第4.1節 − 組込みプロシージャが以下の機能に応じて分類されています。
- 注意
- パラメータで使われる文字列のほとんどのものにはASCII以外の文字を使用できますが, ファイル名,プロセス名などを指定するパラメータ文字列には,ASCII文字のみが使用できます。
[integer :=] ALIGN_CURSOR
| XTPU$_TOOMANY | ERROR | パラメータの数が多すぎる |
{integer2 | string2} := ASCII ({integer1 | keyword | string1})
ISO Latin1文字セットに含まれる文字を示す10進数。
キーワードはキー名でなければなりません。 キー名が印字可能文字を生成するキーの名前のときは,ASCIIはその文字を返します。 そうでなければ,ASCIIの値が0である文字を返します。
ASCII値を得たい文字。 文字列の長さが1文字よりも長いときには,最初の文字のASCII値が得られます。
ASCII組込みプロシージャはISO Latin1以外の文字を扱いません。 このため以下のような制限事項があります。
| XTPU$_ARGMISMATCH | ERROR | パラメータのデータ・タイプが正しくない |
| XTPU$_NEEDTOASSIGN | ERROR | ASCIIは代入文の右辺でのみ使用できる |
| XTPU$_NULLSTRING | WARNING | 長さ0の文字列が渡された |
| XTPU$_TOOFEW | ERROR | パラメータの数が少なすぎる |
| XTPU$_TOOMANY | ERROR | パラメータの数が多すぎる |
1. my_character := ASCII (182)この代入ステートメントはmy_characterという変数にISO Latin1文字の "¶" を代入します。
2. character := ASCII ("B")
この代入ステートメントは,
"B" という文字のASCII値(66)をcharacterという変数に代入します。
string2 := CALL_USER (integer, string1)
ユーザ作成プログラムに参照によって渡される整数値。
ユーザ作成プログラムにディスクリプタによって渡される文字列。
CALL_USERは次のように使用します。
CALL_USERのパラメータは呼び出したプログラムへの入力パラメータになります。 DEC XTPUは,パラメータに対して何の処理も行わずに外部プロシージャに渡します。 呼び出されるルーチンが必要としていない場合でも,パラメータは必ず2つ渡さなければなりません。 値を渡す必要のないときには,以下のようなNULLパラメータを渡してください。
CALL_USER (0, "")
| XTPU$_CALLUSERFAIL | WARNING | CALL_USERルーチンの実行が失敗した |
| XTPU$_ARGMISMATCH | ERROR | パラメータのデータ・タイプが正しくない |
| XTPU$_BADUSERDESC | ERROR | ユーザ・ルーチンがリターン・ディスクリプタに正しくない値を入れた |
| XTPU$_INVPARAM | ERROR | パラメータの型が間違っている |
| XTPU$_NEEDTOASSIGN | ERROR | CALL_USERは代入文の右辺でのみ使用できる |
| XTPU$_NOCALLUSER | ERROR | 実行するルーチンが光からない |
| XTPU$_TOOFEW | ERROR | パラメータの数が少なすぎる |
| XTPU$_TOOMANY | ERROR | パラメータの数が多すぎる |
ret_value := CALL_USER (6, "ABC")
この文はユーザが書いたプログラムを呼び出します。
DEC XTPUを起動する前に論理名 XTPU$CALLUSER で CALL_USER によって呼び出したいプログラムが入っているファイルを指定します。
DEC XTPUは第1パラメータ(6)を参照によって,第2パラメータ("ABC")をディスクリプタによって渡します。
もし数字と文字列を入力値として使っているならば,プログラムは6と"ABC"を処理します。
プログラムが結果を返すように作られていれば,結果はret_valueに返されます。
以下の例は,組込みプロシージャCALL_USERの使い方を具体的に示したものです。 浮動小数点演算を行うために呼び出されるルーチンは,BASICで書かれています。
! Filename:FLOATARITH.BAS
1 sub XTPU$CALLUSER ( some_integer% , input_string$ , return_string$)
10 ! don't check some_integer% because this function only does
! floating point arithmetric
20 ! parse the input string
! find and extract the operation
comma_location = pos ( input_string$, ",", 1% )
if comma_location = 0 then go to all_done end if
operation$ = seg$( input_string$, 1%, comma_location - 1% )
! find and extract the 1st operand
operand1_location = pos ( input_string$, ",", comma_location +1)
if operand1_location = 0 then go to all_done end if
operand1$ = seg$( input_string$, comma_location + 1%, &
operand1_location -1 )
! find and extract the 2nd operand
operand2_location = pos ( input_string$, ",", operand1_location + 1)
if operand2_location = 0 then
operand2_location = len( input_string$) + 1
end if
operand2$ = seg$( input_string$, operand1_location + 1%, &
operand2_location -1 )
select operation$ ! do the operation
case "+"
result$ = sum$( operand1$, operand2$ ) !
case "-"
result$ = dif$( operand1$, operand2$ ) !
case "*"
result$ = num1$( Val( operand1$ ) * Val( operand2$ ))
case "/"
result$ = num1$( Val( operand1$ ) / Val( operand2$ ))
case else
result$ = "unkown operation."
end select
return_string$ = result$
999 all_done: end sub
$ BASIC/LIST floatarigh
!+ ! File: FLOATARITH.OPT ! ! Options file to link floatarith BASIC program with VAXTPU !- FLOATARITH.OBJ UNIVERSAL=XTPU$CALLUSER
$ LINK floatarith/SHARE/OPT/MAP/FULL
$ DEFINE XTPU$CALLUSER device:[directory]floatarith.EXE
PROCEDURE my_call_user
! test the built-in procedure call_user
LOCAL output,
input;
input := READ_LINE ("Call user>"); ! パラメータを入力
output := CALL_USER (0, input); ! プログラムの呼び出し
MESSAGE (output);
ENDPROCEDURE;
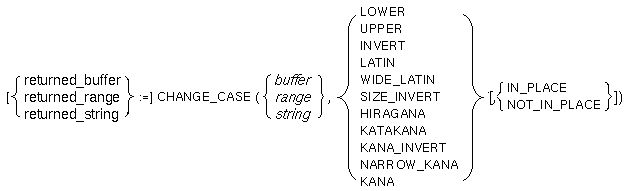
変更したい文字列を含むバッファ。 第1パラメータにバッファを指定したときには,キーワードNOT_IN_PLACEは使えません。
変更したい文字列を含むレンジ。 第1パラメータにレンジを指定したときには,キーワードNOT_IN_PLACEは使えません。
変換したい文字列。 第3パラメータにIN_PLACEを指定したときには,第1パラメータに指定された文字列を変更します。 文字列定数に対しては何も行いません。
