Reliable Transaction Router
Application Design Guide
Order Number: AA–REPMB–TE
January 2001
This guide explains how to design application programs for use with Reliable Transaction Router.
Revision/Update Information:
This manual supersedes the Reliable Transaction Router Application Design Guide, for Version 3.2.Software Version:
Reliable Transaction Router V4.0ã
2001 Compaq Computer CorporationCompaq, the Compaq logo, AlphaServer, TruCluster, VAX, and VMS Registered in U.S.
Patent and Trademark Office.
DECnet, OpenVMS, and PATHWORKS are trademarks of Compaq Information Technologies, L.P.
Microsoft, Windows, and Windows NT are trademarks of Microsoft Corporation.
Intel is a trademark of Intel Corporation.
UNIX and The Open Group are trademarks of The Open Group.
All other product names mentioned herein may be trademarks or registered trademarks of their respective companies.
Confidential computer software. Valid license from Compaq required for possession, use or copying. Consistent with FAR 12.211 and 12.212, Commercial Computer Software, Computer Software Documentation, and Technical Data for Commercial Items are licensed to the U.S. Government under vendor's standard commercial license.
Compaq shall not be liable for technical or editorial errors or omissions contained herein.
The information in this publication is subject to change without notice and is provided "AS IS" WITHOUT WARRANTY OF ANY KIND. THE ENTIRE RISK ARISING OUT OF THE USE OF THIS INFORMATION REMAINS WITH RECIPIENT. IN NO EVENT SHALL COMPAQ BE LIABLE FOR ANY DIRECT, CONSEQUENTIAL, INCIDENTAL, SPECIAL, PUNITIVE OR OTHER DAMAGES WHATSOEVER (INCLUDING WITHOUT LIMITATION, DAMAGES FOR LOSS OF BUSINESS PROFITS, BUSINESS INTERRUPTION OR LOSS OF BUSINESS INFORMATION), EVEN IF COMPAQ HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES. THE FOREGOING SHALL APPLY REGARDLESS OF THE NEGLIGENCE OR OTHER FAULT OF EITHER PARTY AND REGARDLESS OF WHETHER SUCH LIABILITY SOUNDS IN CONTRACT, NEGLIGENCE, TORT, OR ANY OTHER THEORY OF LEGAL LIABILITY, AND NOTWITHSTANDING ANY FAILURE OF ESSENTIAL PURPOSE OF ANY LIMITED REMEDY.
The limited warranties for Compaq products are exclusively set forth in the documentation accompanying such products. Nothing herein should be construed as constituting a further or additional warranty.
Table of Contents
Tolerating Storage Device Failure Tolerating Node FailureUsing Concurrent Servers
Using Threads
Using Multiple Partitions
Router Failover
Server Failover
Concurrent Servers
Standby Servers
Standby Support
The Cluster Environment
True Clusters
Host-Based Clusters
Recognized Clusters
Unrecognized Clusters
Clustered Resource Managers and Databases
Failure Scenarios with RTR Standby Servers
Shadow Servers
The Role of Quorum
Surviving on Two Nodes
Partitioning
Transaction Serialization
Transaction Serialization Detail
RTR Commit Group
Independent Transactions
CSN Ordering
CSN Boundary
Batch Processing Considerations
Recovery after a Failure
Journal Accessibility
Journal Sizing
Replay Anomalies
RTR Performance Tests
Summary
Concurrent Servers
Partitions and Performance
Facilities and Performance
Router Placement
Broadcast Messaging
Making Broadcasts Reliable
Large Configurations
Using Read-Only Transactions
Making Transactions Independent
Firewalls and RTR
Avoiding DNS Server Failures
Batch Procedures
Be Transaction Aware
Avoid Server-Specific Data
Be Independent of Time of Processing
Use Two Identical Databases for Shadow Servers
Make Transactions Self-Contained
Lock Shared Resources
Ensuring Atomicity
Ensuring Consistency
Ensuring Isolation
Ensuring Durability
Transaction Dependencies with Concurrent Servers
Server-Side Transaction Timeouts
Two-Phase Commit Process
Prepare Phase
Nested Transactions
Transactional Messages
Broadcast Messages
Flow Control
Sequencing of Broadcasts
Sequencing Relative to Transaction Delivery
Recovery of Broadcasts
Lost Broadcasts
Coping with Broadcast Loss
User Events
RTR Events
Oracle Locking
Privileges Required
Overriding Default Locking
Oracle Explicit Data Locking
Table Locks
Acquiring Row Locks
Setting SERIALIZABLE and ROW_LOCKING Parameters
Using the LOCK TABLE Statement
Summary of Locking Options
Non-Default Locking Behavior
Distributed Deadlocks
Providing Parallel Processing
Establishing Read-Only Sites
Data-Content Routing with the C++ API
Changing Transaction States
RTR Message Types
Message Processing Sequence
Accept Processing
Starting a Transaction
Identifying the Transaction
Accepting a Transaction
Rejecting a Transaction
Ending a Transaction
Processing Summary
Administering Transaction Timeouts
Two-Phase Commit
Initiating the Prepare Phase
Commit Phase
Explicit Accept, Explicit Prepare
Implicit Prepare, Explicit Accept
Server Transaction States
Router Transaction States
Recovery Examples
Recovery: Before Server Accepts
Recovery: After Server Accepts
Recovery: After Database is Committed
Recovery: After Beginning a New Transaction
Exception Transaction Handling
Coordinating Transactions
Integration of RTR with Resource Managers
Distributed Transaction Model
Broadcast Messaging Processes
User Events
RTR Events
Authentication Using Callout Servers
RTR C Application Programming Interface
Using the rtr.h Header File
RTR Command Line Interface
Designing an RTR Client/Server Application
The RTR Journal
Data Content Routing with Partitions or Key Ranges
Partitions or Key Ranges
Multithreading
RTR Call Sequence
RTR Message Types
Message Format Definitions
Using the XA Protocol
XA Oracle Example
Using XA with MS DTC
XA DTC Example
Using DECdtm
Nested Transactions
Nested Transaction Example
RTR Transaction Processing
Channel Identifier
Flags Parameter
Facility Name
Recipient Name
Event Number
Access Key
Key Segments
Partition or Key Range
Channel-Open Operation
Determining Message Status
Closing a Channel
Receiving on a Channel
User Handles
Message Reception Styles
Blocking Receive
Polled Receive
Signaled Receive
Starting a Transaction
Using the rtr_start_tx Call
Using the rtr_send_to_server Call
Using the rtr_reply_to_client Call
Identifying a Transaction
Committing a Transaction
Uncertain Transactions
Administering Transaction Timeouts
Two-Phase Commit
Prepare Phase
Commit Phase
Explicit Accept, Explicit Prepare
Implicit Prepare, Explicit Accept
Transaction Recovery
Failure before rtr_accept_tx
Failure after rtr_accept_tx
Changing Transaction State
Exception on Transaction Handling
Broadcast Messaging
Authentication Using Callout Servers
Router Callout Server
Backend Callout Server
Server Failover
Standby Servers
Shadow Servers
Making Transactions Independent
Server Failover
Standby Servers
Shadow Servers
Making Transactions Independent
User Events Example
RTR Events
Figures:
Figure 2-1: Transaction Flow with Concurrent Servers and Multiple Partitions
Figure 2-2: Transaction Flow on Standby Servers
Figure 2-3: RTR Standby Servers
Figure 2-4: Transaction Flow on Shadow Servers
Figure 2-5: Two Sites with Shadowing and Standby Servers
Figure 2-6: Configuration with Quorum Node
Figure 2-7: Commit Sequence Number
Figure 2-8: CSN Vote Window for the C++ API
Figure 2-9: CSN Vote Window for the C API
Figure 2-10: Recovery after a Failure
Figure 2-11: Single-Node TPS and CPU Load by Number of Channels
Figure 2-12: Single-Node TPS and CPU Load by Message Size
Figure 2-13: Two-Node TPS and CPU Load by Number of Channels
Figure 2-14: Two-Site Configuration
Figure 3-1: Transactional Shadow Servers
Figure 3-2: Shadow Servers and Third Common Database (not recommended)
Figure 3-3: Uncertain Interval for Transactions
Figure 3-4: Concurrent Server Commit Grouping
Figure 3-5: Transactional Messaging
Figure 3-6: Transactional Messaging Interaction
Figure 3-8: Scenario for Distributed Deadlock
Figure 4-1: Transactional Messaging with the C++ API
Figure 4-2: C++ API Calls for Transactional Messaging
Figure 4-3: Flow of a Transaction
Figure 5-1: RTR C API Calls for Transactional Messaging
Figure A-1: Transportation Example Configuration
Figure A-2: Stock Exchange Example
Figure A-3: Banking Example Configuration
Figure B-1: OpenVMS CI-Based Cluster
Figure B-2: Tru64 UNIX TruCluster Configuration
Figure B-3: Windows NT Cluster
Figure C-1: Server Events and States with Active Transaction Message Types
Figure C-2: Server States after Standby Events
Figure G-1: Dual-Rail Configuration with Network Cards on a Router
Figure G-2: Dual-Rail Configuration with Network Cards on a Frontend
Tables:
Table 3-1: Backend Transaction States
Table 3-2: Frontend Transaction States
Table 3-4: LOCK TABLE Statements
Table 3-5: Summary of Locking Options
Table 3-6: Non-Default Locking Behavior
Table 4-2: RTRServerTransactionController Methods
Table 4-3: RTRClientTransactionController Methods
Table 4-4: Prepare Phase Server States
Table 4-5: Commit Phase Server States
Table 4-6: Prepare Phase Router States
Table 4-7: Typical Server Application Transaction Sequences
Table 5-1: RTR C API Calls by Category
Table 5-3: How RTR Reports Aborted Transactions
Table 5-5: Client Action Based on Journal State
Table 5-6: Server Participation
The goal of this document is to assist the experienced application programmer in designing applications for use with Reliable Transaction Router (RTR). Here you will find conceptual information and some implementation details to assist in:
As an application programmer, you should be familiar with the following concepts:
If you are not familiar with these software concepts, you will need to augment your knowledge by reading, taking courses, or through discussion with colleagues. You should also become familiar with the other books in the RTR documentation kit, listed in Related Documentation. Before reading this document, become familiar with the information in Reliable Transaction Router Getting Started.
This document is intended to be read from start to finish; later you can use it for reference.
Additional resources in the RTR documentation kit include:
| Document | Description |
| Reliable Transaction Router Getting Started | Provides an overview of RTR for both the application developer and the system manager. This book is a prerequisite for the RTR Application Design Guide. |
| Reliable Transaction Router C++ Foundation Classes | Provides descriptions of C++ API classes and their associated methods, with code examples for methods. |
| Reliable Transaction Router C Application Programmer's Reference Manual | Explains how to design and code RTR applications; contains descriptions and examples of the RTR C API calls. |
| Reliable Transaction Router System Manager's Manual | Describes how to configure, manage, and monitor RTR. |
| Reliable Transaction Router Migration Guide | Explains how to migrate from RTR Version 2 to RTR Version 3. |
| Reliable Transaction Router Installation Guide | Describes how to install RTR. |
| Reliable Transaction Router Release Notes | Describes new features, changes, and known restrictions for RTR. |
Other books that can be helpful in developing your transaction processing application include:
A useful web site for tips and tutorials on Oracle SQL is http://photo.net/sql .
You will find additional information on RTR and existing implementations on the RTR web site http://www.compaq.com/products/software/middleware/rtr/ .
Compaq welcomes your comments on this guide. Please send your comments and suggestions by email to rtrdoc@compaq.com. Please include the document title, date from the title page, order number, section and page numbers in your message.
| Convention | Description |
| Example code | Programming examples are shown in a monospaced font. |
| Title | Titles of manuals and books are shown in italics. Italics are also used for emphasis. |
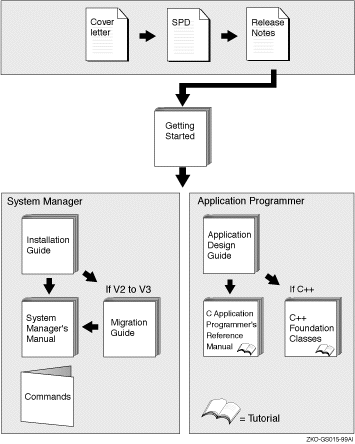
Figure 1 shows the reading path to follow when using the Reliable Transaction Router information set.
This document is for the application programmer who is developing an application for use with Reliable Transaction Router (RTR). Here you will find information on using RTR in the design and development of an application. The main emphasis is on providing design suggestions and considerations for writing the RTR application. Example designs describing existing applications that use RTR show implementations exploiting RTR features, and provide real examples where RTR is in use.
Note
Before reading this manual, read the prerequisite: RTR Getting Started, which describes basic RTR concepts and terminology.
The C++ object-oriented interface is new with RTR V4.0. Most of the material in this
document is generic to RTR and not specific to either the C or C++ API (application
programming interface). However, some implementation specifics for each API are shown in
appendices. Each API also has its own reference document, the RTR C++ Foundation
Classes manual for the C++ API, and the RTR C Application Programmer's Reference
Manual for the C API. This document also contains material specific to each API in
separate chapters.
In designing your application, Compaq recommends that you use object-oriented analysis and
design techniques, whether or not you are using the new object-oriented API. This
methodology includes the following:
Discussing this methodology is outside the scope of this document, but you can find more information in the following books, among others:
When designing your application:
A design flaw can be very expensive or impossible to correct in your application, so doing a thorough design, fully discussed and understood by your team, is essential to the ultimate success of your application in operation. One goal of this document is to help you understand some of the finer subtleties of the product, to help you design an optimum application.
Reliable Transaction Router (RTR) is transactional messaging middleware used to implement highly scalable, distributed applications with client/server technologies. With RTR, you can design and implement transaction management applications, take advantage of high availability, and implement failure-tolerant applications to maximize uptime. RTR helps ensure business continuity across multivendor systems and helps maximize uptime.
Implementing an application to use RTR embeds high availability capabilities in the application. Furthermore, RTR greatly simplifies the design and coding of distributed applications because, with RTR, client-server interactions can be bundled together in transactions. In addition, RTR applications can easily be deployed in highly available configurations.
RTR supports applications that run on different hardware and different operating systems. RTR has not been built to work with any specific database product or resource manager (file system, communication link, or queuing product), and thus provides an application the flexibility to choose the best product or technology suited for its purpose. There are, however, some resource managers with which RTR provides tight coupling. (For more information on using this tighter coupling, see the section in this manual on Using XA.) For specifics on operating systems, operating system versions, and supported hardware, see the Reliable Transaction Router Software Product Description for each supported operating system.
RTR provides several benefits for your application:
An application designed to work with RTR can take advantage of RTR failover capabilities and system availability solutions such as hardware clusters. Transactional shadowing and single input (no need to log on to another node after a failure) with input logging are additional features that provide RTR high availability. You can take advantage of configurations that tolerate process failure, node failure, network failure, and site failure.
To protect your data and transactions against unauthorized tampering, you can make use of the authentication server (also known as the callout server) available with RTR, as well as operating system security features and tunnels.
To ensure against loss of data, you will use RTR transactional shadowing. Transactional shadowing can be done at a single site or at geographically separate sites. In deploying your application, you may need to locate sites in different cities or on different power grids to help ensure against data loss.
To design your application for scalability, you can use a partitioned model that exploits RTR data-content routing. You will also consider hardware issues that constrain an application's high performance in processing transactions.
RTR provides programming interfaces for use in implementing applications that work with RTR, including:
The C++ API is described in the RTR C++ Foundation Classes manual and used in descriptions and examples in this manual. The C API is described in the RTR C Application Programmer's Reference Manual and used in examples in this manual.
The C++ API is an object-oriented application programming interface for RTR. With the C++ API, as an application developer, you can design and implement applications to take advantage of object-oriented (OO) design principles, including patterns and code reuse. The C++ API is backwards compatible and can be used for new applications or integrated into existing RTR applications.
As Figure 1-1 illustrates, the C++ API sits on top of the C API, which is a layer on top of RTR.

Client applications and server applications can use both the C++ API and the C API or just the C++ API. The C++ API maps RTR data elements, data structures, and C API functionality into the object-oriented design world.
C++ API and RTR Technology
The C++ API provides an object-oriented framework through which you can implement fault-tolerant systems.
The C++ API code resides beneath application or business logic code. Thus, the C++ API interfaces directly with RTR while application code does not. This transparency simplifies the development and implementation of transaction processing solutions with RTR.
OO Benefits
The C++ API was created to assist RTR customers who:
The benefits include:
With the C++ API, applications can inherit functionality from RTR.
The C++ API Provides Ease of Use
The C++ API provides a simplified way for you to implement RTR solutions. With the C++ API:
C++ API Design
The C++ API upgrades RTR technology by providing a set of classes that streamlines the development and implementation of RTR transaction processing applications. The C++ API has been designed to:
The C++ API can be used to:
The C++ API enables you to write management routines for both new and existing applications. Additionally, C++ API management classes simplify the process of moving from application design to implementation. For example, the RTRPartitionManager class enables you to write management routines for specifying server types, while methods such as CreateBackEndPartition enable you to specify the roles of servers for tolerating process and node failure.
The C API enables applications to be written with RTR calls using the C programming language. The C API is described in the Reliable Transaction Router C Application Programmer's Reference Manual.
To assist you in designing fault-tolerant RTR transaction processing applications, this chapter addresses configuration and design topics. Specifying how your RTR components are deployed on physical systems is called configuration. Developing your application to exploit the benefits of using RTR is called design or application design.
The following topics are addressed:
Short examples for both C++ and C APIs are available in appendices. The RTR C++ Foundation Classes manual and the RTR C Application Programmer's Reference Manual provide longer code examples. Code examples are also available with the RTR software kit in the examples directory.
To design an application to tolerate process failure, the application designer can use concurrent servers with partitions and possibly threads with RTR.
A concurrent server is an additional instance of a server application running on the same node as the original instance. If one concurrent server fails, the transaction in process is replayed to another server in the concurrent pool.
The main reason for using concurrent servers is to increase throughput by processing transactions in parallel, or to exploit Symmetric Multiprocessing (SMP) systems. The main constraint in using concurrent servers is the limit of available resources on the machine where the concurrent servers run. Concurrent servers deal with the same database partition. They may be implemented as multiple channels in a single process or as channels in separate processes. For an illustration of concurrent servers, see RTR Getting Started. By default, servers are declared concurrent.
When a concurrent server fails, the server application can fail over to another running concurrent server, if one exists. Concurrent servers are useful to improve throughput, to make process failover possible, and to help minimize timeout problems in certain server applications. For more information on this topic, see the section on Server-Side Transaction Timeouts later in this document.
Concurrent servers must not access the same file or the same record in a database table. This can cause contention for a single resource, with potential for performance bottleneck. The resources that you can usefully share include the database and access to global memory. However, an application may need to take out locks on global memory; this would need to be taken into account during design. With some applications, it may be possible to reduce operating system overhead by using multiple channels in a process.
Performance in a system is usually limited by the hardware in the configuration. Evaluating hardware constraints is described in the RTR System Manager's Manual. Given unlimited system resources, adding concurrency will usually improve performance. Before putting a new application or system built with RTR into production, the prudent approach is to test performance. You can then make adjustments to optimize performance. Do not design a system that immediately uses all the resources in the configuration because there will be no room for growth.
Using concurrency also improves reliability, because RTR provides server process failover (the "three strikes and you're out" rule) when you have concurrent servers.
In addition to using concurrent processes, an application can use the following methods to help improve performance:
An application designer may decide to use threads to have an application perform other tasks while waiting for RTR, for example, to process terminal input while waiting for RTR to commit a transaction or send a broadcast.
To use multiple threads, you write your application as a threaded application and use the shared thread library for the operating system on which your application runs. Use one channel per thread (with the C API), or one TransactionController per thread (with the C++ API). The application must manage the multiple processes.
To use multiple channels in a thread, with the RTR C API, use the polled receive method, polling for rtr_receive_message (C API) or Receive (C++ API). The application must contain code to handle the multiple channels or transaction controllers. This is by far the most complex solution and should only be used if it is not possible to use multiple threads or concurrent processes.
When using multiple threads in a process, the application must do the scheduling. One design using threads is to allocate a single channel for each thread. An alternative is to use multiple channels, each with a single thread. In this design, there are no synchronization issues, but the application must deal with different transactions on each thread.
Using multiple threads, design and processing is more streamlined. Within each thread, the application deals with only a single transaction at a time, but the application must deal with issues of access to common variables. It is often necessary to use mutexes (resource semaphores) and locks between resources.
To use multiple partitions in your application, your database must be designed with multiple partitions. You may also be able to use multiple partitions when you have multiple databases. In general, using multiple partitions can reduce resource contention and improve performance. In the case where contention for database resources is causing performance degradation, partitioning or repartitioning your database can improve performance. To reduce resource contention in a database:
When you have multiple databases to which transactions are posted, you can also design your RTR application to use partitions and thereby achieve better performance than without partitioning.
To configure a system that tolerates storage device failure well, consider incorporating the following in your configuration and software designs:
Further discussion of these devices is outside the scope of this document.
RTR failover employs concurrent servers, standby servers, shadow servers, and journaling, or some combination of these. To survive node failure, you can use standby and shadow servers in several configurations.
If the application starts up a second server for the partition, the server is a standby server by default.
Consider using a standby server to improve data availability, so that if your backend node fails or becomes unavailable, you can continue to process your transactions on the standby server. You can have multiple standby servers in your RTR configuration.
The time-to-failover on OpenVMS and Tru64 UNIX systems is virtually instantaneous; on other operating systems, this time is dictated by the cluster configuration that is in use.
The C++ API includes management classes that enable you to write management routines that can specify server type, while the C API uses flags on the open channel calls.
RTR deals with router failures automatically and transparently to the application. In the event of a router failure, neither client nor server applications need to do anything, and do not see an interruption in service. Consider router configuration when defining your RTR facility to minimize the impact of failure of the node where a router resides. If possible, place your routers on independent nodes, not on either the frontend or backend nodes of your configuration. If you do not have enough nodes to place routers on separate machines, configure routers with backends. This assumes a typical situation with many client applications on multiple frontends connecting to a few routers. For tradeoffs, see the sections on Design for Performance and Design for Operability sections of this chapter.
Provide multiple routers for redundancy. For configurations with a large number of frontends, the failure of a router causes many frontends to seek an alternate router. Therefore, configure sufficient routers to handle reconnection activity. When you configure multiple routers, one becomes the current router. If it fails, RTR automatically fails over to another.
For read-only applications, routers can be effective for establishing multiple sites for failover without using shadowing. To achieve this, define multiple, nonoverlapping facilities with the same facility name in your network. Then provide client applications in the facility with the list of routers. When the router for the active facility fails, client applications are automatically connected to an alternate site. Read-only transactions can alternatively be handled by a second partition running on a standby server. This can help reduce network traffic.
When a router fails, in-progress transactions are routed to another router if one is available in that facility.
Server failover in the RTR environment can occur with failure of concurrent, standby, transactional shadow servers, or a combination of these. Servers in a cluster have additional failover attributes. Conceptually, server process failures can be contrasted as follows:
Note
A standby server can be configured over nodes that are not in the same cluster, but recovery of a failed node's journal is not possible until a server is restarted on the failed node. You may decide to use a standby server in another cluster to increase site-disaster tolerance. (See the section on Configuration for Tolerating Site Disaster for more details on this configuration.)
Failover of any server is either event-driven or timer-based. For example, server loss due to process failure is event-driven and routinely handled by RTR. Server loss due to network link failure is timer-based, with timeout set by the SET LINK/INACTIVITY timer (default: 60 seconds). For more information on setting the inactivity timer, see the SET LINK command in the RTR System Manager's Manual.
The server type of a specific server depends on whether it is in a cluster environment and what other servers are declared for the same key range. In a cluster environment, a server declared as a standby and as a shadow becomes a standby server if there is another server for the same key range on the cluster. In a non-cluster environment, the server becomes a shadow server. For example, Figure 2-1 illustrates the use of concurrent servers to process transactions for Partition A.
Figure 2-1: Transaction Flow with Concurrent Servers and Multiple Partitions
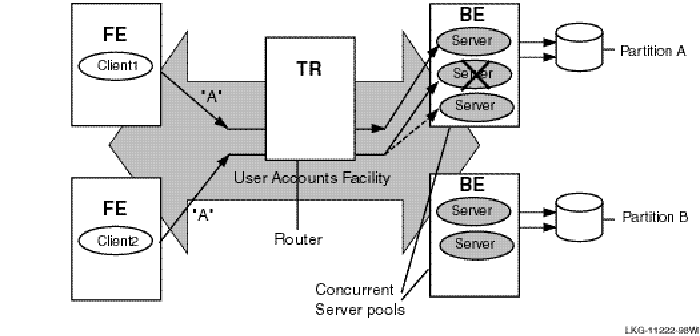
When one of the concurrent servers cannot service transactions going to partition A, another concurrent server (shown by the dashed line) processes the transaction. Failover to the concurrent server is transparent to the application and the user.
Concurrent Servers
Concurrent servers are useful in environments where more than one transaction can be performed on a database partition at one time to increase throughput.
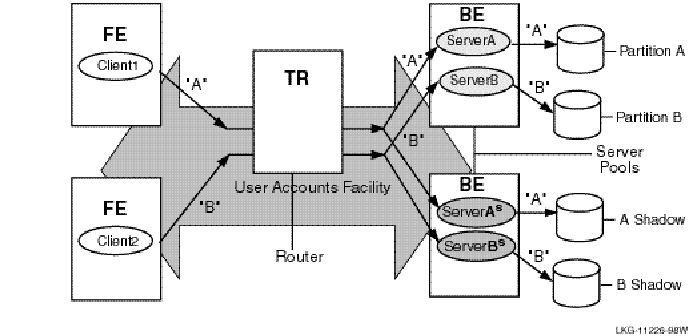
Standby Servers
Standby servers provide additional availability and node-failure tolerance. Figure 2-2 illustrates the processing of transactions for two partitions using standby servers.
Figure 2-2: Transaction Flow on Standby Servers
When the configuration is operating normally, the primary servers send transactions to the designated partition (solid lines); transactions "A" proceed through primary server A to database partition A and transactions "B" proceed through primary server B to database partition B. However, when the primary server fails, the router reroutes transactions "A" through the standby server A’ to partition A, and transactions "B" through the standby server B’ to database partition B. Note that standby servers for different partitions can be on different nodes to improve throughput and availability. For example, the bottom node could be the primary server for partition B, with the top node the standby. The normal route is shown with a solid line, the standby route with a dashed line.
When the primary path for transactions intended for a specific partition fails, the standby server can still process the transactions. Standby servers automatically take over from the primary server if it fails, transparently to the application. Standby servers recover all in-progress transactions and replay them to complete the transactions.
As shown in Figure 2-2, there can be multiple standby servers for a partition.
Failover and transaction recovery behave differently depending on whether server nodes are in a cluster configuration. Not all "cluster" systems are recognized by RTR; RTR recognizes only the more advanced or "true" cluster systems.
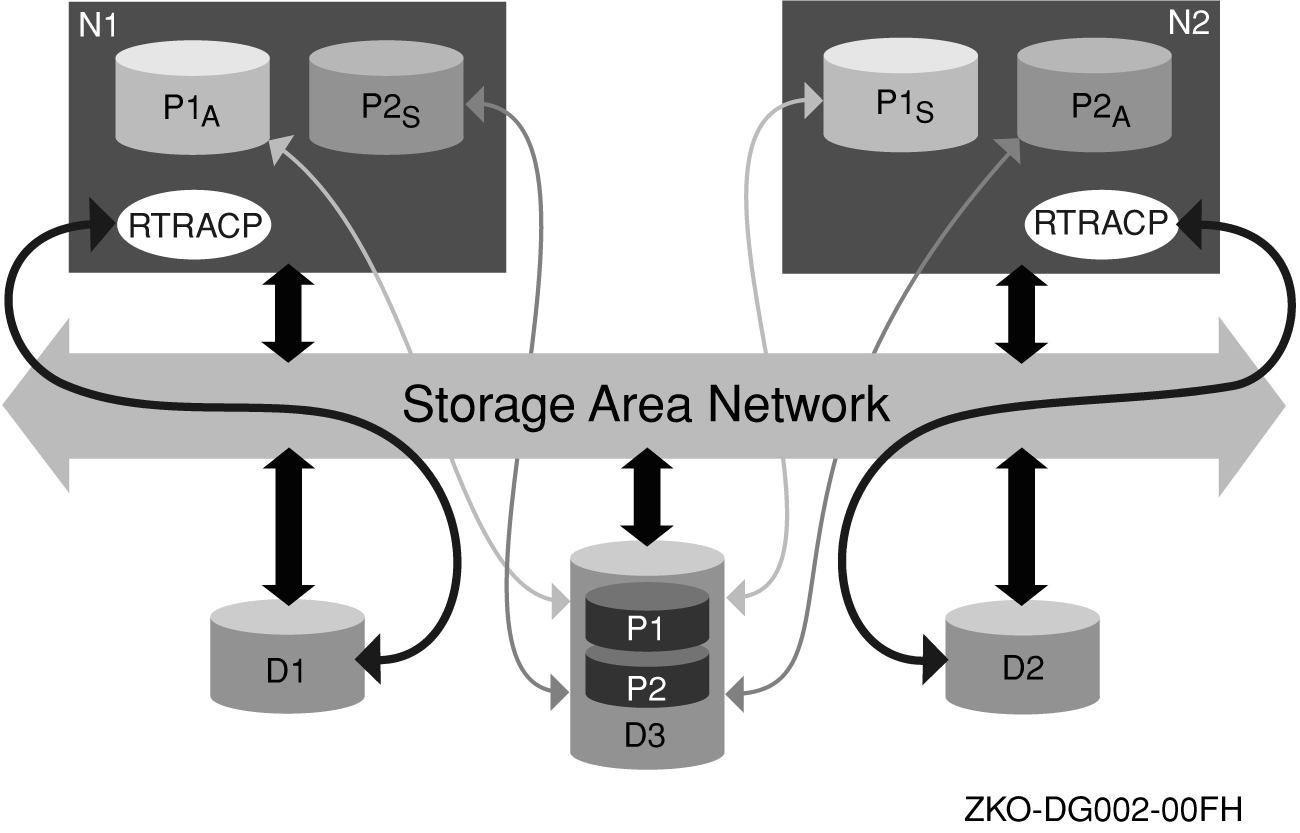
Figure 2-3 shows the components that form an RTR standby server configuration. Two nodes, N1 and N2, in a cluster configuration are connected to shared disks D1, D2 and D3. Disks D1 and D2 are dedicated to the RTR journals for nodes N1 and N2 respectively, and D3 is the disk that hosts the clustered database. This is a partitioned database with two partitions, P1 and P2. Under normal operating conditions, the RTR active server processes for each partition, P1A and P2A run on nodes N1 and N2 respectively. The standby server processes for each partition run on the other node, that is, P1S runs on N2 and P2S runs on N1. In this way, both nodes in the cluster actively participate in the transactions and at the same time provide redundancy for each other. In case of failure of a node, say N1, the standby server P1S is activated by RTR and becomes P1A and continues processing transactions without any loss of service or loss of in-flight transactions. Both the active and standby servers have access to the same database and therefore both can process the same transactions.
Figure 2-3: RTR Standby Servers
Failover between RTR standby servers behaves differently depending on the type of cluster where RTR is running. Actual configuration and behavior of each type of cluster depends on the operating system and the physical devices deployed. For RTR, configurations are either true clusters or host-based clusters.
True Clusters
True clusters are systems that allow direct and equal access to shared disks by all the nodes in the cluster, for example OpenVMS and Tru64 UNIX (Version 5.0). Since concurrent access to files must be managed across the cluster, a distributed lock manager (DLM) is typically used as well. Since all cluster members have equal access to the shared disks, a failure of one member does not affect the accessibility of other members to the shared disks. This is the best configuration for smooth operation of RTR standby servers. In such a cluster configuration, RTR failover occurs immediately if the active node goes down.
Host-Based Clusters
Host-based clusters include MSCS on Windows NT, Veritas for Solaris, IBM AIX and Tru64 UNIX (versions before 5.0). These clusters do not allow equal access to the disks among cluster members. There is always one host node that mounts the disk locally. This node then makes this disk available to other cluster members as a shared disk. All cluster members accessing this disk communicate through the host. In such a configuration, failure of the host node affects accessibility of the disks by the other members. They will not be able to access the disks until the host-based cluster software appoints another host node and this node has managed to mount the disks and export them. This will cause a delay in the failover, and also introduces additional network overhead for the other cluster members that need to access the shared disks.
Recognized Clusters
The cluster systems currently recognized by RTR are: OpenVMS, and TruCluster systems on Tru64 UNIX. Cluster behavior affects how the standby node fails over and how transactions are recovered from the RTR journal. For RTR to coordinate access to the shared file system across the clustered nodes, it uses the Distributed Lock Manager on both OpenVMS and Tru64 UNIX.
Failover
When the active server goes down, RTR fails over to the standby server. Before that, RTR on the upcoming active node attempts to perform a scan of the failed node’s journal. Since this is a clustered system, the cluster manager fails over the disks as well to the new active node. RTR will wait for this failover to happen before it starts processing new transactions.
Transaction Recovery
In all the recognized clusters, whenever a failover occurs, RTR attempts to recover all the in-doubt transactions from the failed node’s journal and replay them to the new active node. If RTR on the upcoming active server node cannot access the journal of the node that failed, it waits until the journal becomes accessible. This wait allows for any failover time in the cluster disks. This is particularly relevant in host-based clusters (for example, NT clusters) where RTR must allow time for a new host to mount and export the disks. If after a certain time the journal is still inaccessible, the partition state goes into local recovery fail. In such a situation, the system manager must complete the failover of the cluster disks manually. If this succeeds, RTR can complete the recovery process and continue processing new transactions.
Unrecognized Clusters
The current version of RTR does not recognize the cluster systems available for Sun Solaris, NT, HP-UX or IBM AIX.
Failover
When the active server goes down, RTR fails over to the standby server. RTR treats unrecognized cluster systems as independent non-clustered nodes. In this case, RTR scans for the failed node's journal among the valid disks accessible to it. However if it does not find it, it does not wait for it, as with recognized clusters. Instead, it changes to the active state and continues processing new transactions.
Transaction Recovery
As in the case of recognized clusters, whenever a failover occurs, RTR attempts to recover all the in-doubt transactions from the failed node’s journal and replay them to the new active node. If the failover of the cluster disks happens fast enough so that when the new active node does the journal scan, the journal is visible, RTR will recover any in-doubt transactions from the failed node’s journal. However, if the cluster disk failover has not yet happened, RTR does not wait. RTR changes the standby server to the active state and continues processing new transactions. Note that this does not mean that the transactions in the failed node’s journal have been lost, as they will remain in the journal and can be recovered. See the RTR System Manager’s Manual for information on how to do this.
Clustered Resource Managers and Databases
When RTR standby servers work in conjunction with clustered resource managers such as Oracle RDB or Oracle Parallel Server, additional considerations apply. These affect mainly the performance of the application and are relevant only to those cluster systems that do not have "true" cluster file systems. OpenVMS and Tru64 UNIX V5.0 both have "true" cluster file systems.
Other cluster file systems host their file systems on one node and export the file system to the remaining nodes. In such a scenario, the RTR server could be working with a resource manager on one node that has its disks hosted on another node; not an optimal situation. Ideally, disks should be local to the RTR server that is active. Since RTR only waits for the journals to become available, this is not synchronized with the failover of the Resource Manager’s disks. An even worse scenario occurs if both the RTR journal and the database disks are hosted on a remote node. In this case, the use of failover scripts is recommended to assist switching over in the most optimal way. Subsequent sections discuss this in more detail.
Failure Scenarios with RTR Standby Servers
In this section the various failure situations are analyzed in more detail. This can help system managers to configure the system in an optimal way.
Active Server Fails: Concurrent Servers Available
When the active server fails in the midst of a transaction, if there are other RTR servers for that partition on the same node (concurrent servers), RTR simply reissues the transaction to one of the other servers. Transaction processing is continued with the remaining servers. If the server fails due to a programming error, all the servers are likely to have the same error. Thus reissuing the same transaction to the remaining servers could cause all the concurrent servers to fail, one after another. RTR has a built-in protection against this so that if the same transaction knocks out three servers in a row, that transaction is aborted. The count three is the default value and can be configured to suit the application requirements. This behavior is the same whether or not RTR is run in a cluster.
Active Server Fails: Standby Servers Available
After the last available active server for a specific partition has failed, RTR tries to fail over to a standby server, if any exist. If no standby servers have been configured, the transaction is aborted. Take the case of the configuration shown in Figure 2-3. Assume that P1A (active server process for partition 1) has crashed on node N1. RTR will attempt to fail over to P1S. Before P1s can be given new transactions to process, it has to resolve any in-doubt transactions that are in N1’s journal sitting on D1. Therefore RTR on N2 scans the journal of N1 looking for any in-doubt transactions. If it finds any, these are reissued to the P1S. Once transaction recovery is completed, P1S then changes state to active and becomes the new P1A. In this case, since the RTR ACP is still alive, and since it is the RTR ACP on N1 that owns the journal on D1, RTR on N2 will do a journal scan via the RTR ACP on N1. This behavior is the same for both recognized and unrecognized clusters.
RTR ACP Fails: Standby Servers Available
If the RTR ACP fails, all the active servers on that node have their RTR channels closed and any transaction in progress is rejected. RTR tries to fail over to the standby server, if any exist. If no standby servers have been configured, the transaction is aborted. Take the case of the configuration shown in Figure 2-3. Assume that the ACP has crashed on node N1. RTR on the surviving node recognizes this and attempts to fail over to P1S. As before, a journal scan of N1’s journal must be done before changing to active state. Since the ACP on N1 has gone, this cannot be used for the journal scan. The ACP on N2 must do the journal scan on its own. In this case, the behavior is different on recognized and unrecognized clusters.
Journal Scan: Recognized Clusters
Because this is a cluster configuration, both nodes N1 and N2 can access the journal N1.J0 on D1. On "true" clusters RTR can directly access N1.J0 and on host-based clusters, RTR can access N1.J0 through the host node N1. Since the RTR ACP on N1 has failed, it will have released locks on N1.J0 making it free for the ACP on N2 to access. There is no failover time as the failure of the ACP on N1 is detected by RTR immediately. If a cluster transition causes D1 and D3 to be hosted on N2, this initiates the worst-case scenario, because the active server for P1A is running on N1 but will be accessing the database partition P1 through the host N2. Similarly, the RTR ACP on N1 will also access its journal N1.J0 through the host N2. Note that this inefficiency is not present in "true" clusters. Thus, wherever host-based clustering is used, any re-hosting of disks should result in a matching change in the active/standby configuration of the RTR servers as well. RTR events or failover scripts can be used to achieve this.
Journal Scan: Unrecognized Clusters
RTR treats unrecognized clusters as though they are not clusters. That is, RTR on the upcoming active server (N2) performs a journal scan. It searches among the disks accessible to it but does not specifically look for clustered disks. It also does not perform a journal scan on any NFS-mounted disks. If RTR on N2 can find the journal N1.J0, it performs a full recovery of any transactions sitting in this journal and then continues processing transactions. If it cannot find the journal (N1.J0), it just continues processing new transactions. It does not wait for journals to become available.
Active Node Fails: Standby Nodes Available
In this scenario, the node on which the active RTR servers are running fails. This causes a loss of a cluster node in addition to the RTR ACP and RTR servers. So, in addition to RTR failover, there is also a cluster failover. The RTR failover occurs as described above, with first a journal scan, transactions in the journal recovered, and then changing the standby server to active (P1S
à P1A). As this also causes a cluster failover, the effects vary according to cluster type.Journal Scan: Recognized Clusters
Because RTR recognizes that it is in a cluster configuration, it will wait for the cluster management to fail over the disks to N.2. This failover process depends on whether it is a "true" cluster or a host-based cluster.
"True" Clusters
"True" clusters allow N.2 to access D.1 immediately and recover from the journal N1.J0 . This is because both N.1 and N.2 have equal access to the disk. Because the RTR ACP has gone down with the node, the DLM locks on N1.J0 are also released making it free for use by N.2. In this cluster configuration, the RTR failover occurs immediately when the active node goes down.
Host-Based Clusters
The failover is more complicated in host-based clusters. When N.1 goes down, the host for D.1 also disappears. The cluster software must then select a new host, N.2, in this case. It then proceeds to re-host D.1 on N.2. Once this has happened, D.1 will become visible from N.2. Now RTR proceeds with the usual journal scan and transaction recovery. Thus RTR failover time depends on cluster failover time.
Journal Scan: Unrecognized Clusters
RTR treats unrecognized clusters as though they were not clusters, that is, RTR on the upcoming active server node (N.2) will perform a journal scan. Since it does not have access to the RTR ACP on the node that just failed (N.1), it cannot read that journal. Since the unrecognized clusters are all host-based, there will be a failover time required to re-host D.1 on N.2. RTR will not wait for this re-hosting. It performs a journal scan for N1.J0, does not find it and so does not do any transaction recovery. RTR simply moves into the active state and starts processing new transactions.
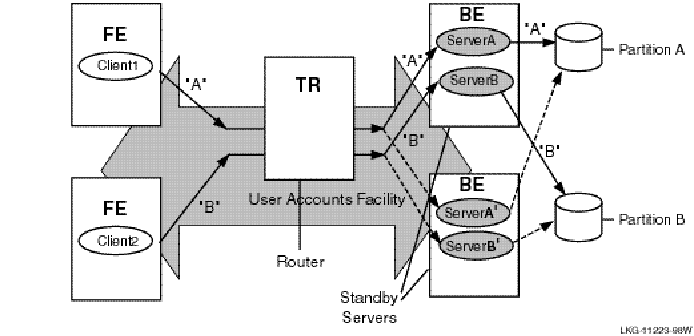
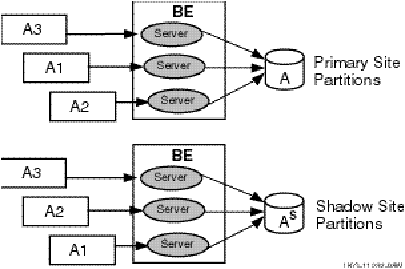
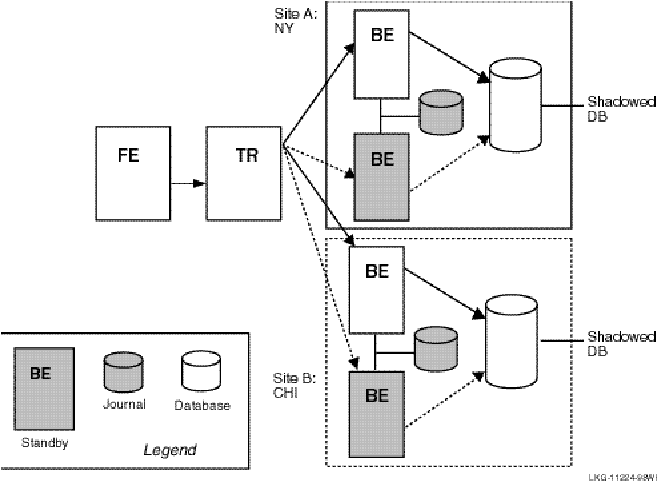
A transactional shadow server handles the same transactions as the primary server, and maintains an identical copy of the database on the shadow. Both the primary and the shadow server receive every transaction for their key range or partition. If the primary server fails, the shadow server continues to operate and completes the transaction. This helps to protect transactions against site failure. For greater reliability, a shadow server can have one or more standby servers. Figure 2-4 shows two primary servers, A and B, and their shadow servers, As and Bs.
Figure 2-4: Transaction Flow on Shadow Servers
To prevent database loss at an entire site, you can use either transactional shadowing or standby servers or both. For example, for the highest level of fault tolerance, the configuration should contain two shadowed databases, each supported by a remote journal, with each server backed up by a separate standby server.
With such a configuration, you can use RTR shadowing to capture client transactions at two different physically separated sites. If one site becomes unavailable, the second site can then continue to record and process the transactions. This feature protects against site disaster. Figure 2-5 illustrates such a configuration. The journal at each site is accessed by whichever backend is in use.
Figure 2-5: Two Sites with Shadowing and Standby Servers
To understand and plan for smooth inter-node communication you must understand quorum.
Quorum is used by RTR to ensure facility consistency and deal with potential network partitioning. A facility achieves quorum if the right number of routers and backends in a facility (referred to in RTR as the quorum threshold), usually a majority, are active and connected.
In an OpenVMS cluster
, for example, nodes communicate with each other to ensure that they have quorum, which is used to determine the state of the cluster; for cluster nodes to achieve quorum, a majority of possible voting member nodes must be available. In an OpenVMS cluster, quorum is node based. In the RTR environment, quorum is role based and facility specific. Nodes/roles in a facility that has quorum are quorate; a node that cannot participate in transactions becomes inquorate.RTR computes a quorum threshold based on the distributed view of connected roles. The minimum value can be two. Thus a minimum of one router and one backend is required to achieve quorum. If the computed value of quorum is less than two, quorum cannot be achieved. In exceptional circumstances, the system manager can reset the quorum threshold below its computed value to continue operations, even when only a minimum number of nodes, less than a majority, is available. Note, however, that RTR uses other heuristics, not based on simple computation of available roles, to determine quorum viability. For instance, if a missing (but configured) backend’s journal is accessible, that journal is used to count for the missing backend.
A facility without quorum cannot complete transactions. Only a facility that has quorum, whose nodes/roles are quorate, can complete transactions. A node/role that becomes inquorate cannot participate in transactions.
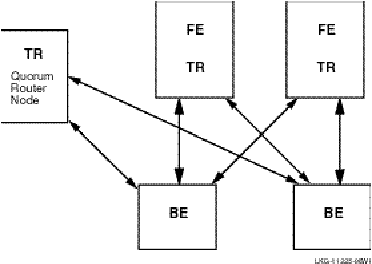
Your facility definition also has an impact on the quorum negotiation undertaken for each transaction. To ensure that your configuration can survive a variety of failure scenarios (for example, loss of one or several nodes), you may need to define a node that does not process transactions. The sole use of this node in your RTR facility is to make quorum negotiation possible, even when you are left with only two nodes in your configuration. This quorum node prevents a network partition from occurring, which could cause major update synchronization problems.
Note that executing the CREATE FACILITY command or its programmatic equivalent does not immediately establish all links in the facility, which can take some time and depends on your physical configuration. Therefore, do not use a design that relies on all links being established immediately.
Quorum is used to:
If your configuration is reduced to two server nodes out of a larger population, or if you are limited to two servers only, you may need to make some adjustments in how to manage quorum to ensure that transactions are processed. Use a quorum node as a tie breaker to ensure achieving quorum.
Figure 2-6: Configuration with Quorum NodeFor example, with a five-node configuration (Figure 2-6) in which one node acts as a quorum node, processing still continues even if one entire site fails (only two nodes left). When an RTR configuration is reduced to two nodes, the system manager can manually override the calculated quorum threshold. For details on this practice, see the Reliable Transaction Router System Manager’s Manual.
Frequently with RTR, you will partition your database. Partitioning your database means dividing your database into smaller databases to distribute the smaller databases across several disk drives. The advantage of partitioning is improved performance because records on different disk drives can be updated independently - resource contention for the data on a single disk drive is reduced. With RTR, you can design your application to access data records based on specific key ranges. When you place the data for those key ranges on different disk drives, you have partitioned your database. How you establish the partitioning of your database depends on the database and operating systems you are using. To determine how to partition your database, see the documentation for your database system.
In some applications that use RTR with shadowing, the implications of transaction serialization need to be considered.
Given a series of transactions, numbered 1 through 6, where odd- numbered transactions are processed on Frontend A (FE A) and even- numbered transactions are processed on Frontend B (FE B), RTR ensures that transactions are passed to the database engine on the shadow in the same order as presented to the primary. This is serialization. For example, the following table represents the processing order of transactions on the frontends.
| Transaction Ordering on Frontends | |
| FE A | FE B |
| 1 | 2 |
| 3 | 4 |
| 5 | 6 |
The order in which transactions are committed on the backends, however, may not be the
same as their initial presentation. For example, the order in which transactions are
committed on the primary server may be 2,1,4,3,5,6, as shown in the following table.
| Transaction Ordering on
Backend - Primary BE A |
| 2 |
| 1 |
| 4 |
| 3 |
| 5 |
| 6 |
The secondary shadowed database needs to commit these transactions in the same order. RTR ensures that this happens, transparently to the application.
However, if the application cannot take advantage of partitioning, there can be situations where delays occur while the application waits, say, for transaction 2 to be committed on the secondary. The best way to minimize this type of serialization delay is to use a partitioned database. However, because transaction serialization is not guaranteed across partitions, to achieve strict serialization where every transaction accepts in the same order on the primary and on the shadow, the application must use a single partition.
Not every application requires strict serialization, but some do. For example, if you are moving $20, say, from your savings to your checking account before withdrawing $20 from your checking account, you will want to be sure that the $20 is first moved from savings to checking before making your withdrawal. Otherwise you will not be able to complete the withdrawal, or perhaps, depending upon the policies of your bank, you may get a surcharge for withdrawing beyond your account balance. Or a banking application may require that checks drawn be debited first on a given day, before deposits. These represent dependent transactions, where you design the application to execute the transactions in a specific order.
If your application deals only with independent transactions, however, serialization will probably not be important. For example, an application that tracks payment of bills for a company would consider that the bill for each customer is independent of the bill for any other customer. The bill-tracking application could record bill payments received in any order. These would be independent transactions. An application that can ignore serialization will be simpler than one that must include logic to handle serialization and make corrections to transactions after a server failure.
In addition to dependent transactions that can make serialization more complex, if the application uses batch processing or concurrent servers, there may be difficulties with ensuring strict serialization, if the application requires it.
In a transactional shadow configuration using the same facility, the same partition, and the same key-range, RTR ensures that data in both databases are correctly serialized, provided that the application follows a few rules. For a description of these rules, see the Application Implementation chapter, later in this document. The shadow application runs on the backends, processes transactions based on the business and database logic required, and hands off transactions to the database engine that updates the database. The application can take advantage of multiple CPUs on the backends.
Transactions are serialized by accept committing them in chronological order within a partition. Do not share data records between partitions because they cannot be serialized correctly on the shadow site.
Dependent transactions operate on the same record and must be executed in the same order on the primary and the secondary servers. Independent transactions do not update the same data records and can be processed in any order.
RTR relies on database locking during its accept phase to determine if transactions executing on concurrent servers within a partition are dependent. A server that holds a lock on a data record during its vote call (AcceptTransaction for the C++ API or rtr_accept_tx for the C API) blocks other servers from updating the same record. Therefore only independent transactions can vote at the same time.
RTR tracks time in cycles using windows; a vote window is the time between the close of one commit cycle and the start of the next commit cycle.
