この章には,アプリケーションを作成するための具体的な方法が書かれています。
IMLIBの機能は,アプリケーションの中で使われる状況によって,次のように分類できます。
以下の節では,分類されたそれぞれの機能について説明します。
IMLIBの初期化は以下の手順に従って行われます。
OPEN PROFILEによってPROFILEをオープンします。OPEN PROFILEが返すUNIT IDは, これ以降IMLIBのライブラリを呼び出すときに使われます。 複数のかな漢字変換コンテキストを使うアプリケーションは, 必要なコンテキストの数だけOPEN PROFILEを呼びます。
GET PROFILE DATAによって,PROFILEに書かれた情報を読み込みます。 PROFILEの情報に,キー定義以外のかな字変換の環境を定義するものが含まれています。 アプリケーションは,できる限り PROFILEに書かれた情報に従って動作することが望まれます。
SET KEYBINDによって,バイナリ形式のKEYBINDファイルを読み込みます。
以上でIMLIBの初期設定は完了します。次はキー入力処理に移ります。
IMLIBの使用を終了するときに使われる機能について,以下に示します。
CLOSE PROFILEは,PROFILEファイルをクローズしてIMLIBの使用を終了します。 CLOSE PROFILEは,IMLIBを使った機能をすべて終了した後に呼ばれます。
SET PROFILE DATAによって,PROFILEのデータを変更することができます。 SET PROFILE DATAは,メモリ上のデータを変更します。 変更された内容をファイルに書き込むにはWRITE PROFILEを使います。
WRITE PROFILEは,SET PROFILE DATAで変更された PROFILEの内容をファイルに書き込むときに使われます。
キー入力処理はIMLIBを使う上での核となる部分です。 この節は,キー入力処理を行うアプリケーションの作成方法について書かれています。
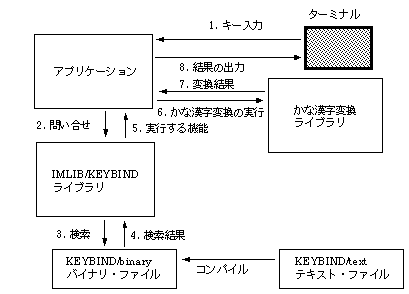
アプリケーションが,IMLIBを使ってキー入力を処理する概念を示す図を, 図 2-1に示します。
かな漢字変換入力を行うには,いくつかのレベルがあります。 IMLIBは,パーソナル・コンピュータ用に市販されているワードプロセッサ・プログラムの1つである「一太郎」 [1]と同程度のかな漢字変換入力インターフェイスの実現を前提に,設計されています。
市販されているパーソナル・コンピュータ上のワードプロセッサ・プログラムは一般に, 日本語OpenVMS 独自のかな漢字変換インターフェイス(JEDI, EVEJなどのインターフェイス)よりも, 複雑なインターフェイスを持っています。 最も典型的な例はスペース・キーの機能です。スペース・キーは, キーが押されたときの状態によって通常のスペース・キーとして動作したり, かな漢字変換キーとして動作したりします。また,自動ローマ字かな変換の機能なども, ワードプロセッサのインターフェイスの実現を複雑にしているものの1つです。
アプリケーションは,KEYBINDによって提供されるキー定義の情報や PROFILEによって指定される付加情報以外のものを,すべて用意しなければなりません。 たとえば,以下に示すものはアプリケーションが用意するものです。
IMLIBを使ったプログラムの中で実行される処理の流れを, 図 2-2 に示します。 これはIMLIBのCバインディング・インターフェイスで記述した例です。 VMSバインディングの場合は,GET KEY ACTIONが2つの呼び出し(SET KEYとGET ACTION)に分かれます。 これによって処理の流れも変わります。
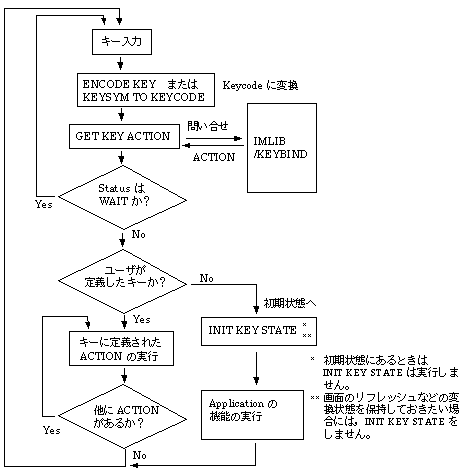
