![[Compaq]](../../images/compaq.gif)
![[Go to the documentation home page]](../../images/buttons/bn_site_home.gif)
![[How to order documentation]](../../images/buttons/bn_order_docs.gif)
![[Help on this site]](../../images/buttons/bn_site_help.gif)
![[How to contact us]](../../images/buttons/bn_comments.gif)
![[OpenVMS documentation]](../../images/ovmsdoc_sec_head.gif)
| Document revision date: 30 March 2001 | |
|
|
|
|
|
|
| Previous | Contents | Index |
With indexed files, buckets (not blocks) are the units of transfer between the disk and memory. The bucket size is specified when the file is created, although the bucket size of an existing file can be changed by converting the file (see Chapter 10).
The bucket size is specified by the FDL attribute FILE BUCKET_SIZE (VMS RMS control block field FAB$B_BKS or XAB$B_BKZ), as described in Chapter 2.
When accessing indexed files, it is important to remember that the index portion of the file must be read by RMS to locate the desired record. The algorithm used by RMS places a higher priority for the higher-level buckets of the index in the buffer cache. Thus, the highest levels of the index remain in the buffer cache, while the buffers that may have contained the actual data buckets and the lower-level index buckets are reused to contain other buckets. That is, the buffers that are reused first contain either data or lower-level index buckets, which are the first to be discarded from the buffer cache.
When accessing indexed files, the number of local buffers (CONNECT MULTIBUFFER_COUNT) is specified at run time and recommended values can vary greatly for different application programs. When records are processed randomly, use as many buffers as your process working set can support to cache additional index buckets. When records are accessed sequentially, even after locating the first record randomly, use a small multibuffer count, such as the default of 2 buffers.
Many application programs access files using a mixture of completely random and completely sequential processing. For such application programs, a compromise of the above number of buffers is recommended.
When adding records to an indexed file, consider choosing the deferred-write option (FDL attribute FILE DEFERRED_WRITE; FAB$L_FOP field FAB$V_DFW). With the deferred-write option, the buffer into which the records have been moved is not written to disk until the buffer is needed for other purposes or until the file is closed. This option, however, may cause records to be lost if a system crash should occur before the records are written to disk.
To see the current process-default buffer count, use the DCL command
SHOW RMS_DEFAULT. To set the process-default buffer count, use the DCL
command SET RMS_DEFAULT/INDEXED/BUFFER_COUNT=n, where n is the
number of buffers.
7.3.6 Using Global Buffers for Shared Files
Two types of buffer caches are available using RMS: local and global. Local buffers reside within process (program) memory space and are not shared among processes, even if several processes access the same file and read the same records. Global buffers, which are designed for application programs that access the same files and perhaps the same records, do not reside in process memory space.
If several processes share a file, you should specify that the file uses global buffers. A global buffer is an I/O buffer that two or more processes can access in conjunction with file sharing. If two or more processes request the same information from a file, each process can use the global buffers instead of allocating its own process-local buffers. Figure 7-3 illustrates the use of global buffers.
Figure 7-3 Using Global Buffers for a Shared File
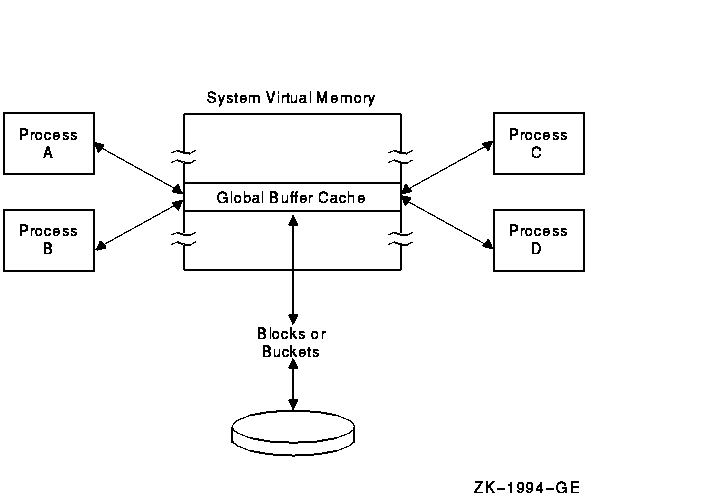
Unlike local buffers, global buffers can be accessed by multiple processes accessing the same file. When a record requested by one process is located in a global buffer, the record can be transferred directly from the global buffer to the program, eliminating an I/O read operation. Note that if the previous accessor modified the record, RMS writes the buffer to disk before returning the record to the new accessor. This ensures that the modified bucket in memory matches its counterpart on the disk.