RTR Commit Group
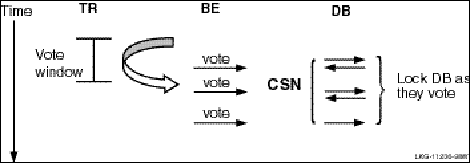
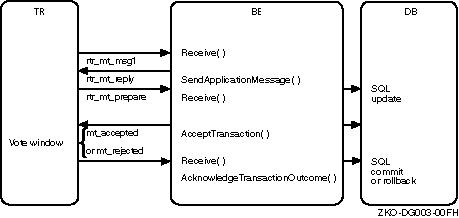
RTR commit grouping enables independent transactions to be scheduled together on the shadow secondary. A group of transactions that execute an AcceptTransaction (or rtr_accept_tx call for the C API) call within a vote window form an RTR commit group, identified by a unique commit sequence number (CSN). For example, given a router (TR), backend (BE), and database (DB), each transaction sent by the backend to the database server is represented by a vote. When the database receives each vote, it locks the database and responds as voted. The backend responds to the router in a time interval called the vote window, during which all votes that have locked the database receive the same commit sequence number. This is illustrated in Figure 2-7.
To improve performance on the secondary server, RTR lets this commit group of transactions execute in any order on the secondary.
RTR reuses the current CSN if it determines that the current transaction is independent of previous transactions. This way, transactions can be sent to the shadow in a bunch.
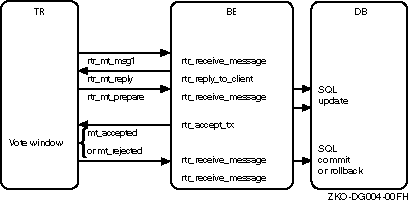
In a little more detail, RTR assumes that transactions within the vote window are independent. For example, given a router and a backend processing transactions, as shown in Figure 2-8, transactions processed between execution of AcceptTransaction and the final Receive that occurs after the SQL commit or rollback will have the same commit sequence number.
Figure 2-9 illustrates the vote window for the C API. Transactions processed between execution of the rtr_accept_tx call and the final rtr_receive_message call that occurs after the SQL commit or rollback will have the same commit sequence number.
Not all database managers require locking before the SQL commit operation. For example, some insert calls create a record only during the commit operation. For such calls, the application must ensure that the table or some token is locked so that other transactions are not incorrectly placed by RTR in the same commit group.
All database systems do locking at some level, at the database, file, page, record, field, or token level, depending on the database software. The application designer must determine the capabilities of whatever database software the application will interface with, and consider these in developing the application. For full use of RTR, the database your application works with must, at minimum, be capable of being locked at the record level.
When a transaction is specified as being independent (using the SetIndependentTransaction parameter set to true in the AcceptTransaction method (C++ API) or with the INDEPENDENT flag (C API)), the current commit sequence number is assigned to the independent transaction. Thus the transaction can be scheduled simultaneously with other transactions having the same CSN, but only after all transactions with lower CSNs have been processed.
RTR tracks time in cycles using windows; a vote window is the time between the close of one commit cycle and the start of the next commit cycle. For example, independent transactions include transactions such as zero-hour ledger posting (posting of interest on all accounts at midnight), and selling bets (assuming that the order in which bets are received has no bearing on their value).
RTR examines the vote sequence of transactions executing on the primary server, and determines dependencies between these transactions. The assumption is: if two or more transactions vote within a vote window, these transactions could be processed in any order and still produce the same result in the database. Such a group of transactions is considered independent of other transaction groups. Such groups of transactions that are mutually independent may still be dependent on an earlier group of independent transactions.
CSN Ordering
CSN Boundary
To force RTR to provide a CSN boundary, the application must:
- Use dependent transactions. This is the default behavior.
- Ensure that a transaction is voted on after any transactions on which it is dependent.
The CSN boundary is between the end of one CSN and the start of the next, as represented by the last transaction in one commit group and the first transaction in the subsequent commit group.
In practice, for the transaction to be voted on after its dependent transactions, it is enough for the dependent transaction to access a common database resource, so that the database manager can serialize the transaction correctly.
Dependent transactions do not automatically have a higher CSN. To ensure a higher CSN, the transaction also needs to access a record that is locked by a previous transaction. This will ensure that the dependent transaction does not vote in the same vote cycle as the transaction on which it is dependent. Similarly, transactions that are independent do not automatically all have the same CSN. In particular, for the C API, if they are separated by an independent transaction, that transaction creates a CSN boundary.
RTR commit grouping enables independent transactions to be scheduled together on the shadow secondary. Flags on
rtr_accept_tx and rtr_reply_to_client enable an application to signal RTR that it is safe to schedule this transaction for execution on the secondary within the current commit sequence group. In a shadow environment, an application can obtain certain performance improvements by using independent transactions where suitable. With independent transactions, transactions in a commit group can be executed on the shadow server in a different order than on the primary. This reduces waiting times on the shadow server. For example, transactions in a commit group can execute in the order A2, A1, A3 or the primary partition and in the order A1, A2, A3 on the shadow site.Of course independent transactions can only be used where transaction execution need not be strictly the same on both primary and shadow servers. Examples of code fragments for independent transactions are shown in the code samples appendices of this manual.
Batch Processing Considerations
Some of your applications may rely on batch processing for periodic activity. Application facilities can be created with batch processing. (The process for creating batch jobs is operating-system specific, and is thus outside the scope of this document.) Be careful in your design when using batch transactions. For example, accepting data in batch from legacy systems can have an impact on application results or performance. If such batch transactions update the same database as online transactions, major database inconsistencies or long transaction processing delays can occur.
Recovery after a Failure
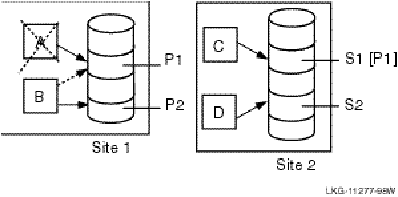
An example of a typical failure scenario follows. The basic configuration setup is RTR with a database manager such as Sybase, that does not take advantage of Memory Channel in the Tru64 UNIX TruCluster. There are four data servers, A and B at Site 1, and C and D at Site 2, with just two partitions, 1 and 2, as shown in Figure 2-10. The database is shadowed.
Site 1 A runs Primary Partition P1
B runs Primary Partition P2 and is a standby to A for P1
Site 2 C runs Shadow Partition S1
D runs Shadow Partition S2
Figure 2-10: Recovery after a Failure
The goal for this environment is to be able to survive a "double hit," without
any loss of performance. While A is down, there is a window during which there is a single
point of failure in the system. To meet this need, a standby server can be launched on
machine B as a new P1, and the transactions being journaled in [P1] on C can be played
across to Site 1. This can be done without any downtime, and P1 on C can continue to
accept new transactions. When the playing across is finished, recovery is complete because
all new transactions will be sent to both [P1] on C and P1 on B.
In more detail, the following sequence of events occurs:
The fact that node A is not accessible does not prevent B from being able to shadow P1 on node C. In this configuration, the absence of node A is unlikely to cause a quorum outage.
The RTR journal on each node must be accessible to be used to replay transactions. When setting up your system, consider both journal sizing and how to deal with replay anomalies.
To size a journal, use the following rough estimates as guidelines:
Use of large transactions generally causes poor performance, not only for initial processing and recording in the database, but also during recovery. Large transactions fill up the RTR journals more quickly than small ones.
You can use the
RTR_STS_REPLYDIFF status message to determine if a transaction has been recorded differently during replay. For details on this and other status messages, see the RTR C++ Foundation Classes manual or the RTR C Application Programmer’s Reference Manual.You should also consider how the application is to handle secondary or shadow server errors and aborts, and write your application accordingly.
In designing for performance, take the following into account:
An important part of your application design will concern performance considerations: how will your application perform when it is running with RTR on your systems and network? Providing a methodology for evaluating the performance of your network and systems is beyond the scope of this document. However, to assist your understanding of the impact of running RTR on your systems and network, this section provides information on two major performance parameters:
This information is roughly scalable to other CPUs and networks. The material is based on empirical tests run on a relatively busy Ethernet network operating at 700 to 800 Kbps (kilobytes per second). This baseline for the network was based on FTP tests (doing file transfer using a File Transfer Protocol tool) because in a given configuration, network bandwidth is often a limiting factor in performance. For a typical CPU (for example, a Compaq AlphaServer 4100 5/466 4 MB) opening 80 to 100 channels with a small (100 byte) message size, a TPS (transactions per second) rate of 1400 to 1600 is usual.
Tests were performed using simple application programs (TPSREQ - client and TPSSRV - server) that use RTR Version 3 C API application programming interface calls to generate and accept transactions. (TPSREQ and TPSSRV are supplied on the RTR software kit.) The transactions consisted of a single message from client to server. The tests were conducted on OpenVMS Version 7.1 running on AlphaServer 4100 5/466 4 MB machines. Two hardware configurations were used:
In each configuration, transactions per second (TPS) and CPU-load (CPU%) consumed created by the application (app-cpu) and the RTR ACP process (acp-cpu) were measured as a function of the:
The transactions used in these tests were regular read/write transactions; there was no use of optimizations such as READONLY or ACCEPT_FORGET. The results for a single node with an incrementing number of channels are shown in Figure 2-11.
Figure 2-11 Single-Node TPS and CPU Load by Number of Channels
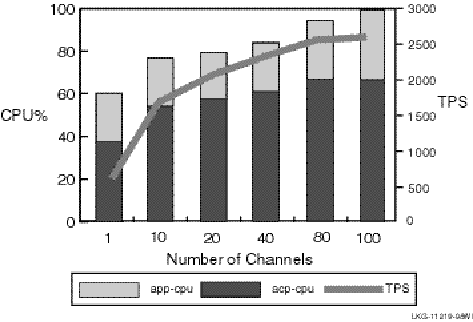
This test using 100-byte messages suggests the following:
The results for a single node with a changing message size are shown in Figure 2-12.
Figure 2-12: Single-Node TPS and CPU Load by Message Size
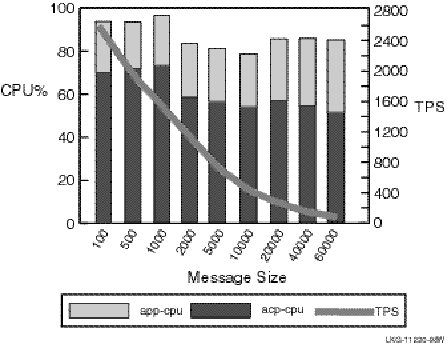
This test using 80 client and server channels suggests that:
The results for the two-node configuration are shown in Figure 2-13.
Figure 2-13: Two-Node TPS and CPU Load by Number of Channels
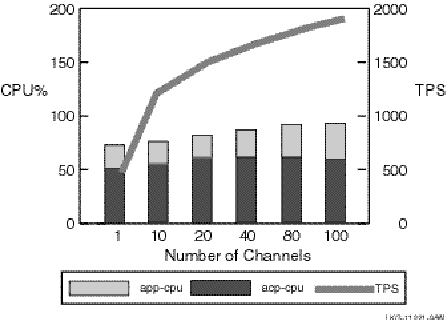
This two-node test using 100-byte messages provides CPU usage with totals for frontend and backend combined (hence a maximum of 200 percent). This test suggests that the constraint in this case appears to be network bandwidth. The TPS rate flattens out at a network traffic level consistent with that measured on the same LAN by other independent tests (for example, using FTP to transfer data across the same network links).
Determining the factors that limit performance in a particular configuration can be complex. While the previous performance data can be used as a rough guide to what can be achieved in particular configurations, they should be applied with caution. Performance will certainly vary depending on the capabilities of the hardware, operating system, and RTR version in use, as well as the work performed by the user application (the above tests employ a dummy application which does no real end-user work.)
In general, performance in a particular case is constrained by contention for a required resource. Typical resource constraints are:
Additionally, achieving a high TPS rate can be limited by:
For suggestions on examining your RTR environment for performance, see Appendix F in this document, Evaluating Application Resource Requirements.
Use concurrent servers in database applications to optimize performance and continue processing when a concurrent server fails.
When programming for concurrency, you must ensure that the multiple threads are properly synchronized so that the program is thread-safe and provides a useful degree of concurrency without ever deadlocking. Always check to ensure that interfaces are thread-safe. If it is not explicitly stated that a method is thread-safe, you should assume that the routine or method is not thread-safe. For example, to send RTR messages in a different thread, make sure that the methods for sending to server, replying to client and broadcasting events are safe. You can use these methods provided that the:
Partitioning data enables the application to balance traffic to different parts of the database on different disk drives. This achieves parallelism and provides better throughput than using a single partition. Using partitions may also enable your application to survive single-drive failure in a multi-drive environment more gracefully. Transactions for the failed drive are logged by RTR while other drives continue to record data.
To achieve performance goals, you should establish facilities spread across the nodes in your physical configuration using the most powerful nodes for your backends that will have the most traffic.
In some applications with several different types of transactions, you may need to ensure that certain transactions go only to certain nodes. For example, a common type of transaction is for a client application to receive a stock sale transaction, which then proceeds through the router to the current server application. The server may then respond with a broadcast transaction to only certain client applications. This exchange of messages between frontends and backends and back again can be dictated by your facility definition of frontends, routers, and backends.
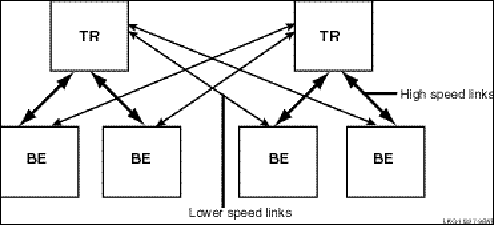
Placement of routers can have a significant effect on your system performance. With connectivity over a wide-area network possible, do not place your routers far from your backends, if possible, and make the links between your routers and backends as high speed as possible. However, recognize that site failover may send transactions across slower-speed links. For example, Figure 2-14 shows high-speed links to local backends, but lower-speed links that will come into use for failover.
Figure 2-14: Two-Site Configuration
Additionally, placing routers on separate nodes from backends provides better failover capabilities than placing them on the same node as the backend.
In some configurations, you may decide to use a dual-rail or multihome setup for a firewall or to improve network-related performance. (See Appendix G for information on this setup.)
When a server or client application sends out a broadcast message, the message passes through the router and is sent to the client or server application as appropriate. A client application sending a broadcast message to a small number of server applications will probably have little impact on performance, but a server application sending a broadcast message to many, potentially hundreds of clients, can have a significant impact. Therefore, consider the impact of frequent use of large messages broadcast to many destinations. If your application requires use of frequent broadcasts, place them in messages as small as possible. Broadcasts could be used, for example, to inform all clients of a change in the database that affects all clients.
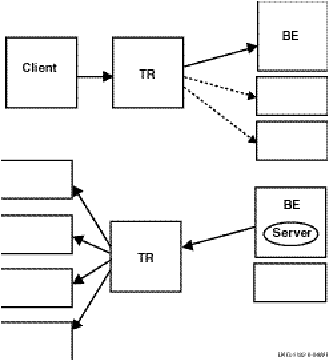
Figure 2-15 illustrates message fan-out from client to server, and from server to client.
You can also improve performance by creating separate facilities for sending broadcasts.
Making Broadcasts Reliable
To help ensure that broadcasts are received at every intended destination, the application might number them with an incrementing sequence number and have the receiving application check that all numbers are received. When a message is missing, have a retransmit server re-send the message.
Very large configurations with unstable or slow network links can reduce performance significantly. In addition to ensuring that your network links are the fastest you can afford and put in place, examine the volume of inter-node traffic created by other uses and applications. RTR need not be isolated from other network and application traffic, but can be slowed down by them.
Read-only transactions can significantly improve throughput because they do not need to be journaled. A read-only database can sometimes be updated only periodically, for example, once a week rather than continuously, which again can reduce application and network traffic.
When using transactional shadowing, it can enhance performance to process certain transactions as independent. When transactions are declared as independent, processing on the shadow server proceeds without enforced serialization. Your application analysis must establish what transactions can be considered independent, and you must then write your application accordingly. For example, bets placed at a racetrack for a specific race are typically independent of each other. In another example, transactions within one customer's bank account are typically independent of transactions within another customer’s account.
For examples of code snippets for each RTR API, see the appendices of samples in this manual.
Configuration for OperabilityTo help make your RTR system as manageable and operable as possible, consider several tradeoffs in establishing your RTR configuration. Review these tradeoffs before creating your RTR facilities and deploying an application. Make these considerations part of your design and validation process.
For security purposes, your application transactions may need to pass through firewalls in the path from the client to the server application. RTR provides this capability within the CREATE FACILITY syntax. See the RTR System Manager's Manual, Network Transports, for specifics on how to specify a node to be used as a firewall, and how to set up your application tunnel through the firewall.
Nodes in your configuration are often specified with names and IP or DECnet addresses fielded by a name server. When the name server goes down or becomes unavailable, the name service is not available and certain requests may fail. To minimize such outages, declare the referenced node name entries in a local host names file that is available even when the name server is not. Using a host names file can also improve performance for name lookups.
Operations staff often create batch or command procedures to take snapshots of system status to assist in monitoring applications. The character cell displays (ASCII output) of RTR can provide input to such procedures. Be aware that system responses from RTR can change with each release, which can cause such command procedures to fail. If possible, plan for such changes when bringing up new versions of the product.
In addition to understanding the RTR run-time and system management environments, you must also understand the RTR applications environment and the implications of that environment on your implementation. This section provides information on requirements that transaction processing applications must take into account and deal with effectively. It also cites rules to follow that can help prevent your application from violating the rules for ensuring that your transactions are ACID compliant. The requirements and rules complement each other and sometimes repeat a similar concept. Your application must take both into account.
Applications written to operate in the RTR environment should adhere to the following rules:
RTR expects server applications to be transaction aware; an application must be able to roll back an appropriate amount of work when asked. Furthermore, to preserve transaction integrity, rollback must be all or nothing. Each transaction incurs some overhead, and the application must be prepared to deal with failures and concomitant rollback gracefully.
When designing your client and server applications, note the outcome of transactions. Transactional applications often store data in variables that pertain to the operation taking place outside the control of RTR. Depending on the outcome of the RTR transaction, the values of these variables may need to be adjusted. RTR guarantees delivery of messages (usually to a database), but RTR does not know about any data not passed through RTR.
The rule is: Code your application to preserve transaction integrity through failures.
The client and server applications must not exchange any data that makes sense on only one node in the configuration. Such data can include, for example, a memory reference pointer, whose purpose is to allow the client to reference this context in a later transaction, indexes into files, node names, or database record numbers. These values only make sense on the machine on which they were generated. If your application sends data to another machine, that machine will not be able to interpret the data correctly. Furthermore, data cannot be shared across servers, transaction controllers, or channels.
The rule is: How you track state must be meaningful on all nodes where your application runs.
Transactions are assumed to contain all the context information required to be successfully executed. An RTR transaction is assumed to be independent of time of processing. For example, in a shadow environment, if the secondary server cannot credit an account because it is past midnight, but the transaction has already been successfully committed on the primary server, this would cause an inconsistency between the primary and secondary databases. Or, in another example, Transaction B cannot rely on the fact that Transaction A performed some operation before it.
Make no assumptions about the amount of time that will occur between transactions, and avoid using a transaction to establish a session with a server application that can time out. Such a timeout might occur in a client application that logs onto a server application that sets a timer to determine when to log the client off. If a crash occurs after a successful logon, subsequent transactions may fail because the logon session is no longer valid.
The rule is: If you have operations that must not be shadowed, identify them and exclude them from your application. Furthermore, do not keep a state that can become stale over time.
In your application, you can define transactions as independent with the C++ API, using the SetIndependentTransaction method in your transaction controller AcceptTransaction or SendApplicationMessage calls. Using the C API, you use the independent transaction flag in your rtr_accept_tx or rtr_reply_to_client calls.
For more information on the independent transaction methods in the RTRServerTransactionController class, see the RTR C++ Foundation Classes manual. For more information on the independent transaction flag and the different uses of these calls, see the RTR C Application Programmer’s Reference Manual.
Shadow server use is aimed at keeping two identical copies of the database synchronized. For example, Figure 3-1 illustrates a configuration with a router serving two backends to two shadow databases. The second router is for router failover.
Figure 3-1: Transactional Shadow Servers
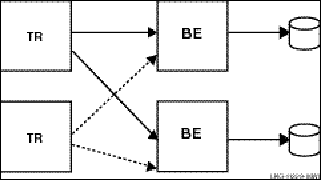
If an update of a copy triggers the update of a third common database, the application must determine whether it is running as a primary or a secondary, and only perform an update if it is the primary. Otherwise, there can be complex failure scenarios where duplication can occur.
For example, RTR has no way to determine if a transaction being shadowed is a one-time-only transaction, such as a bookstore debiting your credit card for the purchase of a book. If this transaction is processed on the primary node and the processed data fed to a third common database, and the transaction is later processed on the secondary node, your account would incorrectly be double charged. The application must handle this situation correctly.
The rule is: Design your application to deal correctly with transactions, such as debiting a credit card or bank account, that must never be performed more than once.
Figure 3-2 shows a configuration with two shadow servers and a third, independent server for a third, common database. This is not a configuration recommended for use with RTR without application software that deals with the kind of failure situation described above. Another method is to decouple the shadow message from the other branch.
Figure 3-2: Shadow Servers and Third Common Database (not recommended)
When updating a single resource through multiple paths, the recommended method is to use the RTR standby functionality.
All information required to process a transaction from the perspective of the server application should be contained within the transaction message. For example, if the application required a user-ID established earlier to successfully execute the transaction, the user-ID should be included in the transaction message.
The rule is: Construct complete transaction messages within your application.
While a server application is processing a transaction, and particularly before it "accepts" the transaction, it must ensure that all shared resources accessed by that transaction are locked. Failure to do so can cause unpredictable results in shadowing or recovery.
The rule is: Lock shared resources while processing each transaction.
To ensure that your application deals with transactions correctly, its transactions must be:
For the atomic attribute, the result of a transaction is all or nothing, that is, either totally committed or totally rolled back. To ensure atomicity, do not use a data manager that cannot roll back its updates on request. All standard data managers or database management systems have the atomicity attribute. However, in some cases, when interfacing to an external legacy system, a flat-file system, or an in-memory database, a transaction may not be atomic.
For example, a client application may believe that a transaction has been rejected, but the database server does not. With a database manager that can make this mistake, the application itself must be able to generate a compensating transaction to roll back the update.
Data managers that do not use XA/DTC, DECdtm or Microsoft DTC to integrate with RTR using XA or DECdtm must be programmed to handle rtr_mt_msg1_uncertain messages.
For example, to illustrate the atomicity rules, Figure 3-3 shows the uncertain interval in a transaction sequence that the application program must be aware of and take into account, by performing appropriate rollback.
Figure 3-3: Uncertain Interval for Transactions
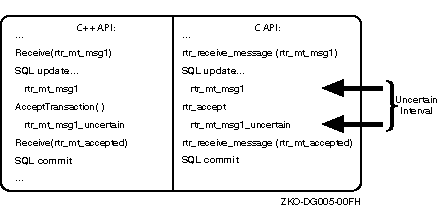
If there is a crash before the AcceptTransaction method (rtr_accept_tx statement for the C API) is executed, on recovery, the transaction is replayed as rtr_mt_msg1 because the database will have rolled back the prior transaction instance. However, if there is a crash after the AcceptTransaction method or rtr_accept_tx statement is executed, on recovery, the transaction is replayed as rtr_mt_msg1_uncertain because RTR does not know the status of the prior transaction instance. Your application must understand the implications of such failures and deal with them appropriately.
A transaction either creates a new and valid state of data, or, if any failure occurs, returns all data to its state as it was before the start of the transaction. This is called consistency.
Several rules must be considered to ensure consistency:
The changes to shared resources that a transaction causes do not become visible outside the transaction until the transaction commits. This makes transactions serializable. To ensure isolation:
Figure 3-4: Concurrent Server Commit Grouping
RTR commit grouping allows independent transactions to be scheduled together on the shadow secondary.
For a transaction to be durable, the changes caused by transaction commitment must survive subsequent system and media failure. Thus transactions are both persistent and stable.
For example, your bank deposit is durable if, once the transaction is complete, your account balance reflects what you have deposited.
The durability rule is:
Standby servers that update the database must have access to each other’s RTR journal, and use cluster-aware data managers such as Oracle Parallel Servers. If a node running as a standby server crashes, in-progress transactions will be recovered from the failed node’s journal files.
If there are dependencies between separate RTR transactions, these should be considered carefully because the locking mechanisms of resource managers can cause unexpected behavior. These issues around locking mechanisms occur only if there is more than one server for the same partition.
For example, consider the case where there is a transaction T1 which inserts a record in the database and a subsequent transaction T2 which uses that record to make another update. If the partition has been configured with concurrent servers, it can happen that the update transaction T2 which has been given to a free server will begin executing and reach the database before the insert operation issued by transaction T1 has completed the commit process. In this scenario, the inserted record is not yet visible to the update transaction T2 because the commit is not yet complete. This will cause transaction T2 to fail. However, if the database table being updated is locked for the duration of the insert, transaction T2 will block (wait) until the insert has committed and there will be no possibility of transaction T2 overtaking transaction T1.
In another example, the first transaction T1 makes an update to the table and a second transaction T2 uses the updated value in its transaction. If the resource manager does not lock the row being accessed by transaction T1 right at the start of the update, that row can be queried by the second transaction T2 which has started on a concurrent server. However, transaction T2 will in this case be working with the old and not the updated value that was the result of T1. To prevent such unexpected and potentially undesirable behavior, check the locking mechanisms of the resource managers being used before using concurrent servers.
RTR provides client applications the option to specify a transaction timeout, but has no provision for server applications to specify a timeout on transaction duration. If there is a scarcity of server application processes, all other client transactions remain queued. If these transactions have also specified timeouts, they are aborted by RTR (assuming that the timeout value is less than 2 minutes).
