙφΛΥΛΡΛΛΛΤΛœ1 ΗΜζΝΑΛΈ ΗΜζΛΈ λ≤ΜΛ§Μ»ΛοΛλΛόΛΙΓΘ
ΛΖΛΩΛ§ΛΟΛΤ
ΞΪΓΦΞ» ΞΪΞΓΞ» Ξ§ΓΦΞ… Ξ§ΓΦΞ» ΞΪΞΔΞ» ΞΪΓ≥Ξ» ΞΪΞΪΞ» ΞΪΧλ Ξ§ΞΔΞ… Ξ§Γ≥Ξ… Ξ§ΞΓΞ»
Λρ / KEY = (POSITION:1, SIZE:6, KOKUGO) Λ«ΞΫΓΦΞ»ΛΙΛκΛ»ΓΛΦΓΛΈΛηΛΠΛΥΛ ΛξΛόΛΙΓΘ
ΞΪΞΔΞ» ΞΪΓΦΞ» ΞΪΞΓΞ» Ξ§ΓΦΞ» Ξ§ΞΓΞ» Ξ§ΞΔΞ… Ξ§ΓΦΞ… ΞΪΞΪΞ» ΞΪΓ≥Ξ» ΞΪΧλ Ξ§Γ≥Ξ…
Λ≥ΛΈάαΛ«ΛœΓΛSORT Λ» MERGE Ξ≥ΞόΞσΞ…ΛΈΜ»Ά― ΐΥΓΛΣΛηΛ”ΤϋΥήΗλΞΫΓΦΞ»/ΞόΓΦΞΗΓΠΞΒΞ÷ΞκΓΦΞΝΞσΛΥΛΡΛΛΛΤάβΧάΛΖΛόΛΙΓΘ
3.3.1 ΤϋΥήΗλΆ―ΒΓ«Ϋ
KEY ΫΛΨΰΜ“ΛΥΤϋΥήΗλΆ―Λ»ΛΖΛΤΦΓΛΈΛβΛΈΛρΡ…≤ΟΛΖΛΤΛΛΛόΛΙΓΘ
3.3.2 SORT/MERGE Ξ≥ΞόΞσΞ…ΛΈΜ»Ά―Έψ
Α ≤ΦΛΥΜ»Ά―ΈψΛρΦ®ΛΖΛόΛΙΓΘ
SORT/KEY=(POSITION:1, SIZE:2, ONYOMI) INDATA.DAT ONDATA.DAT |
SORT/KEY=(POSITION:1, SIZE:2, KUNYOMI) INDATA.DAT KUNDATA.DAT |
MERGE/KEY=(POSITION:1, SIZE:2, BUSHU) IN1.DAT, IN2.DAT BUSHDATA.DAT |
MERGE/KEY=(POSITION:1, SIZE:2, SOKAKU) IN1.DAT, IN2.DAT SOKADATA.DAT |
SORT/KEY=(POSITION:10, SIZE:6, KOKUGO) INDATA.DAT SOKADATA.DAT |
MERGE/KEY=(POSITION:20, SIZE:8, KANA8BIT) IN1.DAT, IN2.DAT SOKADATA.DAT |
SORT/KEY=(POSITION:1, SIZE:2, JISCODE) INDATA.DAT SOKADATA.DAT |
ΛόΛΩΓΛΤϋΥήΗλΞ’ΞΘΓΦΞκΞ…ΛΈΨλΙγΛΥΛœΓΛDCLΛηΛξΤ±ΜΰΛΥ ΘΩτΛΈΞΫΓΦΞ» ΐΦΑΛρΜΊΡξΛΙΛκΛ≥Λ»Λ§≤Ρ«ΫΛ«ΛΙΓΘΛΩΛ»Λ®Λ–ΦΓΛΈΛηΛΠΛΥΜΊΡξΛ«Λ≠ΛόΛΙΓΘ
SORT/KEY=(POSITION:30, SIZE:6, SOKAKU, ONYOMI, JISCODE) IN.DAT OUT.DAT |
Λ≥ΛλΛœΦΓΛΈΜΊΡξ ΐΥΓΛ»Τ±≈υΛ«ΛΙΓΘ
SORT/KEY=(POSITION:30, SIZE:6, SOKAKU) -
