![[Compaq]](../../images/compaq.gif)
![[Go to the documentation home page]](../../images/buttons/bn_site_home.gif)
![[How to order documentation]](../../images/buttons/bn_order_docs.gif)
![[Help on this site]](../../images/buttons/bn_site_help.gif)
![[How to contact us]](../../images/buttons/bn_comments.gif)
![[OpenVMS documentation]](../../images/ovmsdoc_sec_head.gif)
| Document revision date: 19 July 1999 | |
|
|
|
|
|
|
| Previous | Contents | Index |
Executive Mode Time
High levels of executive mode time can be an indication of excessive RMS activity. File design decisions and access characteristics can have a direct impact on CPU performance. For example, consider how the design of indexed files may affect the consumption of executive mode time:
Be sure to consult the Guide to OpenVMS File Applications when designing an RMS application.
It contains descriptions of available alternatives along with their
performance implications.
13.1.3 CPU Offloading
The following are some techniques you can use to reduce demand on the CPU:
$ SET SECURITY file-spec /ACL = (IDENTIFIER=INTERACTIVE+NETWORK,ACCESS=NONE) |
Users of standalone workstations on the network can take advantage of local and client/server environments when running applications. Such users can choose to run an application based on DECwindows on their workstations, resources permitting, or on a more powerful host sending the display to the workstation screen. From the point of view of the workstation user, the decision is based on disk space and acceptable response time.
Although the client/server relationship can benefit workstations, it
also raises system management questions that can have an impact on
performance. On which system will the files be backed up---workstation
or host? Must files be copied over the network? Network-based
applications can represent a significant additional load on your
network depending on interconnect bandwidth, number of processors, and
network traffic.
13.1.5 CPU Load Balancing in an OpenVMS Cluster
You can improve responsiveness on an individual CPU in an OpenVMS Cluster by shifting some of the work load to another, less used processor. You can do this by setting up generic batch queues or by assigning terminal lines to such a processor. Some terminal server products perform automatic load balancing by assigning users to the least heavily used processor.
Do not attempt to load balance among CPUs in an OpenVMS Cluster until you are sure that other resources are not blocking (and thus not inflating idle time artificially) on a processor that is responding poorly---and until you have already done all you can to improve responsiveness on each processor in the cluster. |
Your principal tool in assessing the relative load on each CPU is the MODES class in the MONITOR multifile summary. Compare the Idle Time figures for all the processors. The processor with the most idle time might be a good candidate for offloading the one with the least idle time.
On an OpenVMS Cluster member system where low-priority batch work is being executed, there may be little or no idle time. However, such a system can still be a good candidate for receiving more of the OpenVMS Cluster work load. The interactive work load on that system might be very light, so it would have the capacity to handle more default-priority work at the expense of the low-priority work.
There are several ways to tell whether a seemingly 100% busy processor is executing mostly low-priority batch work:
$ MONITOR /INPUT=SYS$MONITOR:file-spec /VIEWING_TIME=1 PROCESSES /TOPCPU |
The following are some techniques for OpenVMS Cluster load balancing. Once you have determined the relative CPU capacities of individual member systems, you can do any of the following:
There are only two ways to apply software tuning controls to alleviate performance problems related to CPU limitations:
The other options, reducing demand or adding CPU capacity, are really
not tuning solutions.
13.2 Adjust Priorities
When a given process or class of processes receives inadequate CPU service, the surest technique for improving the situation is to raise the priority of the associated processes. To avoid undesirable side effects that can result when a process's base priority is raised permanently, it is often better to simply change the application code to raise the priority only temporarily. You should adopt this practice for critical pieces of work.
Priorities are established for processes through the UAF value. Users with appropriate privileges (ALTPRI, GROUP, or WORLD) can modify their own priority or those of other processes with the DCL command SET PROCESS/PRIORITY. Process priorities can also be set and modified during execution with the system service $SETPRI. For information on process priorities, see Section 3.9.
Priorities are assigned to subprocesses and detached processes with the DCL command RUN/PRIORITY or with the $CREPRC system service at process creation. The appropriately privileged subprocess or detached process can modify its priority while running with the $SETPRI system service.
Batch queues are assigned priorities when they are initialized
(INITIALIZE/QUEUE/PRIORITY) or started (START/QUEUE/PRIORITY). While
you can adjust the priorities on a batch queue by stopping the queue
and restarting it (STOP/QUEUE and START/QUEUE/PRIORITY), the only way
to adjust the priority on a process while it is running is through the
system service $SETPRI.
13.3 Adjust QUANTUM
By reducing QUANTUM, you can reduce the maximum delay a process will ever experience waiting for the CPU. The trade-off here is that, as QUANTUM is decreased, the rate of time-based context switching will increase, and therefore the percentage of the CPU used to support CPU scheduling will also increase. When this overhead becomes excessive, performance will suffer.
Do not adjust QUANTUM unless you know exactly what you expect to accomplish and are aware of all the ramifications of your decision. |
The OpenVMS class scheduler allows you to tailor scheduling for
particular applications. The class scheduler replaces the OpenVMS
scheduler for specific processes. The program SYS$EXAMPLES:CLASS.C
allows applications to do class scheduling.
13.5 Establish Processor Affinity
You can associate a process with a particular processor by using the
command SET PROCESS/AFFINITY. This allows you to dedicate a processor
to specific activities.