To avoid this problem, the application designer has two choices:
- Use concurrent server processes
- Have the application administer its own timeout
The first (and easier) option is to use concurrent server processes. This allows transaction requests to be serviced by other free servers, even if one server is occupied by such a transaction that is taking a long time to disappear. The second option is to design the server application so that it can abort the transaction independently.
There are three cases where this use of concurrent servers is not ideal. First, there is an implicit assumption about how many such lingering transactions might remain on the system. In the worst case, this could exceed or equal the number of client processes. But having so many concurrent server processes to cater to this contingency is wasteful of system resources. Second, use of concurrent servers is beneficial when the servers do not need to access a common resource. For instance, if all these servers needed to update the same record in the database, they would simply be waiting on a lock taken by the first server. Additional servers do not resolve this issue. Third, it must make business sense to have additional servers. For example, if transactions must be executed in the exact order in which they entered the system, concurrent servers may introduce sequencing problems.
Take the example of the order matcher in a stock trading application. Business rules may dictate that orders be matched on a first-come, first-matched basis; using concurrent servers would negate this rule.
The second option is to let the server application process administer its own timeout and abort the transaction when it sees no activity on its input stream.
To ensure that transactions are fully executed and that the database is consistent, RTR uses the two-phase commit process for committing a transaction. The two-phase commit process has both a prepare phase and a commit phase. Transactions must reach the commit phase before they are hardened in the database.
The two-phase commit mechanism is initiated by the client when it executes a call to RTR that declares that the client has accepted the transaction. The servers participating in the transaction are then asked to be prepared to accept or roll back the transaction, based on a subsequent request.
Prepare Phase
Transactions are prepared before being committed by accept processing. Table 3-1 lists backend transaction states that represent the steps in the prepare phase.
| Phase | State | Meaning |
| Phase 0 | WAITING | Waiting for a server to become free. |
| RECEIVING | Processing client messages. | |
| Phase 1 | VREQ | Vote of server requested. |
| VOTED | Server has voted and awaits final transaction status. | |
| Phase 2 | COMMIT | Final status of a committed transaction delivered to server. |
| ABORT | Final status of an aborted transaction delivered to server. |
The RTR frontend sees several transaction states during accept processing. Table 3-2 lists frontend transaction states that represent the steps in the prepare phase.
| State | Meaning |
| SENDING | Processing, not ready to accept. |
| VOTING | Accept processing in process; frontend has issued an rtr_accept_tx call, but the transaction has not been acknowledged. |
| DONE | Transaction is complete, either accepted or rejected. |
Implementation details are shown in the separate chapters for the RTR APIs.
An RTR transaction can be part of a transaction that is coordinated by a parent transaction manager such as RTR itself, or Tuxedo, or MS DTC. RTR lets transactions be embedded within other transactions; such transactions are called nested transactions or subtransactions. A nested transaction is considered indivisible within its enclosing transaction, typically coordinated by a parent transaction manager.
A transaction that is not nested is called a top-level transaction. A nested transaction is a child of its parent (enclosing) transaction. A parent may have several children who are siblings; ancestor and descendent relationships apply. A top-level transaction and its descendants are collectively known as a transaction family or a family.
A nested transaction must be strictly nested within its enclosing transaction; it must be completed (committed or aborted) before the enclosing transaction can complete. If the enclosing transaction aborts, all effects of the nested transaction are also undone.
A transaction can create several child transactions; the parent transaction performs no work until all child transactions are complete. A transaction cannot, however, observe the effects of a sibling transaction until that sibling completes.
Nested transactions isolate the effect of failures from the enclosing transaction and from other concurrent transactions. A nested transaction that has not completed can abort without causing its parent transaction to abort.
Committed nested transactions are durable (permanent) only with respect to certain other transactions: a committed child is permanent with respect to its parent. To stop a committed child, the parent transaction is stopped. The child is said to be committed with respect to its parent, or with respect to its siblings. Every transaction is committed with respect to itself and its descendants. To abort a committed nested transaction, all of its committed-with-respect-to transactions must be aborted.
With RTR, client/server messaging enables the application to send:
With RTR, client and server applications communicate by exchanging messages in a transaction dialog. Transactional messages are grouped in a unit of work called a transaction. RTR takes ownership of a message when called by the application.
A transaction is a group of logically connected messages exchanged in a transaction dialog. Each dialog forms a transaction in which all participants have the opportunity to accept or reject the transaction. A transaction either commits or aborts. When the transaction is complete, all participants are informed of the transaction’s completion status. The transaction succeeds if all participants accept it, but fails if even one participant rejects it.
In the context of a transaction, an RTR client application sends one or more messages to the server application, which responds with zero or more replies to the client application. Client messages can be grouped to form a transaction. All work within a transaction is either fully completed or all work is undone. This ensures transaction integrity from client initiation to database commit with the cooperation of the server application.
For example, say you want to take $20 from your checking account and add it to your savings account. With an application using RTR you are assured that this entire transaction is completed; you will not be left at the point where you have taken $20 from your checking account but it has not yet been deposited in your savings account. This feature of RTR is transactional integrity, illustrated in Figure 3-5.
Figure 3-5: Transactional Messaging
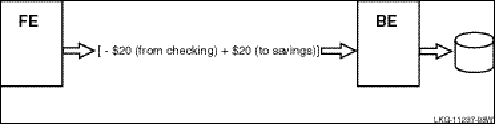
The transactional message is either all or nothing for everything enclosed in brackets [ ] in Figure 3-5.
An RTR client application sends one or more messages to one or more server applications and receives zero or more responses from one or more server applications. For example:
RTR generates a unique identifier, the transaction ID or TID, for each transaction. The client can inject also its own TID into RTR. Doing so will make RTR treat the transaction as a nested transaction.
Figure 3-6 illustrates frontend/backend interaction with pseudo-code for transactions and shows transaction brackets. The transaction brackets show the steps in completing all parts of a transaction, working from left to right and top to bottom. The transaction (txn) is initiated at "Start txn" at the frontend, and completed after the "Commit txn" step on the backend. The transaction ID is encoded to ensure its uniqueness throughout the entire distributed system. In the prepare phase on the server, the application should lock the relevant database (db) records. The commit of a transaction hardens the commit to the database. The
rtr_start_tx message specifies the characteristics of the transaction. RTR identifies the server based on key information in the transaction.Figure 3-6: Transactional Messaging Interaction
Broadcast messaging lets client and server applications send non-transactional information to recipients. Recipients must be declared with the opposite role; that is, a client can send a broadcast message to servers, and a server can send a broadcast message to clients. Broadcasts are delivered on a "best try" basis; they are not guaranteed to reach every potential recipient. A broadcast message can be directed to a specific client or server, or be sent to all reachable recipients.
This point-to-point messaging using broadcast semantics is a feature to use instead of transactions when the information being sent is not recorded as a transaction in the database, and when you need to send information to several clients (or servers) simultaneously. For example, in a stock trading environment, when a trade has been completed and the stock price has changed, the application can use a broadcast message to send the new stock price to all trading stations. Another use for such messages is to inform the applications about a state change in the environment (for example, the fact that the exchange is now closed for business).
Other considerations when using broadcast messages include:
Flow Control
Broadcast messages are subject to flow control. A broadcaster may be blocked and unable to send messages when traffic is high and recipients are unable to process the broadcasts. The broadcaster sends at the minimum rate (MINIMUM_BROADCAST_RATE) which can be set to send "no matter what" for a given node. However, if an application does this, the application may in practice hold up broadcasts for others, and application design must take this into account. For example, no client application should be able to issue a Control S (^ S) to hold up all broadcasts. If an application doing broadcasts works with transactions that might get held up, it may be time to consider using multiple channels on multiple threads.
Sequencing of Broadcasts
RTR guarantees that broadcasts are received in the same order as sent by a specific sender. However, if there is more than one sender in an application, different recipients can receive broadcasts in different orders. For example, Sender A could send broadcasts ABC and Sender B, broadcasts XYZ. These could be received by two different recipients as ABCXYZ or XYZABC. If this is important in your application, correct application design is to use one sender that takes in all input needed for such broadcasts.
Sequencing Relative to Transaction Delivery
Consider a shadowed trading environment that initiates 5PM processing with a broadcast for closing of the exchange. Application design should send broadcasts and transactions through different pipes. Because RTR does not guarantee receipt of a broadcast at all servers, but does guarantee receipt of transactions, this critical "broadcast" could be most effectively handled by being sent in a transaction as an event through the transaction pipe.
Recovery of Broadcasts
There is no replay or recovery for broadcasts.
Lost Broadcasts
A broadcast can sometimes be lost. This can be caused by link loss or perhaps when there is excessively high volume.
Coping with Broadcast Loss
There is overhead associated with managing and correcting for loss of broadcasts. Thus Compaq recommends that applications do not use broadcasts for critical information. If, however, an application decides to use broadcasts and wants to ensure that all broadcasts are accounted for, one approach is to add a tracking sequence number to each broadcast that is sent out. All recipients can then check for missing sequence numbers and request a resend of any missing broadcasts.
A client or server application may need to send unsolicited messages to one or more participants. Applications tell RTR which broadcast classes they want to receive.
The sender sends one message received by several recipients. Recipients subscribe to a specific type of message. Delivery is not guaranteed.
Broadcast messages can be:
Clients cannot broadcast to other clients, and servers cannot broadcast to other servers. To enable communication between two applications of the same type, open a second instance of the application of the other type. Messaging destination names can include wildcards, enabling flexible definition of the subset of recipients for a particular broadcast.
Broadcast types include user events and RTR events; both are numbered.
Event numbers are provided as a list beginning with RTR_EVTNUM_USERDEF and ending with RTR_EVTNUM_ENDLIST. To subscribe to all user events, an application can use the range indicators RTR_EVTNUM_USERBASE and RTR_EVTNUM_USERMAX, separated by RTR_EVTNUM_UP_TO, to specify all possible user event numbers.
A user broadcast is named or unnamed. An unnamed broadcast does a match on user event number; the event number completely describes the event. A named broadcast does a match on both user event number and recipient name. The recipient name is a user-defined string. Named broadcasts provide greater control over who receives a particular broadcast.
Named events specify an event number and a textual recipient name. The name can include wildcards (% and *).
For all unnamed events specify the evtnum field and RTR_NO_RCPSPC as the recipient name.
RTR delivers status information to which client and server applications can subscribe. Status information is delivered as messages, where the type of each message is an RTR event.
RTR events are numbered. The base value for RTR events is defined by the symbol RTR_EVTNUM_RTRBASE; its maximum value is defined by the symbol RTR_EVTNUM_RTRMAX. RTR events and event numbers are listed in the Reliable Transaction Router API manuals and in the RTR header files rtr.h and rtrapi.h.
An application can subscribe to RTR events to receive notification of external events that are of interest to the application. For example, a shadow server may need to know if it is a primary or a secondary server to perform certain work, such as uploading information to a central database, that is done at only one site.
To subscribe to all RTR events, use the range indicators RTR_EVTNUM_RTRBASE and RTR_EVTNUM_RTRMAX.
RTR events are delivered as messages of type rtr_mt_rtr_event.
In application design, consider creating separate facilities for sending broadcasts. By separating broadcast notification from transactional traffic, performance improvements can be substantial. Facilities can further be reconfigured to place the RTR routers strategically to minimize wide-area traffic.
A server application can expect to see a primary or secondary event delivered only in certain transaction states. For more detail, see the state diagrams in Appendix C, Server States.
With location transparency, applications do not need to be modified when the hardware configuration is altered, whether changes are made to systems running RTR services or to the network topology. Client and server applications do not know the location of one another so services can be started anywhere in the network. Actual configuration binding is a system management operation at run time, through the assignment of roles (frontend/backend/router) within a given facility to the participant nodes.
For RTR to automatically take care of failover, server applications need to specify certain availability attributes for the partition.
Because RTR automatically takes care of failover, applications need not be concerned with specifying the location of server resources.
RTR can provide information to an application with the RTRMessage and RTREvent classes (for the C++ API). Certain inherited methods within these classes translate RTR internal error message values to informational text meaningful to the reader. For the C API, this is done with the rtr_error_text call.
If an application encounters an error, it should log the error message received. Error messages are more fully described in rtrapi.h for the C++ API and in rtr.h for the C API, where each error code is explained.
For example, the following short program uses the standard C library output function to display the text of an error status code.
Program "prog":
#include "rtr.h"
or #include <rtr.h>When this program is run, it produces the following output:
$run prog
No license installed
The several hundred error or status codes reside in the rtr.h header file; status codes can come from any RTR subsystem. A few codes that an application is likely to encounter are described in Table 3-3.
| Status Code | Meaning |
| RTR_STS_COMSTAUNO | Commitment status unobtainable. The fate of the transaction currently being committed is unobtainable; this may be due to a hardware failure. |
| RTR_STS_DLKTXRES | The transaction being processed was aborted due to deadlock with other transactions using the same servers. RTR will replay the transaction after the deadlock has been resolved and cleared. |
| RTR_STS_FELINLOS | Frontend link lost; probably due to a network failure. |
| RTR_STS_INVFLAGS | Invalid flags. |
| RTR_STS_NODSTFND | No destination found; no server had declared itself to handle the key value specified in the sent message. Probably a server down or disconnected. |
| RTR_STS_OK | All is well; normal successful completion. |
| RTR_STS_REPLYDIFF | Two servers respond with different information during a replay; transaction aborted. |
| RTR_STS_TIMOUT | Timeout expired; transaction aborted. |
| RTR_STS_SRVDIED | Probably a server image exited, for example because a node is down. |
| RTR_STS_SRVDIEDVOT | A server exited before committing a transaction. |
| RTR_STS_SRVDIEDCOM | A server exited after being told to commit a transaction. |
RTR can abort a transaction at any time, so the application must be prepared to deal with such aborted transactions. Server applications are expected to roll back transactions as the need arises, and must be built to take the correct action, and subsequently carry on to deal with new transactions that are received.
A client application can also get a reject and must also be built to deal with the likely cases it will encounter. The application must be built to decide on the correct course of action in the event of a transaction abort.
When using a database system with RTR, an application designer must be aware of how the database system works and how it handles database locks. Because Oracle is a frequently used database system, this section provides a short summary of Oracle locking methods. The application designer must use Oracle documentation to supplement this brief description. This material is fully discussed in the Oracle8 and Oracle8i Application Developer's Guides, specifically in the chapters on Processing SQL Statements, Explicit Data Locking, Explicitly Acquiring Row Locks, Serializable and Row Locking Parameters, User Locks, Non-Default Locking, and Concurrency Control Using Serializable Transactions. Oracle database operations are performed using Structured Query Language (SQL).
Oracle Locking
Privileges Required
In its own schema, an application can automatically acquire any type of table locks. However, to acquire a table lock on a table in another schema, the application must have the LOCK ANY TABLE system privilege or an object privilege such as SELECT or UPDATE for the table.
Overriding Default Locking
By default, Oracle locks data structures automatically. However, an application can request specific data locks on rows or tables when it needs to override default locking. Explicit locking lets an application share or deny access to a table for the duration of a transaction.
An application can explicitly lock entire tables using the LOCK TABLE statement, but locking a table means that no other transaction, user, or application can access it. This can cause performance problems.
With the SELECT FOR UPDATE statement, an application explicitly locks specific rows of a table to ensure the rows do not change before an update or a delete. Oracle automatically obtains row-level locks at update or delete time, so use the FOR UPDATE clause only to lock the rows before the update or delete.
A SELECT statement with Oracle does not acquire any locks, but a SELECT…FOR UPDATE does. For example, the following is a typical SELECT …FOR UPDATE statement:
SELECT partno FROM parts FOR UPDATE OF priceThis statement starts a transaction to update the parts table with a price change for a specific part.
Oracle Explicit Data Locking
To ensure data concurrency, integrity, and statement-level read consistency, Oracle always performs necessary locks. However, an application can override default locks. This can be useful when:
- An application needs transaction-level read consistency or repeatable reads
. For example, when transactions must query a consistent set of data for the duration of the transaction, and the application must be sure that the data have not been changed by any other transactions. To achieve transaction-level read consistency, an application can use:- Explicit locks
- Read-only transactions
- Serializable transactions
- Default-lock overrides
- An application requires a transaction to have exclusive access to a resource. A transaction with exclusive access need not wait for other transactions to complete.
Overrides to Oracle locks can be done at two levels:
- Transaction level
- System level
At transaction level: Transactions override Oracle default locks with the following SQL statements,:
- LOCK TABLE
- SELECT…FOR UPDATE
- SET TRANSACTION…READ ONLY
- SET TRANSACTION…ISOLATION LEVEL SERIALIZABLE
At system level: Oracle can start an instance with non-default locking by adjusting the following initialization parameters:
- SERIALIZABLE
- ROW_LOCKING
If an application overrides any Oracle default locks, the application itself must:
- Ensure that the overriding locking procedures work correctly.
- Guarantee data integrity.
- Ensure acceptable data concurrency.
- Ensure that deadlocks cannot occur or are handled appropriately.
When a LOCK TABLE statement executes, it overrides default locking, and a transaction explicitly acquires the specified table locks. A LOCK TABLE statement on a view locks the underlying base tables (see Table 3-4).
Table 3-4: LOCK TABLE Statements
| Statement | Meaning |
| LOCK TABLE tablename IN EXCLUSIVE MODE [NOWAIT]; | Acquires exclusive table locks. Locks all rows of the table. No other user can modify the table. With NOWAIT, the application acquires the table lock only if the lock is immediately available, and Oracle issues an error if not. Without NOWAIT, the transaction does not proceed until the requested table lock is acquired. If the wait for a table lock reaches the limit set by the initialization parameter DISTRIBUTED_LOCK_TIMEOUT, a distributed transaction can time out. As no data will have been modified due to the timeout, the application can proceed as if it has encountered a deadlock. |
| LOCK TABLE tablename IN ROW SHARE
MODE; LOCK TABLE tablename IN ROW EXCLUSIVE MODE; |
These offer the highest degree of concurrency. Consider if the transaction must prevent another transaction from acquiring an intervening share, share row, or exclusive table lock for a table before the table can be updated in the transaction. If another transaction acquires an intervening share, share row, or exclusive table lock, no other transactions can update the table until the locking transaction commits or rolls back. |
| LOCK TABLE tablename IN SHARE MODE; | Consider this share table lock
if:
Note: If multiple transactions concurrently hold share table locks for the same table, NO transaction can update the table. Thus if share table locks on the same table are common, deadlocks will be frequent and updates will not proceed. For such a case, use share row exclusive or exclusive table locks. |
| LOCK TABLE tablename IN SHARE ROW EXCLUSIVE MODE; | Acquire a share row exclusive
table lock when:
|
Acquiring Row Locks
The SELECT…FOR UPDATE statement acquires exclusive row locks of selected rows. The statement can be used to lock a row without changing the row. Acquiring row locks can also be used to ensure that only a single interactive application user updates rows at a given time. For information on using this statement with cursors or triggers, see the Oracle8 or Oracle8i documentation. To acquire a row lock only when it is immediately available, include NOWAIT in the statement.
Each row in the return set of a SELECT…FOR UPDATE statement is individually locked. The statement waits until a previous transaction releases the lock. If a SELECT…FOR UPDATE statement locks many rows in a table, and the table is subject to moderately frequent updates, it may improve performance to acquire an exclusive table lock rather than using row locks.
If the wait for a row lock reaches the limit set by the initialization parameter DISTRIBUTED_LOCK_TIMEOUT, a distributed transaction can time out. As no data will have been modified, the application can proceed as if it has encountered a deadlock.
Setting SERIALIZABLE and ROW_LOCKING Parameters
How an instance handles locking is determined by the SERIALIZABLE option on the SET TRANSACTION or ALTER SESSION command, and the initialization parameter ROW_LOCKING. By default, SERIALIZABLE is set to false and ROW_LOCKING is set to always.
Normally these parameters should never be changed. However they may be used for compatibility with applications that run with earlier versions of Oracle, or for sites that must run in ANSI/ISO-compatible mode. Performance will usually suffer with non-default locking.
Using the LOCK TABLE Statement
The application uses the LOCK TABLE statement to lock entire database tables in a specified lock mode to share or deny access to them. For example, the statement below locks the parts table in row-share mode. Row-share locks allow concurrent access to a table; they prevent other users from locking the entire table for exclusive use. Table locks are released when your transaction issues a commit or rollback.
LOCK TABLE parts IN ROW SHARE MODE NOWAIT;
The lock mode determines which other locks can be placed on the table. For example, many users can acquire row-share locks on a table at the same time, but only one user at a time can acquire an exclusive lock. While one user has an exclusive lock on a table, no other users can insert, delete, or update rows in that table. For more information about lock modes, see Oracle8 or Oracle8i Server Application Developer's Guide.
A table lock never keeps other users from querying a table, and a query never acquires a table lock. Only if two different transactions try to modify the same row will one transaction wait for the other to complete.
If your program includes SQL locking statements, make sure the Oracle users requesting the locks have the privileges needed to obtain the locks.
Table 3-5: Summary of Locking Options
| Case | Description | SERIALIZABLE | ROW_LOCKING |
| 0 | Default settings | FALSE | ALWAYS |
| 1 | As Oracle Version 5 and earlier (no concurrent inserts, updates or deletes in a table) | FALSE (disabled) | INTENT |
| 2 | ANSI compatible | Enabled | ALWAYS |
| 3 | ASNI compatible with table-level locking (no concurrent inserts, updates or deletes in a table) | Enabled | INTENT |
Table 3-6: Non-Default Locking Behavior
| Statement | Case 0 | Case 1 | Case 2 | Case 3 | |||||
| SERIALIZABLE | FALSE (disabled) | Disabled | Enabled | Enabled | |||||
| ROW_LOCKING | ALWAYS | INTENT | ALWAYS | INTENT | |||||
| Row | Table | Row | Table | Row | Table | ||||
| SELECT | - | - | - | S | - | S | |||
| INSERT | X | SRX | X | RX | X | SRX | |||
| UPDATE | X | SRX | X | SRX | X | SRX | |||
| DELETE | X | SRX | X | SRX | X | SRX | |||
| SELECT…FOR UPDATE | X | RS | X | S | X | S | |||
| LOCK TABLE…IN.. | |||||||||
| ROW SHARE MODE | RS | RS | RS | RS | RS | RS | |||
| ROW EXCLUSIVE MODE | RX | RX | RX | RX | RX | RX | |||
| SHARE MODE | S | S | S | S | S | S | |||
| SHARE ROW EXCLUSIVE MODE | SRX | SRX | SRX | SRX | SRX | SRX | |||
| EXCLUSIVE MODE | X | X | X | X | X | X | |||
| DDL Statements | - | X | - | X | - | X | |||
Modes: X = EXCLUSIVE
RS = ROW SHARE
RX = ROW EXCLUSIVE
S = SHARE
SRX = SHARE ROW EXCLUSIVE
The information in this table comes from the Oracle 8i Application Developer's Guide.
A deadlock or deadly embrace can occur when transactions lock data items in a database. The typical scenario is with two transactions txn1 and txn2 executing concurrently with the following sequence of events:
Neither txn1 nor txn2 can proceed; they are in a deadly embrace. Figure 3-7 illustrates a deadly embrace.
With RTR, to avoid such deadlocks, follow these guidelines:
RTR attempts to resolve deadlocks by aborting one deadlocked transaction path with error code RTR_STS_DLKTXRES and replaying the transaction. Other paths are not affected. Server applications should be written to handle this status appropriately.
The RTR status code RTR_STS_DLKTXRES can occur under several environmental conditions that RTR detects and works around. The application need not take any explicit action other than releasing the resources connected with the active transaction such as doing a rollback on the database transaction.
For example, RTR may issue an RTR_STS_DLKTXRES status when:
As an example of the first case, consider clients A and B both performing transactions TCA and TCB, where both TCA and TCB include a message to both server X and server Y followed by an ACCEPT. There is only one instance of Server X and Server Y available, and due to the quirks of distributed processing, only Server X receives the message belonging to TCA and only Server Y receives the message belonging to TCB. Figure 3-8 reflects this scenario. Because Server Y has no chance of accepting TCA until TCB is processed to completion and Server X has no chance of accepting TCB until TCA is processed to completion, Server X and Y are in a distributed deadlock. In such a case, RTR selects TCA or TCB to abort with DLKTXRES and replays it in a different order.
Figure 3-8: Scenario for Distributed Deadlock
Sometimes RTR needs to abort a transaction and reschedule it. For example, it can happen that a state change is needed after the primary server started to process a transaction but RTR had to change its role to secondary before the transaction was completed. Thus the transaction would be executed on the other node as primary and later played to this server as secondary. RTR uses the same status code RTR_STS_DLKTXRES when aborting the transaction.
One method for improving response time is to send multiple messages from clients without waiting for a reply. The messages can be sent to different partitions to provide parallel processing of transactions.
For certain read-only applications, RTR can be used without shadowing to establish sites to protect against site failure. The method is to define multiple non-overlapping facilities with the same facility name across a network that is geographically dispersed. In the facility, define a failover list of routers, for example, some in one city, some in another. Then when the local router fails, a client is automatically reconnected to another node. If all local nodes in the facility are unavailable, the client is automatically connected to a node at the alternate site.
Another method is to define a partition on a standby server for read-only transactions. This minimizes network traffic to the standby. A read-only partition on a standby server can reduce node-to-node transaction locking.
Generally, databases (and applications built to work with them) are required to be idempotent. That is, given a specific state of the database, the same transaction applied many times would always produce the same result. Because RTR relies on replays and rollbacks, if there is a server failure before a transaction is committed, RTR assumes the database will automatically roll back to the previous state, and the replayed transaction will produce results identical to the previous presentation of the transaction. RTR assumes that the database manager and server application provide idempotency.