/KEY=(POSITION:30, SIZE:6, ONYOMI) -
/KEY=(POSITION:30, SIZE:6, JISCODE) IN.DAT OUT.DAT
|
3.3.3 Μ≈ΆΆΞ’ΞΓΞΛΞκ (Specification file) ΟφΛΈΜ»Ά― ΐΥΓ
Μ≈ΆΆΞ’ΞΓΞΛΞκΛΈΟφΛ«ΛβΓΛΤϋΥήΗλΞ«ΓΦΞΩΓΠΞΩΞΛΞΉΛρΜ»Ά―Λ«Λ≠ΛόΛΙΓΘ…ΗΫύ»«ΛΈΞ…Ξ≠ΞεΞαΞσΞ»Λ«ΛΔΛ≤ΛΤΛΔΛκΞ«ΓΦΞΩΓΠΞΩΞΛΞΉ(ΓΊ OpenVMS ΞφΓΦΞΕΓΦΞΚΓΠΞόΞΥΞεΞΔΞκΓΌΛρΜ≤Ψ»)Α ≥ΑΛΥΓΛΦΓΛΈΒΩΜςΞ«ΓΦΞΩΓΠΞΩΞΛΞΉΛρΜ»Ά―Λ«Λ≠ΛόΛΙΓΘ
| ONYOMI | (≤ΜΤ…ΛΏ) |
| KUNYOMI | (Ζ±Τ…ΛΏ) |
| BUSHU | (…τΦσΞ≥ΓΦΞ…) |
| SOKAKU | (Νμ≤ηΩτ) |
| KOKUGO | (ΙώΗλΦ≠≈Β ΐΦΑΝ¥≥―ΩΕΛξ≤ΨΧΨ) |
| KANA8BIT | (ΙώΗλΦ≠≈Β ΐΦΑ»Ψ≥―ΩΕΛξ≤ΨΧΨ) |
| JISCODE | (JIS Ξ≥ΓΦΞ…ΓΠΞΤΓΦΞ÷Ξκ) |
3.3.4 Μ≈ΆΆΞ’ΞΓΞΛΞκΟφΛ«ΛΈΜ»Ά―Έψ
Α ≤ΦΛΥΜ»Ά―ΈψΛρΦ®ΛΖΛόΛΙΓΘ
$ SORT/SPECIFICATION=SPEC.SRT DATA.DAT OUT.DAT |
SPEC.SRT ΛœΑ ≤ΦΛΈΛ»ΛΣΛξΛ«ΛΙΓΘ
/FIELD=(NAME=KASHIRA, POSITION:1, SIZE:2, SOKAKU) ------(1) /FIELD=(NAME=NAMAE, POSITION:1, SIZE:20, BUSHU) ------(2) /FIELD=(NAME=JUSHO, POSITION:21, SIZE:56) ------(3) /KEY=NAMAE ------(4) /DATA=JUSHO ------(5) /DATA=" " ------(6) /DATA=NAMAE ------(7) /CONDITION=(NAME=LEIWA, TEST=(KASHIRA LE "¥δ")) ------(8) /INCLUDE=(CONDITION=LEIWA) ------(9) |
(1)ΓΛ (2)ΓΛ (3) Λœ "KASHIRA"ΓΛ"NAMAE"ΓΛ"JUSHO" Λ»ΛΛΛΠ3ΛΡΛΈΞ’ΞΘΓΦΞκΞ…ΛρΡξΒΝΛΖΛόΛΙΓΘ (4)ΛΥΛηΛΟΛΤΓΛ"NAMAE" Ξ’ΞΘΓΦΞκΞ…ΛρΜ»ΛΟΛΤ1Ξ–ΞΛΞ»ΧήΛΪΛι 20 Ξ–ΞΛΞ»Λρ…τΦσΫγΛΥΞΫΓΦΞ»ΛΙΛκΛ≥Λ»Λ§ΜΊΡξΛΒΛλΛόΛΙΓΘΛ≥ΛΈΈψΛ«ΛœΓΛΝ¥…τΛΈΞλΞ≥ΓΦΞ…ΛρΫ–ΈœΛΙΛκΛΈΛ«ΛœΛ Λ·ΓΛ (8)ΓΛ (9) Λ«ΝΣ¬ρΛΖΛΩΞλΞ≥ΓΦΞ…ΛΈΛΏΛρΫ–ΈœΛΖΛόΛΙΓΘΛΡΛόΛξΓΛ"NAMAE" Ξ’ΞΘΓΦΞκΞ…ΛΈάηΤ§ΛΈ ΗΜζΛΈΝμ≤ηΩτΛ§ΓΛ "¥δ" ΛΈΝμ≤ηΩτ 8 Λ»Τ±ΛΗΛΪΓΛΛόΛΩΛœΨ·Λ ΛΛΞλΞ≥ΓΦΞ…ΛΈΞ«ΓΦΞΩΛάΛ±ΛρΫ–ΈœΛΙΛκΛ»ΛΛΛΠΛ≥Λ»Λ«ΛΙΓΘΫ–ΈœΞ’Ξ©ΓΦΞόΞΟΞ»Λœ (5)ΓΛ(6)ΓΛ(7) ΛΥΛηΛΟΛΤΜΊΡξΛΒΛλΛΤΛΛΛόΛΙΓΘ
Α ≤ΦΛΈ DATA-1 Λ§ DATA.DAT ΛΈΨλΙγΓΛ DATA-2 Λ§Ζκ≤ΧΛ»ΛΖΛΤ OUT.DAT ΛΥΫ–ΈœΛΒΛλΛόΛΙΓΘ
<DATA-1>
| ¥δ≈ΡάΩ | ≈λΒΰ≈‘άΛ≈ΡΟΪΕηΚυΨεΩε5ΟζΧή3Γί5 |
| Μ≥Υή…π¬ß | ≈λΒΰ≈‘Ωυ ¬Εη≤ΦΙβΑφΗΆ1ΟζΧή12Γί35 |
| «ρΦ·άΒΡΧ | ≈λΒΰ≈‘≥κΨΰΕηΒΒΆ≠2ΟζΧή24Γί10 άΕ…ςΝώ203ΙφΦΦ |
| Τ¬τ≤¬»ΰ | άιΆ’Η©άιΆ’Μ‘»ΡΝ“Ρ°1ΟζΧή2Γί5 |
| ΤΘΑφΒΉΖ― | ≈λΒΰ≈‘Έΐ«œΕηΥ≠ΕΧΟφ2ΟζΧή25 JBLΞ≥ΓΦΞί102ΙφΦΦ |
| »”≈ΡΫ®Αλ | ≈λΒΰ≈‘άΛ≈ΡΟΪΕη¬ε≈Ρ1ΟζΧή2Γί35 Υ≠ΟφΞόΞσΞΖΞγΞσ801Ιφ |
| ΤνΧνΆέΜ“ | ≈λΒΰ≈‘ΩΖΫ…Εη«œΨλ≤ΦΡ°3ΟζΧή1Γί1 |
| ΕαΤΘ≤¬Χά | ≈λΒΰ≈‘Ωυ ¬Εη¬γΒή1ΟζΧή3Γί13 Ω―άΗάνΞ≥ΓΦΞί304ΙφΦΦ |
| «»Τ§ΆέΑλ | ≈λΒΰ≈‘≥κΨΰΕηΦΤΥτ5ΟζΧή10Γί22 |
| ≈ΡΖΠΖρΜΑ | ≈λΒΰ≈‘Ωυ ¬Εη± Γ3ΟζΧή32Γί14 |
<DATA-2>
| ≈λΒΰ≈‘Ωυ ¬Εη≤ΦΙβΑφΗΆ1ΟζΧή12Γί35 | Μ≥Υή…π¬ß |
| ≈λΒΰ≈‘≥κΨΰΕηΦΤΥτ5ΟζΧή10Γί22 | «»Τ§ΆέΑλ |
| ≈λΒΰ≈‘Ωυ ¬Εη± Γ3ΟζΧή32Γί14 | ≈ΡΖΠΖρΜΑ |
| ≈λΒΰ≈‘≥κΨΰΕηΒΒΆ≠2ΟζΧή24Γί10 άΕ…ςΝώ203ΙφΦΦ | «ρΦ·άΒΡΧ |
| ≈λΒΰ≈‘άΛ≈ΡΟΪΕηΚυΨεΩε5ΟζΧή3Γί5 | ¥δ≈ΡάΩ |
| άιΆ’Η©άιΆ’Μ‘»ΡΝ“Ρ°1ΟζΧή2Γί5 | Τ¬τ≤¬»ΰ |
| ≈λΒΰ≈‘Ωυ ¬Εη¬γΒή1ΟζΧή3Γί13 Ω―άΗάνΞ≥ΓΦΞί3O4ΙφΦΦ | ΕαΤΘ≤¬Χά |
3.4 ΤϋΥήΗλΞΫΓΦΞ»/ΞόΓΦΞΗΓΠΞΒΞ÷ΞκΓΦΞΝΞσ
