![[Compaq]](../../images/compaq.gif)
![[Go to the documentation home page]](../../images/buttons/bn_site_home.gif)
![[How to order documentation]](../../images/buttons/bn_order_docs.gif)
![[Help on this site]](../../images/buttons/bn_site_help.gif)
![[How to contact us]](../../images/buttons/bn_comments.gif)
![[OpenVMS documentation]](../../images/ovmsdoc_sec_head.gif)
| Document revision date: 19 July 1999 | |
|
|
|
|
|
|
| Previous | Contents | Index |
Configuration 2 provides configuration 1 strategies, plus:
The availability of a CI configuration can be further improved by physically separating the path A and path B CI cables and their associated path hubs. This significantly reduces the probability of a mechanical accident or other localized damage destroying both paths of a CI. This configuration is shown in Figure 9-3.
Figure 9-3 Redundant Components and Path-Separated Star Couplers (Configuration 3)

Configuration 3 is electrically identical to configuration 2. However, the path A and path B cables are physically separate for both CIs. The path A cables for both CI 1 and CI 2 are routed together to star coupler cabinet A, but are connected to different CI path hubs in that cabinet.
Similarly, the path B cables for both CIs go to different CI path hubs in star coupler cabinet B. The path-specific star coupler cabinets and associated path cables should be separated as much as possible. For example, the star coupler cabinets could be installed on opposite sides of a computer room, and the CI cables could be routed so that path A and path B cables follow different paths.
The path separation technique illustrated for configuration 3 (Figure 9-3) can also be applied to configuration 1 (Figure 9-1). In this case, each star coupler cabinet would have only one path hub. The CI's path A cables would go to the path hub in Star Coupler A. Similarly, the path B cables would go to Star Coupler B. |
The CI OpenVMS Cluster configuration shown in Figure 9-3 has the following components:
| Part | Description |
|---|---|
| Host 1, Host 2 |
Dual CI capable OpenVMS Alpha or VAX hosts.
Rationale: Either host can fail and the system can continue. The full performance of both hosts is available for application use under normal conditions. |
| CI 1-1,CI 1-2, CI 2-1, CI 2-2 |
Dual CI adapters on each host. Adapter CI 1-
n is Host 1's CI adapter connected to CI
n, and so on.
Rationale: Either host's CI adapters can fail and the host will retain CI connectivity to the other host and to the HSJ storage controllers. Each CI adapter on a host is connected to a different star coupler. In the absence of failures, the full data bandwidth and I/O-per-second capacity of both CI adapters is available to the host. |
| Star Coupler A (Path A Hubs), Star Coupler B (Path B Hubs) |
Two CI star couplers, each comprising two independent path hubs. Star
Coupler A's path hubs are connected to path A cables for both CIs, and
Star Coupler B's path hubs are connected to path B cables for both CIs.
Rationale: Mechanical or other localized damage to a star coupler or an attached cable would probably not affect the other CI paths. The other paths and star coupler would continue to provide full connectivity for both CIs. Loss of a path affects only the bandwidth available to the storage controllers and host adapters connected to the failed path. When all paths are available, the combined bandwidth of both CIs is usable. |
| Path A CI Cables, Path B CI Cables | Each path's hub is connected to the CI host adapters and HSJ storage controllers by a transmit/receive cable pair per path. The path A cables of both CIs are routed together, but their routing differs from the routing of the path B cables. |
| HSJ 1, HSJ 2 |
Dual HSJ storage controllers in a single StorageWorks cabinet.
Rationale: Either storage controller can fail and the other controller can control any disks the failed controller was handling by means of the SCSI buses shared between the two HSJs. When both controllers are available, each can be assigned to serve a subset of the disks. Thus, both controllers can contribute their I/O-per-second and bandwidth capacity to the cluster. |
| SCSI 1, SCSI 2 |
Shared SCSI buses connected between HSJ pairs.