キー入力モジュールは,ユーザのキー入力を受け取ります。IMLIBを使うためには, 入力は1つのキーごとに行わなければなりません。キー入力のメカニズムは, オペレーティング・システムや使用しているユーザ環境によって異なります。 IMLIBは,OpenVMSオペレーティング・システム,ULTRIXオペレーティング・システム, Digital UNIXオペレーティング・システム,およびそれらの上に構築されている DECwindowsのインターフェイスを考慮して作られています。
OpenVMSでのキー入力には,QIOが使われます。 QIOは入力のターミネータとしてエスケープ・シーケンスを指定することができますので, キーボード上のファンクション・キー数字キーパッドや編集キーを, 1回の QIOで読み込むことができます。読み込まれたキーは,エスケープ・シーケンス, 文字キーともに ENCODE KEYを呼び出すことでIMLIB のKEYCODEに変換することができます。
DECwindowsでは,XLookupStringによってキー入力を読み込みます。 XLookupStringは,X Window Systemで定義されているKEYSYMの値を返しますので, アプリケーションは,IMLIBが提供するルーチンKEYSYM TO KEYCODEを使って, KEYCODEの値を得ます。
ワードプロセッサなどでよく見られる,キー入力時の自動ローマ字かな変換の サポートは,アプリケーションが行う必要があります。自動ローマ字かな変換を サポートするかどうかは,アプリケーション開発者の任意です。
ワードプロセッサで見られるのと同等なユーザ・インターフェイスを提供するには, 文字列バッファが3個必要です。それぞれのバッファの役割を以下に示します。
ユーザが入力した文字キーを,そのまま保持しておくバッファです。 このバッファの内容は,変換対象や入力文字列編集の対象となる文字列に対応します。 変換が確定すると,このバッファの内容は消去されます。
自動ローマ字かな変換を行った結果を保持するバッファです。 自動ローマ字かな変換を行わない場合や,かなキー入力を行った場合には, キー入力バッファの内容と同じになります。 このバッファの内容は,変換対象や入力文字列編集の対象となります。 変換が確定するとこのバッファの内容は消去されます。
スクリーン上と同じイメージを保持します。 かな漢字変換の結果はこのバッファに反映されます。
ユーザにとって使いやすい入力インターフェイスを提供するためには, 入力文字列を編集できる機能を提供することは不可欠です。 入力文字列編集とは,たとえばユーザが"日本語"と入力しようとしたのに,間違えて "nijongo"というようなローマ字を入力してしまったときに,カーソルを "j"まで移動して,"h"と置き換えるような作業のことを言います。 正しい文字と置きかわった時点で「変換キー」を押すと, かな漢字変換を行うことができるということになります。
入力文字列編集において問題となる点のうち, 自動ローマ字かな変換を行っているときに限定される点については, 第2.3.9項で説明します。 この節では,入力文字列編集について一般的な説明を行います。
入力文字列編集を行うのは,内部状態が「入力状態」にあるときです。 次のような条件の場合に内部状態が「入力状態」になります。
入力文字列編集に関連するACTIONを以下に示します。
入力文字列編集時には,上記のACTIONによって変換領域は解除しません。 バッファの内容はECHOとDELETEを除いて変化しません。 ECHOのときは,カーソル位置に入力されたキーに対応する文字を挿入し, DELETEのときは,カーソルの左側の文字を削除します。 文字の挿入と削除は,3つのバッファすべてに対して適用されます。
入力文字列編集における例外条件を,以下に示します。