3.4.1 ΤϋΥήΗλΞΫΓΦΞ»/ΞόΓΦΞΗΓΠΞΒΞ÷ΞκΓΦΞΝΞσΛΈΒΓ«Ϋ
…ΗΫύ»«SORT/MERGE ΛœΑ ≤ΦΛΈΞΒΞ÷ΞκΓΦΞΝΞσΛρΡσΕΓΛΖΛΤΛΛΛόΛΙΓΘ
Λ≥ΛλΛιΛΈΞΒΞ÷ΞκΓΦΞΝΞσΛΈΜ»ΛΛ ΐΛδΞ―ΞιΞαΓΦΞΩΛ Λ…ΛΥΛΡΛΛΛΤΛœΓΛΓΊ OpenVMS Utility Routines Manual ΓΌΛόΛΩΛœΓΊ OpenVMS Programming Enviroment Manual ΓΌΛρΜ≤Ψ»ΛΖΛΤΛ·ΛάΛΒΛΛΓΘΤϋΥήΗλΞΫΓΦΞ»/ΞόΓΦΞΗΛ«ΛœΓΛ…ΗΫύ»« SORT/MERGE ΞΒΞ÷ΞκΓΦΞΝΞσΛΈΒΓ«ΫΛΥ≤ΟΛ®ΛΤΦΓΛΈΤϋΥήΗλΒΓ«ΫΛ§Ρ…≤ΟΛΒΛλΛΤΛΛΛόΛΙΓΘ
ΒΦΜςΞ«ΓΦΞΩΓΠΞΩΞΛΞΉΛ»ΛΖΛΤΑ ≤ΦΛΈΞ≥ΓΦΞ…Λ§Μ»Ά―Λ«Λ≠ΛόΛΙΓΘ
| SOR$K_SEQ_ONYOMI | ≤ΜΤ…ΛΏ |
| SOR$K_SEQ_KUNYOMI | Ζ±Τ…ΛΏ |
| SOR$K_SEQ_BUSHU | …τΦσΞ≥ΓΦΞ… |
| SOR$K_SEQ_SOKAKU | Νμ≤ηΩτ |
| SOR$K_SEQ_KOKUGO | ΙώΗλΦ≠≈Β ΐΦΑΝ¥≥―ΩΕΛξ≤ΨΧΨ |
| SOR$K_SEQ_KANA8BIT | ΙώΗλΦ≠≈Β ΐΦΑ»Ψ≥―ΩΕΛξ≤ΨΧΨ |
| SOR$K_SEQ_JISCODE | JIS Ξ≥ΓΦΞ…ΓΠΞΤΓΦΞ÷Ξκ |
Λ≥ΛλΛιΛΈΞ≥ΓΦΞ…Λœ SYS$LIBRARY:IMAGELIB.OLB ΛΥ¥όΛόΛλΛΤΛΛΛκΛΈΛ«ΓΛΤΟ ΧΛ ΜΊΡξΛ ΛΖΛΥΞξΞσΞ·ΜΰΛΥΦΪΤΑ≈ΣΛΥΞΜΞΟΞ»ΛΒΛλΛόΛΙΓΘΡΙΛΒΛœΞοΓΦΞ…( 16 Ξ”ΞΟΞ»)Λ«ΛΙΓΘ
3.4.2 ΞΫΓΦΞ»/ΞόΓΦΞΗΓΠΞΒΞ÷ΞκΓΦΞΝΞσΛΈΜ»Ά―Έψ
Λ≥ΛΈΞΉΞμΞΑΞιΞύΛœΓΛΞ’ΞΓΞΛΞκ " EXAM1.DAT " ΛΈΚ«ΫιΛΈ 12 Ξ–ΞΛΞ»ΓΛΛΡΛόΛξ6 ΗΜζΛΈΩΕΛξ≤ΨΧΨΞ’ΞΘΓΦΞκΞ…ΛρΙώΗλΦ≠≈ΒΫγΛΥΞΫΓΦΞ»ΛΖ " EXAM1OUT.DAT " ΛΥΫ–ΈœΛΖΛόΛΙΓΘ
IMPLICIT INTEGER*4 (A-Z)
INTEGER*2 KEYBUFF(5)
CHARACTER*9 IN_FILE
CHARACTER*12 OUT_FILE
EXTERNAL SOR$K_SEQ_KOKUGO
DATA IN_FILE, OUT_FILE /'EXAM1.DAT', 'EXAM1OUT.DAT'/
KEYBUFF(1) = 1 ! Number of KEY