指定した文字列のアルファベット(全角,半角)は小文字に変換されます。
指定した文字列のアルファベット(全角,半角)は大文字に変換されます。
指定した文字列のアルファベット(全角,半角)が大文字の場合には小文字に変換され, 小文字の場合には大文字に変換されます。
指定した文字列の全角のLatin文字は半角のLatin文字に変換されます。
指定した文字列の半角のLatin文字は全角のLatin文字に変換されます。
指定した文字列の半角のLatin文字は全角に,全角のLatin文字は半角に変換されます。
指定した文字列のカタカナ(全角)および半角カナはひらがなに変換されます。
指定した文字列のひらがなおよび半角カナはカタカナ(全角)に変換されます。
指定した文字列のひらがなはカタカナ(全角)に,カタカナ(全角)はひらがなに変換されます。
指定した文字列のひらがなおよびカタカナ(全角)は半角カナに変換されます。
指定した文字列のアルファベット(半角,全角)はローマ字として扱われ, ひらがなに変換されます。また,文字列中のカタカナおよび半角カナはひらがなに変換されます。
| returned_buffer | 第1パラメータにバッファを指定したときに, 変更されたテキストが含んだバッファが戻されるバッファ型の変数。 変数 "returned_buffer" は第1パラメータで指定されたバッファと同じバッファを示します。 |
| returned_range | 第1パラメータにレンジを指定したときに, 変更されたテキストを含んだレンジが戻されるレンジ型の変数。 変数 "returned_range"は第1パラメータで指定されたレンジと同じレンジを示します。 |
| returned_string | 第1パラメータに文字列を指定したときに,変更されたテキストを含む文字列が戻される文字列型の変数。 IN_PLACEを指定したときにも,文字列は戻されます。 |
表 4-1はCHANGE_CASEの各キーワードとその変換項目です。
| キーワード | ||||||||
|---|---|---|---|---|---|---|---|---|
| 文字列 | LATIN | WIDE_ LATIN |
KANA | HIRA GANA | KATA KANA |
KANA_ INVERT | NARROW_ KANA | SIZE_INVERT |
| 半角 | none | 全角 | ひら | none | none | none | none | 全角 |
| 全角 | 半角 | none | ひら | none | none | none | none | 半角 |
| ひらがな | none | none | none | none | カタ | カタ | 半カ | none |
| カタカナ | none | none | ひら | ひら | none | ひら | 半カ | none |
| 半角カナ | none | none | ひら | ひら | カタ | none | none | none |
|
none = 変換されない ひら = ひらがな カタ = カタカナ 半カ = 半角カナ | ||||||||
| XTPU$_BADKEY | WARNING | 間違ったキーワードが指定された |
| XTPU$_NOTMODIFIABLE | WARNING | 変更できないバッファの中のテキストを変更することはできない |
| XTPU$_ARGMISMATCH | ERROR | 引数の型が正しくない |
| XTPU$_CONTROLC | ERROR | CHANGE_CASEの実行中に[Ctrl/C]が押された |
| XTPU$_INVPARAM | ERROR | パラメータのデータ・タイプが間違っている |
| XTPU$_TOOFEW | ERROR | パラメータの数が少なすぎる |
| XTPU$_TOOMANY | ERROR | パラメータの数が多すぎる |
[{returned_buffer |
returned_range} :=] CHANGE_CODE ({buffer | range }, keyword1, keyword2)
変更したい文字列を含むバッファ。
変更したい文字列を含むレンジ。
変換前のコードセットを示すキーワード。有効なキーワードは, DEC_MCS,ISO_LATIN1,ASCII_JISKANA,DECKANJI,SDECKANJI,およびSJISです。
変換後のコードセットを示すキーワード。有効なキーワードは, DEC_MCS,ISO_LATIN1,ASCII_JISKANA,DECKANJI,SDECKANJI,およびSJISです。
| returned_buffer | 第1パラメータにバッファを指定したときに, 変更されたテキストが含んだバッファが戻されるバッファ型の変数。 変数 "returned_buffer" は第1パラメータで指定されたバッファと同じバッファを示します。 |
| returned_range | 第1パラメータにレンジを指定したときに,変更されたテキストを含んだレンジが戻されるレンジ型の変数。 変数"returned_range"は第1パラメータで指定されたレンジと同じレンジを示します。 |
| XTPU$_BADKEY | WARNING | 間違ったキーワードが指定された |
| XTPU$_NOTMODIFIABLE | WARNING | 変更できないバッファの中のテキストを変更することはできない |
| XTPU$_CONTROLC | ERROR | CHANGE_CODEの実行中に[Ctrl/C]が押された |
| XTPU$_INVPARAM | ERROR | パラメータのデータ・タイプが間違っている |
| XTPU$_TOOFEW | ERROR | パラメータの数が少なすぎる |
| XTPU$_TOOMANY | ERROR | パラメータの数が多すぎる |
{integer3|string2} := CODE ({integer1|keyword|string1} [,integer2])
UCS-2での文字の10進数表現。0から65535までの値が有効です。 それ以外の数字を渡したときの動作は定義されていません。
対応する文字が必要なキーの名前。 プリント可能な文字に対応しないキーのキー名を指定した場合には, CODEはUCS-2の値が0である文字を戻します。
対応するUCS-2の値が必要な文字。 1文字より長い文字列を指定した場合には,CODEは最初の文字の値を戻します。
文字のカラム幅を示す整数。 このパラメータは第1パラメータに整数を指定したときのみ指定できます。 省略時の値は1です。 漢字など2カラム文字のUCS-2コードから文字列への変換を行うときは, このパラメータに2を指定しなければなりません。
文字列パラメータが与えられたときには, このプロシージャは最初の文字に対応するUCS-2コードを通知します。
| XTPU$_NULISTRING | WARNING | 長さ0の文字列が渡された |
| XTPU$_ARGMISMATCH | ERROR | 引数のデータ・タイプが正しくない |
| XTPU$_NEEDTOASSIGN | ERROR | CODEは代入文の右辺でのみ使用できる |
| XTPU$_TOOFEW | ERROR | 引数の数が少なすぎる |
| XTPU$_TOOMANY | ERROR | 引数の数が多すぎる |
integer := COLUMN_LENGTH ({buffer | range | string})
カラム長を知りたいバッファの名前。 バッファを指定した場合,行の終端はカラム数としてカウントされないので注意してください。
カラム長を知りたいレンジの名前。 レンジを指定した場合,行の終端はカラム数としてカウントされないので注意してください。
カラム長を知りたい文字列。
| XTPU$_ARGMISMATCH | ERROR | COLUMN_LENGTHのパラメータは,バッファ,レンジ,文字列のいずれかでなければならない |
| XTPU$_CONTROLC | ERROR | COLUMN_LENGTHの実行中に [Ctrl/C]が押された |
| XTPU$_NEEDTOASSIGN | ERROR | COLUMN_LENGTHは代入文の右辺でのみ使用できる |
| XTPU$_TOOFEW | ERROR | パラメータの数が少なすぎる |
| XTPU$_TOOMANY | ERROR | パラメータの数が多すぎる |
[{strint2|integer2} :=] CONVERT_KANA (keyword [,{string1 | integer1}])
変換に関する各指示を指定するキーワードで,下記の中から1つを指定します。 指定するキーワードによって,その他のパラメータや戻り値のデータ・タイプが異なります。