13.6 Reduce Demand or Add CPU Capacity
You need to explore ways to schedule the work load so that there are fewer compute-bound processes running concurrently. Section 1.4.2 includes a number of suggestions for accomplishing this goal.
You may find it possible to redesign some applications with improved algorithms to perform the same work with less processing. When the programs selected for redesign are those that run frequently, the reduction in CPU demand can be significant.
You also want to control the concurrent demand for terminal I/O.
If you find that none of the previous suggestions or workload management techniques satisfactorily resolve the CPU limitation, you need to add capacity. It is most important to determine which type of CPU capacity you need, because there are two different types that apply to very different needs.
Work loads that consist of independent jobs and data structures lend themselves to operation on multiple CPUs. If your work load has such characteristics, you can add a processor to gain CPU capacity. The processor you choose may be of the same speed or faster, but it can also be slower. It takes over some portion of the work of the first processor. (Separating the parts of the work load in optimal fashion is not necessarily a trivial task.)
Other work loads must run in a single-stream environment, because many pieces of work depend heavily on the completion of some previous piece of work. These work loads demand that CPU capacity be increased by increasing the CPU speed with a faster model of processor. Typically, the faster processor performs the work of the old processor, which is replaced rather than supplemented.
To make the correct choice, you must analyze the interrelationships of the jobs and the data structures.