KEYBUFF(2) = %LOC(SOR$K_SEQ_KOKUGO) ! Kokugo dictionary sequence
KEYBUFF(3) = 0 ! Ascending sort
KEYBUFF(4) = 0 ! Key offset
KEYBUFF(5) = 12 ! Size in bytes
STATUS = SOR$PASS_FILES(IN_FILE, OUT_FILE)
IF (.NOT. STATUS) GOTO 10
STATUS = SOR$BEGIN_SORT(KEYBUFF)
IF (.NOT. STATUS) GOTO 10
STATUS = SOR$SORT_MERGE( )
IF (.NOT. STATUS) GOTO 10
STATUS = SOR$END_SORT( )
IF (.NOT. STATUS) GOTO 10
STOP 'SUCCESS'
10 CONTINUE
STOP 'FAILURE'
END
|
Λ≥ΛΈΞΉΞμΞΑΞιΞύΛœΓΛΤΰΈœΛœΞ’ΞΓΞΛΞκ≈œΛΖΓΛΫ–ΈœΛœΞλΞ≥ΓΦΞ…≈œΛΖΛρΜ»ΛΟΛΤΛΛΛόΛΙΓΘΛόΛΩΞ≠ΓΦΛœ2ΛΡΛΔΛξΓΛ¬η1Ξ≠ΓΦΛœΝμ≤ηΩτΛ«ΨΚΫγΓΛ¬η2Ξ≠ΓΦΛœ…τΦσΞ≥ΓΦΞ…Λ«ΙΏΫγΛ»Λ ΛΟΛΤΛΛΛόΛΙΓΘ
C Define external functions and data and initialize
IMPLICIT INTEGER*4 (A-Z)
CHARACTER*80 RECBUF
CHARACTER*9 INPUTNAME !Input file name
INTEGER*2 KEYBUF(9) !Key definition buffer
EXTERNAL SS$_ENDOFFILE
EXTERNAL SOR$GK_RECORD
EXTERNAL SOR$K_SEQ_BUSHU !Bushu collating sequence
EXTERNAL SOR$K_SEQ_SOKAKU !Sokaku collating sequence
DATA INPUTNAME/'EXAM2.DAT'/
KEYBUF(1) = 2
KEYBUF(2) = %LOC(SOR$K_SEQ_SOKAKU) !Primary key SOKAKU
KEYBUF(3) = 0 !Ascending
KEYBUF(4) = 0 !offset 0
KEYBUF(5) = 10 !size 10
KEYBUF(6) = %LOC(SOR$K_SEQ_BUSHU) !Secondary key BUSHU
KEYBUF(7) = 1 !Descending
KEYBUF(8) = 0 !offset 0
KEYBUF(9) = 10 !size 10
SRTTYPE = %LOC(SOR$GK_RECORD)
C Pass SORT the file names.
