| Previous | Contents | Index |
Some of your applications may rely on batch processing for periodic activity. Application facilities can be created with batch processing. (The process for creating batch jobs is operating-system specific, and is thus outside the scope of this document.) Be careful in your design when using batch transactions. For example, accepting data in batch from legacy systems can have an impact on application results or performance. If such batch transactions update the same database as online transactions, major database inconsistencies or long transaction processing delays can occur.
An example of a typical failure scenario follows. The basic configuration setup is RTR with a database manager such as Sybase, that does not take advantage of Memory Channel in the Tru64 UNIX TruCluster. There are four data servers, A and B at Site 1, and C and D at Site 2, with just two partitions, 1 and 2, as shown in Figure 2-10. The database is shadowed.
| Site 1: | A runs Primary Partition P1 |
| B runs Primary Partition P2 and is a standby to A for P1 | |
| Site 2: | C runs Shadow Partition S1 |
| D runs Shadow Partition S2 |
Figure 2-10 Recovery after a Failure
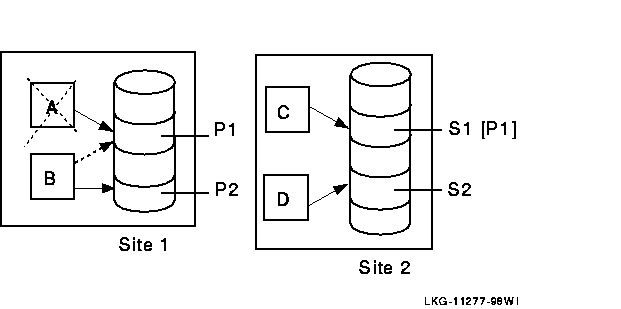
The goal for this environment is to be able to survive a )double hit,) without any loss of performance. While A is down, there is a window during which there is a single point of failure in the system. To meet this need, a standby server can be launched on machine B as a new P1, and the transactions being journaled in [P1] on C can be played across to Site 1. This can be done without any downtime, and P1 on C can continue to accept new transactions. When the playing across is finished, recovery is complete because all new transactions will be sent to both [P1] on C and P1 on B.
In more detail, the following sequence of events occurs:
The fact that node A is not accessible does not prevent B from being able to shadow P1 on node C. In this configuration, the absence of node A is unlikely to cause a quorum outage.
The RTR journal on each node must be accessible to be used to replay transactions. When setting up your system, consider both journal sizing and how to deal with replay anomalies.
To size a journal, use the following rough estimates as guidelines:
Use of large transactions generally causes poor performance, not only for initial processing and recording in the database, but also during recovery. Large transactions fill up the RTR journals more quickly than small ones.
You can use the RTR_STS_REPLYDIFF status message to determine if a transaction has been recorded differently during replay. For details on this and other status messages, see the RTR C++ Foundation Classes manual or the RTR C Application Programmer's Reference Manual.
You should also consider how the application is to handle secondary or shadow server errors and aborts, and write your application accordingly.
In designing for performance, take the following into account:
An important part of your application design will concern performance considerations: how will your application perform when it is running with RTR on your systems and network? Providing a methodology for evaluating the performance of your network and systems is beyond the scope of this document. However, to assist your understanding of the impact of running RTR on your systems and network, this section provides information on two major performance parameters:
This information is roughly scalable to other CPU s and networks. The material is based on empirical tests run on a relatively busy Ethernet network operating at 700 to 800 Kbps (kilobytes per second). This baseline for the network was based on FTP tests (doing file transfer using a File Transfer Protocol tool) because in a given configuration, network bandwidth is often a limiting factor in performance. For a typical CPU (for example, a Compaq AlphaServer 4100 5/466 4 MB) opening 80 to 100 channels with a small (100 byte) message size, a TPS (transactions per second) rate of 1400 to 1600 is usual.
Tests were performed using simple application programs (TPSREQ - client and TPSSRV - server) that use RTR Version 3 C API application programming interface calls to generate and accept transactions. (TPSREQ and TPSSRV are supplied on the RTR software kit.) The transactions consisted of a single message from client to server. The tests were conducted on OpenVMS Version 7.1 running on AlphaServer 4100 5/466 4 MB machines. Two hardware configurations were used:
In each configuration, transactions per second (TPS) and CPU-load (CPU%) consumed created by the application (app-cpu) and the RTR ACP process (acp-cpu) were measured as a function of the:
The transactions used in these tests were regular read/write transactions; there was no use of optimizations such as READONLY or ACCEPT_FORGET. The results for a single node with an incrementing number of channels are shown in Figure 2-11.