There are two situations in which global buffers cannot be used for shared files. When a process permanent file is being accessed, RMS does not use global buffers (no error is returned). When an image is linked using the LINK option keyword IOSEGMENT=NOP0BUFS (rarely used), RMS does not use global buffers.
Even if global buffers are used, a minimal number of local buffers should be requested, because, under certain circumstances, RMS may need to use local buffers. When attempting to access a record, RMS looks first in the global buffer cache for the record before looking in the local buffers; if the record is still not found, an I/O operation occurs. When using the deferred-write option with global buffering enabled, the number of buckets that can be buffered without I/O is equal to the number of local buffers; thus, the use of more than the minimum number of local buffers should be considered.
You can specify the number of global buffers two ways: by using a preset file default or by having the first process that accesses the file specify the value at run time. To set the file default (maintained in the file header), use the DCL command SET FILE/GLOBAL_BUFFERS=n where n is the number of buffers.
To set the global buffer value at run time, the first process to connect to the file with the FILE GLOBAL_BUFFER_COUNT attribute (FAB field FAB$W_GBC) greater than 0 can set this value. The default value returned in the FAB$W_GBC field following an Open (or Create) service may be altered if unacceptable before invoking the Connect service. When a previous or subsequent application program attempts to open and connect to the file, the global buffer count determines whether or not that process uses global buffers. If the value is 0, that process uses only local buffers; if the value is greater than 0, that process uses global buffers along with other processes. Refer to the OpenVMS Record Management Services Reference Manual for additional information on the use of the FAB$W_GBC field and Connect service. An example of a routine that sets the global buffer count after opening a file is provided in Example 5-2.
To request that the global buffer cache be read-only, specify SHARING GET and SHARING MULTISTREAMING attributes (FAB$B_SHR field FAB$V_SHRGET and FAB$V_MSE).
When modifying an application program to use global buffers, consider using more global buffers and slightly larger bucket sizes if records are processed randomly. For application programs with many users, consider allocating a number of global buffers equal to the number of local buffers used previously, multiplied by number of users (if resources permit):
|
No. Global Buffers = No. Local Buffers x Average No. Users |
When using an indexed file, if the index structure is small and the number of users is many, consider allocating enough global buffers to keep the entire index structure in memory.
For shared sequential file operations, the first accessor of the file
uses the multiblock count value to establish the global buffer size for
all subsequent accessors.
7.3.6.1 Enhancing Global Buffer Performance
OpenVMS includes enhancements that improve RMS global buffer performance. These features are greater scalability, greater concurrent access to the global section, and read-mode bucket locking for shared access to global buffers.
RMS implements an algorithm for global buffer management that dramatically improves scalability. The performance associated with the previous algorithm effectively limited the maximum number of global buffers on large, shared files. With this change, you may increase the number of global buffers on these files to the full limit of 32,767 to fully exploit large memory systems.
RMS synchronizes access to the global section that is used for RMS global buffers by using inline atomic instruction sequences rather than distributive locking. This change allows more concurrent access to the section, particularly on symmetric multiprocessing machines (SMP).
Greater scalability benefits those who wish to use very large global buffer counts. Concurrent access to the global section helps any application using global buffers where contention on the global section itself is a bottleneck.