上記のような場合にはアプリケーションは,PROFILEのINDEX "DEC-JAPANESE.OUTRANGE.cursorPosition"の値によって動作を決定します。 この値が"none"のときは,何も実行しません。カーソルはその位置に留まります。 この値が"done"のときは,現在の変換を終了して, アプリケーションがそのキーに対して定義した動作を実行します。
文字セル端末用のアプリケーションの多くは, オーバーストライク・モード(上書き)をサポートしています。 ここには,オーバーストライク・モードの扱いについて IMLIBが推奨する方法について記述します。
IMLIBは,通常の編集状態がオーバーストライク・モードであっても 入力文字列編集中は,インサート・モード(挿入)の動きをする方法をお勧めします。 かな漢字変換が終了して確定した文字列は,アプリケーションの オーバーストライク/インサート・モードの設定に従って, アプリケーションのバッファ中に上書き,または挿入されます。 次にオーバーストライク・モードにおける入力文字列編集について, 具体的な例をあげて説明します。IMLIBは2つの実現方法を併記します。 どちらの方法を選択するかはアプリケーションの責任です。 カーソル位置は"_"で示します。


「固定法」は,スクリーン入力型のアプリケーション,たとえばエディタなどに適した実現方法です。 すでにある文字列の位置が移動しないという利点があります。 しかし,入力文字列が長すぎると元の文字列が見えなくなります。
これに対して「浮動法」は,行入力型のアプリケーションに適した実現方法といえます。 元の文字列は編集中も見ることができます。しかし, 最終的には元の位置に戻る文字列も,編集中は移動してしまうことになります。 また,確定したときに上書きされるので, 上書きされた文字列は確定したときに突然消えることになります。
ここでは,自動ローマ字かな変換を行う際に問題となることについて記述します。
自動ローマ字かな変換状態での入力文字列編集において,最も複雑な点は, 「キー入力バッファ」の内容と「キー・エコー・バッファ」の内容が異なることです。 ユーザから見えるのは「キー・エコー・バッファ」だけであるにもかかわらず, 編集は両方のバッファに対して行わなければなりません。
ローマ字とひらがなは1対1に対応しないため,ひらがなが表示されている状態で, ローマ字の1文字だけを操作するということはできません。 編集時にカーソルはひらがなの上を1文字ずつ移動するので,「キー入力バッファ」には, どの位置にひらがなの境界があるのかを示す情報が必要になります。
たとえば,「キー入力バッファ」に"nihongo"という文字列が入っているとすると, 「キー・エコー・バッファ」は"にほんご"となっています。 このとき「キー入力バッファ」の中の"ni", "ho", "n", "go"がそれぞれ, ひらがなに対応しているという情報を持っておかなければなりません。 「キー・エコー・バッファ」中で"ほ"が消去されると, 「キー入力バッファ」においては"ho"が消去されることになります。 これは,ひらがな文字1文字に対して,ローマ字が複数文字対応している例です。 このとき"ho"は1編集単位です。
ローマ字複数文字に,ひらがな複数文字を対応させなければならない場合もあります。 たとえば,ローマ字"ryoukin"に対する,ひらがな"りょうきん"がこれにあたります。 この場合ひらがな"り"に対応するローマ字は存在しません。そのかわり, ひらがな"りょ"にローマ字"ryo"が対応します。従って,ローマ字文字列の中の "ryo",ひらがな文字列の中の"りょ"が編集単位となります。 カーソルは編集単位でしか移動できませんので, "りょ"の間にカーソルが置かれることはありません。
上記2つの例からわかるように,編集単位を示す情報は「キー入力バッファ」と 「キー・エコー・バッファ」の両方に必要です。この情報は, 入力が行われるのと同時に付けられます。両方のバッファ内には, 常に同じ数の編集単位が存在します。