| START_CONVERSION | 新しい変換を開始し,変換文字列を返します |
| FORWARD | 現在の文節の次候補を含む変換文字列を返します |
| REVERSE | 現在の文節の前候補を含む変換文字列を返します |
| NONE | 現時点での変換文字列を返します |
| END_CONVERSION | 漢字辞書を更新します |
| HIRAGANA | 現在の文節をひらがなに変換し,変換文字列を返します |
| KATAKANA | 現在の文節をカタカナ(全角)に変換し,変換文字列を返します |
| NARROW_KANA | 現在の文節を半角カナに変換し,変換文字列を返します |
| ROMAN | 現在の文節を全角英数字に変換し,変換文字列を返します |
| SHRINK | 現在の文節の長さを縮小し,変換文字列を返します |
| EXPAND | 現在の文節の長さを拡大し,変換文字列を返します |
| CLAUSE_OFFSET | 現在の文節の漢字列中の文字オフセットを返します |
| CLAUSE_LENGTH | 現在の文節の文字長を返します |
| PHONETIC_OFFSET | 現在の文節の読み文字列中の文字オフセットを返します |
| PHONETIC_LENGTH | 現在の文節の読みの長さを返します |
| CLAUSE_NEXT | 次の文節に移動します |
| CLAUSE_PREVIOUS | 前の文節に移動します |
| CLAUSE_NUMBER | 現在の文節番号を設定します |
| MAX_CLAUSE_NUMBER | 現在の変換文字列の文節数を返します |
新しい変換を開始するときの読み文字列。 かな漢字変換は全角かなの部分を対象とします。 キーワードがSTART_CONVERSIONの場合にのみ必要で,それ以外の場合に指定してはいけません。
現在の文節を指定した番号の文節に設定します。 キーワードがCLAUSE_NUMBER の場合のみに有効で,それ以外の場合に指定してはいけません。
キーワードがCLAUSE_OFFSETの場合,現在の文節の変換文字列中での文字オフセットの値が整数値で返されます。 CLAUSE_LENGTHの場合,現在の文節の変換後文字列に占める文字長が整数値で返されます。
キーワードがCLAUSE_OFFSET,CLAUSE_LENGTHの場合,変換された文字列を返します。 この文字列は,現在の文節に対応する文字列ではなく, string1 で指定した読み文字列全体に対する変換文字列です。 ただし,FORWARD,REVERSE,HIRAGANAなどの変換操作の対象となるのは, 文字列全体ではなく,現在の文節に対応する文字列です。
かなを漢字に変換する場合,いくつかの候補文字(同音異字語)が存在することがあります。 このプロシージャは,START_CONVERSIONのキーワードを指定すると辞書の第1候補を返し, FORWARD,REVERSEを指定するとそれぞれ次候補,前候補を返します。 また,END_CONVERSIONを指定するとその時点での候補の, 次に同じ単語の変換(START_CONVERSION)を開始する時の優先順位が上がるので, よく使われる単語は再変換の回数が少なくてすむようになります。
変換機能
ASCII(半角) / ROMAN(全角)からひらがな,カタカナ,ローマ字へ, あるいはひらがな,カタカナから漢字への変換が可能です。
| START_CONVERSION | string1 で指定された読みの変換を開始します。 このとき,string1 に対する文法解析を行い,変換文字列は1またはそれ以上の文節に分けられます。 このとき,現在の文節は1番目の文節となります。 |
| FORWARD | 現在の文節の自立語の次候補を求め,新しい変換文字列を返します。 |
| REVERSE | 現在の文節の自立語の前候補を求め,新しい変換文字列を返します。 |
| NONE | 現時点での変換文字列をそのまま返します。 |
| END_CONVERSION | 変換文脈を終了し,変換文字列を確定するとともに,個人辞書の学習を行います。 |
| HIRAGANA | 現在の文節をひらがなに変換し,新しい変換文字列を返します。 ASCII,ROMAN,ひらがなおよびカタカナからなる部分が変換対象となります。 |
| KATAKANA | 現在の文節をカタカナ(全角)に変換し,新しい変換文字列を返します。 1回目に呼ばれた時は文節の自立語のみをカタカナに変換し, 2回目に呼ばれた時は文節全体をカタカナに変換します。 STARTの時 string1 にはひらがなで渡されていなければなりません。 |
| NARROW_KANA | 現在の文節を半角カナに変換し,新しい変換文字列を返します。 1回目に呼ばれた時は文節の自立語のみを半角カナに変換し, 2回目に呼ばれた時は文節全体を半角カナに変換します。 STARTの時 string1 にはひらがなで渡されていなければなりません。 |
| ROMAN | 現在の文節を全角英数字に変換し,新しい変換文字列を返します。 ASCIIからなる部分のみが変換対象となります。 |
| SHRINK | 現在の文節の長さを1文字分縮小し,文法解析を再び行って新しい変換文字列を返します。 文法解析の結果,文節の長さが1以上縮小されることもあります。 |
| EXPAND | 現在の文節の長さを拡大し,文法解析をやりなおして新しい変換文字列を返します。 |
一般的に,文節の縮小/拡大を実行すると,現在の文節以降の文字列が変化し, それに伴って文節数も変化する可能性が高いので注意してください。
| CLAUSE_OFFSET | 現在の文節が,変換文字列の中のどの位置から始まるかを文字オフセットとして返します。 文節移動を行った結果として値が変化します。 |
| CLAUSE_LENGTH | 現在の文節の長さを返します。変換操作を行った後は値が変化する可能性があります。 |
| PHONETIC_OFFSET | 現在の文節が,読み文字列の中のどの位置から始まるかを文字オフセットとして返します。 文節移動を行った結果として値が変化します。 |
| PHONETIC_LENGTH | 現在の文節の読み文字列の長さを返します。 変換操作を行った後は値が変化する可能性があります。 |
| CLAUSE_NEXT | 変換対象を次の文節に移動します。 この結果,FORWARD,REVERSEなどの対象となる部分が次の文節に移動します。 |
| CLAUSE_PREVIOUS | 変換対象を前の文節に移動します。 現在の文節が先頭の文節である場合,最後の文節に移動します。 この結果,FORWARD,REVERSEなどの対象となる部分が次の文節に移動します。 |
| CLAUSE_NUMBER | パラメータ integer1 で指定した文節を現在の文節とします。 integer1を指定しなかったときは,現在の文節の文節番号を返します。 |
| MAX_CLAUSE_NUMBER | 現在の変換文字列の文節数を返します。 |
| XTPU$_ROUND | INFORMATION | FORWARDによる次候補が一巡して最初の単語に戻った |
| XTPU$_NEEDTOASSIGN | ERROR | 返される値を代入する変数が必要である |
| XTPU$_NODIC | WARNING | この編集セッションでは辞書を使用していない |
| XTPU$_BADVALUE | ERROR | 指定した整数値が有効な範囲内にない |
| XTPU$_CNVERR | ERROR | かな漢字変換ルーチンの内部エラーが発生した |
| XTPU$_DICUPDERR | ERROR | 個人辞書の更新時にエラーが発生した |
| XTPU$_INVPARAM | ERROR | 引数の型が正しくない |
| XTPU$_NOCLA | ERROR | 変換対象となる文節が指定されていない,変換を開始していない |
| XTPU$_NODICENT | WARNING | 文節の縮小あるいは拡大ができない。単語が辞書にない(変換不可能) |
| XTPU$_STRTOOLONG | ERROR | 入力文字数が253文字を越えた |
| XTPU$_TOOFEW | ERROR | パラメータの数が少なすぎる |
| XTPU$_TOOMANY | ERROR | パラメータの数が多すぎる |
| XTPU$_TRUNCATE | WARNING | 変換文字列が長すぎるため,切り捨てが行われた |
{integer2|string2} := DEC_KANJI ({integer1|string1})
ASCII文字あるいは漢字に変換したい整数。 ASCIIあるいはDEC漢字セットで決められた整数(10進数)。
ASCIIコードあるいはDEC漢字コードを得たい文字。
文字列パラメータが与えられたときには, このプロシージャは最初の文字に対応するASCIIコードあるいはDEC漢字コードを戻します。