This appendix lists decision trees you can use to conduct the evaluations described in this manual. A decision tree consists of nodes that describe steps in your performance evaluation. Numbered nodes indicate that you should proceed to the next diagram that contains that number.
Figure A-1 Verifying the Validity of a Performance Complaint
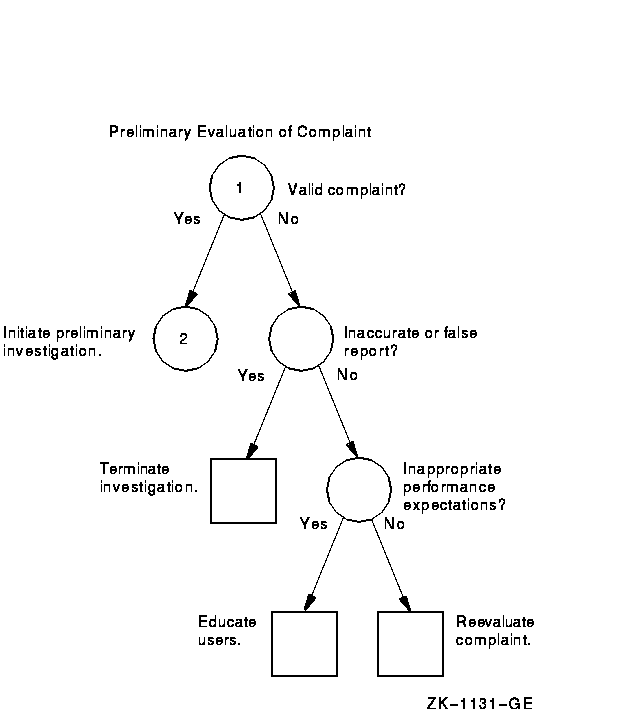
Figure A-2 Steps in the Preliminary Investigation Process
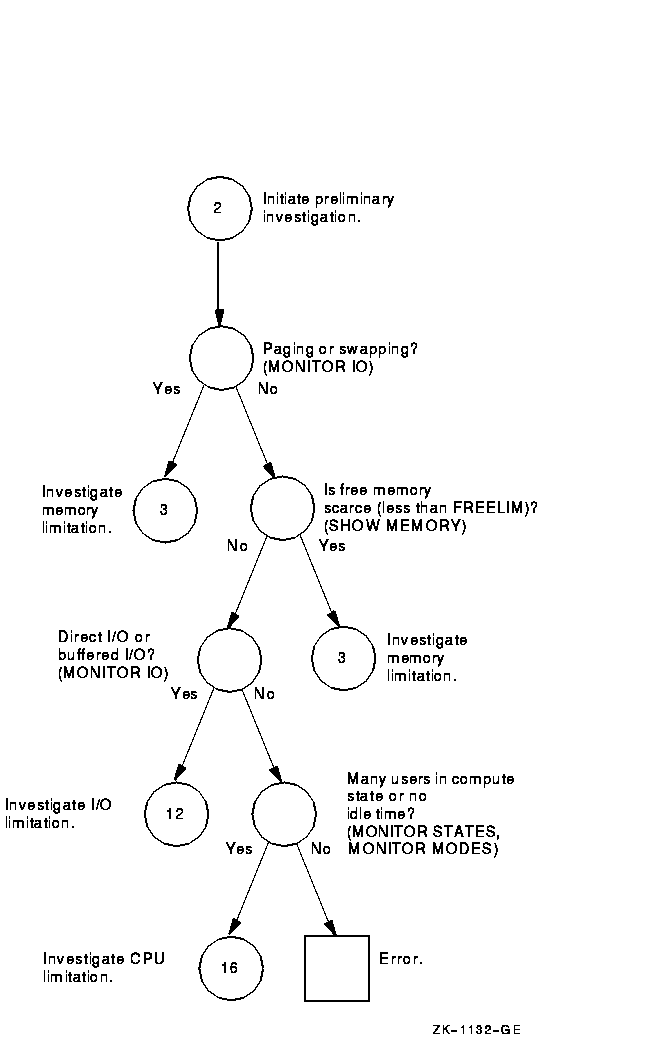
Figure A-3 Investigating Excessive Paging---Phase I
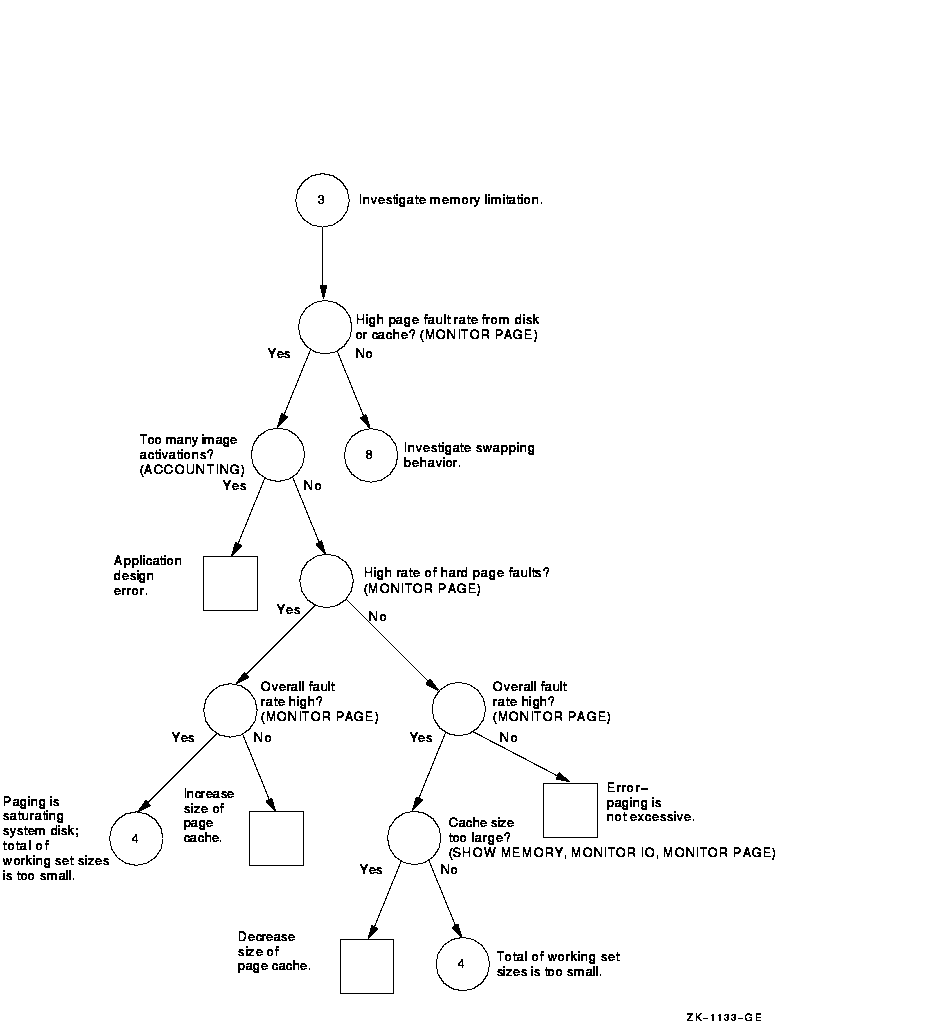
Figure A-4 Investigating Excessive Paging---Phase II
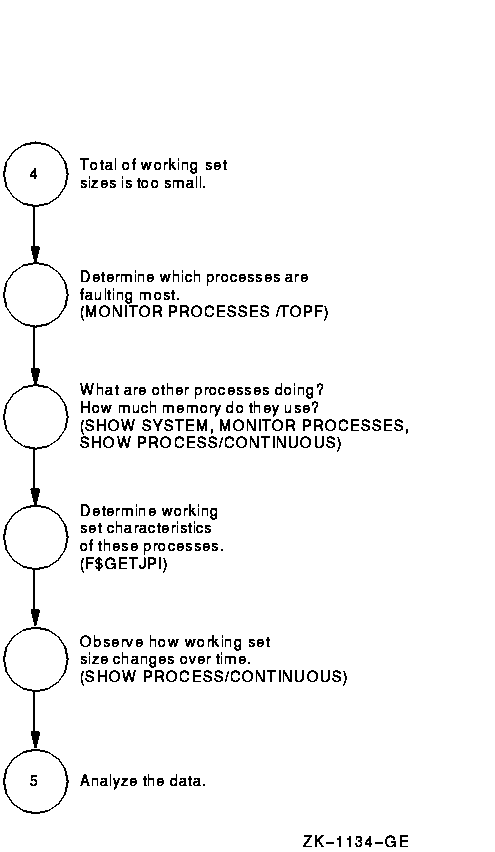
Figure A-5 Investigating Excessive Paging---Phase III
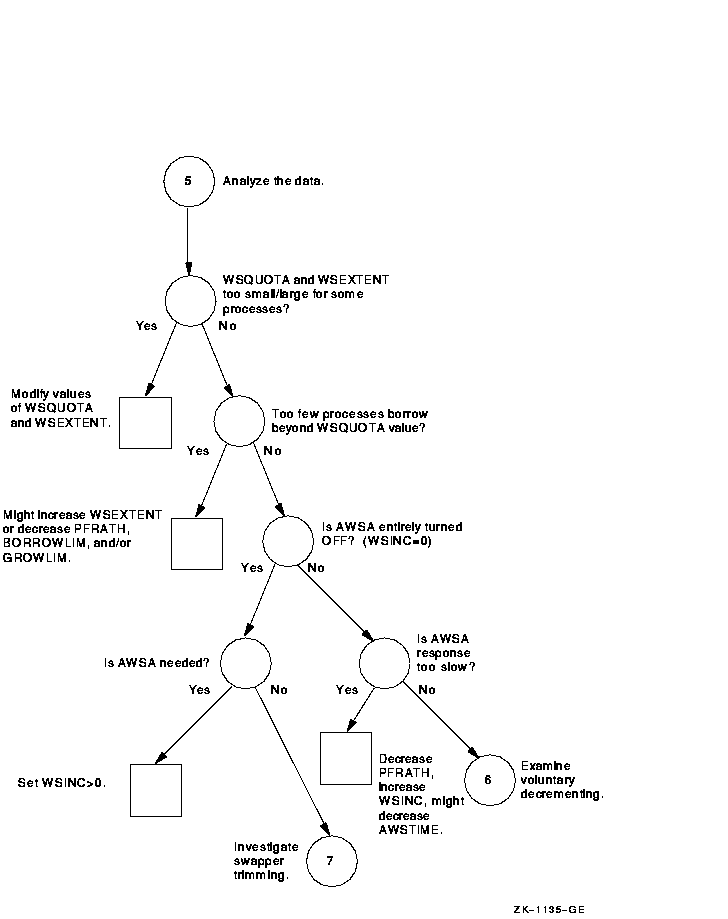
Figure A-6 Investigating Excessive Paging---Phase IV
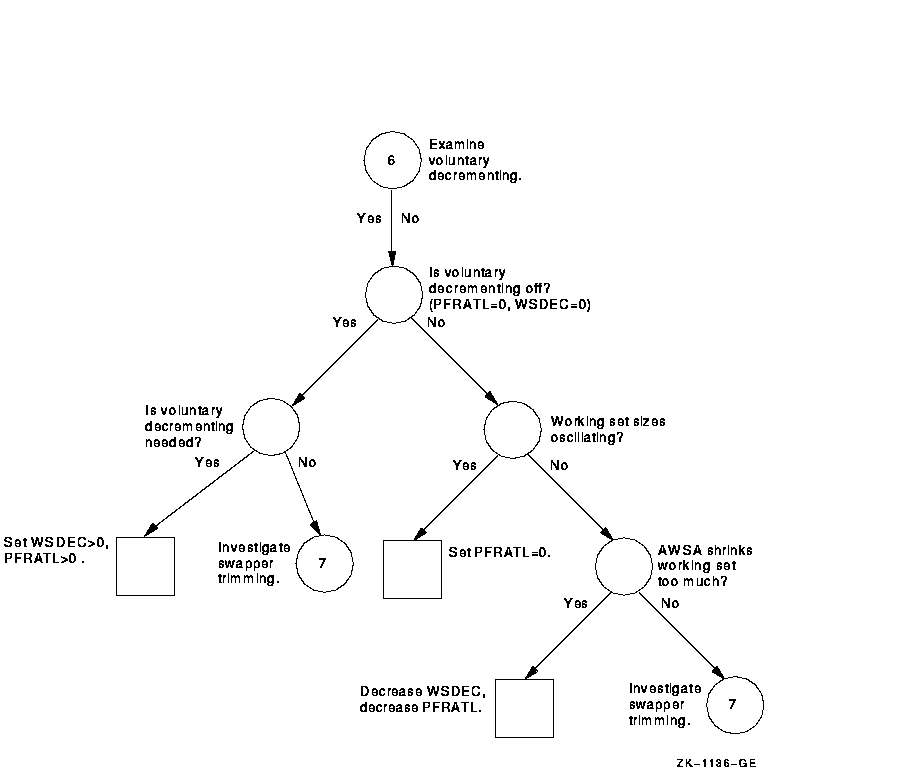
