| 前へ | 次へ | 目次 | 索引 |
この組込みプロシージャは,指定されたキーワードに従って,指定されたバッファ,レンジ,または文字列中のテキストの,大文字/小文字変換,ひらがな/カタカナ/半角カナ変換,全角Latin文字/半角Latin文字変換,および ASCIIからひらがなへの変換を実行します。CHANGE_CASEは変換された文字列を含むバッファ,レンジ,または文字列を戻すこともできます。
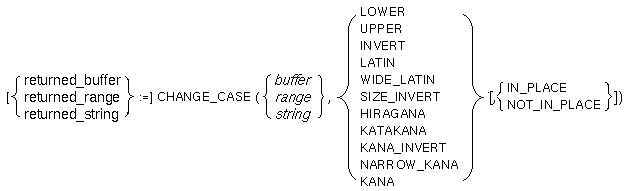
buffer
変更したい文字列を含むバッファ。第1パラメータにバッファを指定したときには,キーワード NOT_IN_PLACE は使えません。range
変更したい文字列を含むレンジ。第1パラメータにレンジを指定したときには,キーワード NOT_IN_PLACE は使えません。string
変換したい文字列。第3パラメータに IN_PLACE を指定したときには,第1パラメータに指定された文字列を変更します。文字列定数に対しては何も行いません。LOWER
指定した文字列のアルファベット(全角,半角)は小文字に変換されます。UPPER
指定した文字列のアルファベット(全角,半角)は大文字に変換されます。INVERT
指定した文字列のアルファベット(全角,半角)が大文字の場合には小文字に変換され,小文字の場合には大文字に変換されます。LATIN
指定した文字列の全角のLatin文字は半角のLatin文字に変換されます。WIDE_LATIN
指定した文字列の半角のLatin文字は全角のLatin文字に変換されます。SIZE_INVERT
指定した文字列の半角のLatin文字は全角に,全角のLatin文字は半角に変換されます。HIRAGANA
指定した文字列のカタカナ(全角)および半角カナはひらがなに変換されます。KATAKANA
指定した文字列のひらがなおよび半角カナはカタカナ(全角)に変換されます。KANA_INVERT
指定した文字列のひらがなはカタカナ(全角)に,カタカナ(全角)はひらがなに変換されます。NARROW_KANA
指定した文字列のひらがなおよびカタカナ(全角)は半角カナに変換されます。KANA
指定した文字列のアルファベット(半角,全角)はローマ字として扱われ,ひらがなに変換されます。また,文字列中のカタカナおよび半角カナはひらがなに変換されます。
returned_buffer 第1パラメータにバッファを指定したときに,変更されたテキストが含んだバッファが戻されるバッファ型の変数。変数 "returned_buffer" は第1パラメータで指定されたバッファと同じバッファを示します。 returned_range 第1パラメータにレンジを指定したときに,変更されたテキストを含んだレンジが戻されるレンジ型の変数。変数 "returned_range" は第1パラメータで指定されたレンジと同じレンジを示します。 returned_string 第1パラメータに文字列を指定したときに,変更されたテキストを含む文字列が戻される文字列型の変数。IN_PLACE を指定したときにも,文字列は戻されます。
表 4-1 は CHANGE_CASE の各キーワードとその変換項目です。
| キーワード | ||||||||
|---|---|---|---|---|---|---|---|---|
| 文字列 | LATIN | WIDE_ LATIN |
KANA | HIRA GANA |
KATA KANA |
KANA_ INVERT |
NARROW_ KANA | SIZE_ INVERT |
| 半角 | none | 全角 | ひら | none | none | none | none | 全角 |
| 全角 | 半角 | none | ひら | none | none | none | none | 半角 |
| ひらがな | none | none | none | none | カタ | カタ | 半カ | none |
| カタカナ | none | none | ひら | ひら | none | ひら | 半カ | none |
| 半角カナ | none | none | ひら | ひら | カタ | none | none | none |
none= 変換されない
ひら = ひらがな
カタ = カタカナ
半カ = 半角カナ
XTPU$_BADKEY WARNING 間違ったキーワードが指定された XTPU$_NOTMODIFIABLE WARNING 変更できないバッファの中のテキストを変更することはできない XTPU$_ARGMISMATCH ERROR 引数の型が正しくない XTPU$_CONTROLC ERROR CHANGE_CASE の実行中に [Ctrl/C] が押された XTPU$_INVPARAM ERROR パラメータのデータ・タイプが間違っている XTPU$_TOOFEW ERROR パラメータの数が少なすぎる XTPU$_TOOMANY ERROR パラメータの数が多すぎる