| XTPU$_NULLSTRING | WARNING | 長さ0の文字列が渡された |
| XTPU$_ARGMISMATCH | ERROR | 引数のデータ・タイプが正しくない |
| XTPU$_NEEDTOASSIGN | ERROR | DEC_KANJIは代入文の右辺でのみ使用できる |
| XTPU$_TOOFEW | ERROR | 引数の数が少なすぎる |
| XTPU$_TOOMANY | ERROR | 引数の数が多すぎる |
PROCEDURE user_kanji_list (jis_ku)
LOCAL cnt, col, low_byte;
cnt := jis_ku * 256 + 41120;
max := cut + 94;
COPY_TEXT (FAO('第 !ZL 区', jis_ku));
SPLIT_LINE;
COPY_TEXT ("0 1 2 3 4 5 6 7 8 9 A B C D E F");
SPLIT_LINE;
COPY_TEXT (user_hex(cnt) + ' ');
col := 1;
LOOP
EXITIF cnt 〉max;
IF col 〉16 THEN
SPLIT_LINE;
UPDATE (current_window);
col := 1;
COPY_TEXT (user_hex(cnt) + ' ');
ENDIF;
low_byte := cnt-((cnt / 256)*256);
IF low_byte〈〉160 THEN
COPY_TEXT (' '+ DEC_KANJI(cnt));
ELSE
COPY_TEXT (' ');
ENDIF;
cnt := cnt + 1;
col := col + 1;
ENDLOOP;
SPLIT_LINE;
ENDPROCEDURE;
PROCEDURE user_hex (dec_num)
LOCAL res, rmn, temp;
temp := dec_num;
IF temp =0 THEN
res := '0'
ELSE
res := ''
ENDIF;
LOOP
EXITIF temp 〈= 0;
rmn := temp-((temp / 16) * 16);
temp := temp / 16;
IF (0〈 rmn) AND (rmn〈 16) THEN
res := SUBSTR ('123456789ABCDEF', rmn, 1) + res;
ELSE
res := '0' + res;
ENDIF;
ENDLOOP;
user_hex := res;
ENDPROCEDURE;
DELETE_TANGO (string1, string2)
辞書から削除される単語の読みを表わすひらがな文字列。
辞書から読みを削除される単語。
『日本語ライブラリ 利用者の手引き』第5章 "かな漢字変換ライブラリ" のJLB$DEL_TANGOを参照してください。
| XTPU$_NODIC | WARNING | この編集セッションでは個人辞書は使用していない |
| XTPU$_NODICENT | WARNING | 個人辞書に指定された単語が見つからない |
| XTPU$_DICUPDERR | ERROR | 個人辞書の変更時にエラーが発生した |
| XTPU$_INVPARAM | ERROR | 引数のデータ・タイプが正しくない |
| XTPU$_NORETURNVALUE | ERROR | DELETE_TANGOは値を返さない |
| XTPU$_TOOFEW | ERROR | 引数の数が少なすぎる |
| XTPU$_TOOMANY | ERROR | 引数の数が多すぎる |
1. DELETE_TANGO (" じゅうしょ", "東京都あきる野市")
このステートメントは,個人辞書に登録されている単語 "東京都あきる野市" と,
その読み "じゅうしょ" を個人辞書から削除します。
次のサンプル・プロシージャは,選択された単語を個人辞書から削除します。 読みがなを引数としてとり,引数が空文字であると, その読みをローマ字で入力するように要求します。 単語が選択されていない場合や削除に失敗した(単語とその読みが正しくない)ときにはエラー・メッセージが表示されます。 このプロシージャで用いている user_select_position は,選択開始位置を示すグローバル変数です。
! This procedure specifies start position of selection
PROCEDURE user_select
ON_ERROR
IF error = XTPU$_ONESELECT THEN
MESSAGE ("すでに選択されています。");
RETURN;
ENDIF;
ENDON_ERROR;
user_select_position := SELECT (reverse);
ENDPOROCEDURE
! This procedure removes selected TANGO and its YOMIGANA
! from personal dictionary.
PROCEDURE user_delete_tango (yomi)
LOCAL yomigana, tango_range, tango;
ON_ERROR
IF (error = XTPU$_NOSELECT) OR (error = XTPU$_SELRANGEZERO) THEN
MESSAGE ("単語が選択されていません。");
ELSE
MESSAGE ("単語を削除できません。");
ENDIF;
user_select_position := 0;
RETURN;
ENDON_ERROR;
tango_range := select_range;
user_select_position := 0; ! This global variable is used to
! specify start position of selection
POSITION (BEGINNING_OF(tango_range));
tango := SUBSTR (tango_range, 1, LENGTH(tango_range));
tango_range := 0;
yomigana := yomi;
IF yomigana = ''THEN
yomigana := READ_LINE (" 読みがなをローマ字で入力してください:");
ENDIF;
CHANGE_CASE (yomigana, KANA);
DELETE_TANGO (yomigana, tango);
ENDPROCEDURE;
ENTER_TANGO (string1, string2)
個人辞書に登録する単語の読みを表わすかな文字列。
個人辞書に登録する単語。
『日本語ライブラリ 利用者の手引き』の "かな漢字変換ライブラリ" の JLB$ENT_TANGO を参照してください。
| XTPU$_NODIC | WARNING | この編集セッションでは個人辞書は使用していない |
| XTPU$_DICUPDERR | ERROR | 個人辞書の変更時にエラーが発生した |
| XTPU$_INVPARAM | ERROR | 引数のデータ・タイプが正しくない |
| XTPU$_NORETURNVALUE | ERROR | ENTER_TANGOは値を返さない |
| XTPU$_TOOFEW | ERROR | 引数の数が少なすぎる |
| XTPU$_TOOMANY | ERROR | 引数の数が多すぎる |
1. ENTER_TANGO (" じゅうしょ", "東京都あきる野市")
このステートメントは,個人辞書に単語 "東京都あきる野市" と,
その読み "じゅうしょ" を新しく登録します。
次のサンプル・プロシージャは,選択された単語を個人辞書に登録します。 読みがなを引数としてとり,引数が空文字であると, その読みをローマ字で入力するように要求します。 単語が選択されていないときや登録に失敗した(単語とその読みが正しくない)ときにはエラー・メッセージを表示します。 このプロシージャで用いている user_select_position は,選択開始位置を示すグローバル変数です。
PROCEDURE user_select
! This procedure specifies start position of selection
ON_ERROR
IF error = XTPU$_ONESELECT THEN
MESSAGE ("すでに選択されています。");
RETURN;
ENDIF;
ENDON_ERROR;
user_select_position := SELECT (REVERSE);
ENDPROCEDURE;
! This procedure reserves selected TANGO and its YOMIGANA
! in personal dictionary.
