! Specification file for sorting negative and positive data ! in ascending order ! /FIELD=(NAME=SIGN,POS:1,SIZ:1) (1) /FIELD=(NAME=AMT,POS:2,SIZ:4) (2) /CONDITION=(NAME=CHECK1, (3) TEST=(SIGN EQ "-")) /CONDITION=(NAME=CHECK2, (4) TEST=(SIGN EQ " ")) /INCLUDE=(CONDITION=CHECK1, (5) KEY=(AMT,DESCENDING), DATA=SIGN, DATA=AMT) /INCLUDE=(CONDITION=CHECK2, (6) KEY=(AMT,ASCENDING), DATA=SIGN, DATA=AMT) |
指定ファイルを確認する際には,次の点に注意してください。
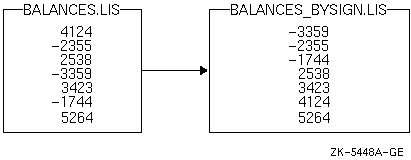
- このコマンド行は,レコードの第1バイトで始まる,長さ1バイトのフィールドを定義し,このフィールドに名前SIGNを割り当てる。
- このコマンド行は,レコードの第2バイトで始まる,長さ4バイトのフィールドを定義し,このフィールドに名前AMTを割り当てる。
- これは条件文である。 SIGN バイトに負符号 ( - ) がある場合,条件 CHECK1 を満たす。
- これは条件文である。SIGN バイトがブランクの場合,条件 CHECK2 を満たす。
- 条件CHECK1を満たす場合,レコードを降順にソートする。
- 条件CHECK2を満たす場合,レコードを昇順にソートする。
図 11-8 は,上の指定ファイルの例を BALANCES.LIS という入力ファイルに使用した結果を示しています。
図 11-8 指定ファイルを使用した出力
/FIELD=(NAME=RECORD_TYPE,POS:1,SIZ:1) ! Record type, 1-byte
/FIELD=(NAME=PRICE,POS:2,SIZ:8) ! Price, both files
/FIELD=(NAME=TAXES,POS:10,SIZ:5) ! Taxes, both files
/FIELD=(NAME=STYLE_A,POS:15,SIZ:10) ! Style, format A file
/FIELD=(NAME=STYLE_B,POS:20,SIZ:10) ! Style, format B file
/FIELD=(NAME=ZIP_A,POS:25,SIZ:5) ! Zip code, format A file
/FIELD=(NAME=ZIP_B,POS:15,SIZ:5) ! Zip code, format B file
/CONDITION=(NAME=FORMAT_A, ! Condition test, format A
TEST=(RECORD_TYPE EQ "A"))
/CONDITION=(NAME=FORMAT_B, ! Condition test, format B
TEST=(RECORD_TYPE EQ "B"))
/INCLUDE=(CONDITION=FORMAT_A, ! Output format, type A
KEY=ZIP_A,
DATA=PRICE,
DATA=TAXES,
DATA=STYLE_A,
DATA=ZIP_A)
/INCLUDE=(CONDITION=FORMAT_B, ! Output format, type B
KEY=ZIP_B,
DATA=PRICE,
DATA=TAXES,
DATA=STYLE_B,
DATA=ZIP_B)
|
この例では,不動産代理店の2つの支社から送られた2つの入力ファイルが,指定ファイルの指示に従ってソートされます。 1つ目のファイルのレコードは,最初の位置にAがついており,次の形式になっています。
|A|PRICE|TAXES|STYLE|ZIP|
1 2 10 15 25
|
2つ目のファイルのレコードは,最初の位置にBがつき, styleフィールドとzip codeフィールドが,次のように逆になっています。
|B|PRICE|TAXES|ZIP|STYLE|
1 2 10 15 20
|
これらの2つのファイルを,レコードAの形式のzip codeフィールドでソートするとき,最初に両方のレコードのフィールドを,/FIELD修飾子で定義します。その後,/CONDITION修飾子で, 2つのタイプのレコードを区別するためのテストを指定します。最後に/INCLUDE修飾子を指定して,タイプBのレコード形式をタイプAのレコード形式に変更して出力します。
/INCLUDE修飾子でキー・フィールドまたはデータ・フィールドのいずれかを指定する場合, /INCLUDE修飾子のSort操作で明示的にすべてのキー・フィールドとデータ・フィールドを指定する必要があります。
また,タイプAでもタイプBでもないレコードは,ソート時に排除されます。
/COLLATING_SEQUENCE=(SEQUENCE=
("AN","EB","AR","PR","AY","UN","UL",
"UG","EP","CT","OV","EC","0"-"9"),
MODIFICATION=("'"="19"),
FOLD)
|
この/COLLATING_SEQUENCE修飾子では,ユーザ定義順序を指定します。この指定により,それぞれの月に,日付順の固有の値が定義されます。たとえば,SEMINAR.DATというファイルを日付順に並べたい場合, SEMINAR.DATファイルは次のようになっています。