For example, consider an internet transaction where you log into your bank account and transfer money from one account to another, perhaps from savings to checking. If you interrupt the transfer, and replay it two hours later, the transfer may not succeed because it would be required to have been done within a certain time interval after the login. Such a transaction is not idempotent.
In a heterogeneous environment, you can use RTR with several hardware architectures, both little endian and big endian. RTR does data marshalling in your application so that you can take advantage of such a mixed environment.
If you are constructing an application for a heterogeneous environment:
With RTR, applications can run on systems from more than one vendor. You can mix operating systems with RTR, and all supported operating systems and hardware architectures can interoperate in the RTR environment. For example, you can have some nodes in your RTR configuration running OpenVMS and others running Windows NT.
To develop your applications in a multivendor environment:
An existing application written using RTR Version 2 with OpenVMS will still operate with RTR Versions 3 and 4. See the Reliable Transaction Router Migration Guide for pointers on using RTR Version 2 applications with RTR Version 3, and moving RTR Version 2 applications to RTR Version 3.
This chapter provides information on RTR transaction model and recovery concepts for client and server applications implemented with the C++ API.
Topics include:
Additional information on RTR transactions and recovery can be found in the Application Implementation chapter of this guide and in RTR Getting Started.
Figure 4-1 illustrates frontend/backend interaction with pseudo-code for transactions and shows transaction brackets. The transaction brackets show the steps in completing all parts of a transaction, working from left to right and top to bottom. In the figure, TC stands for transaction controller.
Figure 4-1: Transactional Messaging with the C++ API
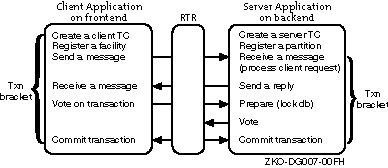
The transaction is initiated at "Start transaction" on the frontend, and completed after the "Commit transaction" step on the backend. The transaction ID is encoded to ensure its uniqueness throughout the entire distributed system. In the prepare phase on the server, the application should lock the relevant database (DB) records. The commit of a transaction hardens the commit to the database.
Figure 4-2 illustrates a typical call sequence between a client and server application. These calls are RTRClientTransactionController and RTRServerTransactionController class methods. The first call in both the client and server transaction controllers is to create a new transaction controller, for example, in the server, use RTRServerTransactionController::RTRServerTransactionController.
Figure 4-2: C++ API Calls for Transactional Messaging
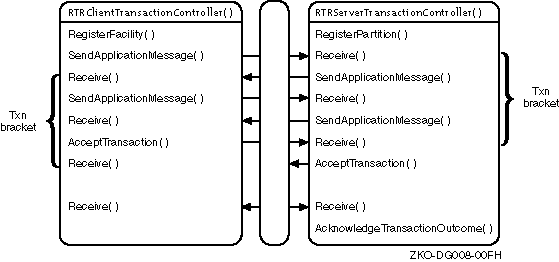
For a client, an application typically uses the following methods in this order:
Client first creates a transaction controller and a facility.
The client sends a request to the server.
After the server has processed the request, the client calls Receive and the data object contains the RTR message
The client calls AcceptTransaction, if all went well.
For a server, an application typically uses the following methods in this order:
On the first server transaction controller Receive, RTRData contains
rtr_mt_msg1. With event-driven processing (the default behavior) the server message handler calls OnInitialize and then calls OnApplicationMessage.On a second Receive from a client SendApplicationMessage, the RTR message received in the data object contains
rtr_mt_msgn, causing OnApplicationMessage to be called by the server message handler.After processing the client's request, the server calls SendApplicationMessage.
When the client accepts the transaction, the server Receive call includes
rtr_mt_prepare from RTR.The server accepts the transaction.
RTR sends rtr_mt_accepted
With event-driven processing, the appropriate methods in the RTRClientMessageHandler and RTRServerMessageHandler classes are called by RTRData::Dispatch. You must use the RTRClientTransactionController::RegisterHandlers and RTRServerTransactionController::RegisterHandlers methods to enable this default handling.
Data-content routing is the capability provided by RTR to support the partitioned data model. With the C++ API, you define partitions with the RTRPartitionManager class. Partitions are defined with partition name, facility name and KeySegment attributes. Using RTR data-content routing, message content determines message destination. The routing key, defined in the C++ API RTRKeySegment class is embedded within the application message. When a server is started, the server informs RTR that it serves a particular partition.
When a client sends a message that references that particular partition, RTR knows where to find a server for that partition and routes the message accordingly. Even if the server is moved to another location, RTR can still find it. The client and the application do not need to worry about locating the server. This is location independence.
The benefits of data-content routing are simpler application development and flexible, scalable growth without application changes. RTR hides the underlying network complexity from the application programmer, thus simplifying development and operation.
With Set State methods within the RTRServerTransactionProperties class, users can change a transaction state in their application servers. With the event-driven processing model, your states are shown through the message handlers. In the polling model, the states are accessed with an RTRData::GetMessageType() call.
Consider the following scenario: upon receiving an rtr_mt_accepted message indicating that a transaction branch is committed, the server normally performs an SQL commit to write all changes to the underlying database. However, the server that is to detect the SQL commit or the underlying database may be temporarily unavailable.
With the C++ API, you can change the state of a transaction to EXCEPTION using the SetStateToException method, to temporarily put this transaction in the exception queue. When things get better, users can call SetStateToCommit or SetStateToDone to change the transaction state back to COMMIT or DONE, respectively.
The following example shows how a transaction state can be changed using the set state methods. See the RTRServerTransactionProperties class documentation in the Reliable Transaction Router C++ Foundation Classes manual for more details.
RTRServerTransactionProperties::SetStateToException();
RTRServerTransactionProperties_object_name.SetStateToException(stCurrentTxnState);
The parameter stCurrentTxnState is a transaction state of type rtr_tx_jnl_state_t.
Normally at the RTR command level, users need to provide at least facility name and partition name qualifiers to help RTR select a desired set of transactions to be processed. Because a transaction's TID (rtr_tid_t) is unambiguously unique, a user needs only to specify the transaction's current state and its TID.
Note that if a transaction has multiple branches running on different partitions simultaneously on this node, RTR will reject this set transaction request with an error. RTR can only change state for one branch of a multiple partition transaction at a time.
RTR calls (and responses to them) contain RTR message types (mt) such as
rtr_mt_reply or rtr_mt_rejected. There are four groups of message types:Table 4-1lists all RTR message types.
| Transactional | Status | Event-related | Informational |
| rtr_mt_msg1 | rtr_mt_accepted | rtr_mt_user_event | rtr_mt_opened |
| rtr_mt_msg1_ uncertain |
rtr_mt_rejected | rtr_mt_rtr_event | rtr_mt_closed |
| rtr_mt_msgn | rtr_mt_prepare | rtr_mt_request_info | |
| rtr_mt_reply | rtr_mt_prepared | rtr_mt_rettosend |
Applications should include code for all RTR expected return message types. Message types are returned to the application in the message status block. For more detail on message types, see the Reliable Transaction Router C Application Programmer's Reference Manual.
Figure 4-3 illustrates transactional messaging interaction between a client application and a server application using C++ API calls.
Figure 4-3: Flow of a Transaction
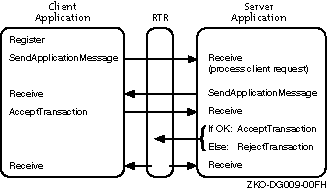
In Figure 4-3:
RTR sends both the server and the client a message that either declares that the transaction was accepted or rejected.
All the above steps comprise two parts of a transaction:
Message processing involves a message being sent by a client and a reply coming back from one or more servers. This is where the business application processing takes place.
The typical steps during message processing are:
Figure 4-4 illustrates the accept-processing portion of a completed RTR transaction.
The steps in accept processing are:
There is one way to start a transaction – explicitly by creating a server transaction controller object, registering a facility, and using StartTransaction.
The SendMessage call sends a message as part of a transaction from a client. If there is no transaction currently active on the transaction controller, a new one is started. The AcceptTransaction can be bundled with the last message. The SendMessage call
also sends a reply message from a server to the client. The reply message is part of the transaction initiated by the client.A transaction is defined as a group of messages initiated by the client. The server knows that a transaction has begun when it receives a message of one of the following types:
If transaction timeouts are not required, the transaction starts on the next SendMessage call.
The Register call enables the transaction to join another transaction or set a transaction timeout. When a transaction is started implicitly, the timeout feature is disabled.
A client has two options for message delivery after a failure:
When a message is received, the message status block contains the transaction identifier (TID).
You can use the GetTID call to obtain the RTR transaction identifier for the current transaction. This identifier is a unique number generated by RTR for each transaction. The application can use the TID if the client needs to know the TID to take some action before receiving a response.
The application can specify a reason on the AcceptTransaction method so that the caller can specify an accept reason that is passed on to all participants in the transaction. If more than one transaction participant specifies a reason, the reason values are ORed together by RTR. The accept is final: the caller cannot reject the transaction later. The caller cannot send any more messages for this transaction.
A client can accept a transaction in one of two ways: with the AcceptTransaction call or by using the
SetAcceptTransaction method.Using the SetAcceptTransaction method removes the need to issue an AcceptTransaction method and can help optimization of client traffic. Merging the data and accept messages in one call puts them in a single network packet. This can make better use of network resources and improve throughput.
The server can call the ForceRetry method to have RTR redeliver the transaction beginning with
rtr_mt_msg1 without aborting the transaction for other participants. Using the RejectTransaction method, the application can specify a reason that the caller can pass on to all participants in the transaction. If more than one transaction participant specifies a reason, the reason values are ORed together by RTR.A server application can end a transaction by either accepting or rejecting the transaction. RTR can reject a transaction at any time after the transaction is started but before it is committed. For example, if RTR cannot deliver a transaction to its destination, it rejects the transaction and delivers the reject completion status to all participants that know about the transaction.
A transaction is accepted explicitly with the AcceptTransaction method, and rejected explicitly with the RejectTransaction method. RTR can reject a transaction at any time once the transaction is started but before it is committed. If RTR cannot deliver a transaction to its destination, it rejects the transaction explicitly and delivers the reject completion status to all participants.
A
transaction participant can specify a reason for an accept or reject on the AcceptTransaction and RejectTransaction methods. If more than one transaction participant specifies a reason, RTR uses the OR operator to combine the reason values together. For example, with two servers, A and B, each providing a reason code of 1 or 2, respectively, the client receives the result of the OR operation, reason code 3, in its message buffer in RTRData.A transaction is done once a client or server application receives a completion message, either an
rtr_mt_accepted or rtr_mt_rejected message from RTR. An application no longer receives messages related to a transaction after receiving a completion message or if the application uses RejectTransaction A client or server can also specify SetForgetTransaction to signal its acceptance and end its involvement in a transaction early. RTR returns no more messages (including completion messages) associated with the transaction; any such messages received will be returned to the caller.A client or server application no longer receives messages related to a transaction after it receives an OnAccepted or OnRejected message from RTR, or if the application called RejectTransaction.
This section summarizes the default behavior of the client and server transaction controller objects when they interact in processing a transaction. When a transaction controller receives an RTRData object, it receives an RTR message. With the event-driven model of processing, Dispatch is automatically called and the appropriate methods, based on the RTR message, execute by default. For tables of the RTR to C++ API mapping of messages and events, see the Reliable Transaction Router C++ Foundation Classes manual. Table 4-2 lists commonly used server transaction controller methods.
Table 4-2: RTRServerTransactionController Methods
| ServerTransactionController | RTR Message within RTRData | Event-Driven Default Calls | Default Behavior |
| RTRServerTransactionController::RegisterPartition() | NA (not applicable) | NA | Creates a partition. |
| RTRServerTransactionController::RegisterHandlers() | NA | NA | Registers server message and event handlers with the server transaction controller. |
| RTRServerTransactionController::Receive() | rtr_mt_msg1 | OnInitialize OnApplicationMessage |
Receives application message. |
| RTRServerTransactionController::Receive() | rtr_mt_msgn | OnApplicationMessage | Receives application message. |
| RTRServerTransactionController:: SendApplicationMessage() | NA | NA | Sends application message. |
| RTRServerTransactionController::Receive() | rtr_mt_prepare | OnPrepare | Receives application message. |
| RTRServerTransactionController::AcceptTransaction | NA | NA | Accepts transaction. |
| RTRServerTransactionController::Receive() | rtr_mt_accepted | OnAccepted | Receives application message. |
| RTRServerTransactionController::Receive() | rtr_mt_rejected | OnRejected | Receives application message. |
To register two partitions, create two partitions and call Register once for each.
Table 4-3 lists basic client transaction controller methods.
Table 4-3: RTRClientTransactionController Methods
| ClientTransaction Controller |
RTR Message within RTRData | Event-Driven Default Calls | |
| RTRClientTransactionController::Receive() | rtr_mt_reply | RTRServerMessageHandler::(OnInitialize) RTRServerMessageHandler::(OnApplicationMessage) |
|
| RTRClientTransactionController::AcceptTransaction() | rtr_mt_accept | ||
| RTRClientTransactionController::Receive() | rtr_mt_accepted | OnAccepted | |
For more information on RTRTransactionController methods, see the Reliable Transaction Router C++ Foundation Classes manual.
RTR provides a relatively simple way to administer a transaction timeout in the server. Use of timeout values on the
Receive() method lets a server application specify how long it is prepared to wait for the next message. (Of course, the server should be prepared to wait forever to get a new transaction or for the result of an already-voted transaction.)One way to achieve this would be to have a transaction controller-specific global variable, say, called
SERVER_INACTIVITY_TIMEOUT, which is set to the desired value (in milliseconds—that is, use a value of 5000 to set a 5-second timeout). Note that this timeout value should be used after receiving the first message of the transaction. The value should be reset to RTR_NO_TIMOUTMS after receiving the rtr_mt_prepare message. Whenever the Receive method completes with an RTR_STS_TIMOUT, the server transaction controller calls RejectTransaction to abort the partially processed transaction. This would prevent transactions from occupying the server process beyond a reasonable time.A prepared application votes its intention using the AcceptTransaction method. An application that does not agree to commit to this transaction votes with the RejectTransaction method. This is the first (or prepare) phase of the two-phase commit process.
Initiating the Prepare Phase
The two-phase commit process with the C++ API is initiated by the client application when it issues a call to RTR indicating that the client "accepts" the transaction. This does not mean that the transaction is fully accepted, only that the client is prepared to accept it. RTR then asks the server applications participating in the transaction if they are prepared to accept the transaction. A server application that is prepared to accept the transaction votes its intention by issuing the AcceptTransaction method, an "accept" vote. A server application that is not prepared to accept the transaction issues the RejectTransaction method, a "not accept" vote. Issuing all votes concludes the prepare phase.
RTR provides an optional message to the server, OnPrepareTransaction, to expose the prepare phase. This message indicates to the server that it is time to prepare any updates for a later commit or rollback operation.
Commit Phase
In the second phase of the commit, RTR collects votes from all the servers. If they are all votes to accept, then RTR tells all participant servers that they can now commit the transaction to the database. RTR also informs the client that the transaction has completed successfully. If any server rejects the transaction, all participants are informed of this and the database is left unchanged.
Your application can use the level of participation that makes the most sense for your business and operations needs.
Explicit Accept, Explicit Prepare
To request an explicit accept and explicit prepare of transactions, the server receives both prepare and accept messages. The server then explicitly accepts or rejects a transaction when it receives the prepare message. The transaction sequence for an explicit prepare and explicit accept is as follows:
à ReceiveClient RTR Server
SendApplicationMessage à rtr_mt_msg1
With explicit transaction handling, the following steps occur:
A participant can reject the transaction up to the time RTR has sent the
rtr_mt_prepare message to the server using the AcceptTransaction method and the AcceptTransaction method is executed. Once the client application has used the AcceptTransaction method, the result cannot be changed.The sequence for an implicit prepare and explicit accept is as follows:
à rtr_mt_msg1 à ReceiveClient RTR Server
SendApplicationMessage
In certain database applications, where the database manager does not let an application explicitly prepare the database, transactions can simply be accepted or rejected. For server optimization, the server can signal its acceptance of a transaction with either the SetAcceptTransaction method, or with the client calling the SetAcceptTransaction method. This helps minimize network traffic for transactions by increasing the likelihood that the data message and the RTR accept message will be sent in the same network packet.
The server transaction states depend on whether the transaction is in prepare or commit phase. Table 4-4 lists server transaction states in the prepare phase.
Table 4-4: Prepare Phase Server States
| State | Meaning |
| RECEIVING | This state represents the server not yet voting on the transaction. |
| VOTING | The transaction state changes to VOTING when the client has accepted the transaction and RTR has asked the server to vote but the server has not yet answered. |
Table 4-5 lists server transaction states in the commit phase.
Table 4-5: Commit Phase Server States
| State | Meaning |
| COMMIT | The server commits the transaction after receiving a message from RTR. If all servers vote to accept (AcceptTransaction), all participants receive a commit message. |
| ABORT | The server aborts the transaction after receiving a message from RTR. If any server votes to abort (RejectTransaction), all participants receive an abort message. |
The transaction states for the router depend on whether the transaction is in prepare or commit phase. Table 4-6lists states in the prepare phase.
Table 4-6: Prepare Phase Router States
| State | Meaning |
| SENDING | The router state changes to VREQ except on a failed transaction, in which case it changes to ABORTING. |
| VREQ | This state represents RTR waiting for the server to vote by issuing AcceptTransaction or RejectTransaction. Once a vote is received, the state changes to either COMMITTING or ABORTING. |
When a transaction fails in progress, RTR provides recovery support using RTR replay technology. RTR, as a distributed transaction manager, communicates with a database resource manager in directing the two-phase commit process. Table 4-7 lists the typical server application transaction sequences for committing a transaction to the database. The sequence depends on which processing model you implement, polling or event driven.
Table 4-7: Typical Server Application Transaction Sequences
| Polling Model | Event-Driven Model |
| 1.
RTRServerTransactionController:: Receive(rtr_mt_msg1) |
1.
RTRServerTransactionController:: Receive(rtr_mt_msg1) |
| 2. SQL update | 2. RTRServerMessageHandler::OnInitialize() |
| 3.
RTRServerTransactionController:: AcceptTransaction() |
3. RTRServerMessageHandler:: OnApplicationMessage() |
| 4.
RTRServerTransactionController:: Receive(rtr_mt_accepted) |
4. SQL update |
| 5. SQL commit | 5.
RTRServerTransactionController:: AcceptTransaction() |
| 6.
RTRServerTransactionController:: AcknowledgeTransactionOutcome() |
6.
RTRServerTransactionController:: Receive(rtr_mt_accepted) |
| 7. RTRServerMessageHandler::OnAccepted() | |
| 8. SQL commit | |
| 9.
RTRServerTransactionController:: AcknowledgeTransactionOutcome() |
The impact of a crash on application recovery depends on where in the process the crash occurs. RTR handles the recovery, with the assistance of the application.
The typical server application transaction sequence using the event-driven processing model is as follows:
RTR transaction recovery summarized:
If the failure occurs before the server accepts a transaction, the sequence is as follows:
1. Receive(OnInitialize,
OnApplicationMessage)
FAILURE
2. SQL update
3. AcceptTransaction
4. Receive(OnAccepted)
5. SQL commit
6. Receive
If a crash occurs before the server accepts a transaction (between steps 1 and 3):
If another server (concurrent or standby) is available, RTR replays the transaction to that other server.
If the failure occurs after a server accepts a transaction, the sequence is as follows:
1. Receive(OnInitialize,
OnApplicationMessage)
2. SQL update
3. AcceptTransaction
FAILURE 4. Receive(OnAccepted)
5. SQL commit
6. Receive
If a failure occurs after the AcceptTransaction method is executed, but before the SQL Commit, the transaction is replayed. The type of the first message is then
rtr_mt_uncertain when the server is restarted. Servers should check to see if the transaction has already been executed in a previous presentation. If not, it is safe to re-execute the transaction because the database operation never occurred.After the failure where the server accepts a transaction, but before the database is committed (between steps 3 and 5) the following occurs:
If a failure occurs after the transaction has been accepted, but before it has been committed, the message is
rtr_mt_uncertain when the server is restarted. It is safe to re-execute the transaction since the database commit operation never occurred.If the failure occurs after the database is committed (for example, after the SQL commit but before receipt of a message starting the next transaction), RTR does not know the difference. The sequence is as follows:
1. Receive(OnInitialize,
OnApplicationMessage)
2. SQL update
3. AcceptTransaction
4. Receive(OnAccepted)
5. SQL commit
FAILURE
6. ReceiveIf failure occurs after an SQL commit is made, but before the receipt of a message starting the next transaction (between steps 5 and 6), the sequence is as follows:
In this case, the transaction should not be re-executed because the database commit operation has already occurred.
If the failure occurs after executing a Receive method to begin a new transaction, RTR assumes a successful commit (if the Receive occurs after receiving the
rtr_mt_accepted message) and will forget the transaction. There is no replay following these events. The sequence is as follows:1. Receive(OnInitialize,
OnApplicationMessage)
2. SQL update
3. AcceptTransaction
4. Receive(OnAccepted)
5. SQL commit
6. Receive
FAILUREIf a crash occurs after a Receive call is made to begin a new transaction (after step 6), the sequence is as follows:
As an application design suggestion, the application can maintain the list of transaction identifiers (TID) on a per-process, per-transaction controller basis to keep the list from growing infinitely.
RTR keeps track of how many times a transaction is presented to a server application before it is VOTED. The rule is: three strikes and you’re out! After the third strike, RTR rejects the transaction with the reason RTR_STS_SRVDIED. The server application has committed the transaction and the client believes that the transaction is committed. The transaction is flagged as an exception and the database is not committed. Such an exception transaction can be manually committed if necessary. This process eliminates the possibility that a single rogue transaction can crash all available copies of a server application at both primary and secondary sites.
Application design can change this behavior. The application can specify the retry count to use when in recovery using the SetRecoveryRetryCount method in the RTRBackEndPartitionProperties class, or the system administrator can set the retry count from the RTR CLI with the SET PARTITION command. If no recovery retry count is specified, RTR retries replay three times. For recovery, retries are infinite. For more information on the SET PARTITION command, see the Reliable Transaction Router System Manager's Manual; for more information on the SetRecoveryRetryCount method, see the Reliable Transaction Router C++ Foundation Classes manual.
When a node is down, the operator can select a different backend to use for the server restart. To complete any incomplete transactions, RTR searches the journals of all backend nodes of a facility for any transactions for the key range specified in the server’s RegisterPartition call.
RTR provides two mechanisms for coordinating RTR transactions with database transactions (or database managers): transaction management coordination (XA, DECdtm) and RTR replay technology.
When RTR is used with a resource manager (database or DB manager), two transactions are defined: an RTR transaction and that of the resource manager. These must be coordinated to ensure that a transaction committed by the resource manager is also committed by RTR. The same applies to rejected transactions.
Without a transaction manager, RTR uses replay technology to handle coordination with a resource manager. With a transaction manager, the transaction manager is the common agent to link the two transactions.
To use broadcast messaging with the C++ API, client and server applications can overload their event handlers.
To enable communication between two applications of the same type, create a second transaction controller of the other type. Messaging destination names can include wildcards, enabling flexible definition of the subset of recipients for a particular broadcast.
Use the SendApplicationEvent method to broadcast a user-event message.
Broadcast types include user events and RTR events; both are numbered and can be named.
A user broadcast is named or unnamed. An unnamed broadcast performs a match on the user event number; the event number completely describes the event. A named broadcast performs a match on both user event number and recipient name. The recipient name is a user-defined string. Named broadcasts provide greater control over who receives a particular broadcast.
Named events specify an event number and a textual recipient name. The name can include wildcards (% and *).
For all unnamed events, specify the evtnum field and RTR_NO_RCPSPC as the recipient name.
For example, the following code specifies named events for all subscribers:
SendApplicationEvent( evUserEventNumber, "*", RTR_NO_MSGFMT)
For a broadcast to be received by an application, the recipient name specified by the subscribing application on its RegisterFacility method for clients and RegisterPartition method for servers must match the recipient specifier used by the broadcast sender on the SendApplicationEvent call.
Note
RTR_NO_RCPSPC
is not the same as "*".An application receives broadcasts with the Receive method. A message type returned in the RTRData buffers informs the application of the type of broadcast received. For example,
Receive(...pmsg,maxlen,...pmsgsb);
The user event would be in msgsb.msgtype == rtr_mt_user_event. User broadcasts can also contain a broadcast message. This message is returned in the message buffer provided by the application. The size of the user’s buffer is determined by the maxlen field. The number of bytes actually received is returned by RTR in the msglen field of the message status block.
RTR delivers status information to which client and server applications can subscribe. Status information is delivered as messages, where the type of each message is an RTR event.
RTR events are numbered. The base value for RTR events is defined by the symbol RTR_EVTNUM_RTRBASE; its maximum value is defined by the symbol RTR_EVTNUM_RTRMAX. RTR events and event numbers are listed in the Programming with the C++ API chapter of this guide and in the RTR header file rtrapi.h.
An application can subscribe to RTR events to receive notification of external events that are of interest to the application. For example, a shadow server may need to know if it is a primary or a secondary server to perform certain work, such as uploading information to a central database, that is done at only one site.
To subscribe to all RTR events, use the range indicators
RTR_EVTNUM_RTRBASE and RTR_EVTNUM_RTRMAX.RTR events are delivered as messages of type
rtr_mt.rtr.event. Read the message type to determine what RTR has delivered. For example,rtr_status_t Receive( *pRTRData )
The event number, evtnum, is returned in the RTRData. The following RTR events return key range data back to the client application:
In application design, you may wish to consider creating separate facilities for sending broadcasts. By separating broadcast notification from transactional traffic, performance improvements can be substantial. Facilities can further be reconfigured to place the RTR routers strategically to minimize wide-area traffic.