Rationale: Provide access to each disk on a shared SCSI bus from either HSJ storage controller. This effectively dual ports the disks on that bus. |
| Disk 1, Disk 2, . . . Disk n-1, Disk n |
Critical disks are dual ported between HSJ pairs by shared SCSI buses.
Rationale: Either HSJ can fail and the other HSJ will assume control of the disks that the failed HSJ was controlling. |
| Shadow Set 1 through Shadow Set n |
Essential disks are shadowed by another disk that is connected on a
different shared SCSI.
Rationale: A disk, or the SCSI bus to which it is connected, or both, can fail and the other shadow set member will still be available. When both disks are available, their combined READ I/O-per-second capacity and READ data bandwidth capacity is available to the cluster. |
Configuration 3 offers the same individual component advantages as configuration 2, plus:
Configuration 3 has the following disadvantages:
Configuration 3 provides all the strategies of configuration 2 except
for physical separation of CIs. The major advantage over configuration
2 are the path-specific star coupler cabinets. They provide physical
isolation of the path A cables and the path A hub from the path B
cables and the path B hub.
9.6 Configuration 4
The availability of a CI configuration can be further improved by physically separating shadow set members and their HSJ controllers. This significantly reduces the probability of a mechanical accident or other localized damage that could destroy both members of a shadow set. This configuration is shown in Figure 9-4.
Figure 9-4 Redundant Components, Path-Separated Star Couplers, and Duplicate StorageWorks Cabinets (Configuration 4)

Configuration 4 is similar to configuration 3 except that the shadow set members and their HSJ controllers are mounted in separate StorageWorks cabinets that are located some distance apart.
The StorageWorks cabinets, path-specific star coupler cabinets, and associated path cables should be separated as much as possible. For example, the StorageWorks cabinets and the star coupler cabinets could be installed on opposite sides of a computer room. The CI cables should be routed so that path A and path B cables follow different paths.
The separate StorageWorks cabinets technique illustrated in configuration 4 (Figure 9-4) can also be applied to configuration 1 (Figure 9-1) and configuration 2 (Figure 9-2). |
The CI OpenVMS Cluster configuration shown in Figure 9-4 has the following components:
| Part | Description |
|---|---|
| Host 1, Host 2 |
Dual CI capable OpenVMS Alpha or VAX hosts.
Rationale: Either host can fail and the system can continue to run. The full performance of both hosts is available for application use under normal conditions. |
| CI 1-1,CI 1-2, CI 2-1, CI 2-2 |
Dual CI adapters on each host. Adapter CI 1-
n is Host 1's CI adapter connected to CI
n, and so on.
Rationale: Either of a host's CI adapters can fail and the host will retain CI connectivity to the other host and the HSJ storage controllers. Each CI adapter on a host is connected to a different star coupler. In the absence of failures, the full data bandwidth and I/O-per-second capacity of both CI adapters are available to the host. |
| Star Coupler A (Path A Hubs), Star Coupler B (Path B Hubs) |
Two CI star couplers, each comprising two independent path hub
sections. Star Coupler A's path hubs are connected to the path A cables
for both CIs, and Star Coupler B's path hubs are connected to the path
B cables for both CIs.
Rationale: Mechanical or other localized damage to a star coupler or an attached cable would probably not affect the other CI paths. The other paths and star coupler would continue to provide full connectivity for both CIs. Loss of a path affects the bandwidth available to the storage controllers and host adapters that are connected to the failed path. When all paths are available, the combined bandwidth of both CIs is usable. |
| Path A CI cables, Path B CI cables | Each path's hub is connected to the CI host adapters and HSJ storage controllers by a transmit/receive cable pair per path. The path A cables of both CIs are routed together, but their routing differs from the routing of the path B cables. |
| HSJ 1, HSJ 2 |
Dual HSJ storage controllers, each in a separate StorageWorks cabinet.
Data is replicated across StorageWorks cabinets using Volume Shadowing
for DIGITAL OpenVMS.