Figure 2-11 Single-Node TPS and CPU Load by Number of Channels
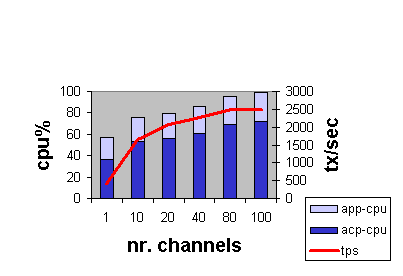
This test using 100-byte messages suggests the following:
The results for a single node with a changing message size are shown in Figure 2-12.
Figure 2-12 Single-Node TPS and CPU Load by Message Size

This test using 80 client and server channels suggests that:
The results for the two-node configuration are shown in Figure 2-13.
Figure 2-13 Two-Node TPS and CPU Load by Number of Channels
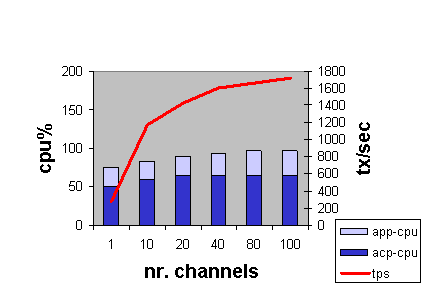
This two-node test using 100-byte messages provides CPU usage with totals for frontend and backend combined (hence a maximum of 200 percent). This test suggests that the constraint in this case appears to be network bandwidth. The TPS rate flattens out at a network traffic level consistent with that measured on the same LAN by other independent tests (for example, using FTP to transfer data across the same network links).
Determining the factors that limit performance in a particular configuration can be complex. While the previous performance data can be used as a rough guide to what can be achieved in particular configurations, they should be applied with caution. Performance will certainly vary depending on the capabilities of the hardware, operating system, and RTR version in use, as well as the work performed by the user application (the above tests employ a dummy application which does no real end-user work.)
In general, performance in a particular case is constrained by contention for a required resource. Typical resource constraints are:
Additionally, achieving a high TPS rate can be limited by:
For suggestions on examining your RTR environment for performance, see Appendix F in this document, Evaluating Application Resource Requirements.
Use concurrent servers in database applications to optimize performance and continue processing when a concurrent server fails.
When programming for concurrency, you must ensure that the multiple threads are properly synchronized so that the program is thread-safe and provides a useful degree of concurrency without ever deadlocking. Always check to ensure that interfaces are thread-safe. If it is not explicitly stated that a method is thread- safe, you should assume that the routine or method is not thread-safe. For example, to send RTR messages in a different thread, make sure that the methods for sending to server, replying to client and broadcasting events are safe. You can use these methods provided that the:
Partitioning data enables the application to balance traffic to different parts of the database on different disk drives. This achieves parallelism and provides better throughput than using a single partition. Using partitions may also enable your application to survive single-drive failure in a multi-drive environment more gracefully. Transactions for the failed drive are logged by RTR while other drives continue to record data.
To achieve performance goals, you should establish facilities spread across the nodes in your physical configuration using the most powerful nodes for your backends that will have the most traffic.
In some applications with several different types of transactions, you may need to ensure that certain transactions go only to certain nodes. For example, a common type of transaction is for a client application to receive a stock sale transaction, which then proceeds through the router to the current server application. The server may then respond with a broadcast transaction to only certain client applications. This exchange of messages between frontends and backends and back again can be dictated by your facility definition of frontends, routers, and backends.
Placement of routers can have a significant effect on your system performance. With connectivity over a wide-area network possible, do not place your routers far from your backends, if possible, and make the links between your routers and backends as high speed as possible. However, recognize that site failover may send transactions across slower-speed links. For example, Figure 2-14 shows high-speed links to local backends, but lower-speed links that will come into use for failover.
Figure 2-14 Two-Site Configuration
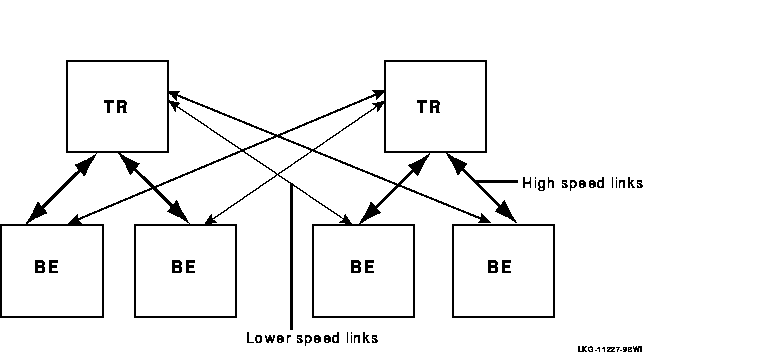
Additionally, placing routers on separate nodes from backends provides better failover capabilities than placing them on the same node as the backend.