PROCEDURE user_enter_tango (yomi)
LOCAL yomigana, tango_range, tango;
ON_ERROR
IF (error = XTPU$_NOSELECT) OR (error = XTPU$_SELRANGEZERO) THEN
MESSAGE ("単語が選択されていません。");
ELSE
MESSAGE ("単語を登録できません。");
ENDIF;
user_select_position := 0;
RETURN;
ENDON_ERROR;
tango_range := select_range;
user_select_position := 0; ! This global variable is used to
! specify start position of selection
POSITION (BEGINNING_OF(tango_range));
tango := SUBSTR (tango_range, 1, LENGTH(tango_range));
tango_range := 0;
yomigana := yomi;
IF yomigana = '' THEN
yomigana := READ_LINE (" 読みがなをローマ字で入力してください:");
ENDIF;
CHANGE_CASE (yomigana, KANA);
ENTER_TANGO (yomigana, tango);
ENDPROCEDURE;
FAOには最大127個までのパラメータを指定することができます。
FAOは,指定された文字列をメッセージ・コードセットに指定されたコードセットに変換して, $FAOシステム・サービスを呼び出します。 このため,そのときのメッセージ・コードセットで表現できない文字は, FAOを呼び出した結果,失われます。 メッセージ・コードセットについて詳しくは, SET(MESSAGE_CODESET)組込みプロシージャを参照してください。
$FAOシステム・サービスについての詳しい説明は, 『OpenVMS System Services Reference Manual』を参照してください。
string2 := FAO (string1 [,FAO parameters])
引用符で囲まれた文字列,文字列定数を含む変数名,または文字列を表わす式であり, 固定長テキストの出力文字列とFAOディレクティブから構成されます。
文字列の一部として指定することができるFAOディレクティブは下記のとおりです。
| !AS | 文字列を入力されたとおりに挿入する |
| !OL | 倍長語(ロングワード)を8進数に変換する |
| !XL | 倍長語(ロングワード)を16進数に変換する |
| !ZL | 倍長語(ロングワード)を10進数に変換する |
| !UL | 倍長語(ロングワード)を10進数に変換するが, 負の数値に対する調整は実行しない |
| !SL | 倍長語(ロングワード)を10進数に変換し,負の数値も正しく変換する |
| !/ | 新しい行を挿入する(キャリッジ・リターン/ライン・フィード) |
| !_ | タブを挿入する |
| !^ | フォーム・フィードを挿入する |
| !! | 感嘆符を挿入する |
| !%S | 最後に変換された数値が1でない場合にはSを挿入する |
| !%T | パラメータとして0を入力した場合には, 現在の時刻を挿入する(DEC XTPUは4倍長語を使用しないため, 特定の時刻を渡すことはできない) |
| !%D | パラメータとして0を入力した場合には,現在の日付と時刻を挿入する (DEC XTPUは4倍長語を使用しないため特定の日付を渡すことはできない) |
FAOパラメータについては『OpenVMS System Services Reference Manual』を参照してください。 一般的には,FAOパラメータは string1 のFAOディレクティブに対応しています。
FAO組込みプロシージャの引数に指定される文字列は, メッセージ・コードセットに指定される文字列でなければなりません。 メッセージ・コードセットについての詳しい説明は,SET (MESSAGE_CODESET)を参照してください。
| XTPU$_INVFAOPARAM | WARNING | 引数が整数または文字列でない |
| XTPU$_INVPARAM | ERROR | FAOの第1引数は文字列でなければならない |
| XTPU$_NEEDTOASSIGN | ERROR | FAO組込みプロシージャは代入文の右辺でのみ使用できる |
| XTPU$_TOOFEW | ERROR | 引数の数が少なすぎる |
FILL ({buffer|range}, [string [,integer1 [,integer2 [,integer3]]]])
形式を変更したいテキストを含むバッファ。
形式を変更したいテキストを含むレンジ。
テキストをバッファに挿入するときにワード区切り文字として使用したい文字の集合。 半角の空白文字は常にワード区切り文字です。
左マージンの値。 左マージンの値は1以上で,右マージンの値より小さくなければなりません。 省略時にはバッファの左マージンが使われます。
右マージンの値。 右マージンの値は左マージンよリ大きく,バッファの最大レコード・サイズ以下でなければなりません。 省略時にはバッファの右マージンが使われます。
最初の行の段付けの値。この値は最初の行の左マージンを変更します。 値は正負共に有効ですが,この値を左マージンに足した結果が1以上で,かつ右マージンよリ小さくなければなりません。 省略時には0が使われます。
DEC XTPUではFILL組込みプロシージャが2カラム以上の文字(複数カラム文字)を扱うことができます。 複数カラム文字が含まれているときには,1カラム文字のワード区切り文字に加えて, 2つの複数カラム文字の間もワード区切りとして扱われます。 すなわち,2つの複数カラム文字の間で行が分割されることがあります。
DEC XTPUのFILL組込みプロシージャでは,日本語の禁則処理をすることができます。 行頭禁則文字の指定には,SET (FILL_NOT_BEGIN)を,行末禁則文字の指定には, SET (FILL_NOT_END)を使います。また,SET (MARGIN_ALLOWANCE)で, 右マージンの右側に置くことのできる行頭禁則文字の文字数を指定することができます。
Latin文字からなる文章にFILLを実行したときに行末に空白文字がくると,その空白文字は削除されます。 また,FILLの結果複数行がつながると,その間に空白文字が置かれます。 しかし複数カラム文字が含まれているときには,この機能が不要になることがあります。 そのようなときには,SET(FILL_TRIM_SPACE)でFILLを実行するときに, 空白文字の削除および追加を行うかどうかを制御できます。
| XTPU$_BADMARGINS | WARNING | 正しくないFILLのマージンが指定された |
| XTPU$_INVRANGE | WARNING | 正しくないレンジ領域が指定された |
| XTPU$_NOTMODIFIABLE | WARNING | 変更が禁止されているバッファでFILLを実行することはできない |
| XTPU$_ARGMISMATCH | ERROR | パラメータのデータ・タイプが正しくない |
| XTPU$_CONTROLC | ERROR | FILLの実行中に[Ctrl/C]が押された |
| XTPU$_INVPARAM | ERROR | パラメータのデータ・タイプが正しくない |
| XTPU$_NOCACHE | ERROR | 割り当てられたメモリの不足で新しい行が作れない |
| XTPU$_TOOFEW | ERROR | パラメータの数が少なすぎる |
| XTPU$_TOOMANY | ERROR | パラメータの数が多すぎる |
return_value := GET_INFO (parameter1, parameter2)
return_value := GET_INFO (parameter1, parameter2, parameter3)
DEC XTPUのデータ・タイプまたはキーワード。 GET_INFOは,parameter1 として指定されたアイテムに関する情報を通知します。 parameter1 として指定できるデータ・タイプのうちDEC XTPUで拡張されたものについては, 表 4-2を参照してください。 また,parameter1 として指定できるキーワードのうちDEC XTPUで拡張されてものについては, 表 4-3を参照してください。
引用符で囲まれた文字列,変数名,または表 4-2 または表 4-3の文字列定数を表わす式。 parameter2 として使用される文字列は, parameter1 で指定されたアイテムに関して要求される情報の種類を指定します。 文字列は大文字で入力しても小文字で入力してもかまいません。
引用符で囲まれた文字列,変数名。 parameter1 がSCREENで paramerter2 が "video_character_set"という文字列のときは, parameter3 には文字セットを示すキーワードを与えます。 有効なキーワードはDEC_SUPPLEMENTAL,LATIN1_SUPPLEMENTAL,JIS_ROMAN, JIS_KATAKANA,KANJI_1,またはKANJI_UDCです。