A server application can expect to see a primary or secondary event delivered only in certain transaction states. For more detail, see the state diagrams in Appendix C, Server States.
RTR callout servers enable security checks to be carried out on all requests using a facility. Callout servers can run on backend or router nodes. They receive a copy of every transaction delivered to or passing through the node, and they vote on every transaction. To enable a callout server, use the /CALLOUT qualifier when issuing the
RTR CREATE FACILITY command. Callout servers are facility based, not key-range or partition based.An application enables a callout server with the CreateFacility method in the RTRFacilityManager class. For a router callout, the application sets the EnableRouterCallout boolean to true:
RTRFacilityManager.CreateFacility(...
bEnableRouterCallout = true
...);
For a backend callout server, the application sets the EnableBackendCallout boolean to true:
RTRFacilityManager.CreateFacility(...
bEnableBackendCallout = true);
RTR provides a C application programming interface (API) that features transaction semantics and intelligent routing in the client/server environment. It provides software fault tolerance using shadow servers, standby servers, and concurrent server processing. It can provide authentication with callout servers. RTR makes single-point failures transparent to the application, guaranteeing that, within the limits of reliability of the basic infrastructure and the physical hardware used, a transaction will arrive at its destination.
The RTR C API contains 16 calls that address four groups of activity:
The initialization call signals RTR that a client or server application wants to use RTR services and the termination call releases the connection once the requested work is done.
Messaging calls enable client and server applications to send and receive messages and broadcasts.
Transactional calls collect groups of messages as transactions (txn).
Informational calls enable an application to set RTR options or interrogate RTR data structures.
Table 5-1: RTR C API Calls by Category
| Initiation/ termination Calls |
Messaging Calls | Transactional Calls | Informational Calls | Manipulation |
| rtr_open_channel | rtr_broadcast_event | rtr_start_tx | rtr_request_info | |
| rtr_close_channel | rtr_reply_to_client | rtr_accept_tx | rtr_get_tid (tid is the transaction identifier) | |
| rtr_reject_tx | rtr_error_text | |||
| rtr_send_to_server | rtr_prepare_tx | rtr_set_info | ||
| rtr_receive_message | rtr_set_user_ handle |
|||
| rtr_set_wakeup |
To execute these calls using the RTR CLI, precede each with the keyword CALL. For example,
RTR> CALL RTR_OPEN_CHANNEL
Table 5-2 provides additional information on RTR API calls, which are listed in alphabetical order.
| Routine Name | Description | Client and Server |
Client Only |
Server Only |
Returns completion status as a message |
| rtr_accept_tx() | Votes on a transaction (server). Commits a transaction (client). |
Yes |
Yes | Yes | |
| rtr_broadcast_event() | Broadcasts an event message. | Yes | |||
| rtr_close_channel() | Closes a previously opened channel. | Yes | |||
| rtr_error_text() | Converts RTR message numbers to message text. |
Yes | |||
| rtr_get_tid() | Gets the current transaction ID. | Yes | |||
| rtr_open_channel() | Opens a channel for sending and receiving messages. |
Yes | Yes | ||
| rtr_prepare_tx() | Prepares a nested transaction to be committed. | Yes | Yes | ||
| rtr_receive_message() | Receives the next message (transaction message, event or completion status); returns a message and a message status block. |
Yes | |||
| rtr_reject_tx() | Rejects a transaction. | Yes | |||
| rtr_reply_to_client() | Sends a response from a server to
a client. |
Yes | |||
| rtr_request_info() | Requests information from RTR. | Yes | Yes | ||
| rtr_send_to_server() | Sends a message from a client to
the server(s). |
Yes | |||
| rtr_set_info() | Sets an RTR parameter. | Yes | Yes | ||
| rtr_set_user_handle() | Associates a user value with a transaction. |
Yes | |||
| rtr_set_wakeup() | Sets a function to be called on message arrival. |
Yes | |||
| rtr_start_tx() | Explicitly starts a transaction and specifies its characteristics. | Yes |
The rtr.h file included with the product defines all RTR data, status, and message types, including text that can be returned in error messages from an application. You must use it in application compilation.
To support the multi-operating system environment, error codes are processed by RTR using data values in rtr.h, and translated into text messages. Status codes are described in the Reliable Transaction Router C Application Programmer’s Reference Manual.
The command line interface (CLI) to the RTR API enables the programmer to write short RTR applications from the RTR command line. This can be useful for testing short program segments and exploring how RTR works. For an example of a sequence of commands that starts RTR and exchanges messages between a client and a server, see RTR Getting Started.
The design of an RTR client/server application should capitalize on the RTR multi-layer model, separating client activity in the application from server and database activity. The RTR client software layer passes messages transparently to the router layer, and the router layer sends messages and transactions reliably and transparently, based on message content, to appropriate server processes. Server application software typically interacts with database software to update and query the database, and respond back to the client.
The client/server environment has both plusses and minuses. Performing processing on the client that does not need to be handled by the server is a plus, as it enables the client to perform tasks that the server need have no knowledge of, and need expend no resources to support. With RTR as the medium for moving transactions from client to server, the application need not be concerned in detail about how the transactions are sent, or what to do in the event of node or site failures. RTR handles all required journaling and recovery without direct intervention by the application. The application needs no code to deal with server and link failures. However, the application must deal with transactions that get aborted, such as business-logic cases (for example, insufficient funds in a bank account) where rules dictate the abort. Table 5-3 lists the types of transaction aborts.
Table 5-3: How RTR Reports Aborted Transactions
| Transaction Aborted | Action |
| Business logic cases. For example, insufficient funds in a bank account. | Application reports error to user. Server or client aborts transactions. |
| RTR generated abort, RTR_STS_NODSTFND. RTR has exhausted all redundancy paths. | Application reports system unavailable, perhaps temporarily. |
| Timeout abort. | Task dependent. Try again or inform user. |
| Deadlock aborts. | None. RTR reschedules. |
In a client/server environment, application design becomes more complex because the designer must consider what tasks the clients are to perform, and what the servers must do. Typically the client application will capture information entered by the user, while the server interacts with the database to update the database with transactions passed to it by the router.
The RTR journal is always in use, recording transaction activity to persistent storage. The journal thus provides the capability of recovery from any single hardware or process failure. When a server application no longer provides service, for example, when it goes off line, goes down, or is taken out of service temporarily, RTR aborts all transactions for that service with
RTR_STS_NODSTFND. When doing transactional shadowing, the journal at the active site is used to record transactions, for the out-of-service site. Journaling on frontends is required to support nested transactions to record the final state of a transaction.If transactions do not update the database, specify them as read-only by using the
RTR_F_SEN_READONLY flag on the rtr_send_to_server call. Read-only transactions are not recovered as uncertain transactions. Also, in a shadowed environment, these transactions would not be remembered and would therefore save on journal space.Client applications use data content routing to route each transactional request to the appropriate server servicing the correct database segment. The key value supplied by the client application in the key fields (as defined in the definition of the partition) is used by RTR to achieve data content or data partition routing.
RTR enables an application to route transactions by partition or key range, rather than sending all transaction requests to a single server application.
When RTR has chosen a specific server for a request within a given transaction, RTR ensures that all requests within that transaction are routed to the same server application channel.
Key ranges, or data partitions, are a major concept in RTR. An application is said to service a partition. Failovers and other availability attributes are applied to all applications, which service a given partition. All server applications able to service a specific data partition on a given node are called concurrents of one another. Concurrent servers may be either multiple channels within a given process, or separate processes.
Partitions can be given names. This lets the system manager manipulate the attributes for a partition at runtime. For example, the operator can temporarily suspend the presentation of online transactions to the partition. This provides time to initiate a database backup operation.
Partitions, in RTR, are the essence of routing. The server application declares its intention to service a certain partition or key range by associating itself with a name, or explicitly defining the key format and range of values.
A partition has many attributes, some of which are specified by the programmer or operator. Some key attributes include:
To plan for future expansion, consider using compound keys rather than single field keys. For example, using a bank example, with a bank that has multiple branches, an application that routes data to each bank can use a BankID key field or partition. Over time, the application may also need to further subdivide transactions not only by bank but also by customer ID. If the application is initially written with a compound key providing both a BankID and a CustomerID key, it can be simpler to make such a change in future.
An application can be multithreaded. There are several ways to use multithreading in the application architecture. Check the Reliable Transaction Router Release Notes and SPD for the current extent of support for multithreaded programming for a given platform.
The two common ways of using multithreading are:
One word of caution for application developers who intend to deploy on OpenVMS: AST programming and threading do not mix well, and may cause intermittent deadlocks. It is therefore prudent not to use ASTs when using threads on OpenVMS with RTR.
For a client, an application typically uses the following calls in this order:
For a server, an application typically uses the following calls in this order:
The rtr_receive_message call returns a message and a message status block (MsgStatusBlock). For example,
... status = rtr_receive_message(&Channel,
RTR_NO_FLAGS,
RTR_ANYCHAN,
MsgBuffer,
DataLen,
RTR_NO_TIMOUTMS,
&MsgStatusBlock);
The message status block contains the message type, the user handle, if any, the message length, the TID, and the event number, if the message type is
rtr_mt_rtr_event or rtr_mt_user_event. For more information on the message status block, see the descriptions of rtr_receive_message and rtr_set_user_handle in the Reliable Transaction Router C Application Programmer’s Reference Manual.RTR calls and responses to them contain RTR message types (mt) such as
rtr_mt_reply or rtr_mt_rejected. The four groups of message types, listed in Table 5-4, are:| Transactional | Status | Event-related | Informational |
| rtr_mt_msg1 | rtr_mt_accepted | rtr_mt_user_event | rtr_mt_opened |
| rtr_mt_msg1_ uncertain |
rtr_mt_rejected | rtr_mt_rtr_event | rtr_mt_closed |
| rtr_mt_msgn | rtr_mt_prepare | rtr_mt_request_info | |
| rtr_mt_reply | rtr_mt_prepared | rtr_mt_rettosend |
Applications should include code for all RTR expected return message types. Message types
are returned to the application in the message status block. For more detail on message
types see the Reliable Transaction Router C Application Programmer's Reference Manual.
Figure 5-1 shows the RTR C API calls you use to achieve transactional messaging in your application.
Figure 5-1: RTR C API Calls for Transactional Messaging
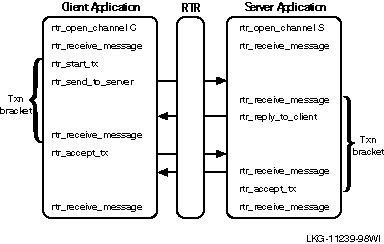
To work in a mixed-operating system environment, an application can specify a message format definition on the following calls:
RTR performs data marshaling, evaluating and converting data appropriately as directed by the message format descriptions provided in the application.
The following example shows an RTR application using a message format declaration; first the RTR call specifying that TXN_MSG_FMT contains the actual format declaration, then the definition used by the call.
RTR application call:
status = rtr_send_to_server(p_channel,
RTR_NOFLAGS,
&txn_msg,
msg_size,
TXN_MSG_FMT );
Data definition:
#
define TXN_MSG_FMT "%1C%UL%7UL%31C"This data structure accommodates an 8-bit signed character field ( C ) for the key, a 32-bit unsigned field (UL) for the server number, a 224-bit (7x32) field (7UL) for the transaction ID, and a 31-bit byte (248-bit) field (31C) for character text. For details of defining message format for a mixed-endian environment, see the Reliable Transaction Router C Application Programmer’s Reference Manual.
You use the XA protocol supported by RTR to communicate with an X/Open Distributed Transaction Processing (DTP) conformant resource manager. This eliminates the need for an application program to process rtr_mt_uncertain messages. For examples of system setup, see the RTR System Manager's Manual, Appendix C.
Note
int main( int argc, char *argv[] )
{
switch(msgsb.msgtype)
{
case rtr_mt_msg1:
case rtr_mt_msgn:
switch(msg.txn_type)
{
case ...
EXEC SQL ...
EXEC SQL COMMIT WORK RELEASE;
...
}
The XA software architecture of RTR provides interoperability with the Distributed Transaction Controller of Microsoft, MS DTC. Thus RTR users can develop application programs that update MS SQL databases, MS MQ, or other Microsoft resource managers under the control of a true distributed transaction. RTR as a distributed transaction manager communicates directly with MS DTC to manage a transaction or perform recovery using the XA protocol. For each standard XA call received from RTR, MS DTC translates it into a corresponding OLE transaction call that SQL Server or MS MQ expects to perform database updates. This is shown in Figure 5-2.
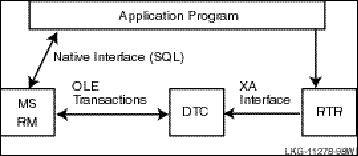
For example, using XA and DTC (Compaq Tru64 UNIX and Microsoft Windows NT only) eliminates the need to process uncertain messages (
rtr_mt_msg1_uncertain). To use the XA protocol with RTR, you must:Both the resource manager instance name and the database (RM) name in [OPEN-STRING] must be identical to that in the previously executed REGISTER RM command. The information is stored in the RTR key segment structure, and the
RTR_F_OPE_XA_MANAGED flag associates the channel with the XA interface.Only one transaction at a time is processed on an RTR channel; thus a server process or thread of control can only open one channel to handle a single XA request. Better throughput can be achieved by using a multithreaded application.
For example, the following code from a sample server application shows use of the RM key, the XA flag, and commenting out commits and rollbacks for the Oracle and DTC environments.
The following XA/DTC server application example is for a Windows NT environment only.
Note
In this example, error checking has been omitted for clarity
.int main( int argc, char argv[] )
{
server_key[0].ks_type = rtr_keyseg_unsigned;
server_key[0].ks_length = sizeof(rtr_uns_8_t);
server_key[0].ks_offset = 0;
server_key[0].ks_lo_bound = &low;
server_key[0].ks_hi_bound = &high;
server_key[1].ks_type = rtr_keyseg_rmname; /* RM name */
server_key[1].ks_length = sizeof(String32)+sizeof(String128);
server_key[1].ks_offset = 0;
server_key[1].ks_lo_bound = rm_name;
server_key[1].ks_hi_bound = xa_open_string;
flag = RTR_F_OPE_SERVER |
RTR_F_OPE_XA_MANAGED | /* XA flag */
RTR_F_OPE_NOSTANDBY |
RTR_F_OPE_EXPLICIT_PREPARE |
RTR_F_OPE_EXPLICIT_ACCEPT;
/* Connect SQL server thru DB-Library */
dbinit();
login = dblogin();
DBSETLUSER(login, sql_username);
DBSETLPWD(login, sql_password);
dbproc = dbopen(login, sql_servername);
dbfreelogin(login);
dbuse(dbproc, sql_dbname);
rtr_open_channel(&server_channel, flag, fac_name,
NULL, RTR_NO_PEVTNUM, NULL,2, server_key);
...
rtr_receive_message(&server_channel, RTR_NO_FLAGS, RTR_ANYCHAN,
&receive_msg,sizeof(receive_msg), RTR_NO_TIMOUTMS, &msgsb)
== RTR_STS_OK)
...
while (rtr_receive_message(&server_channel, RTR_NO_FLAGS, RTR_ANYCHAN,
&receive_msg, sizeof(receive_msg), RTR_NO_TIMOUTMS, &msgsb);
...
msg = receive_msg.receive_data_msg;
switch(msgsb.msgtype)
{
case rtr_mt_msg1:
dbenlistxatrans(dbproc, RTR_TRUE);
/* Remove uncertain processing
case rtr_mt_msg1_uncertain:
...
*/
...
rtr_accept_tx(s_chan,RTR_NO_FLAGS,RTR_NO_REASON);
...
case rtr_mt_accepted:
/* EXEC SQL COMMIT; Comment out SQL Commits */
case rtr_mt_rejected:
/* EXEC SQL ROLLBACK;Comment out SQL rollbacks */
...
}
exit(0);
}
You can use the DECdtm protocol to communicate with OpenVMS Rdb. This provides a two-phase commit capability. For additional information on using this protocol, see the OpenVMS documentation, for example, Managing DECdtm Services in the OpenVMS System Manager's Manual, and the Oracle Rdb Guide to Distributed Transactions available from Oracle.
Nested transactions extend transactional control rights between two transaction domains. To implement nested transactions, the application uses the following RTR C API calls:
The
For additional details on the syntax and use of these calls, see the Reliable Transaction Router C Application Programmer’s Reference Manual.
When using nested transactions, a journal is required on the frontend node used for nested transactions, if that node does not already support a backend.
The transactional outcome of the nested transaction is delivered to the RTR client that starts the nested transaction. This provides a flexible model where parent and nested transactions can commit independently if required by the application. For example, using nested transactions, several outcomes are possible:
The application must provide the logic to perform the correct processing based on each case and the requirements of the application.
To start a global transaction, an application uses
rtr_open_channel and rtr_start_tx. For example,To engage the nested transaction, the application uses
rtr_send_to_server and rtr_prepare_tx. For example,rtr_send_to_server(...pmsg, msglen, ...)
rtr_prepare_tx(channel, flags, reason,
pmsg, /* blob /
msglen) /* blob length */
The client process sends the data to the nested resource on the client channel that has started the nested transaction. When the client process is ready to complete the transaction, it must first determine if the nested transaction can complete:
The RTR application client establishes the connection with
rtr_open_channel and rtr_start_tx. For example,rtr_open_channel(..., flags=RTR_F_OPE_CLIENT, ...)
rtr_start_tx(..., jointxid=XA_txid, ...)
rtr_send_to_server(msg1)
rtr_send_to_server(msg2)
rtr_prepare_tx()
rtr_receive_message()
rtr_accept_tx()
The RTR application server also uses
rtr_open_channel, combined with rtr_receive_message. For example,rtr_open_channel(..., flags=RTR_F_OPE_SERVER,...)
rtr_receive_message()
rtr_receive_message()
rtr_receive_message()
rtr_receive_message()
rtr_accept_tx()
rtr_receive_message()
This sequence establishes the following dialog between the client and server applications. On the client application, when the
rtr_start_tx call is executed, RTR sends an rtr_mt_opened message to both client and server applications. The server application receives this message with the rtr_receive_message call. The client sends its first message to the server as rtr_mt_msg1, followed by rtr_mt_msgn and rtr_mt_prepare. The server application responds to the client with an rtr_mt_prepared message, and the client sends back an rtr_mt_accepted message.For recovery of nested transactions, in the event of failure of the client application or of the node where an RTR nested transaction is started, the superior transaction manager must be able to determine which transactions are in an indeterminate state. Before the
rtr_mt_opened message is delivered to the client application, RTR scans the local journal and creates a list of in-doubt (prepared) transactions. After the rtr_mt_opened message has been delivered to the application, the application must ask RTR if there are any transactions in an incomplete state. This is achieved with the rtr_request_info call. For example,status= rtr_request_info(...
rtr_info_class_t = "ftx",
rtr_itemcode_t = "$name", /* Select item */
rtr_selval_t = "facility_name",
rtr_itemcode_t = "kr_id, tx_id" /* Get items */
...);
The
rtr_request_info call returns information about the prepared transactions for the specified facility.In another example, user data passed in the
pmsg parameter (blob) of the rtr_prepare_tx call is retrieved during recovery of a prepared, nested transaction. The XID specified by the foreign transaction manager (rtr_xid_t) is also available. Sample code follows:status= rtr_request_info(...
rtr_info_class_t = "ftx",
rtr_itemcode_t = "txid", /* Select item */
rtr_selval_t = "tx id value from previous call",
rtr_itemcode_t = "xid, state, jnl_state, sr_state,
bloblen, blob" /* Get items */
...);
Table 5-5 lists possible client actions based on the contents of the journal state (
jnl_state) field.Table 5-5: Client Action Based on Journal State
| State in Journal | Action |
| rtr_tx_jnl_prepare | Participants are waiting for final phase of two-phase commit. Set the transaction state to either COMMIT or ABORT using the rtr_set_info statement. |
| rtr_tx_jnl_commit | RTR is waiting for confirmation that the superior transaction has been committed. The next operation on this channel implicitly forgets this transaction. |
| rtr_tx_jnl_abort | RTR is waiting for confirmation that the superior transaction has been aborted. The next operation on this channel implicitly forgets this transaction. |
To pass transactions from client to server, RTR (with the C API) uses channels as identifiers. Each application communicates with RTR on a particular channel. In a multithreaded application, when multiple transactions are outstanding, the application uses the channel to inform RTR which transaction a command is for.
With RTR, the client or server application can:
To open a channel, the application uses the
rtr_open_channel call. This opens a channel for communication with a client or server application on a specific facility. Each application process can open up to 255 channels.For example, the
rtr_open_channel call in this client application opens a single channel for the facility called DESIGN:status = rtr_open_channel(&Channel,
RTR_F_OPE_CLIENT, [1]
DESIGN, /* Facility name / [2]
client_name,
rtrEvents,
NULL, /* Access key / [3]
RTR_NO_NUMSEG,
RTR_NO_PKEYSEG /* Key range */ [4]
);
The application uses parameters on the
rtr_open_channel call to define the application environment. Typically, the application defines the:[1] Role of the application (client or server)
[2] Name of the application facility
[3] Facility access key, a password; in this case no password is used
[4] Key range or key segment for data content routing
For a server application, the
rtr_open_channel call additionally supplies the number of key segments, numseg, and the partition name, in pkeyseg.The syntax of the
rtr_open_channel call is as follows:status = rtr_open_channel (pchannel,flags,facnam,rcpnam, pevtnum,access,numseg,pkeyseg)
You can set up a variable section in your client program to define the required parameters and then set up your
rtr_open_channel call to pass those parameters. For example, the variables definition would contain code similar to the following:
/*
** ---------------- Variables -------------------
*/
rtr_status_t Status;
rtr_channel_t Channel;
rtr_ope_flag_t Flags = RTR_F_OPE_CLIENT;
rtr_facnam_t Facility = "DESIGN";
rtr_rcpnam_t Recipient = RTR_NO_RCPNAM;
rtr_access_t Access = RTR_NO_ACCESS;
The
rtr_open_channel call would contain:status = rtr_open_channel(&Channel,
Flags,
Facility,
Recipient,
Evtnum,
Access,
RTR_NO_NUMSEG,
RTR_NO_PKEYSEG);
if (Status != RTR_STS_OK)
/*
{ Provide for error return */}
You will find more complete samples of client and server code in the appendix of this document and on the RTR software kit in the Examples directory.
To specify the location to return the channel identifier, use the channel argument in the
rtr_channel_t channel;
or
This parameter points to a valid channel identifier when the application receives an
rtr_mt_opened message.rtr_ope_flag_t
flags = RTR_F_OPE_CLIENT;
or
flags = RTR_F_OPE_SERVER;
To define the facility name, use the facnam parameter. For example,
rtr_facnam_t
facnam = "DESIGN";
To specify a recipient name, use the
rcpnam parameter, which is case sensitive. For example,
To specify user event numbers, use the evtnum parameter. For example,
rtr_evtnum_t all user_events[]={
RTR_EVTNUM_USERDEF,
RTR_EVTNUM_USERBASE,
RTR_EVTNUM_UP_TO,
RTR_EVTNUM_USERMAX,
RTR_EVTNUM_ENDLIST
};
You can use the facility access key to restrict client or server access to a facility. The key acts as a password to restrict access to the specific facility for which it is declared.
To define the facility access key, use the access parameter. For example,
rtr_access_t
access = "amalasuntha";
The facility access key is a string supplied by the application. The first server channel in an RTR facility defines the access key; all subsequent server and client open channel requests must specify the same access value. To use no access key, use
RTR_NO_ACCESS or NULL for the access argument.You can also use this feature for version control. By changing the access code whenever an incompatible protocol change is made in the application message format, client applications are prevented from processing transactions with the server applications.
To specify the number of key segments defined for a server application, use the numseg parameter. For example,
rtr_numseg_t
numseg = 2;
To specify the key range for a partition to do data-content routing, the server application defines the routing key when it opens a channel on a facility with the
rtr_open_channel call. All servers in a facility must specify the same offset, length, and data type for the key segments in the rtr_open_channel call; only high and low bounds (*ks_lo_bound, *ks_hi_bound) can be unique to each server key segment. By application convention, the client places key data in the message at the offset, length, and data type defined by the server.The channel-open operation completes asynchronously. Call completion status is returned in a subsequent message. RTR sends a message to the application indicating successful or unsuccessful completion; the application receives the status message using an
rtr_receive_message call. If status is rtr_mt_opened, the open operation is successful. If status is rtr_mt_closed, the open operation is unsuccessful, and the application must examine the failure and respond accordingly. The channel is closed.Data returned in the user buffer with
rtr_mt_opened and rtr_mt_closed include both the status and a reason. For example,case rtr_mt_opened:
printf(" Channel %d opened\n", channel);
status = RTR_STS_OK;
break;
case rtr_mt_closed:
p_status_data = (rtr_status_data_t *)txn_msg;
printf(" cannot open channel because %s\n",
rtr_error_text(p_status_data->status));
exit(-1);
Use the call
rtr_error_text to find the meaning of returned status. A client channel will receive no message at all if a facility is configured but no server is available. Once a server becomes available, RTR sends the rtr_mt_opened message.To close a channel, the application uses the
rtr_close_channel call. A channel can be closed at any time after it has been opened. Once closed, no further operations can be performed on a channel, and no further messages for the channel are received.To receive on a channel and obtain status information from RTR, use the
rtr_receive_message call. To receive on any open channel, use the RTR_ANYCHAN value for the p_rcvchan parameter in the rtr_receive_message call. To receive from a list of channels, use the p_rcvchan parameter as a pointer to a list of channels, ending the list with RTR_CHAN_ENDLIST. An application can receive on one or more opened channels. RTR returns the channel identifier. A pointer to a channel is supplied on the rtr_open_channel call, and RTR returns the channel identification (ID) by filling in the contents of that pointer.To simplify matching an RTR channel ID with an application thread, an application can associate a user handle with a channel. The handle is returned in the message status block with the
rtr_receive_message call. The application can use the message status block (MsgStatusBlock) to identify the message type of a received message. For example,{
rtr_receive_message (&channel, RTR_NO_FLAGS, RTR_ANYCHAN, txn_msg, maxlen,
RTR_NO_TIMOUTMS, MsgStatusBlock);
} . . .
typedef struct {
rtr_msg_type_t msgtype;
rtr_usrhdl_t usrhdl;
rtr_msglen_t msglen;
rtr_tid_t tid;
rtr_evtnum_t evtnum;
} rtr_msgsb_t;
RTR delivers both RTR and application messages when the
rtr_receive_message call completes. The application can use the message type indicator in the message status block to determine relevant buffer format. For further details on using message types and interpreting the contents of the user buffer, see the Reliable Transaction Router C Application Programmer's Reference Manual.An application can specify one of three reception styles for the
rtr_receive_message call. These are:An application can use a blocking receive to wait until a message arrives. To use a blocking receive, include
rtr_receive_message (&channel, RTR_NO_FLAGS,
RTR_ANYCHAN,
MsgBuffer, DataLen, RTR_NO_TIMOUTMS, &MsgStatusBlock);
An application can use a polled receive to poll RTR with a specified timeout. To use a polled receive, the application can set a value in milliseconds on the timoutms parameter.