この組込みプロシージャは,指定されたキーワードに従って,指定されたバッファまたはレンジ中のテキストのコードセットを変換します。
[{returned_buffer |returned_range} :=] CHANGE_CODE ({buffer | range }, keyword1, keyword2)
buffer
変更したい文字列を含むバッファ。range
変更したい文字列を含むレンジ。keyword1
変換前のコードセットを示すキーワード。有効なキーワードは,DEC_MCS, ISO_LATIN1,ASCII_JISKANA,DECKANJI,DECKANJI2000, SDECKANJI,および SJISです。keyword2
変換後のコードセットを示すキーワード。有効なキーワードは,DEC_MCS, ISO_LATIN1,ASCII_JISKANA,DECKANJI,DECKANJI2000, SDECKANJI,および SJISです。
returned_buffer 第1パラメータにバッファを指定したときに,変更されたテキストが含んだバッファが戻されるバッファ型の変数。変数 "returned_buffer" は第1パラメータで指定されたバッファと同じバッファを示します。 returned_range 第1パラメータにレンジを指定したときに,変更されたテキストを含んだレンジが戻されるレンジ型の変数。変数 "returned_range" は第1パラメータで指定されたレンジと同じレンジを示します。
この組込みプロシージャは,あるコードセットを指定してファイルから読み込んだバッファの内容のすべて,または一部を別のコードセットと解釈し直す場合に使用されます。たとえば,DEC漢字コードセットと思って読み込んだファイルが,実際は ISO Latin1 コードセットで書かれていた場合,この組込みプロシージャを使用すれば,もう一度 ISO Latin1 コードセットを指定してファイルから読み直すことなしに,バッファ中のコードセットの解釈のみを ISO Latin1 コードセットに変えることができます。これによって正しい文字が画面に表示されることになります。
XTPU$_BADKEY WARNING 間違ったキーワードが指定された XTPU$_NOTMODIFIABLE WARNING 変更できないバッファの中のテキストを変更することはできない XTPU$_CONTROLC ERROR CHANGE_CODE の実行中に [Ctrl/C] が押された XTPU$_INVPARAM ERROR パラメータのデータ・タイプが間違っている XTPU$_TOOFEW ERROR パラメータの数が少なすぎる XTPU$_TOOMANY ERROR パラメータの数が多すぎる
この組込みプロシージャは,UCS-2 (Universal Character Set (ISO 10646) の 2オクテット表現,いわゆるUnicode) と文字との相互変換を行います。またキーに対応する文字を得るためにも使用されます。
{integer3|string2} := CODE ({integer1|keyword|string1} [,integer2])
integer1
UCS-2での文字の10進数表現。0から65535までの値が有効です。それ以外の数字を渡したときの動作は定義されていません。keyword
対応する文字が必要なキーの名前。プリント可能な文字に対応しないキーのキー名を指定した場合には,CODEはUCS-2 の値が 0 である文字を戻します。string1
対応する UCS-2 の値が必要な文字。1文字より長い文字列を指定した場合には, CODE は最初の文字の値を戻します。integer2
文字のカラム幅を示す整数。このパラメータは第1パラメータに整数を指定したときのみ指定できます。省略時の値は1です。漢字など2カラム文字の UCS-2 コードから文字列への変換を行うときは,このパラメータに2を指定しなければなりません。
第1パラメータに整数が与えられたときには,このプロシージャは第2パラメータに指定された数字に従って,1カラムあるいは2カラムの文字を通知します。第1パラメータの数字と文字の対応は,UCS-2の規定によって決められています。変換されたコードに対応する文字が表示できるかどうかはチェックされません。文字列パラメータが与えられたときには,このプロシージャは最初の文字に対応する UCS-2コードを通知します。
XTPU$_NULISTRING WARNING 長さ0の文字列が渡された XTPU$_ARGMISMATCH ERROR 引数のデータ・タイプが正しくない XTPU$_NEEDTOASSIGN ERROR CODE は代入文の右辺でのみ使用できる XTPU$_TOOFEW ERROR 引数の数が少なすぎる XTPU$_TOOMANY ERROR 引数の数が多すぎる