16 NOV 1983 Communication Skills
05 APR 1984 Coping with Alcoholism
11 Jan '84 How to Be Assertive
12 OCT 1983 Improving Productivity
15 MAR 1984 Living with Your Teenager
08 FEB 1984 Single Parenting
07 Dec '83 Stress --- Causes and Cures
14 SEP 1983 Time Management
|
一次キーがyearフィールドで,二次キーがmonthフィールドです。 monthフィールドは数値ではありませんが,日付順に並べたいため,独自の照合順序を定義する必要があります。この場合,それぞれの月に固有のキー値を指定して,それぞれの月の2番目と3番目の文字を(日付順に)ソートすることにより,これを行います。
MODIFICATIONオプションでは,アポストロフィ(')が19と同等になるよう指定していますが,これによって,'83と1984が比較できるようになります。またFOLDオプションは,大文字と小文字が同等に扱われるよう指定します。
このSort操作の出力は,次のようになります。
14 SEP 1983 Time Management
12 OCT 1983 Improving Productivity
16 NOV 1983 Communication Skills
07 Dec '83 Stress --- Causes and Cures
11 Jan '84 How to Be Assertive
08 FEB 1984 Single Parenting
15 MAR 1984 Living with Your Teenager
05 APR 1984 Coping with Alcoholism
|
ユーザ定義照合順序の他の例については,
第 11.3 節 を参照してください。
/FIELD=(NAME=AGENT,POSITION:20,SIZE:15)
/CONDITION=(NAME=AGENCY,
TEST=(AGENT EQ "Real-T Trust"
OR
AGENT EQ "Realty Trust"))
/DATA=(IF AGENCY THEN "Realty Trust" ELSE AGENT)
|
この例では,2つの不動産ファイルをソートします。 1つのファイルは,ある代理店がReal-T Trustと呼ぶもので,もう1つのファイルはRealty Trustと呼ばれます。 /CONDITION修飾子と/DATA修飾子により, Realty Trustのソート出力ファイルにAGENTフィールドがリストされることになります。
/FIELD=(NAME=ZIP,POSITION:60,SIZE:6)
/CONDITION=(NAME=LOCATION,
TEST=(ZIP EQ "01863"))
/KEY=(IF LOCATION THEN 1
ELSE 2)
|
この例では,郵便番号01863を持つすべてのレコードがソート出力ファイルの最初にリストされます。条件テストは,/FIELD修飾子で定義されているようにZIPフィールドで行われます。条件名はLOCATIONになっています。 /KEY修飾子にある値1と2は,条件を満たすレコードと条件を満たさないレコードの相対順序を表すものです。
/FIELD=(NAME=ZIP,POSITION:60,SIZE:6)
/CONDITION=(NAME=LOCATION,
TEST=(ZIP EQ "01863"))
/DATA=(IF LOCATION THEN "NORTH CHELMSFORD"
ELSE "Outside district")
|
この例では,/CONDITION修飾子により,郵便番号01863についてテストが行われます。 /DATA修飾子は,テスト結果に従って, townフィールドの名前が出力レコードに追加されるよう指定します。
/FIELD=(NAME=FFLOAT,POS:1,SIZ:0,F_FLOATING) /CONDITION=(NAME=CFFLOAT,TEST=(FFLOAT GE 100)) /OMIT=(CONDITION=CFFLOAT) |
この例では,/FIELD修飾子でフィールドFFLOATがF_FLOATINGと定義されているため,数値100がF_FLOATINGデータ型とみなされます。
/FIELD=(NAME=AGENT,POSITION:1,SIZE:5) /FIELD=(NAME=ZIP,POSITION:6,SIZE:3) /FIELD=(NAME=STYLE,POSITION:10,SIZE:5) /FIELD=(NAME=CONDITION,POSITION:16,SIZE:9) /FIELD=(NAME=PRICE,POSITION:26,SIZE:5) /FIELD=(NAME=TAXES,POSITION:32,SIZE:5) /DATA=PRICE /DATA=" " /DATA=TAXES /DATA=" " /DATA=STYLE /DATA=" " /DATA=ZIP /DATA=" " /DATA=AGENT |
この/FIELD修飾子は,次の形式を持つ入力ファイルのレコードのフィールドを定義します。
AGENT ZIP STYLE CONDITION PRICE TAXES |
/DATA修飾子では,/FIELD修飾子で定義されているフィールド名を使用しますが,レコードを再フォーマットして,次の形式の出力レコードを作成します。
PRICE TAXES STYLE ZIP AGENT |