Rationale: A StorageWorks cabinet can be destroyed, or one storage controller can fail, and the remaining controller located in the other StorageWorks cabinet can control shadow copies of all disks. When both controllers are available, each can be assigned to serve a subset of the disks. Volume shadowing will distribute READ I/Os across the HSJs. Thus, both controllers can contribute their I/O-per-second and bandwidth capacity to the cluster. |
| SCSI 1, SCSI 2 |
Private SCSI buses connected to an HSJ.
Rationale: Provide host access to each shadow set member. |
| Shadow Set |
Essential disks are shadowed between HSJ pairs using volume shadowing.
Each HSJ and its disks are in a StorageWorks cabinet that is physically
separated from the other StorageWorks cabinet.
Rationale: An entire StorageWorks cabinet can be destroyed, or a disk, the SCSI bus, or the HSJ to which it is connected can fail, and the other shadow set member will still be available. When both disks are available, they can each provide their READ I/O per second capacity and READ data bandwidth capacity to the cluster. |
Configuration 4 offers most of the individual component advantages of configuration 3, plus:
Configuration 4 has the following disadvantages:
Configuration 4 (Figure 9-4) provides all of the strategies of
configuration 3. It also provides shadow set members that are in
physically separate StorageWorks cabinets.
9.7 Summary
All four configurations illustrate how to obtain both availability and performance by:
An advanced technique, separating the CI path A and path B cables and associated hubs, is used in configuration 3 and configuration 4. This technique increases availability and maintains performance with no additional hardware. Configuration 4 provides even greater availability without compromising performance by physically separating shadow set members and their HSJ controllers.
Using these configurations as a guide, you can select the techniques that are appropriate for your computing needs and adapt your environment as conditions change. The techniques illustrated in these configurations can be scaled for larger CI configurations.
This chapter explains how to maximize scalability in many different
kinds of OpenVMS Clusters.
10.1 What Is Scalability?
Scalability is the ability to expand an OpenVMS Cluster system in any system, storage, and interconnect dimension and at the same time fully use the initial configuration equipment. Your OpenVMS Cluster system can grow in many dimensions, as shown in Figure 10-1. Each dimension also enables your applications to expand.
Figure 10-1 OpenVMS Cluster Growth Dimensions
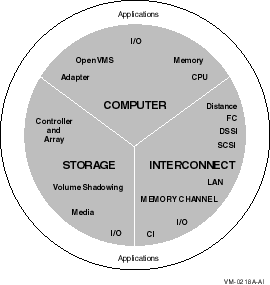
Table 10-1 describes the growth dimensions for systems, storage, and interconnects in OpenVMS Clusters.
| This Dimension | Grows by... |
|---|---|
| Systems | |
| CPU |
Implementing SMP within a system.
Adding systems to a cluster. Accommodating various processor sizes in a cluster. Adding a bigger system to a cluster. Migrating from VAX to Alpha systems. |
| Memory | Adding memory to a system. |
| I/O |
Adding interconnects and adapters to a system.
Adding MEMORY CHANNEL to a cluster to offload the I/O interconnect. |
| OpenVMS |
Tuning system parameters.
Moving to OpenVMS Alpha. |
| Adapter |
Adding storage adapters to a system.
Adding CI and DSSI adapters to a system. Adding LAN adapters to a system. |
| Storage | |
| Media |
Adding disks to a cluster.
Adding tapes and CD-ROMs to a cluster. |
| Volume shadowing |
Increasing availability by shadowing disks.
Shadowing disks across controllers. Shadowing disks across systems. |
| I/O |
Adding solid-state or DECram disks to a cluster.
Adding disks and controllers with caches to a cluster. Adding RAID disks to a cluster. |
| Controller and array |
Moving disks and tapes from systems to controllers.
Combining disks and tapes in arrays. Adding more controllers and arrays to a cluster. |
| Interconnect | |
| LAN |
Adding Ethernet and FDDI segments.
Upgrading from Ethernet to FDDI. Adding redundant segments and bridging segments. |
| CI, DSSI, Fibre Channel, SCSI, and MEMORY CHANNEL | Adding CI, DSSI, Fibre Channel, SCSI, and MEMORY CHANNEL interconnects to a cluster or adding redundant interconnects to a cluster. |
| I/O |
Adding faster interconnects for capacity.