Figure A-7 Investigating Excessive Paging---Phase V
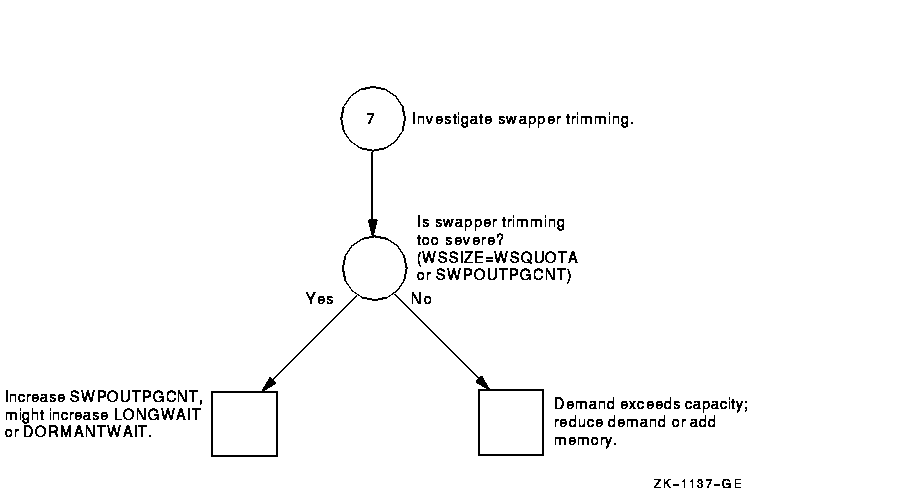
Figure A-8 Investigating Swapping---Phase I
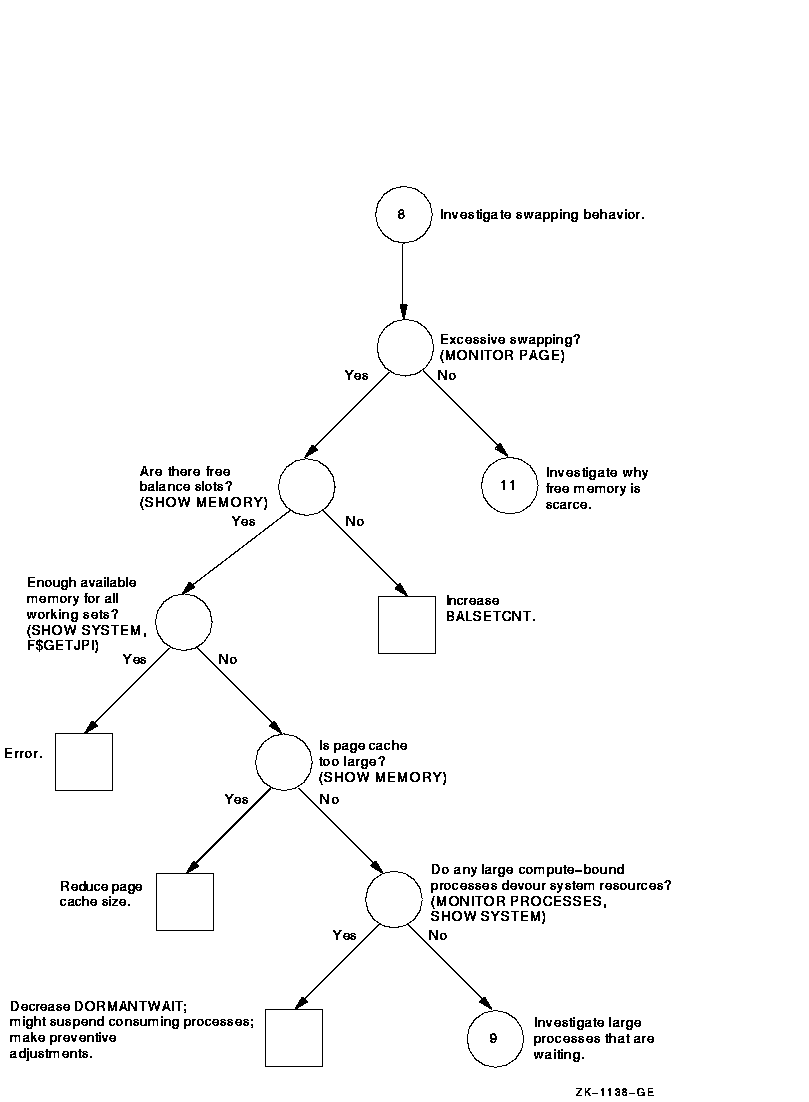
Figure A-9 Investigating Swapping---Phase II
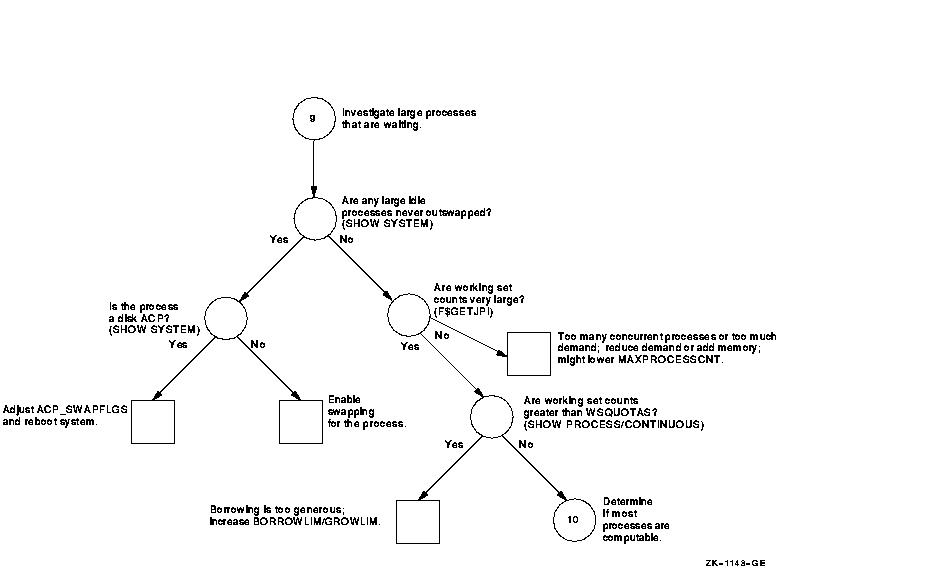
Figure A-10 Investigating Swapping---Phase III

Figure A-11 Investigating Limited Free Memory---Phase I
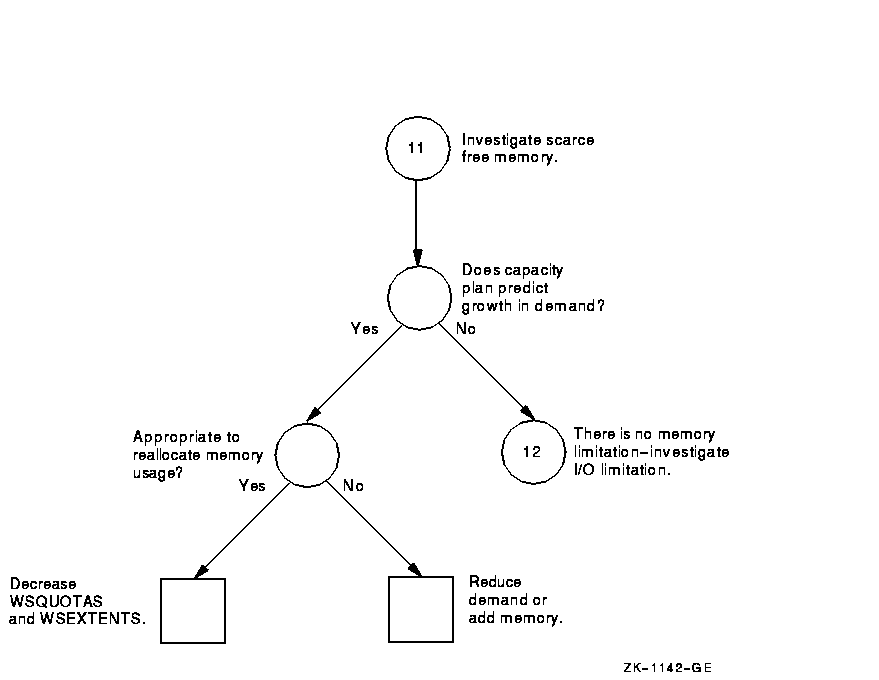
Figure A-12 Investigating Disk I/O Limitations---Phase I
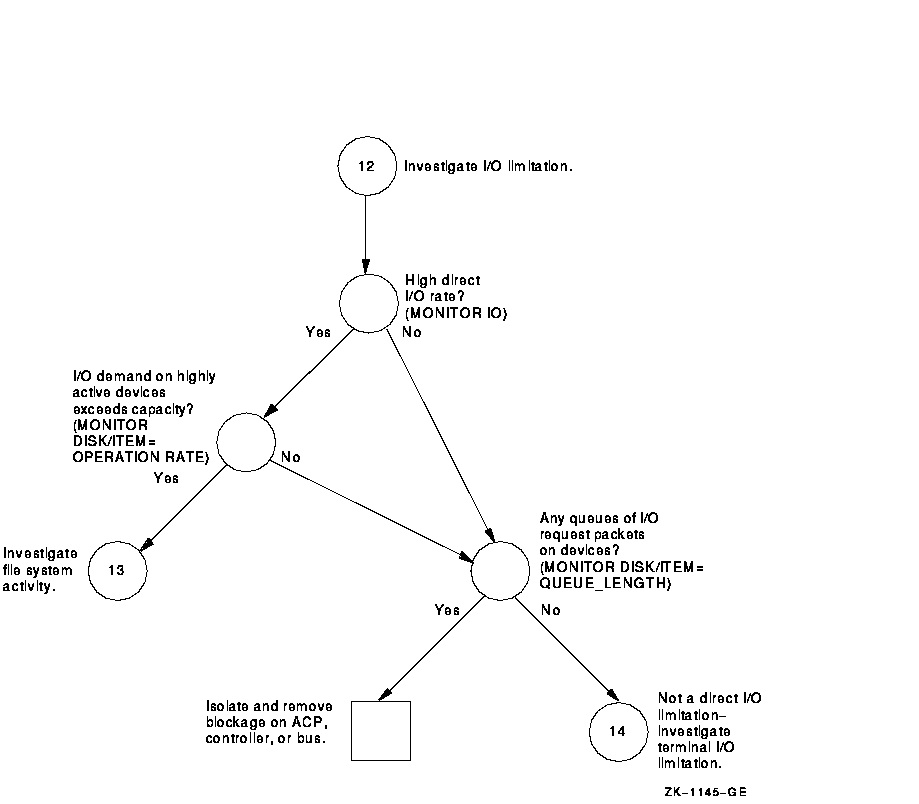
Figure A-13 Investigating Disk I/O Limitations---Phase II
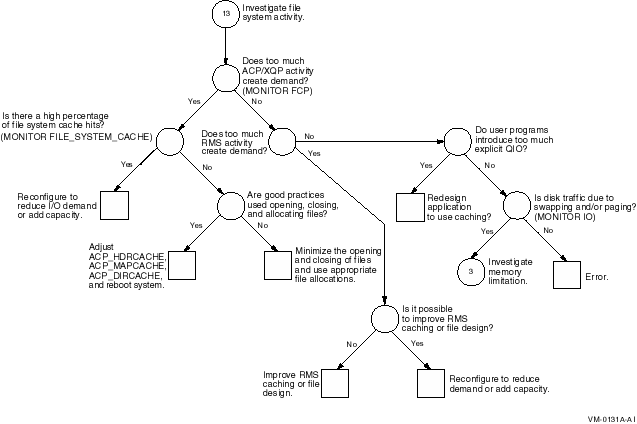
Figure A-14 Investigating Terminal I/O Limitations---Phase I

Figure A-15 Investigating Terminal I/O Limitations---Phase II
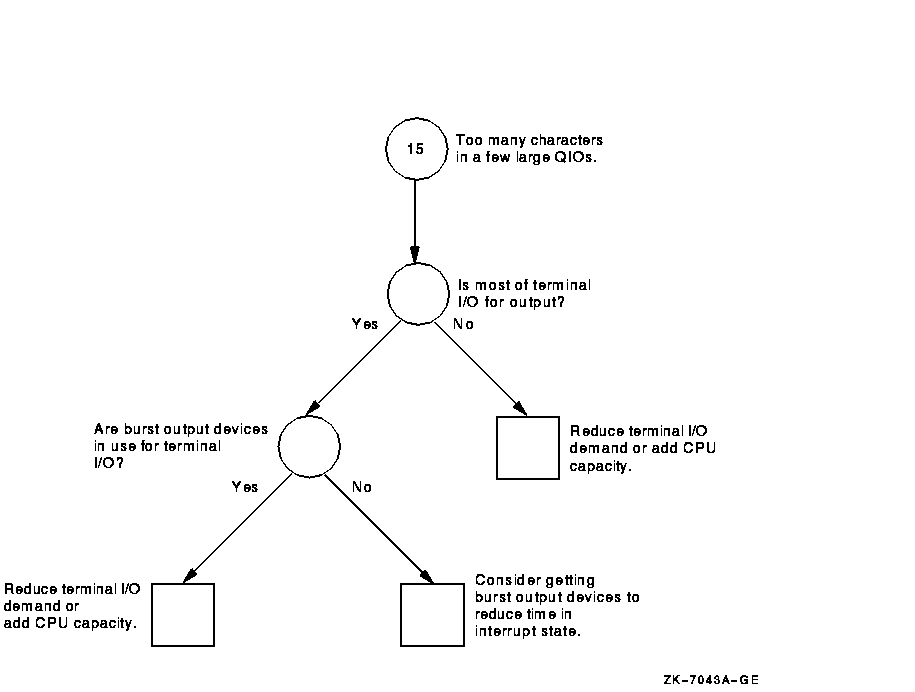
Figure A-16 Investigating Specific CPU Limitations---Phase I
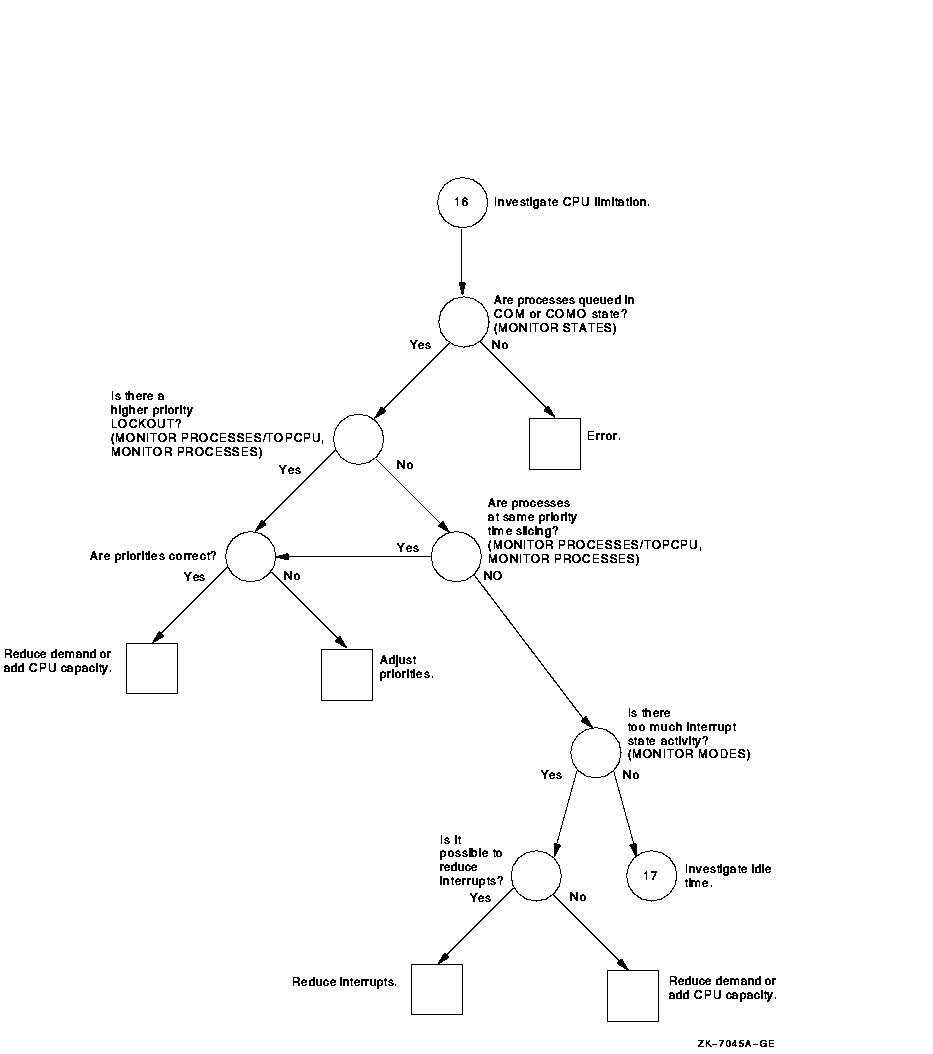
Figure A-17 Investigating Specific CPU Limitations---Phase II