この組込みプロシージャは,文字列またはレンジに含まれる文字の,画面上のカラム数を示す整数を通知します。
integer := COLUMN_LENGTH ({buffer | range | string})
buffer
カラム長を知りたいバッファの名前。バッファを指定した場合,行の終端はカラム数としてカウントされないので注意してください。range
カラム長を知りたいレンジの名前。レンジを指定した場合,行の終端はカラム数としてカウントされないので注意してください。string
カラム長を知りたい文字列。
バッファ,レンジ,あるいは文字列の中にTAB文字が含まれていたときは,TAB文字のカラム数は表示されているカラム数に関わらず1カラムとして計算されます。
XTPU$_ARGMISMATCH ERROR COLUMN_LENGTH のパラメータは,バッファ,レンジ,文字列のいずれかでなければならない XTPU$_CONTROLC ERROR COLUMN_LENGTH の実行中に [Ctrl/C] が押された XTPU$_NEEDTOASSIGN ERROR COLUMN_LENGTH は代入文の右辺でのみ使用できる XTPU$_TOOFEW ERROR パラメータの数が少なすぎる XTPU$_TOOMANY ERROR パラメータの数が多すぎる
この組込みプロシージャは,日本語 Compaq OpenVMS かな漢字変換ライブラリを使用して,ひらがなまたはカタカナの文字列を漢字に,また,ローマ字をひらがな/カタカナの表示に変換します。
[{strint2|integer2} :=] CONVERT_KANA (keyword [,{string1 | integer1}])
keyword
変換に関する各指示を指定するキーワードで,下記の中から1つを指定します。指定するキーワードによって,その他のパラメータや戻り値のデータ・タイプが異なります。
START_CONVERSION 新しい変換を開始し,変換文字列を返します FORWARD 現在の文節の次候補を含む変換文字列を返します REVERSE 現在の文節の前候補を含む変換文字列を返します NONE 現時点での変換文字列を返します END_CONVERSION 漢字辞書を更新します HIRAGANA 現在の文節をひらがなに変換し,変換文字列を返します KATAKANA 現在の文節をカタカナ(全角)に変換し,変換文字列を返します NARROW_KANA 現在の文節を半角カナに変換し,変換文字列を返します ROMAN 現在の文節を全角英数字に変換し,変換文字列を返します SHRINK 現在の文節の長さを縮小し,変換文字列を返します EXPAND 現在の文節の長さを拡大し,変換文字列を返します CLAUSE_OFFSET 現在の文節の漢字列中の文字オフセットを返します CLAUSE_LENGTH 現在の文節の文字長を返します PHONETIC_OFFSET 現在の文節の読み文字列中の文字オフセットを返します PHONETIC_LENGTH 現在の文節の読みの長さを返します CLAUSE_NEXT 次の文節に移動します CLAUSE_PREVIOUS 前の文節に移動します CLAUSE_NUMBER 現在の文節番号を設定します MAX_CLAUSE_NUMBER 現在の変換文字列の文節数を返します
string1
新しい変換を開始するときの読み文字列。かな漢字変換は全角かなの部分を対象とします。キーワードが START_CONVERSION の場合にのみ必要で,それ以外の場合に指定してはいけません。integer1
現在の文節を指定した番号の文節に設定します。キーワードが CLAUSE_NUMBER の場合のみに有効で,それ以外の場合に指定してはいけません。キーワードが CLAUSE_OFFSET の場合,現在の文節の変換文字列中での文字オフセットの値が整数値で返されます。CLAUSE_LENGTH の場合,現在の文節の変換後文字列に占める文字長が整数値で返されます。
キーワードが CLAUSE_OFFSET,CLAUSE_LENGTH の場合,変換された文字列を返します。この文字列は,現在の文節に対応する文字列ではなく,string1 で指定した読み文字列全体に対する変換文字列です。ただし,FORWARD,REVERSE, HIRAGANA などの変換操作の対象となるのは,文字列全体ではなく,現在の文節に対応する文字列です。
学習機能かなを漢字に変換する場合,いくつかの候補文字(同音異字語)が存在することがあります。このプロシージャは,START_CONVERSION のキーワードを指定すると辞書の第1候補を返し,FORWARD,REVERSE を指定するとそれぞれ次候補,前候補を返します。また,END_CONVERSION を指定するとその時点での候補の,次に同じ単語の変換(START_CONVERSION)を開始する時の優先順位が上がるので,よく使われる単語は再変換の回数が少なくてすむようになります。