By increasing the number of global buffers on specific files, you may need to increase the size of some of the system resources. In particular, you may need to increase the sysgen parameters GBLPAGES, GBLPAGFILE, or GBLSECTIONS. In addition, you may need to increase the process working set size and the page file quota. |
Read-Mode Bucket Locking (Alpha Only)
RMS reduces locking for shared access to global buffers and improves performance with its implementation of read-mode global bucket locking, which has the following functionality:
This functionality applies to read operations (using the $GET and $FIND services) for all three file organizations: sequential, relative, and indexed. It also applies to a write operation (using the $PUT service) for the read accesses used for index buckets the first time through an index tree for the write.
You do not need to change existing applications to implement the read-only global bucket locks. However, global buffers must be set on a data file to take advantage of the enhancement. Use the following DCL command, where n is the number of buffers:
$ SET FILE/GLOBAL_BUFFER=n <filename> |
For information about specifying the number of buffers, refer to the OpenVMS DCL Dictionary. For general information about using global buffers, refer to the Guide to OpenVMS File Applications.
In a mixed cluster environment where there may be high contention for specific buckets, the Alpha nodes that are using read-mode global bucket locking may dominate accesses to write-shared files, thereby preventing timely access by other nodes.
With the /CONTENTION_POLICY=keyword qualifier to the SET RMS_DEFAULT command, you can specify the level of locking fairness at either the process or system level for environments that experience high contention conditions.
For more information about using the /CONTENTION_POLICY=keyword qualifier, refer to the OpenVMS DCL Dictionary.
This chapter describes record processing to help you use the run-time record operations described in Chapter 9. This chapter provides information about the following subjects:
Record operations are performed by OpenVMS RMS (hereafter referred to as RMS) primary or secondary services. Primary services have functional equivalents in high-level language record operations, whereas secondary services are specific to RMS functions.
Section 8.2 describes the five primary services. For a brief
description of the secondary services, refer to Section 8.3, and for
more detailed descriptions of the secondary services, refer to the
OpenVMS Record Management Services Reference Manual.
8.2 Primary Services
This section describes the five services that are functionally similar to related high-level language operations. The following table provides a brief description of each of these services and cites the similarities to high-level languages:
| Find | The Find service locates an existing record in the file. It does not return the record to your program; instead it establishes the record's location as the current-record position in the record stream. The Find service, when applied to a disk or magnetic tape file, corresponds to the FIND statement in BASIC and Fortran, the START statement in COBOL, the FIND and LOCATE statements in Pascal, and the READ statement with the SET keyword for PL/I. |
| Get | The Get service returns the selected record to your program. The Get service, when applied to a disk or magnetic tape file, corresponds to (is used by) the GET statement in BASIC; the READ statement in COBOL, Fortran, and PL/I; and the GET statement (and others) in Pascal. |
| Put | The Put service inserts a new record in the file. The Put service, when applied to a disk or magnetic tape file, corresponds to the PUT and PRINT statements in BASIC, the WRITE statement (and others) in COBOL, the WRITE statement in Fortran and PL/I, and the PUT and WRITELN statements in Pascal. |
| Update | The Update service modifies an existing disk file record. The Update service corresponds to the UPDATE statement in BASIC and Pascal and to the REWRITE statement in COBOL, Fortran, and PL/I. |
| Delete | The Delete service erases records from relative disk files and indexed disk files. The Delete service corresponds to the DELETE statement in BASIC, COBOL, Fortran, Pascal, and PL/I. |
A single statement in a high-level language may correspond to one or several RMS record-processing service calls. For example, the COBOL statement DELETE uses the Delete service during sequential record access, but it uses the Find and Delete services during random record access.
File organization in part determines the types of record operations that a program can perform. Table 8-1 shows the major record operations that RMS permits for each file organization.
| Record Operation | File Organization | ||
|---|---|---|---|
| Permitted | Sequential | Relative | Indexed |
| Get | Yes | Yes | Yes |
| Put | Yes 1 | Yes | Yes |
| Find | Yes | Yes | Yes |
| Delete | No | Yes | Yes |
| Update | Yes 2 | Yes | Yes |
The remainder of this section briefly describes the record retrieval
(Find and Get) services, the record insertion (Put) service, the record
modification (Update) service, and the record deletion (Delete)
service. Note that all references to services imply applicability to
similar functional capabilities found in high-level languages.