| parameter1 | parameter2 | 戻り値 | 戻り値の説明 |
|---|---|---|---|
| バッファ変数 | "character_index" | 整数 | 現在の編集位置の文字境界からのカラム・オフセット |
| "character_length" | 整数 | 現在の編集位置の文字のカラム長 | |
| "codeset" | キーワード | バッファのコードセットを示すキーワード | |
| "output_codeset" | キーワード | バッファの出力コードセットを示すキーワード | |
| マーカ変数 | "character_index" | 整数 | マーカの文字境界からのカラム・オフセット |
| "character_length" | 整数 | マーカのある文字のカラム長 |
| parameter1 | parameter2 | 戻り値 | 戻り値の説明 |
|---|---|---|---|
| COMMAND_LINE | "codeset" | キーワード | /CODESET=に指定したコードセット名 |
| "kanji_dictionary" | [1] 整数 (1か0) |
/KANJI_DICTIONARYがアクティブであるかどうかを示す値 (省略時の値によって,またはDEC XTPUを呼び出すときに/KANJI_DICTIONARYを指定することによって) | |
| "kanji_dictionary_file" | 文字列 | /KANJI_DICTIONARY=に指定した個人辞書ファイル名 | |
| SCREEN | "video_character_set" | [1] 整数 (1か0) |
第3パラメータで指定した文字セットを画面に表示できるかどうかを示す値 |
| SYSTEM | "codeset" | キーワード | システム・コードセットを示すキーワード |
| "fill_not_begin" | 文字列 | 行頭禁則文字からなる文字列 | |
| "fill_not_end" | 文字列 | 行末禁則文字からなる文字列 | |
| "fill_trim_space" | [1] 整数 (1か0) |
FILL組込みプロシージャで分割された行の最後の空白文字を取り除くかどうかを示す値 | |
| "jis_roman" | [1] 整数 (1か0) |
JISローマ字文字セットがASCII文字セットに代わって使われるかどうかを示す値 | |
| "kanji_dictionary_file" | 文字列 | DEC XTPUが呼びだされたときに使用された個人辞書ファイル名 | |
| "keyboard_codeset" | キーワード | キーボード・コードセットを示すキーワード | |
| "margin_allowance" | 整数 | 右マージンを越えて置くことができる行頭禁則文字の数 | |
| "message_codeset" | キーワード | メッセージ・コードセットを示すキーワード | |
| [1] 1 という整数値は条件が真であることを示し,0 という整数値は偽 であることを示す。 | |||
| XTPU$_BADREQUEST | WARNING | 2番目の引数によって指定される要求が最初の引数のデータ・タイプに対して正しくないものである |
| XTPU$_BADKEY | WARNING | 最初の引数として誤ったキーワード値, または認識されないデータ・タイプが渡されていた |
| XTPU$_NOBREAKPOINT | WARNING | 文字列定数が使用できるのはブレーク・ポイントの後のみである |
| XTPU$_NOCRRENTBUF | WARNING | 現在のバッファが定義されていない |
| XTPU$_NOKEYMAP | WARNING | キー・マップが定義されていない |
| XTPU$_NOKEYMAPLIST | WARNING | キー・マップ・リストが定義されていない |
| XTPU$_NONAMES | WARNING | 要求された名前にマッチするものがない |
| XTPU$_INVPARAM | ERROR | 引数のデータ・タイプに誤りがある |
| XTPU$_NEEDTOASSIGN | ERROR | GET_INFO組込みプロシージャは代入文の右辺でのみ使用できる |
| XTPU$_TOOFEW | ERROR | 引数の数が少なすぎる |
| XTPU$_TOOMANY | ERROR | 引数の数が多すぎる |
| XTPU$_UNKEYWORD | ERROR | 引数に誤ったキーワードが使われた |
1. my_dictionary := GET_INFO (SYSTEM, "kanji_dictionary_file");この代入ステートメントは, 現在使用中の個人辞書の名前をmy_ dictionaryという変数に代入します。
2. current_codeset := GET_INFO (CURRENT_BUFFER, "codeset");この代入ステートメントは, 現在のバッファのコードセットをcurrent_ codesetという変数に代入します。
keyword2 := KEY_NAME ({integer|key-name|string} [,SHIFT_KEY][,{FUNCTION|KEYPAD}])
キーを示すキーワードの整数表現,DEC XTPUがISO Latin1文字セットに解釈する0から255までの整数。
キーに対するDEC XTPUキー名を示すキーワード。
メイン・キーボードのキーの値を示す文字列。
戻されるキーワードの前に1つまたは複数のシフト・キーが存在することを示すパラメータ。 SHIFT_KEYはDEC XTPUが定義するSHIFTキーで,(省略時の値は[PF1]), キーボードの[Shift]キーではありません。
パラメータでファンクション・キーによって発生するコードを指定していることを示す。
パラメータでキーパッドによって発生するコードを指定していることを示す。
string パラメータに,日本語の全角文字を指定することができます。 また,日本語の全角文字もキー定義に使用することができます。
| XTPU$_BADKEY | WARNING | 指定できるキーワードはSHIFT_KEY,FUNCTION,KEYPADのみである |
| XTPU$_INCKWDCOM | WARNING | キーワードの組み合せが正しくない |
| XTPU$_MUSTBEONE | WARNING | 文字列は1文字でなければならない |
| XTPU$_NOTDEFINABLE | WARNING | キーに定義されない値が指定された |
| XTPU$_NEEDTOASSIGN | ERROR | KEY_NAMEは代入文の右辺でのみ使用できる |
| XTPU$_ARGMISMATCH | ERROR | パラメータのデータ・タイプが正しくない |
| XTPU$_TOOFEW | ERROR | パラメータの数が少なすぎる |
| XTPU$_TOOMANY | ERROR | パラメータの数が多すぎる |
1. key1 := KEY_NAME (' タ')
この代入ステートメントはキーボードの"タ"というキーに対してkey1というキー名を作成します。
2. key2 := KEY_NAME (' タ', SHIFY_KEY)
この例では,キーの組合せに対してキー名を作成するためにKEY_NAMEが使用されています。
marker := MARK (keyword)
以下のいずれかのキーワードを使用しなければなりません。
| BLINK | マーカが点滅することを指定します。 |
| BOLD | マーカがボールド体で表示されることを指定します。 |
| FREE_CURSOR | マーカがフリー・マーカ(文字に対応しないマーカ)であることを指定します。 MARK (FREE_CURSOR)が実行されたときのカーソル位置が,行頭より前, 行末より後ろ,タブの中,DEC漢字文字の第2カラム上, バッファの終端より下でないときにはフリー・マーカにはなりません。 フリー・マーカはビデオ属性を持ちません。 |
| NONE | ビデオ属性がマーカに適用されないことを指定します。 |
| REVERSE | マーカが反転表示されることを指定します。 |
| UNDERLINE | マーカにアンダーラインが引かれることを指定します。 |
マーカは文字の境界にセットされます。したがって, たとえば漢字上にカーソルがあるときに,マーカをセットしようとすると, 現在の文字位置が漢字の2カラム目にあるときでも, マーカはその文字の1カラム目にセットされます。 ただしフリー・マーカは漢字の2カラム目にセットすることができます。
| XTPU$_NOCURRENTBUF | WARNING | マーカはバッファ中にのみ設定できる |
| XTPU$_TOOFEW | ERROR | パラメータの数が少なすぎる |
| XTPU$_TOOMANY | ERROR | パラメータの数が多すぎる |
| XTPU$_NEEDTOASSIGN | ERROR | MARKは代入文の右辺でのみ使用できる |
| XTPU$_INVPARAM | ERROR | パラメータのデータ・タイプが正しくない |