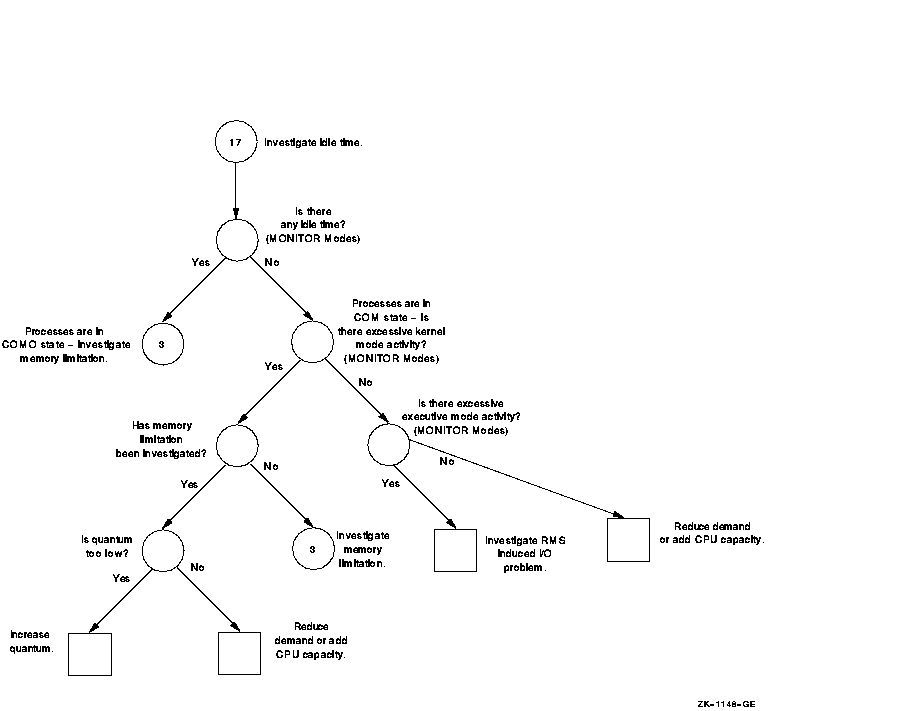
Table B-1 provides a quick reference to the MONITOR data items that you will probably need to check most often in evaluating your resources.
| Item | Class | Description1 |
|---|---|---|
|
Compute Queue
(COM + COMO) |
STATES | Good measure of CPU responsiveness in most environments. Typically, the larger the compute queue, the longer the response time. |
| Idle Time | MODES | Good measure of available CPU cycles, but only when processes are not unduly blocked because of insufficient memory or an overloaded disk I/O subsystem. |
| Inswap Rate | IO | Rate used to detect memory management problems. Should be as low as possible, no greater than 1 per second. |
|
Interrupt State Time
+ Kernel Mode Time |
MODES | Time representing service performed by the system. Normally, should not exceed 40% in most environments. |