The timeout can be:
The call completes after the specified timeout or when a message is available on one of the specified channels.
For example, the following declaration sets polling at 1 second (1000 milliseconds).
rtr_receive_message(&channel, RTR_NO_FLAGS, RTR_ANYCHAN, MsgBuffer, DataLen, 1000, &MsgStatusBlock);
Note
The
rtr_receive_message timeout is not the same as a transaction timeout.An application can use a signaled receive to be alerted by RTR when a message is received. The application establishes a signal handler using the
rtr_set_wakeup call, informing RTR where to call it back when the message is ready.To use a signaled receive, the application uses the
rtr_set_wakeup call and provides the address of a routine to be called by RTR when a message is available. When the wakeup routine is called, the application can use the rtr_receive_message call to get the message. For example,rtr_status_t
rtr_set_wakeup(
procedure
)
void
wakeup_handler(void){
rtr_receive_message();
}
main(){
rtr_set_wakeup(wakeup_handler);
sleep();
}
Note
To disable wakeup, call
rtr_set_wakeup with a null routine address.When using
rtr_set_wakeup in a multithreaded application, be careful not to call any non-reentrant functions or tie up system resources unnecessarily inside the callback routine.The
rtr_open_channel parameters are further described in the Reliable Transaction Router C Application Programmer's Reference Manual.There are two ways to start a transaction:
Use the
rtr_start_tx call when the application must set a client-side transaction timeout to ensure that both client and server do not wait too long for a message. When a transaction is started with rtr_send_to_server, no timeout is specified.For example,
rtr_start_tx(&Channel,
RTR_NO_FLAGS,
RTR_NO_TIMOUTMS,
RTR_NO_JOINCHAN); //or NULL
The
rtr_send_to_server call sends a message as part of a transaction from a client. If there is no transaction currently active on the channel, a new one is started. The transaction accept can be bundled with the last message. A client has two options for message delivery after a failure:Use the
Use the
The
rtr_reply_to_client call sends a reply message from a server to the client. The reply message is part of the transaction initiated by the client. For example,status = rtr_reply_to_client (&Channel,
RTR_NO_FLAGS,
MsgBuffer,
DataLen,
RTR_NO_MSGFMT);
The reply message format can be of any form as designed by the application. For example,
struct acct_inq_msg_t {
char reply_text[80];
} acct_reply_msg;
When an application receives a message with the
rtr_receive_message call, the message status block (MsgStatusBlock) contains the transaction identifier. For example,status = rtr_receive_message (&Channel,
RTR_NO_FLAGS,
RTR_ANYCHAN,
MsgBuffer,
DataLen,
RTR_NO_TIMOUTMS,
&MsgStatusBlock);
The pointer
&MsgStatusBlock points to the message status block that describes the received message. For example,typedef struct {rtr_msg_type_t msgtype;
rtr_usrhdl_t usrhdl;
rtr_msglen_t msglen;
rtr_tid_t tid;
/*If a transactional message, the transaction ID or tid, msgsb.tid */
rtr_evtnum_t evtnum;
} rtr_msgsb_t;
Use the
rtr_get_tid call to obtain the RTR transaction identifier for the current transaction. The TID (transaction identifier) is a unique number generated by RTR for each transaction. The application can use the TID if the client needs to know the TID to take some action before receiving a response.Use the
rtr_set_user_handle call to set a user handle on a transaction instead of using a channel. A client application with multiple transactions outstanding can match a reply or completion status with the appropriate transaction by establishing a new user handle each time a transaction is started.A transaction participant can specify a reason for an accept or reject on the
rtr_accept_tx and rtr_reject_tx call. If more than one transaction participant specifies a reason, RTR uses the OR operator to combine the reason values together. For example, with two servers A and B, each providing a reason code of 1 and 2, respectively, the client receives the result of the OR operation, reason code 3, in its message buffer.Server A Server B
rtr_reason_t rtr_reason_t
reason =1; reason=2;
rtr_reject_tx ( rtr_reject_tx (
channel, channel,
flags, flags,
reason ); reason );
typedef struct {
rtr_status_t status;
rtr_reason_t reason;
} rtr_status_data_t;
The client receives the results of the OR operation in its message buffer:
rtr_status_data_tA transaction is done once a client or server application receives a completion message, either an
rtr_mt_closed, rtr_mt_accepted, or rtr_mt_rejected message from RTR. An application no longer receives messages related to a transaction after receiving a completion message or if the application calls rtr_reject_tx. A client or server can also specify RTR_F_ACC_FORGET on the rtr_accept_tx call to signal its acceptance and end its involvement in a transaction early. RTR returns no more messages (including completion messages) associated with the transaction; any such messages received will be returned to the caller.When issuing the
rtr_accept_tx call with RTR_NO_FLAGS on the call, the caller expresses its request for successful completion of the transaction, and may give an accept reason that is passed on to all participants in the transaction. The accept is final; the caller cannot reject the transaction later. The caller cannot send any more messages for this transaction.A client can accept a transaction in one of two ways: with the
rtr_accept_tx call or by using the RTR_F_SEN_ACCEPT flag on the rtr_send_to_server call.When the client sets
RTR_F_SEN_ACCEPT on the rtr_send_to_server call, this removes the need to issue an rtr_accept_tx call and can help optimization of client traffic. Merging the data and accept messages in one call puts them in a single network packet. This can make better use of network resources and improve throughput.The
rtr_reject_tx call rejects a transaction. Any participant in a transaction can call rtr_reject_tx. The reject is final; the caller cannot accept the transaction later. The caller can specify a reject reason that is passed to all accepting participants of the transaction. Once the transaction has been rejected, the caller receives no more messages for this transaction.The server can set the retry flag
RTR_F_REJ_RETRY to have RTR redeliver the transaction beginning with msg1 without aborting the transaction for other participants. Issuing an rtr_reject_tx call with this flag can let another transaction proceed if locks held by this transaction cause a database deadlock.If there is a crash before the
rtr_accept_tx statement is executed, on recovery, the transaction is replayed as rtr_mt_msg1 because the database will have rolled back the prior transaction instance. However, if there is a crash after the rtr_accept_tx statement is executed, on recovery, the transaction is replayed as rtr_mt_msg1_uncertain because RTR does not know the status of the prior transaction instance. Your application must understand the implications of such failures and deal with them appropriately.RTR provides a relatively simple way to administer a transaction timeout in the server. Use of timeout values on the
rtr_receive_message function lets a server application specify how long it is prepared to wait for the next message. (Of course, the server should be prepared to wait forever to get a new transaction or for the result of an already-voted transaction.)One way to achieve this would be to have a channel-specific global variable, say, called
SERVER_INACTIVITY_TIMEOUT, which is set to the desired value (in milliseconds—that is, use a value of 5000 to set a 5 second timeout). Note that this timeout value should be used after receiving the first message of the transaction. The value should be reset to RTR_NO_TIMOUTMS after receiving the rtr_mt_prepare message. Whenever the rtr_receive_message completes with a RTR_STS_TIMOUT, the server calls the rtr_reject_tx function on that channel to abort the partially-processed transaction. This would prevent transactions from occupying the server process beyond a reasonable time.The two-phase commit process includes prepare and commit phases. A transaction is tentatively accepted or rejected during the prepare phase.
To initiate the prepare phase, the server application specifies the
RTR_F_OPE_EXPLICIT_PREPARE flag when opening the channel, and can use the message rtr_mt_prepare to check commit status. The message indicates to the server application that it is time to prepare any updates for a later commit or rollback operation. RTR lets the server application explicitly accept a transaction using the RTR_F_OPE_EXPLICIT_ACCEPT flag on the rtr_open_channel call. Alternatively, RTR implicitly accepts the transaction after receiving the rtr_mt_accepted message when the server issues its next rtr_receive_message call.The commit process is initiated by the client application when it issues a call to RTR indicating that the client "accepts" the transaction. This does not mean that the transaction is fully accepted, only that the client is prepared to accept it. RTR then asks the server applications participating in the transaction if they are prepared to accept the transaction. A server application that is prepared to accept the transaction votes its intention by issuing the
rtr_accept_tx call, an " accept" vote. A server application that is not prepared to accept the transaction issues the rtr_reject_tx call, a "not accept" vote. Issuing all votes concludes the prepare phase.When RTR has collected all votes from all participating server applications, it determines if the transaction is to be committed. If all collected votes are "accept," the transaction is committed; RTR informs all participating channels. If any vote is "not accept," the transaction is not committed. A server application can expose the prepare phase of two-phase commit by using the
rtr_mt_prepare message type with the RTR_F_OPE_EXPLICIT_PREPARE flag. If the application’s rtr_open_channel call sets neither the RTR_F_OPE_EXPLICIT_ACCEPT nor RTR_F_OPE_EXPLICIT_PREPARE flag, both prepare and accept processing are implicit.The server application can participate in the two-phase commit process fully, somewhat, a little, or not at all. To participate fully, the server does an explicit prepare and an explicit accept of the transaction. To participate somewhat, the server does an explicit prepare and an implicit accept of the transaction. To participate a little, the server does an explicit accept of the transaction. To participate not at all, the server does an implicit accept of the transaction. Table 5-6 summarizes the level of server participation:
5-6: Server Participation| Commit Phase | Full | Somewhat | Little | Not at all |
| Explicit prepare | yes | yes | ||
| Explicit accept | yes | yes | ||
| Implicit accept | yes | yes |
Your application can use the level of participation that makes the most sense for your
business and operations needs.
To request an explicit accept and explicit prepare of transactions, the server channel is opened with the
RTR_F_OPE_EXPLICIT_PREPARE and RTR_F_OPE_EXPLICIT_ACCEPT flags. These specify that the channel will receive both prepare and accept messages. The server then explicitly accepts or rejects a transaction when it receives the prepare message.The transaction sequence for an explicit prepare and explicit accept is as follows:
Client
RTR
Server
With explicit transaction handling, the following steps occur:
A participant can reject the transaction up to the time RTR has sent the
rtr_mt_prepare message type to the server in the rtr_accept_tx call. A participant can reject the transaction up to the time the rtr_accept_tx call is executed. Once the client application has called rtr_accept_tx, the result cannot be changed.The sequence for an implicit prepare and explicit accept is as follows:
Client
RTR
Server
In certain database applications, where the database manager does not let an application explicitly prepare the database, transactions can simply be accepted or rejected. Server applications that do not specify the
RTR_F_EXPLICIT_ACCEPT flag in their rtr_open_channel call implicitly accept the in-progress transaction when an rtr_receive_message call is issued after the last message has been received for the transaction. This call returns the final status for the transaction, rtr_mt_accepted or rtr_mt_rejected. If neither the RTR_F_OPE_EXPLICIT_ACCEPT nor the RTR_F_OPE_EXPLICT_PREPARE flags are set in the rtr_open_channel call, then both prepare and accept processing will be implicit.For server optimization, the server can signal its acceptance of a transaction with either
rtr_reply_to_client, using the RTR_F_REP_ACCEPT flag, or with the client issuing the rtr_send_to_server call, using the RTR_F_SEN_ACCEPT flag. This helps to minimize network traffic for transactions by increasing the likelihood that the data message and the RTR accept message will be sent in the same network packet.When a transaction fails in progress, RTR provides recovery support using RTR replay technology. RTR, as a distributed transaction manager, communicates with a database resource manager in directing the two-phase commit process. When using the XA protocol, the application does not need to process rtr_mt_uncertain messages (see the section Using XA, for more details on using XA).
The typical server application transaction sequence for committing a transaction to the database is as follows:
rtr_receive_message (rtr_mt_msg1)
SQL update
rtr_accept_tx
rtr_receive_message (rtr_mt_accepted)
SQL commit
rtr_receive_message [wait for next transaction]
This sequence is also illustrated in Figure 2-9, CSN Vote Window for the C API.
A failure can occur at any step in this sequence; the impact of a failure depends on when (at which step) it occurs, and on the server configuration.
If a failure occurs before the
rtr_accept_tx call is issued, RTR causes the following to occur:If a failure occurs after the
rtr_accept_tx call is issued but before the rtr_receive_message, the transaction is replayed. The type of the first message is then rtr_mt_uncertain when the server is restarted. In this case, servers should check to see if the transaction has already been executed in a previous presentation. If not, it is safe to re-execute the transaction because the database operation never occurred. After the failure, the following occurs:If a failure occurs after the SQL commit but before receipt of a message starting the next transaction, RTR does not know the difference.
If a failure occurs after an
rtr_receive_message call is made to begin a new transaction, RTR assumes a successful commit if a server calls rtr_receive_message after receiving the rtr_mt_accepted message and will forget the transaction. There is no replay following these events.Under certain conditions, transactions may become blocked or hung, and applications can use certain RTR features to clear such roadblocks. Often, a blocked state can be cleared by the system manager using the SET TRANSACTION CLI command to change the state of a transaction, for example, to DONE. Only certain states, however, can be changed, and changing the state of a transaction manually can endanger the integrity of the application database. For information on using the SET TRANSACTION command from the CLI, see the Reliable Transaction Router System Manager's Manual.
To achieve a change of state within an application, the designer can use the
rtr_tid_t tid;
rtr_channel_t pchannel;
rtr_qualifier_value_t select qualifiers[4];
rtr_qualifier_value_t set_qualifiers[3];
int select_idx = 0;
int set_idx = 0;
rtr_get_tid(pchannel, RTR_F_TID_RTR, &tid);
/* Transaction branch to get current state */
select_qualifiers[select_idx].qv_qualifier = rtr_txn_state;
select_qualifiers[select_idx].qv_value = &rtr_txn_state_commit;
select_idx++;
/* Transaction branch to set new state */
set_qualifiers[set_idx].qv_qualifier = rtr_txn_state;
set_qualifiers[set_idx].qv_value = &rtr_txn_state_exception;
set_idx++;
sts = rtr_set_info(pchannel,
(rtr_flags_t) 0,
(rtr_verb_t)verb_set,
rtr_transaction_object,
select_qualifiers,
set_qualifiers);
if(sts != RTR_STS_OK)
write an error;
sts = rtr_receive_message(
/* channel */ &channel_id,
/* flags */ RTR_NO_FLAGS,
/* prcvchan */ pchannel,
/* pmsg */ msg,
/* maxlen */ RTR_MAX_MSGLEN,
/* timoutms */ 0,
/* pmsgsb / &msgsb);
if (sts == RTR_STS_OK){
const rtr_status_data_t *pstatus = (rtr_status_data_t *)msg;
rtr_uns_32_t num;
switch(pstatus -> status)
{
case RTR_SETTRANDONE: /*Set Tran done successfully */
memcpy(&num,(char*)msg+sizeof(rtr_status_data_t),
sizeof(rtr_uns_32_t));
printf(" %d transaction(s) have been processed\n");
break;
default;
}
}
RTR keeps track of how many times a transaction is presented to a server application before it is VOTED. The rule is: three strikes and you’re out! After the third strike, RTR rejects the transaction with the reason RTR_STS_SRVDIED. The server application has committed the transaction and the client believes that the transaction is committed. The transaction is flagged as an exception and the database is not committed. Such an exception transaction can be manually committed if necessary. This process eliminates the possibility that a single rogue transaction can crash all available copies of a server application at both primary and secondary sites.
Application design can change this behavior. The application can specify the retry count to use when in recovery using the
/recovery_retry_count qualifier in the rtr_set_info call, or the system administrator can set the retry count from the RTR CLI with the SET PARTITION command. If no recovery retry count is specified, RTR retries replay three times. For recovery, retries are infinite. For more information on the SET PARTITION command, see the Reliable Transaction Router System Manager's Manual; for more information on the rtr_set_info call, see the Reliable Transaction Router C Application Programmer's Reference Manual.When a node is down, the operator can select a different backend to use for the server restart. To complete any incomplete transactions, RTR searches the journals of all backend nodes of a facility for any transactions for the key range specified in the server’s rtr_open_channel call.
Use the
A user broadcast is named or unnamed. An unnamed broadcast does a match on user event number; the event number completely describes the event. A named broadcast does a match on user event number and recipient name. The recipient name is a user-defined string. Named broadcasts provide greater control over who receives a particular broadcast. Named events specifiy an event number and a textual recipient name. The name can include wildcards (% and *).
For all unnamed events, specify the evtnum field and
RTR_NO_RCPSPC for the recipient name.For example, the following code specifies named events for all subscribers:
rtr_status_t
rtr_open_channel {
...
rtr_rcpnam_t rcpnam = "*";
rtr_evtnum_t evtnum = {
RTR_EVTNUM_USERDEF,
RTR_EVTNUM_USERBASE,
RTR_EVTNUM_UP_TO,
RTR_EVTNUM_USERMAX,
RTR_EVTNUM_ENDLIST
};
rtr_evtnum_t *p_evtnum = &evtnum;
For a broadcast to be received by an application, the recipient name specified by the subscribing application on its rtr_open_channel call must match the recipient specifier used by the broadcast sender on the rtr_broadcast_event call.
Note
RTR_NO_RCPSPC is not the same as "*".
An application receives broadcasts with the rtr_receive_message call. A message type returned in the message status block informs the application of the type of broadcast received.
An application enables a callout server by setting a flag on the
For a router callout server, the application sets the following flag on the
rtr_open_channel call:rtr_ope_flag_t
flags=RTR_F_OPE_SERVER|RTR_F_OPE_TR_CALL_OUT
For a backend callout server, the application sets the following flag on the
rtr_open_channel call:rtr_ope_flag_t
flags=RTR_F_OPE_SERVER|RTR_F_OPE_BE_CALL_OUT
To provide information for the design of new applications, this section contains scenarios or descriptions of existing applications that use RTR for a variety of reasons. They include:
Brief History
In the 1980s, a large railway system implemented a monolithic application in FORTRAN for local reservations with local databases separated into five administrative domains or regions: Site A, Site B, Site C, Site D, and Site E. By policy, rail travel for each region was controlled at the central site for each region, and each central site owned all trains leaving from that site. For example, all trains leaving from Site B were owned by Site B. The railway system supported reservations for about 1000 trains.
One result of this architecture was that for a passenger to book a round-trip journey, from, say, Site B to Site A and return, the passenger had to stand in two lines, one to book the journey from Site B to Site A, and the second to book the journey from Site A to Site B.
The implementation was on a Compaq OpenVMS cluster at each site, with a database engine built on RMS, using flat files. The application displayed a form for filling out the relevant journey and passenger information: (train, date, route, class, and passenger name, age, sex, concessions). The structure of the database was the same for each site, though the content was different. RTR was not used. Additionally, the architecture was not scalable; it was not possible to add more terminals for client access or add more nodes to the existing clusters without suffering performance degradation.
New requirements from the railway system for a national passenger reservations system included the goal that a journey could be booked for any train from anywhere to anywhere within the system. Meeting this goal would also enable distributed processing and networking among all five independent sites. In addition to this new functionality, the new architecture had to be more scalable and adaptable for PCs to replace the current terminals, part of the long-term plan. With these objectives, the development team rewrote their application in C, revamped their database structure, adopted RTR as their underlying middleware, and significantly improved their overall application. The application became scalable, and additional features could be introduced. Key objectives of the new design were improved performance, high reliability in a moderately unstable network, and high availability, even during network link loss.
The structure of the database at all sites was the same, but the data were for each local region only. The database was partitioned by train ID (which included departure time), date, and class of service, and RTR data content routing was used to route a reservation to the correct domain, and bind reservation transactions as complete transactions across the distributed sites to ensure booking without conflicts. This neatly avoided booking two passengers in the same seat, for example. Performance was not compromised, and data partitioning provided efficiency in database access, enabling the application to scale horizontally as load increased. This system currently deals with approximately three million transactions per day. One passenger reservation represents a single business transaction, but may be multiple RTR transactions. An inquiry is a single transaction.
Figure A-1: Transportation Example Configuration
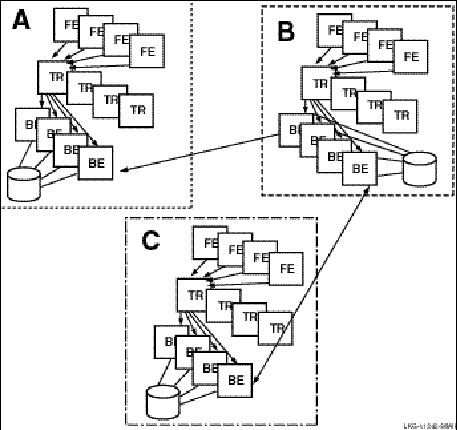
Currently the two transactions (the local and the remote) are not related to each other. The application has to make compensations in case of failure because RTR does not know that the second transaction is a child of the first. (In RTR V3.2, nested transactions could be used to specify this relationship.) This ensures that reservations are booked without conflicts.
The emphasis in configurations is on availability; local sites keep running even when network links to other sites are not up. The disaster-tolerant capabilities of RTR and the system architecture made it easy to introduce site-disaster tolerance, when needed, virtually without redesign.
Brief History
The stock exchange already had an implementation based on OpenVMS, but this system could not easily be extended to deal with other trading environments and different financial certificates.
New Implementation
This example implements reliable broadcasts, database partitioning, and uses both standby and concurrent servers.
For their implementation using RTR, the stock exchange introduced a wholly electronic exchange that is a single market for all securities listed in the country, including equities, options, bonds, and futures. The hardware superstructure is a cluster of 64-bit Compaq AlphaServer systems with a network containing high-speed links with up to 120 gateway nodes connecting to over 1000 nodes at financial institutions throughout the country.
The stock exchange platform is based on the Compaq OpenVMS cluster technology, which achieves high performance and extraordinary availability by combining multiple systems into a fault-tolerant configuration with redundancy to avoid any single point of failure. The standard trading configuration is either high-performance AlphaStations or Sun workstations, and members with multi-seat operations such as banks use AlphaServer 4100 systems as local servers. Due to trading requirements that have strict time dependency, shadowing is not used. For example, it would not be acceptable for a trade to be recorded on the primary server at exactly 5:00:00 PM and at 5:00:01 PM on the shadow.
From their desks, traders enter orders with a few keystrokes on customized trading workstation software running UNIX that displays a graphical user interface. The stock exchange processes trades in order of entry, and within seconds:
Traders further have access to current and complete market data and can therefore more effectively monitor and manage risks. The implementation ensures that all members receive the same information at the same time, regardless of location, making fairness a major benefit of this electronic exchange. (In RTR itself, fairness is achieved using randomization, so that no trader would receive information first, all the time. Using RTR alone, no trader would be favored.)
The stock exchange applications work with RTR to match, execute, and confirm buy/sell orders, and dispatch confirmed trades to the portfolio management system of the securities clearing organization, and to the international settlement system run by participating banks.
The stock exchange designed their client/server frontend to interface with the administrative systems of most banks; one result of this is that members can automate back-room processing of trades and greatly reduce per-order handling expenses. Compaq server reliability, Compaq clustering capability, and cross-platform connectivity are critical to the success of this implementation. RTR client application software resides on frontends on the gateways that connect to routers on access nodes. The access nodes connect to a 12-node Compaq OpenVMS cluster where the RTR server application resides. The configuration is illustrated in Figure A-2. Only nine trader workstations are shown at each site, but many more are in the actual configuration. The frontends are gateways, and the routers are access points to the main system.
Figure A-2: Stock Exchange Example
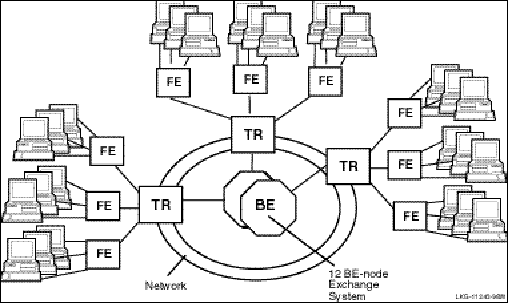
A further advantage of the RTR implementation is that the multivendor, multiprotocol 1000-node environment can be managed with only five staff people. This core staff can manage the network, the operating systems, and the applications with their own software that detects anomalies and alerts staff members by pagers and mobile computers. Using RTR also employs standard two-phase-commit processing, providing complete transaction integrity across the distributed systems. With this unique implementation, RTR swiftly became the underpinning of nationwide stock exchanges. RTR also provides ease of management, and with two-phase commit, makes it easier than previously to manage and control the databases.