変換機能
ASCII(半角) / ROMAN(全角)からひらがな,カタカナ,ローマ字へ,あるいはひらがな,カタカナから漢字への変換が可能です。
START_CONVERSION string1 で指定された読みの変換を開始します。このとき, string1 に対する文法解析を行い,変換文字列は1またはそれ以上の文節に分けられます。このとき,現在の文節は1番目の文節となります。 FORWARD 現在の文節の自立語の次候補を求め,新しい変換文字列を返します。 REVERSE 現在の文節の自立語の前候補を求め,新しい変換文字列を返します。 NONE 現時点での変換文字列をそのまま返します。 END_CONVERSION 変換文脈を終了し,変換文字列を確定するとともに,個人辞書の学習を行います。 HIRAGANA 現在の文節をひらがなに変換し,新しい変換文字列を返します。 ASCII,ROMAN,ひらがなおよびカタカナからなる部分が変換対象となります。 KATAKANA 現在の文節をカタカナ(全角)に変換し,新しい変換文字列を返します。1 回目に呼ばれた時は文節の自立語のみをカタカナに変換し,2 回目に呼ばれた時は文節全体をカタカナに変換します。START の時 string1 にはひらがなで渡されていなければなりません。 NARROW_KANA 現在の文節を半角カナに変換し,新しい変換文字列を返します。1 回目に呼ばれた時は文節の自立語のみを半角カナに変換し,2 回目に呼ばれた時は文節全体を半角カナに変換します。START の時 string1 にはひらがなで渡されていなければなりません。 ROMAN 現在の文節を全角英数字に変換し,新しい変換文字列を返します。ASCII からなる部分のみが変換対象となります。 SHRINK 現在の文節の長さを1文字分縮小し,文法解析を再び行って新しい変換文字列を返します。文法解析の結果,文節の長さが1以上縮小されることもあります。 EXPAND 現在の文節の長さを拡大し,文法解析をやりなおして新しい変換文字列を返します。
一般的に,文節の縮小/拡大を実行すると,現在の文節以降の文字列が変化し,それに伴って文節数も変化する可能性が高いので注意してください。
CLAUSE_OFFSET 現在の文節が,変換文字列の中のどの位置から始まるかを文字オフセットとして返します。文節移動を行った結果として値が変化します。 CLAUSE_LENGTH 現在の文節の長さを返します。変換操作を行った後は値が変化する可能性があります。 PHONETIC_OFFSET 現在の文節が,読み文字列の中のどの位置から始まるかを文字オフセットとして返します。文節移動を行った結果として値が変化します。 PHONETIC_LENGTH 現在の文節の読み文字列の長さを返します。変換操作を行った後は値が変化する可能性があります。 CLAUSE_NEXT 変換対象を次の文節に移動します。この結果,FORWARD, REVERSE などの対象となる部分が次の文節に移動します。 CLAUSE_PREVIOUS 変換対象を前の文節に移動します。現在の文節が先頭の文節である場合,最後の文節に移動します。この結果,FORWARD,REVERSE などの対象となる部分が次の文節に移動します。 CLAUSE_NUMBER パラメータ integer1 で指定した文節を現在の文節とします。 integer1 を指定しなかったときは,現在の文節の文節番号を返します。 MAX_CLAUSE_NUMBER 現在の変換文字列の文節数を返します。
XTPU$_ROUND INFORMATION FORWARD による次候補が一巡して最初の単語に戻った XTPU$_NEEDTOASSIGN ERROR 返される値を代入する変数が必要である XTPU$_NODIC WARNING この編集セッションでは辞書を使用していない XTPU$_BADVALUE ERROR 指定した整数値が有効な範囲内にない XTPU$_CNVERR ERROR かな漢字変換ルーチンの内部エラーが発生した XTPU$_DICUPDERR ERROR 個人辞書の更新時にエラーが発生した XTPU$_INVPARAM ERROR 引数の型が正しくない XTPU$_NOCLA ERROR 変換対象となる文節が指定されていない,変換を開始していない XTPU$_NODICENT WARNING 文節の縮小あるいは拡大ができない。単語が辞書にない(変換不可能) XTPU$_STRTOOLONG ERROR 入力文字数が 253 文字を越えた XTPU$_TOOFEW ERROR パラメータの数が少なすぎる XTPU$_TOOMANY ERROR パラメータの数が多すぎる XTPU$_TRUNCATE WARNING 変換文字列が長すぎるため,切り捨てが行われた
| 前へ | 次へ | 目次 | 索引 |