Adding redundant interconnects for capacity and availability. |
| Distance |
Expanding a cluster inside a room or a building.
Expanding a cluster across a town or several buildings. Expanding a cluster between two sites (spanning 40 km). |
The ability to add to the components listed in Table 10-1 in any way
that you choose is an important feature that OpenVMS Clusters provide.
You can add hardware and software in a wide variety of combinations by
carefully following the suggestions and guidelines offered in this
chapter and in the products' documentation and DIGITAL Systems and
Options Catalog. When you choose to expand your OpenVMS Cluster in
a specific dimension, be aware of the advantages and tradeoffs with
regard to the other dimensions. Table 10-2 describes strategies that
promote OpenVMS Cluster scalability. Understanding these scalability
strategies can help you maintain a higher level of performance and
availability as your OpenVMS Cluster grows.
10.2 Strategies for Configuring a Highly Scalable OpenVMS Cluster
The hardware that you choose and the way that you configure it has a
significant impact on the scalability of your OpenVMS Cluster. This
section presents strategies for designing an OpenVMS Cluster
configuration that promotes scalability.
10.2.1 Scalability Strategies
Table 10-2 lists strategies in order of importance that ensure scalability. This chapter contains many figures that show how these strategies are implemented.
| Strategy | Description |
|---|---|
| Capacity planning |
Running a system above 80% capacity (near performance saturation)
limits the amount of future growth possible.
Understand whether your business and applications will grow. Try to anticipate future requirements for processor, memory, and I/O. |
| Shared, direct access to all storage |
The ability to scale compute and I/O performance is heavily dependent
on whether all of the systems have shared, direct access to all storage.
The CI and DSSI OpenVMS Cluster illustrations that follow show many examples of shared, direct access to storage, with no MSCP overhead. Reference: For more information about MSCP overhead, see Section 10.8.1. |
| Limit node count to between 3 and 16 |
Smaller OpenVMS Clusters are simpler to manage and tune for performance
and require less OpenVMS Cluster communication overhead than do large
OpenVMS Clusters. You can limit node count by upgrading to a more
powerful processor and by taking advantage of OpenVMS SMP capability.
If your server is becoming a compute bottleneck because it is overloaded, consider whether your application can be split across nodes. If so, add a node; if not, add a processor (SMP). |
| Remove system bottlenecks | To maximize the capacity of any OpenVMS Cluster function, consider the hardware and software components required to complete the function. Any component that is a bottleneck may prevent other components from achieving their full potential. Identifying bottlenecks and reducing their effects increases the capacity of an OpenVMS Cluster. |
| Enable the MSCP server | The MSCP server enables you to add satellites to your OpenVMS Cluster so that all nodes can share access to all storage. In addition, the MSCP server provides failover for access to shared storage when an interconnect fails. |
| Reduce interdependencies and simplify configurations | An OpenVMS Cluster system with one system disk is completely dependent on that disk for the OpenVMS Cluster to continue. If the disk, the node serving the disk, or the interconnects between nodes fail, the entire OpenVMS Cluster system may fail. |
| Ensure sufficient serving resources | If a small disk server has to serve a large number disks to many satellites, the capacity of the entire OpenVMS Cluster is limited. Do not overload a server because it will become a bottleneck and will be unable to handle failover recovery effectively. |
| Configure resources and consumers close to each other | Place servers (resources) and satellites (consumers) close to each other. If you need to increase the number of nodes in your OpenVMS Cluster, consider dividing it. See Section 11.2.4 for more information. |
| Set adequate system parameters | If your OpenVMS Cluster is growing rapidly, important system parameters may be out of date. Run AUTOGEN, which automatically calculates significant system parameters and resizes page, swap, and dump files. |
| Previous | Next | Contents | Index |
|
|
| privacy and legal statement | ||
| 6318PRO_013.HTML | ||