The implementation using RTR also enables the stock exchange to provide innovative services and tools based on industry and technology standards, cooperate with other exchanges, and introduce new services without reengineering existing systems. For example, with RTR as the foundation of their systems, they plan an Oracle 7 data warehouse of statistical data off a central Oracle Rdb database, with Compaq Object Broker tools to offer users rapid and rich ad-hoc query capabilities. Part of a new implementation includes the disaster-tolerant Compaq Business Recovery Server solution and replication of its OpenVMS cluster configuration across two data centers, connected with the Compaq DEChub 900 GIGAswitch/ATM networking technology.
The unique cross-platform scalability of these systems further enables the stock exchange to select the right operating system for each purpose. Systems range from the central OpenVMS cluster, to frontends based on UNIX or Microsoft Windows NT. To support trader desktops with spreadsheets, an in-process implementation uses Windows NT with Microsoft Office to report trading results to the trader workstation.
Brief History
Several years ago a large bank recognized the need to devise and deliver more convenient and efficient banking services to their customers. They understood both the expense of face-to-face transactions at a bank office and wanted to explore new ways to reduce these expenses and to improve customer convenience with 24-hour service, a level of service not available at a bank office or teller window.
New Implementation
The bank had confidence in the technology, and with RTR, was able to implement the world’s first secure internet banking service. This enabled them to lower their costs as much as 80% and provide 24 x 365 convenience to their customers. They were additionally able to implement a global messaging backbone that links 20,000 users on a broad range of popular mail systems to a common directory service.
With the bank’s electronic banking service, treasurers and CEOs manage corporate finances, and individuals manage their own personal finances, from the convenience of their office or home. Private customers use a PC-based software package to access their account information, pay bills, download or print statements, and initiate transactions to any bank in the country, and to some foreign banks.
For commercial customers, the bank developed software interfaces that provide import and export links between popular business financial packages and the electronic banking system. Customers can use their own accounting system software and establish a seamless flow of data from their bank account to their company’s financial system and back again.
The bank developed its customized internet applications based on Microsoft Internet Information Server (IIS) and RTR, using Compaq Prioris servers running Windows NT as frontend web servers. The client application runs on a secure HTTP system using 128-bit encryption and employs CGI scripts in conjunction with RTR client code. All web transactions are routed by RTR through firewalls to the electronic banking cluster running OpenVMS. The IIS environment enabled rapid initial deployment and contains a full set of management tools that help ensure simple, low-cost operation. The service handles 8,000 to 12,000 users per day and is growing rapidly. Figure A-3 illustrates the deployment of this banking system.
Figure A-3: Banking Example Configuration
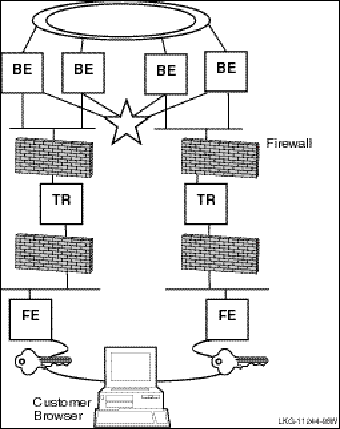
The RTR failure-tolerant, transaction-messaging middleware is the heart of the internet banking service. Data is shadowed at the transactional level, not at the disk level, so that even with a network failure, in-progress transactions are completed with integrity in the transactional shadow environment.
The banking application takes full advantage of the multiplatform support provided by RTR; it achieves seamless transaction-processing flow across the backend OpenVMS clusters and secure web servers based on Windows NT frontends. With RTR scalability, backends can be added as volume increases, load can be balanced across systems, and maintenance can be performed during full operation.
For the electronic banking application, the bank used RTR in conjunction with an Oracle Rdb database. The security and high availability of RTR and OpenVMS clusters provided what was needed for this sensitive financial application, which supports more than a quarter million customer accounts, and up to 38 million transactions a month with a total value of U.S. $300 to $400 million.
The bank’s electronic banking cluster is distributed across two data centers located five miles apart and uses Compaq GIGAswitch/FDDI systems for ultra-fast throughput and instant failover across sites without data loss. The application also provides redundancy into many elements of the cluster. For example, each data center has two or more computer systems linked by dual GIGAswitch systems to multiple FDDI rings, and the cluster is also connected by an Ethernet link to the LAN at bank headquarters.
The cluster additionally contains 64-bit Very Large Memory (VLM) capabilities for its Oracle database; this has increased database performance by storing frequently used files and data in system memory rather than on disk. All systems in the electronic banking cluster share access to 350 gigabytes of SCSI-based disks. Storage is not directly connected to the cluster CPUs, but connected to the network through the FDDI backbone. Thus, if a CPU goes down, storage survives, and is accessible to other systems in the cluster.
The multi-operating system cluster is very economical to run, supported by a small staff of four system managers who handle all the electronic banking systems. Using clusters and RTR enables the bank to provide very high levels of service with a very lean staff.
An OpenVMS cluster provides disk shadowing capabilities, and can be based on several interconnects including:
Figure B-1 shows a CI-based OpenVMS cluster configuration. Client applications run on the frontends; routers and backends are established on cluster nodes, with backend nodes having access to the storage subsystems. The LAN is the Local Area Network, and the CI is the Computer Interconnect joined by a Star Coupler to the nodes and storage subsystems. Network connections can include Compaq GIGAswitch subsystems.
Figure B-1: OpenVMS CI-based Cluster
For other OpenVMS cluster configurations, see the web site http://www.digital.com/software/OpenVMS.
The Tru64 UNIX TruCluster is typically a SCSI-based system, but can also use Memory Channel for greater throughput. Considered placement of frontends, routers, and backends can ensure transaction completion and database synchronization. The usual configuration with a Tru64 UNIX TruCluster contains PCs as frontends, establishes cluster nodes as backends, and can make one node the primary server for transactional shadowing with a second as standby server. Because this cluster normally contains only two nodes, a third non-cluster node on the network can be set up as a tie-breaker to ensure that the cluster can attain quorum. Figure B-2 illustrates a Tru64 UNIX TruCluster configuration.
Figure B-2: Tru64 UNIX TruCluster Configuration
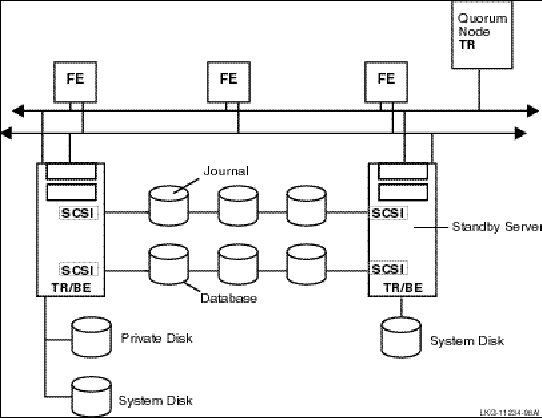
When using standby servers in the Compaq Tru64 UNIX TruCluster environment, the RTR journal must be on a shared device.
Figure B-3: Windows NT Cluster
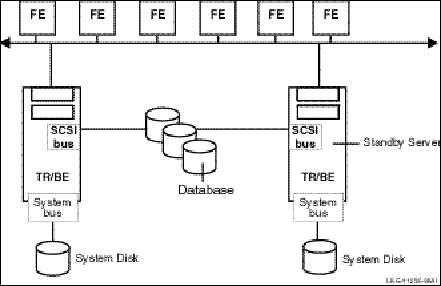
The cluster environment makes possible the use of standby servers in a shadow environment.
Figure C-1 Server Events and States with Active Transaction Message Types
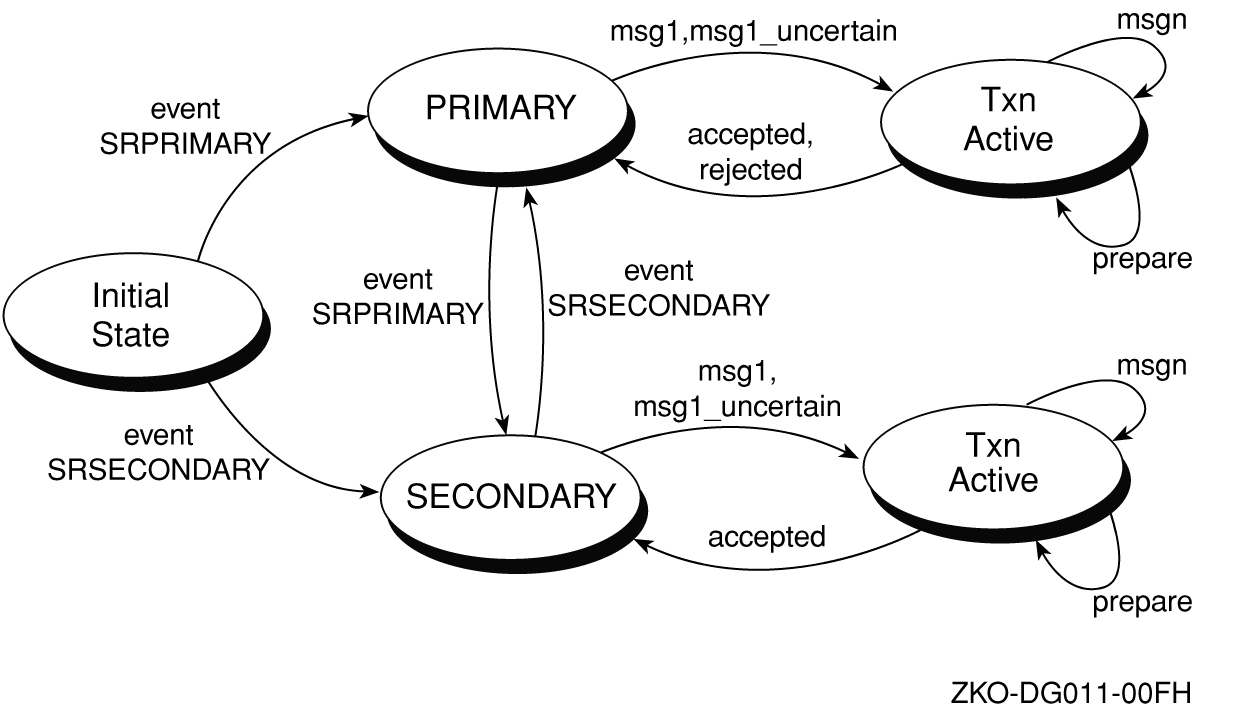
Figure C-2 shows server states after delivery of a standby event, and message types used with transactions that are active or in recovery.
Figure C-2 Server States after Standby Events
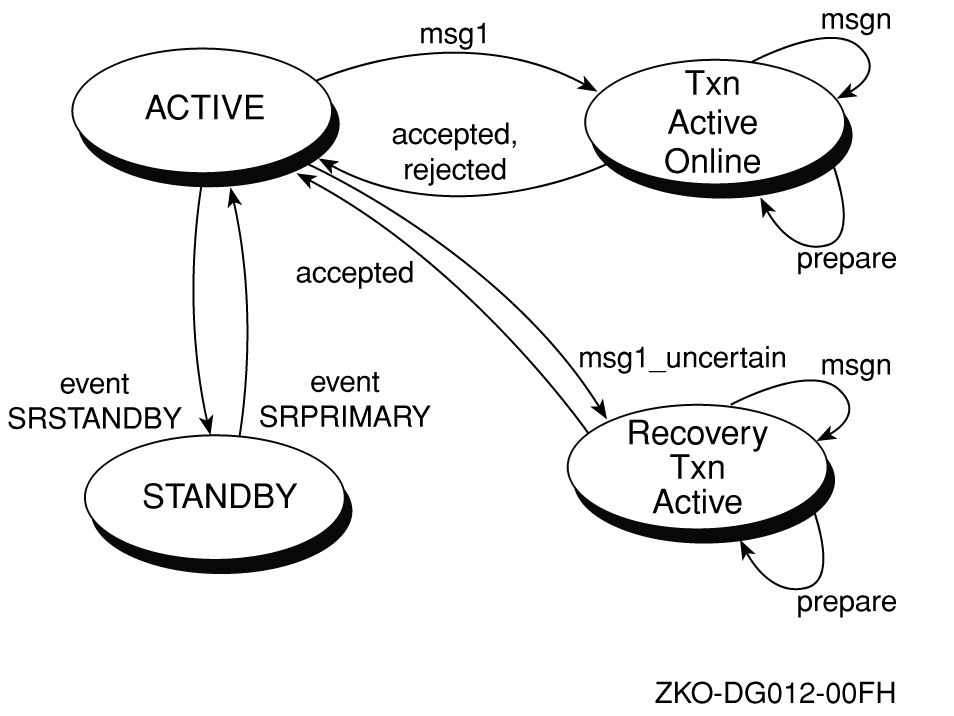
The application must specify server type with boolean attributes using the CreateBackEndPartition
method in the RTRManager class. For example, the following declaration establishes a standby server with concurrency:CreateBackEndPartition( *pszPartitionName,
pszFacility,
pKeySegment
bShadow=false
bConcurrent=true
bStandby=true);
To add a transactional shadow server, use:
bShadow = true
To disallow a standby server, use:
bStandby = false
For the C++ API, concurrent servers can be implemented as many server transaction controllers in one process or as one or many server transaction controllers in many processes.
RTR delivers transactions to any open transaction controllers, so each application thread must be ready to receive and process transactions.
An application creates a transaction controller and registers a partition with the RegisterPartition
method. To specify whether or not a server is concurrent, the application uses the CreateBackendPartition method in the RTRPartitionManager class. The rules are as follows:For example, the following declaration establishes a concurrent server that is also a standby:
CreateBackEndPartition( *pszPartitionName,
pszFacility,
pKeySegment
bShadow=false
bConcurrent=true
bStandby=true);
The following declaration establishes a server with no concurrency:
CreateBackEndPartition( *pszPartitionName,
pszFacility,
pKeySegment
bShadow=false
bConcurrent=false
bStandby=true);
For more information on the CreateBackEndPartition
method, see the Reliable Transaction Router C++ Foundation Classes manual.RTR manages the activation of standby servers at run time.
When an application creates a server partition with the CreateBackEndPartition method in the RTRPartitionManager class, it specifies whether a server is to be standby or not as follows:
CreateBackEndPartition ( *pszPartitionName,
pszFacilityName,
*pKeySegment,
bShadow = false,
bConcurrent = true,
bStandby = false);
When an application creates a server partition with the CreateBackEndPartition method in the RTRPartitionManager class, it specifies whether a server is to be a shadow or not as follows:
CreateBackEndPartition ( *pszPartitionName,
pszFacilityName,
*pKeySegment,
bShadow = true,
bConcurrent = true,
bStandby = false);
Only one primary and one secondary shadow server can be established. Shadow servers can have both standby and concurrent servers.
When partition state is important to an application, the application can determine if a shadow server is in the primary or secondary partition state after server restart and recovery following a server failure. The application does this using methods in the RTRServerEventHandler class such as OnServerIsPrimary, OnServerIsStandby, and OnServerIsSecondary. For example:
OnServerIsPrimary(*pRTRData, *pController);
Making Transactions IndependentWithin your application server code, you identify those transactions that can be considered independent, and set the state of the transaction controller object with the bIndependent attribute in the AcceptTransaction method, as appropriate. The following example illustrates how to set the bIndependent parameter to true with the AcceptTransaction method to make a transaction independent.
RTRServerTransactionController *pController= new
RTRServerTransactionController();
pController->AcceptTransaction(RTR_NO_REASON, true);
Another example:
RTRServerTransactionController stc;
/* Determine from our business logic if this transaction is independent of our other transactions. */
If (true == Independent())
{
stc.AcceptTransaction(RTR_NO_REASON,true)
}
else
{
stc.AcceptTransaction()
}
The application specifies the server type in the
rtr_open_channel call as follows:rtr_status_t
rtr_open_channel (
...
rtr_ope_flag_t
To add a transactional shadow server, include the following flags:
flags =
RTR_F_OPE_SERVER | RTR_F_OPE_SHADOW;To disallow concurrent and standby servers, use the following flags:
flags = RTR_F_OPE_SERVER | RTR_F_OPE_NOCONCURRENT | RTR_F_OPE_NOSTANDBY;
Server FailoverWith the C API, you enable RTR failover behavior with flags set when your application executes the
rtr_open_channel statement or command.For the C API, concurrent servers can be implemented as many channels in one process or as one or many channels in many processes. By default, a server channel is declared as concurrent.
RTR delivers transactions to any open channels, so each application thread must be ready to receive and process transactions. The main constraint in using concurrent servers is the limit of available resources on the machine where the concurrent servers run.
When an application opens a channel with the
rtr_open_channel call, it specifies whether the server is to be concurrent or not, as follows:For example, the following code fragment establishes a server with concurrency:
rtr_open_channel(&Channel,
RTR_F_OPE_SERVER,
FACILITY_NAME,
NULL,
RTR_NO_PEVTNUM,
NULL,
Key.GetKeySize(),
Key.GetKey() != RTR_STS_OK);
If an application starts up a second server for a partition on the same node, the second server is a concurrent server by default.
The following example establishes a server with no concurrency:
rtr_open_channel(&Channel,
RTR_F_OPE_SERVER|RTR_F_OPE_NOCONCURRENT,
FACILITY_NAME,
NULL,
RTR_NO_PEVTNUM,
NULL,
Key.GetKeySize(),
Key.GetKey() != RTR_STS_OK);
When a concurrent server fails, the server application can fail over to another running concurrent server, if one exists.
Concurrent servers are useful both to improve throughput using multiple channels on a single node, and to make process failover possible. Concurrent servers can also help to minimize timeout problems in certain server applications. For more information on this topic, see the section later in this manual on Server-Side Transaction Timeouts.
For more information on the
rtr_open_channel call, see the Reliable Transaction Router C Application Programmer’s Reference Manual and the discussion later in this document.RTR manages the activation of standby servers at run time.
When an application opens a channel, it specifies whether or not the server is to be standby, as follows:
When an application opens a channel, it specifies whether the server is to have the capability to be a transactional shadow server or not, as follows:
Only one primary and one secondary shadow server can be established. Shadow servers can have both standby and concurrent servers.
When partition state is important to an application, the application can determine if a shadow server is in the primary or secondary partition state after server restart and recovery following a server failure. The application does this using RTR events in the
rtr_open_channel call, specifying the events RTR_EVTNUM_SRPRIMARY and RTR_EVTNUM_SRSECONDARY. For example, the following is the usual rtr_open_channel declaration:rtr_status_t
rtr_open_channel (
rtr_channel_t *p_channel, //Channel
rtr_ope_flag_t flags, //Flags
rtr_facnam_t facnam, //Facility
rtr_rcpnam_t rcpnam, //Name of the channel
rtr_evtnum_t *p_evtnum, //Event number list
//(for partition states)
rtr_access_t access, //Access password
rtr_numseg_t numseg, //Number of key segments
rtr_keyseg_t *p_keyseg //Pointer to key-segment data
)
To enable receipt of RTR events that show shadow state, used if an application needs to include logic depending on partition state, the application enables receipt of RTR events that show shadow state.
The declaration includes the events as follows:
rtr_evtnum_t evtnum = {
RTR_EVTNUM_RTRDEF,
RTR_EVTNUM_SRPRIMARY,
RTR_EVTNUM_SRSECONDARY,
RTR_EVTNUM_ENDLIST
};
rtr_evtnum_t *p_evtnum = &evtnum;
Broadcasts deliver using name and subscription name. For details, see the descriptions of
rtr_open_channel and rtr_broadcast_event in the RTR C Application Programmer's Reference Manual.Within your application server code, you identify those transactions that can be considered independent, and process them with the independent transaction flags on
case rtr_mt_prepare:
/* if (txn is independent)...*/
status = rtr_accept_tx (&channel,
RTR_F_ACC_INDEPENDENT,
RTR_NO_REASON);
if (status != RTR_STS_OK)
You can also use the independent flag on the
rtr_reply_to_client call. For example,rtr_reply_to_client(channel,
RTR_F_REP_INDEPENDENT,
pmsg, msglen, msgfmt);
For a broadcast to be received by an application, the recipient name specified by the subscribing application on its
rtr_open_channel call must match the recipient specifier used by the broadcast sender on the rtr_broadcast_event call.Note
RTR_NO_RCPSPC is not the same as "*".
An application receives broadcasts with the
rtr_receive_message call. A message type returned in the message status block informs the application of the type of broadcast received.For example,
rtr_receive_message(...pmsg,maxlen,...pmsgsb);The user event would be in
msgsb.msgtype == rtr_mt_user_event. User broadcasts can also contain a broadcast message. This message is returned in the message buffer provided by the application. The size of the user’s buffer is determined by the maxlen field. The number of bytes actually received is returned by RTR in the msglen field of the message status block.An application subscribes to an RTR event with the
rtr_open_channel call. For example,rtr_status_t
rtr_open_channel(
...
rtr_rcpnam_t rcpnam = RTR_NO_RCPNAM;
rtr_evtnum_t evtnum = {
RTR_EVTNUM_RTRDEF,
RTR_EVTNUM_SRPRIMARY,
RTR_EVTNUM_ENDLIST
};
rtr_evtnum_t *p_evtnum = &evtnum;
You read the message type to determine what RTR has delivered. For example,
rtr_status_t
rtr_receive_message (
...
rtr_msgsb_t *p msgsb
)
Use a data structure of the following form to receive the message:
typedef struct {
rtr_msg_type_t msgtype;
rtr_usrhdl_t usrhdl;
rtr_msglen_t msglen;
rtr_tid_t tid;
rtr_evtnum_t evtnum; /*Event Number*/
} rtr_msgsb_t;
The event number is returned in the message status block in the evtnum field. The following RTR events return key range data back to the client application:
These data are included in the message (pmsg); size is
msglen_sizeof(rtr_msgsb_t). Other events do not have additional data.Use the following brief checklist to help diagnose a particular performance problem:
Possible fixes:
These rates should be comfortably below the rated capacity of the controller and drives. If not, you may be on the trail of a performance constraint. Try:
A rough-and-ready way to measure available network capacity is to do a file-transfer of a large file using FTP or some other program between the nodes, and divide the file size by the time taken. Note that multiple network connections may share the same hardware infrastructure, so you may need to try multiple simultaneous measurements between different node-pairs.
If the RTR network traffic measured is not substantially less than the measured capacity of the network, then this may be the cause of the performance constraint for which you are looking. Try:
If MONITOR STALLS shows a large number of stalls, especially in the columns for stalls longer than three seconds, then you very likely have a packet-loss problem in the network. Try:
(If
Network monitors generally look at overall performance, measured over a period of time. It is often possible to show a 20 percent utilization of network bandwidth over time plotted at 5 minute intervals, but miss the peaks that last for 5 seconds and lose 50 packets. It is those 50 packets that account for the odd transaction getting a response time of 45 seconds instead of the usual 200 msec.
Note
Excessive use of a MONITOR command can be disruptive to the system. For example, running several MONITOR commands simultaneously steals cycles away from RTR to do real work. To minimize the impact of using MONITOR commands, increase the sample size interval using /INTERVAL=no-of-seconds.
If the SHOW PARTITION command consistently shows the number of "Free Servers" as zero and the number of "Txns Active" larger than the number of servers, then a performance problem may be caused by queues building up because an inadequate number of server applications are ready to process incoming transactions. Try the following:
You may need to set up a dual-rail (multihome) environment to accommodate a firewall, segregate a network subnet or possibly to ease the load on an Ethernet line. In some situations, this can improve performance.
For dual-rail or multihome setup, consider these topics:
To set up frontends and routers in a dual-rail environment, use the following steps:
For example, the configuration shown in Figure G-1 illustrates a firewall in a configuration with three RTR nodes and two network cards installed on the router.
Figure G-1 Dual-Rail Configuration with Network Cards on a Router
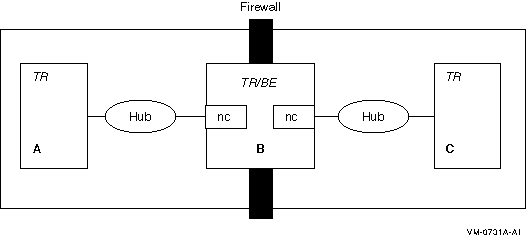
In Figure G-1, Node A is a frontend, Node B, with the two network cards (nc), is both a router and a backend, and Node C is a backend. The hubs are Ethernet hubs.
Figure G-2 illustrates a frontend with two network cards.
Figure G-2 Dual-Rail Configuration with Network Cards on a Frontend
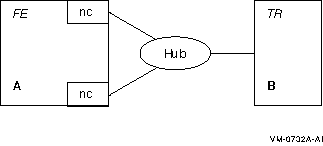
To set up the dual-rail environment, you can, as an example, create Facility A on three physical nodes (configuration shown in Figure G-1) with the following commands:
| Use this Create Facility command: | On: |
| RTR> CREATE FACILITY A
/Frontend=A /Router=B |
The frontend, node A. |
| RTR> CREATE FACILITY A /Router=B /Frontend=* /Backend=B | The router, node B. |
| RTR> CREATE FACILITY A /Router=B
/Backend=C |
The backend, node C. |
RTR resolves addresses to one name in the DNS Name Server when you use a wildcard for frontends from a router.
A host with more than one network interface is multihomed. In a multihomed configuration, care must be taken to ensure that the gethostbyname function returns the list of all possible network addresses for the host. Otherwise, RTR may reject connections when it cannot recognize the host. To return the address list, use a correctly configured DNS. Using the /etc/hosts file on a UNIX server does not return the list of addresses.
If a tunnel separates the frontends from the routers, configure the frontends on the routers with names corresponding to the pseudo-adapter addresses assigned by the tunnel. If these are unpredictable, you can use wildcards on the routers only.
If a tunnel separates the routers and the backends, configure each with respect to the other with the name prefix "tunnel."