ISTATUS = SOR$PASS_FILES(INPUTNAME)
IF (.NOT. ISTATUS) GOTO 10
C Initialize the work areas and keys.
ISTATUS = SOR$BEGIN_SORT(KEYBUF, , , , , , SRTTYPE, %REF(3))
IF (.NOT. ISTATUS) GOTO 10
C Sort the records.
ISTATUS = SOR$SORT_MERGE( )
IF (.NOT. ISTATUS) GOTO 10
C Now retrieve the individual records and display them.
5 ISTATUS = SOR$RETURN_REC(RECBUF)
IF (.NOT. ISTATUS) GOTO 6
ISTATUS = LIB$PUT_OUTPUT(RECBUF)
GOTO 5
6 IF (ISTATUS .EQ. %LOC(SS$_ENDOFFILE)) GOTO 7
GOTO 10
C Clean up the work areas and files.
7 ISTATUS = SOR$END_SORT()
IF (.NOT. ISTATUS) GOTO 10
STOP 'SORT SUCCESSFUL'
10 STOP 'SORT UNSUCCESSFUL'
END
|
Λ≥ΛΈΞΉΞμΞΑΞιΞύΛœΓΛ2ΛΡΛΈΤΰΈœΞ’ΞΓΞΛΞκΛΈΞόΓΦΞΗΛρΙ‘ΛΛΛόΛΙΓΘΞ≠ΓΦΛœΞΣΞ’ΞΜΞΟΞ»5ΛηΛξ 6Ξ–ΞΛΞ»ΛΡΛόΛξ¥ΝΜζ3 ΗΜζΛ«ΤΰΈœΞ’ΞΓΞΛΞκΛ§άΒ≥ΈΛΥΫγ»÷Λ…ΛΣΛξΛΥΛ ΛΟΛΤΛΛΛκΛΪΛρΞΝΞßΞΟΞ·ΛΖΛόΛΙΓΘ
#include <stsdef.h>
struct DESCRIPTOR {
int leng ;
char *ptr ;
};
globalvalue SOR$K_SEQ_ONYOMI,
SOR$M_SEQ_CHECK;
main(){
char infile1[] = "EXAM31.DAT" ,
infile2[] = "EXAM32.DAT" ,
outfile[]= "EXAM3OUT.DAT" ;
struct DESCRIPTOR
inptr1 ={strlen(infile1) , infile1},
inptr2 ={strlen(infile2) , infile2},
outptr ={strlen(outfile) , outfile};
short lrl, key[5] ;
int status, option;
/* initialize the key */
key[0] = 1 ; /* key no. */
key[1] = SOR$K_SEQ_ONYOMI ; /* onyomi */
key[2] = 0 ; /* ascend */
key[3] = 5 ; /* offset */
key[4] = 6 ; /* size */
lrl = 131; /* LRL */
option = SOR$M_SEQ_CHECK; /* check input sequence */
/* merge the files */
if (!((status=sor$pass_files(&inptr1, &outptr)) & STS$M_SUCCESS))
lib$stop(status);
if (!((status=sor$pass_files(&inptr2)) & STS$M_SUCCESS))
lib$stop(status);
if (!((status=sor$begin_merge(key, &lrl, &option)) & STS$M_SUCCESS))
lib$stop(status);
if (!((status=sor$end_sort()) & STS$M_SUCCESS))
lib$stop(status);
}
|
ΤϋΥήΗλΞΫΓΦΞ»/ΞόΓΦΞΗΛΥΛœΦΓΛΈά©Η¬ΜωΙύΛ§ΛΔΛξΛόΛΙΓΘ
| ΝΑΛΊ | ΦΓΛΊ | ΧήΦΓ | ΚςΑζ |