|
MP Synchronization
Time |
MODES | Time spent by a processor waiting to acquire a spin lock in a multiprocessing system. A value greater than 8% might indicate moderate-to-high levels of paging, I/O, or locking activity. |
| Executive Mode Time | MODES | Time representing service performed by RMS and some database products. Its value will depend on how much you use these facilities. |
| Page Fault Rate | PAGE | Overall page fault rate (excluding system faults). Paging might demand further attention when it exceeds 600 faults per second. |
| Page Read I/O Rate | PAGE | The hard fault rate. Should be kept below 10% of overall rate for efficient use of secondary page cache. |
| System Fault Rate | PAGE | Rate should be kept to minimum, proportional to your CPU performance. |
|
Response Time (ms)
(computed) |
DISK | Expected value is 25--40 milliseconds for RA-series disks with no contention and small transfers. Individual disks will exceed that value by an amount dependent on the level of contention and the average data transfer size. |
| I/O Operation Rate | DISK |
Overall I/O operation rate. The following are normal load ranges for
RA-series disks in a typical timesharing environment, where the vast
majority of data transfers are small:
|
|
Page Read I/O Rate
+ Page Write I/O Rate + Inswap Rate (times 2) + Disk Read Rate + Disk Write Rate |
PAGE
PAGE IO FCP FCP |
System I/O operation rate. The sum of these items represents the portion of the overall rate initiated directly by the system. |
| Cache Hit Percentages |
FILE_
SYSTEM_ CACHE |
XQP cache hit percentages should be kept as high as possible, no lower than 75% for the active caches. |
| Previous | Next | Contents | Index |
|
|
| privacy and legal statement | ||
| 6491PRO_015.HTML | ||