| XTPU$_BADKEY | ERROR | 指定できるキーワードはNONE,BOLD,BLINK, REVERSE,UNDERLINE,FREE_CURSORのいずれかである |
| XTPU$_UNKKEYWORD | ERROR | 正しくないキーワードが指定された |
| XTPU$_INSVIRMEM | FATAL | マーカを作るのに十分なメモリがない |
integer2 := PCS_CLASS (string [,integer1])
文字が属するPCSを知りたい文字を指定します。 2文字以上の文字列を指定したときには最初の文字のみが有効です。
PCSのグループ番号を指定します。 このパラメータは将来32以上のPCSを扱うために用意されていますが, 現在はグループ番号0のみが使われますので,省略可能です。省略時の値は0です。
| クラス | ビット | 定数 |
|---|---|---|
| ASCII_CHAR | 0 | XTPU$K_ASCII_CHAR |
| DEC_SUPPLEMENTAL | 1 | XTPU$K_DEC_SUPP |
| LATIN1_SUPPLEMENTAL | 2 | XTPU$K_LATIN1_SUPP |
| JIS_ROMAN | 3 | XTPU$K_JIS_ROMAN |
| JIS_KATAKANA | 4 | XTPU$K_JIS_KATAKANA |
| KANJI_1 (JIS X0208) | 8 | XTPU$K_KANJI_1 |
| KANJI_UDC | 16 | XTPU$K_KANJI_UDC |
| XTPU$_INVPARAM | ERROR | 引数の型が正しくない |
| XTPU$_NEEDTOASSIGN | ERROR | PCS_CLASSは代入文の右辺でのみ使用できる |
| XTPU$_TOOFEW | ERROR | パラメータの数が少なすぎる |
| XTPU$_TOOMANY | ERROR | パラメータの数が多すぎる |
string := READ_CHAR
キーボードから入力される文字コードの解釈は,キーボード・コードセットの設定に従います。 詳しくはGET_INFO (SYSTEM,"keyboard_codeset")および SET (KEYBOARD_CODESET)を参照してください。
| XTPU$_NEEDTOASSIGN | ERROR | READ_CHARは代入文の右辺でのみ使用できる |
| XTPU$_NOCHARREAD | WARNING | READ_CHARが文字を読まなかった |
| XTPU$_TOOMANY | ERROR | パラメータの数が多すぎる |
keyword := READ_KEY
キーボードから入力される文字コードの解釈は,キーボード・コードセットの設定に従います。 詳しくはGET_INFO (SYSTEM,"keyboard_codeset")および SET (KEYBOARD_CODESET)を参照してください。
| XTPU$_CONTROLC | ERROR | READ_KEYの実行中に[Ctrl/C]が押された |
| XTPU$_NEEDTOASSIGN | ERROR | READ_KEYは代入文の右辺でのみ使用できる |
| XTPU$_REQUIRESTERM | ERROR | NODISPLAYモードではREAD_KEYを使用できない |
| XTPU$_TOOMANY | ERROR | パラメータの数が多すぎる |
string2 := READ_LINE [(string1 [,integer])]
入力を要求するプロンプトとして使用されるテキストを指定します。 このパラメータは省略することができます。
プロンプトに対する応答として入力されたデータから何バイトを読み込むかを指定します。 指定できる最大値は132文字です。このパラメータは省略することができます。 このパラメータが指定されなかったときには, [Return]キーまたは[Ctrl/Z]が入力されるまで, あるいは文字列の長さが132文字になるまで入力できます。
キーボードから入力される文字コードの解釈は,キーボード・コードセットの設定に従います。 詳しくはGET_INFO (SYSTEM,"keyboard_codeset")および SET (KEYBOARD_CODESET)を参照してください。
| XTPU$_INVPARAM | ERROR | パラメータのデータ・タイプが正しくない |
| XTPU$_NEEDTOASSIGN | ERROR | READ_LINEは代入文の右辺でのみ使用できる |
| XTPU$_TOOMANY | ERROR | パラメータの数が多すぎる |
SELECTから通知されるマーカは選択・レンジの最初の文字位置を示しています。 マーカに対して指定したビデオ属性は選択・レンジに含まれるすべての文字に適用されます。 選択・レンジの作成方法については,SELECT_RANGE を参照してください。
marker := SELECT (keyword)
戻されるマーカがスクリーン上でどのように表示されるかを指定します。 以下のいずれかのキーワードを使用しなければなりません。
| BLINK | マーカが点滅することを指定します |
| BOLD | マーカがボールド体で表示されることを指定します |
| NONE | ビデオ属性がマーカに適用されないことを指定します |
| REVERSE | マーカが反転表示されることを指定します |
| UNDERLINE | マーカにアンダーラインが引かれることを指定します |
SELECTが実行されたときに, 現在の編集位置が複数カラム文字の2カラム目以降にあった場合には, マーカは1カラム目にセットされます(現在の編集位置は動きません)。
| XTPU$_BADKEY | WARNING | 正しくないキーワードが指定された |
| XTPU$_NOCURRENTBUF | WARNING | 現在のバッファが設定されていない |
| XTPU$_ONESELECT | WARNING | SELECTは現在のバッファですでに実行中である |
| XTPU$_TOOFEW | ERROR | パラメータの数が少なすぎる |
| XTPU$_TOOMANY | ERROR | パラメータの数が多すぎる |
| XTPU$_NEEDTOASSIGN | ERROR | SELECTは代入文の右辺でのみ使用できる |
| XTPU$_INVPARM | ERROR | SELECTのパラメータがキーワードでない |
range := SELECT_RANGE
SELECT_RANGEを実行したときに現在の編集位置が複数カラム文字の2カラム目以降にあった場合には, 編集位置が1カラム目にあるときと同様に動作します。
| XTPU$_NOCURRENTBUF | WARNING | 現在のバッファが設定されていない |
| XTPU$_NOSELECT | WARNING | 現在のバッファでSELECTが実行されていない |
| XTPU$_SELRANGEZERO | WARNING | 選択されたレンジに文字が入っていない |
| XTPU$_NEEDTOASSIGN | ERROR | SELECT_RANGEは代入文の右辺でのみ使用できる |
| XTPU$_TOOMANY | ERROR | パラメータの数が多すぎる |
SET (keyword, parameter [])
最初のパラメータとして使用されるキーワードは,設定または変更される機能を指定します。 SET組込みプロシージャに対して以下のキーワードを指定することができます。 アスタリスク(*)がついたものはDEC XTPUで追加されたもので,後の節で説明されています。
これらの各キーワードとその後に指定されるパラメータについては, 以降のページで詳しく説明します。 キーワードはアルファベット順に説明されています。
最初のパラメータの後に指定されるパラメータの数は, どのキーワードを使用したかによって異なります。 パラメータはキーワードの説明の形式の部分に示されています。
SET (CODESET, {SYSTEM | buffer}, keyword)
システムまたはバッファのコードセットを指定するためのキーワード。
システム・コードセットを設定することを示します。
コードセットを設定するバッファを指定します。
設定するコードセットを示すキーワード。指定できるキーワードは, DEC_MCS,ISO_LATIN1,ASCII_JISKANA,DECKANJI,SDECKANJI,またはSJISです。
バッファのコードセットには2種類あり,SET (CODESET)で指定するコードセットは, READ_FILE組込みプロシージャでファイルを読み込むときに使われます。 ファイルに書き出すときに使用させれるコードセット(出力コードセット)は, SET (OUTPUT_CODESET)組込みプロシージャで設定します。
SET (KEYBOARD_CODESET), SET (MESSAGE_CODESET),SET (OUTPUT_CODESET)も参照してください。
| XTPU$_TOOFEW | ERROR | 引数の数が少なすぎる |
| XTPU$_TOOMANY | ERROR | 引数の数が多すぎる |
| XTPU$_INVPARAM | ERROR | 引数の型が正しくない |
| XTPU$_BADKEY | ERROR | 正しくないキーワードが指定された |