In some configurations, you may decide to use a dual-rail or multihome setup for a firewall or to improve network-related performance. (See Appendix G for information on this setup.)
When a server or client application sends out a broadcast message, the message passes through the router and is sent to the client or server application as appropriate. A client application sending a broadcast message to a small number of server applications will probably have little impact on performance, but a server application sending a broadcast message to many, potentially hundreds of clients, can have a significant impact. Therefore, consider the impact of frequent use of large messages broadcast to many destinations. If your application requires use of frequent broadcasts, place them in messages as small as possible. Broadcasts could be used, for example, to inform all clients of a change in the database that affects all clients.
Figure 2-15 illustrates message fan-out from client to server, and from server to client.
Figure 2-15 Message Fan-Out
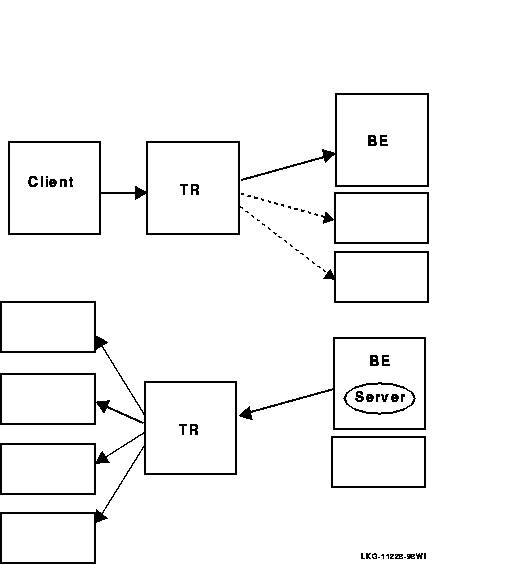
You can also improve performance by creating separate facilities for sending broadcasts.
To help ensure that broadcasts are received at every intended destination, the application might number them with an incrementing sequence number and have the receiving application check that all numbers are received. When a message is missing, have a retransmit server re-send the message.
Very large configurations with unstable or slow network links can reduce performance significantly. In addition to ensuring that your network links are the fastest you can afford and put in place, examine the volume of inter-node traffic created by other uses and applications. RTR need not be isolated from other network and application traffic, but can be slowed down by them.
Read-only transactions can significantly improve throughput because they do not need to be journaled. A read-only database can sometimes be updated only periodically, for example, once a week rather than continuously, which again can reduce application and network traffic.
When using transactional shadowing, it can enhance performance to process certain transactions as independent. When transactions are declared as independent, processing on the shadow server proceeds without enforced serialization. Your application analysis must establish what transactions can be considered independent, and you must then write your application accordingly. For example, bets placed at a racetrack for a specific race are typically independent of each other. In another example, transactions within one customer's bank account are typically independent of transactions within another customer's account. For examples of code snippets for each RTR API, see the appendices of samples in this manual.
To help make your RTR system as manageable and operable as possible, consider several tradeoffs in establishing your RTR configuration. Review these tradeoffs before creating your RTR facilities and deploying an application. Make these considerations part of your design and validation process.
For security purposes, your application transactions may need to pass through firewalls in the path from the client to the server application. RTR provides this capability within the CREATE FACILITY syntax. See the RTR System Manager's Manual, Network Transports, for specifics on how to specify a node to be used as a firewall, and how to set up your application tunnel through the firewall.
Nodes in your configuration are often specified with names and IP or DECnet addresses fielded by a name server. When the name server goes down or becomes unavailable, the name service is not available and certain requests may fail. To minimize such outages, declare the referenced node name entries in a local host names file that is available even when the name server is not. Using a host names file can also improve performance for name lookups.
Operations staff often create batch or command procedures to take snapshots of system status to assist in monitoring applications. The character cell displays (ASCII output) of RTR can provide input to such procedures. Be aware that system responses from RTR can change with each release, which can cause such command procedures to fail. If possible, plan for such changes when bringing up new versions of the product.
| Previous | Next | Contents | Index |