8.2.1 Locating and Retrieving Records
You can use the Find and Get services to locate and retrieve a record. The Find service locates a record and establishes its location as the current-record position in a record stream but does not return the record to a buffer. The Get service locates the record, establishes its location as the current-record position in the record stream, and returns it to the buffer area you specify.
If you use the Get service, you must allocate a buffer area in the data portion of your program to store the retrieved record by defining an appropriate variable or multivariable record structure in the program.
When you invoke the Get service, RMS takes control of the record buffer and may modify it. RMS returns the record size but it can guarantee record integrity only from the access point to the end of the record. |
In addition to retrieving the record, RMS returns to your program the length of the record (in control block field RAB$W_RSZ, record size) and the file address of the record (in control block field RAB$L_RBF, record buffer). If you direct RMS only to locate the record, it does not write the record into your buffer. Instead, it sets the RAB$W_RSZ and RAB$L_RBF fields to point to an internal buffer where the record is located.
When using indexed files, you may need to allocate a buffer for the desired key and to specify its length. When using high-level languages, the language's compiler may automatically handle the allocation and size specification of the record buffer and the key buffer.
In some applications, you can minimize record I/O and improve performance by using the Find service instead of the Get service. For example, a process does not have to retrieve a record when it is preparing to invoke the Update, Delete, Release, or Truncate service. If a process intends to update a record that is accessible to other processes, it should lock the record until it completes the update.
For interactive applications where the user verifies that the appropriate record is being accessed before deleting it or updating it, the program should use the Get service instead of the Find service.
In some situations, a process may use two services and two types of record access to retrieve a set of records. For example, the process might use the Find service and random access mode to locate the first record in the set and then switch to the Get service for sequentially retrieving the records in the set.
An efficient use of the Find service is to create a table of RFAs (record file addresses) to be used for rapidly accessing the records in the same file.
Record retrieval operations are typically used to repetitively read and process a set of records. As part of this type of operation, your program should check for an end-of-file condition after each Find or Get service.
For more information about the Find and Get services, refer to the
OpenVMS Record Management Services Reference Manual.
8.2.2 Inserting Records
The Put service adds a record to the file. Within the data portion of your program, you must provide a buffer for the record to be added. When calling RMS directly, the program must also supply the length of each record to be written. This is a constant value with fixed-length records but varies from record to record when adding variable-length or VFC records. When using high-level languages, however, the language's compiler may automatically specify the record buffer size or supply a means to simplify its specification.
The current-record position is especially important when adding records to a sequential file. RMS establishes the current-record position at the end of file for any record stream associated with a file opened for adding records. To add records to a relative file or to an indexed file, use random access (by key or record number), unless the program adds records sequentially by a specified ordering of primary keys or by relative record number.
The update-if option replaces an existing record using the Put service when you choose random access mode. When superseding existing records, consider using this option to add records to a relative or indexed file. A program can use the update-if option to update a record in a sequential file that is being accessed randomly by relative record number.
Be careful with automatic record locking when you use this option for a shared file because the Put service briefly releases record locks applied by the Get or Find service before the Update operation begins. This could permit another record stream to delete or update the record between the time that the program invokes the Put service and the beginning of the Update service.
Consider using the Update service instead of the Put service with the update-if option to update an existing record in a shared file.
When a file contains alternate keys with characteristics that prohibit duplicate values, the application must be prepared to handle duplicate-alternate-key errors.
For more information about the Put service, refer to the OpenVMS Record Management Services Reference Manual.
| Previous | Next | Contents | Index |
|
|
| privacy and legal statement | ||
| 4506PRO_022.HTML | ||