| XTPU$_ARGMISMATCH | ERROR | 引数の型が正しくない |
SET (FILL_NOT_BEGIN, string)
行頭禁則文字を指定するためのキーワード。
行頭禁則文字からなる文字列。
FILL,SET (FILL_NOT_END),SET (MARGIN_ALLOWANCE)も参照してください。
| XTPU$_TOOFEW | ERROR | 引数の数が少なすぎる |
| XTPU$_TOOMANY | ERROR | 引数の数が多すぎる |
| XTPU$_INVPARAM | ERROR | 引数の型が正しくない |
SET (FILL_NOT_END, string)
行末禁則文字を指定するためのキーワード。
行末禁則文字からなる文字列。
FILL,SET (FILL_NOT_BEGIN),SET (MARGIN_ALLOWANCE)も参照してください。
| XTPU$_TOOFEW | ERROR | 引数の数が少なすぎる |
| XTPU$_TOOMANY | ERROR | 引数の数が多すぎる |
| XTPU$_INVPARAM | ERROR | 引数の型が正しくない |
SET (FILL_TRIM_SPACE, {ON | OFF | 1 | 0})
FILL組込みプロシージャの実行によって行末にきた空白文字を, 取り除くかどうかを制御することを示すキーワード。
FILL組込みプロシージャの実行によって行末にきた空白文字を, 取り除くことを指示します。
FILL組込みプロシージャの実行によって行末にきた空白文字を, 取り除かないことを指示します。
| XTPU$_TOOFEW | ERROR | 引数の数が少なすぎる |
| XTPU$_TOOMANY | ERROR | 引数の数が多すぎる |
| XTPU$_INVPARAM | ERROR | 引数の型が正しくない |
| XTPU$_BADKEY | WARNING | 正しくないキーワードが指定された |
| XTPU$_ONOROFF | ERROR | 第2パラメータはON,OFF,1,0のいずれかでなければならない |
SET (KEYBOARD_CODESET, keyword)
キーボードのコードセットを指定するためのキーワード。
設定するキーボード・コードセットを示すキーワード。 指定できるキーワードは,DEC_MCS,ISO_LATIN1,ASCII_JISKANA,DECKANJI, SDECKANJI,または SJIS です。
SET (CODESET),SET (MESSAGE_CODESET),SET (OUTPUT_CODESET)も参照してください。
| XTPU$_BADKEY | WARNING | 正しくないキーワードが指定された |
| XTPU$_TOOFEW | ERROR | 引数の数が少なすぎる |
| XTPU$_TOOMANY | ERROR | 引数の数が多すぎる |
| XTPU$_INVPARAM | ERROR | 引数の型が正しくない |
SET (MARGIN_ALLOWANCE, integer)
右マージンを越えて置くことができる行頭禁則文字のカラム数を指定するためのキーワード。
右マージンを越えて置くことができる行頭禁則文字のカラム数を指定する整数。
初期値は0で,行頭禁則文字は右マージンを越えて存在できません。 この場合は,行頭禁則文字が行の先頭にこないように, 行頭禁則文字でない文字を伴って次の行に移されるので, 右マージンまで埋まらない行ができることがあります。
FILL,SET (FILL_NOT_BEGIN),SET (FILL_NOT_END)も参照してください。
| XTPU$_TOOFEW | ERROR | 引数の数が少なすぎる |
| XTPU$_TOOMANY | ERROR | 引数の数が多すぎる |
| XTPU$_INVPARAM | ERROR | 引数の型が正しくない |
| XTPU$_BADVALUE | ERROR | 負の値が指定された |
SET (MESSAGE_CODESET, keyword)
メッセージのコードセットを指定するためのキーワード。
設定するメッセージ・コードセットを示すキーワード。 指定できるキーワードは,DEC_MCS,ISO_LATIN1,ASCII_JISKANA,DECKANJI, SDECKANJI,またはSJISです。
SET (CODESET),SET (KEYBOARD_CODESET),SET (OUTPUT_CODESET)も参照してください。
| XTPU$_BADKEY | WARNING | 正しくないキーワードが指定された |
| XTPU$_TOOFEW | ERROR | 引数の数が少なすぎる |
| XTPU$_TOOMANY | ERROR | 引数の数が多すぎる |
| XTPU$_INVPARAM | ERROR | 引数の型が正しくない |
SET (OUTPUT_CODESET, buffer, keyword)
バッファの出力コードセットを指定するためのキーワード。
出力コードセットを設定するバッファを指定します。
設定するコードセットを示すキーワード。指定できるキーワードは, DEC_MCS,ISO_LATIN1,ASCII_JISKANA,DECKANJI,SDECKANJI,またはSJISです。
SET (CODESET),SET (KEYBOARD_CODESET),SET (MESSAGE_CODESET)も参照してください。
| XTPU$_BADKEY | WARNING | 正しくないキーワードが指定された |
| XTPU$_TOOFEW | ERROR | 引数の数が少なすぎる |
| XTPU$_TOOMANY | ERROR | 引数の数が多すぎる |
| XTPU$_INVPARAM | ERROR | 引数の型が正しくない |
SET (VIDEO_CHARACTER_SET, keyword, {ON|OFF|1|0})
端末に表示する文字セットを設定するキーワード。
有効または無効にする文字セットを示すキーワード。 指定できるキーワードは,DEC_SUPPLEMENTAL,LATIN1_SUPPLEMENTAL,JIS_ROMAN, JIS_KATAKANA,KANJI_1,またはKANJI_UDCです。
指定した文字セットを有効にすることを指定します。
指定した文字セットを無効にすることを指定します。
しかしDEC XTPUが端末が持っている文字セットの正しい情報を持っていないと文字化けを起こしたり, 表示できるはずの文字がダイアモンド・シンボルになってしまいます。 このような場合はSET (VIDEO_CHARACTER_SET)組込みプロシージャで正しい情報をDEC XTPUに知らせることができます。
| XTPU$_BADKEY | WARNING | 間違ったキーワードが指定された |
| XTPU$_TOOFEW | ERROR | 引数の数が少なすぎる |
| XTPU$_TOOMANY | ERROR | 引数の数が多すぎる |
| XTPU$_INVPARAM | ERROR | 引数の型が正しくない |
SPLIT_LINE
現在の文字位置が2カラム文字の2カラム目にあるときにSPLIT_LINEを実行すると, 1カラム目にあるときと同様に行が分割されます。
| XTPU$_NOCURRENTBUF | WARNING | 現在のバッファが設定されていない |
| XTPU$_NOTMODIFIABLE | WARNING | 変更が禁止されているバッファの内容は変更できない |
| XTPU$_NOCACHE | ERROR | 十分なメモリがない |
| XTPU$_TOOMANY | ERROR | パラメータの数が多すぎる |
string2 := SYMBOL (string1)
特殊文字を生成するもととなる文字列。
| XTPU$_TOOFEW | ERROR | 引数の数が少なすぎる |
| XTPU$_TOOMANY | ERROR | 引数の数が多すぎる |
| XTPU$_INVPARAM | ERROR | 引数の型が正しくない |
| XTPU$_NEEDTOASSIGN | ERROR | SYMBOLは代入文の右辺でのみ使用できる |
PROCEDURE user_symbol
COPY_TEXT (SYMBOL('=/'));
ENDPROCEDURE;
{range | 0} := VERIFY_BUFFER (keyword, {FORWARD | REVERSE})
コードセットを表すキーワード。指定できるキーワードは,DEC_MCS, ISO_LATIN1,ASCII_JISKANA,DECKANJI,SDECKANJI,SJISです。
現在の変終点からバッファの終わりの方向に検索することを指定するキーワード。
現在の変終点からバッファの先頭の方向に検索することを指定するキーワード。
| XTPU$_BADKEY | WARNING | 間違ったキーワードが渡された |
| XTPU$_TOOFEW | ERROR | 引数の数が少なすぎる |
| XTPU$_TOOMANY | ERROR | 引数の数が多すぎる |
| XTPU$_INVPARAM | ERROR | 引数の型が正しくない |
| XTPU$_NEEDTOASSIGN | ERROR | VERIFY_BUFFER組込みプロシージャは代入文の右辺でのみ使用できる |