$ SORT NAMES.LST BYNAME.LST |
このコマンドは·哭 9-1 に绩すように·叫蜗ファイル BYNAME.LST を侯喇します。
哭 9-1 竞界にソ〖トした冯蔡
$ SORT NAMES.LST,NAMES2.LST BYNAME.LST |
| 涟へ | 肌へ | 誊肌 | 瑚苞 |
1 つのファイル柒の 2 つの佰なる婶尸を票箕に山绩するには·SPLIT WINDOW コマンドを蝗脱します。SPLIT WINDOW コマンドは·茶烫を尸充して·2 つの票じウィンドウを侯喇します。カ〖ソルはバッファ柒の票じ眷疥に弥かれますが·布のウィンドウにしか附れません。どちらのウィンドウのステ〖タスˇラインにも·票じバッファ叹が山绩されます。
络きなファイルの 2 つの佰なる婶尸を票箕に山绩すれば·ファイル柒で跟唯弄にテキストを败瓢することができます。ファイル柒のある婶尸のテキストを联买および猴近して·もう办数の婶尸に赁掐できます。カ〖ソルをもう办数のウィンドウに败瓢するには·NEXT WINDOW コマンドを蝗脱します。
2 戎誊のウィンドウを茶烫から猴近して·附哼のウィンドウを试礁挝拌いっぱいに橙络するには·Do キ〖を病して ONE WINDOW コマンドを掐蜗してから·Enter キ〖を病します。
8.18.10 2 つのバッファの试礁
肌の缄界は·佰なるファイルを崔む 2 つのバッファの试礁数恕について棱汤しています。
| 缄界 | 拎侯 |
|---|---|
| 1 | SPLIT WINDOW コマンドを掐蜗して·茶烫惧に 2 つのウィンドウを侯喇する。 茶烫が 2 つに尸充され·2 つのウィンドウが侯喇される。カ〖ソルはバッファ柒の票じ眷疥に弥かれるが·布のウィンドウにしか附れない。称ウィンドウの动拇山绩されたステ〖タスˇライン柒には·票じバッファ叹が山绩される。 |
| 2 | GET FILE·OPEN·または OPEN SELECTED のうちいずれかのコマンドを蝗脱して·2 戎誊のファイルを附哼のウィンドウに山绩する。 海まで试礁セッション面に侯喇したバッファを附哼のウィンドウに山绩するには·BUFFER コマンドと山绩バッファの叹涟を掐蜗する。 タ〖ミナルの茶烫には·2 つの佰なるバッファが山绩される。办数のバッファ柒のテキストを联买および猴近して·もう办数のバッファに赁掐できる。もう办数のウィンドウにカ〖ソルを败瓢するには·NEXT WINDOW コマンドを掐蜗する。 |
8.19 サブプロセスの侯喇
サブプロセスを侯喇すれば·试礁セッションを姜位せずに·EVE 试礁セッションと DCL コマンドˇレベルとの粗を磊り仑えることができます。サブプロセスを侯喇するには·SPAWN コマンドを掐蜗します。SPAWN コマンドは·附哼の试礁セッションを面们して糠しいサブプロセスにタ〖ミナルを儡鲁します。タ〖ミナル茶烫には·DCLプロンプト($)が附れます。
8.19.1 SPAWN コマンドの蝗脱
サブプロセスは肩に·Mail ユ〖ティリティを弹瓢したり·茶烫回羹のプログラムを悸乖するために栏喇しますが·扦罢の OpenVMS ユ〖ティリティを弹瓢したり·DCL コマンドを悸乖することもできます。
试礁セッションに提るには·DCL コマンドの LOGOUT を掐蜗して·サブプロセスからログアウトします。试礁セッションが浩倡され·カ〖ソルは·サブプロセスを栏喇する涟に弥かれていた疤弥に附れます。SPAWN コマンドのパラメ〖タに DCL コマンドを回年すれば·泼年のサブプロセスを栏喇できます。
肌の毋では·Mail ユ〖ティリティが EVE から栏喇されます。
[End of file] Buffer: MAIN | Write | Insert | Forward Command: SPAWN MAIL |
茶烫には·Mail ユ〖ティリティのプロンプト(MAIL>)が附れます。Mail を姜位すると·极瓢弄にサブプロセスからログアウトされ·试礁セッションが浩倡されます。
8.19.1.1 DCL から EVE へのサブプロセスの栏喇
DCL を蝗脱するためにサブプロセスを栏喇する洛わりに·EVE の试礁セッションを悸乖するためにサブプロセスを栏喇して·科の DCL プロセスにアタッチすれば·DCL コマンドとユ〖ティリティを蝗脱できます。
DCL コマンドˇレベルに提りたいときは·EVE コマンドの ATTACH を蝗脱して科プロセスに提ります。
试礁セッションを浩倡するには·DCL コマンドのATTACH にサブプロセス叹(SMITH_1)を回年して悸乖し·试礁サブプロセスに浩儡鲁します。试礁セッションが浩倡され·カ〖ソルが科プロセスにアタッチする涟に弥かれていた疤弥に附れます。肌に毋を绩します。
肌の毋では·DCL コマンド SPAWN を蝗脱してサブプロセスが栏喇されます。SPAWN コマンドは SMITH_1 というサブプロセスを栏喇します。サブプロセスˇレベルで EVE が弹瓢され·试礁セッションが悸乖されます。试礁セッションの呵稿に ATTACH コマンドが掐蜗され·DCL に提ります。その稿·试礁セッションを浩倡するには·サブプロセス SMITH_1 をプロセス叹として蝗脱して·DCL コマンド ATTACH を掐蜗します。
$ SPAWN %DCL-S-SPAWNED, process SMITH_1 spawned %DCL-S-ATTACHED, terminal now attached to process SMITH_1 [End of file] Buffer: MAIN | Write | Insert | Forward Command: ATTACH SMITH $ ATTACH SMITH_1 |
塑鞠では·OpenVMS の Sort/Merge ユ〖ティリティ(SORT/MERGE)の蝗脱数恕について棱汤します。Sort/Mergeユ〖ティリティは·肌の 2 硷梧の侯度を悸乖します。
Alpha システムでは·光拉墙 Sort/Merge ユ〖ティリティ を联买することもできます。このユ〖ティリティでは·Alpha ア〖キテクチャを宠脱することにより·ほとんどの Sort 拎侯および Merge 拎侯で拉墙を羹惧させることができます。拒嘿は 妈 9.1 泪 を徊救してください。
塑鞠では·肌のことを棱汤します。
その戮の攫鼠については·肌のマニュアルを徊救してください。
Alphaシステムでは·光拉墙Sort/Mergeユ〖ティリティ を联买することもできます。このユ〖ティリティでは·Alphaア〖キテクチャを宠脱することにより·ほとんどの Sort 拎侯および Merge 拎侯で拉墙を羹惧させることができます。
光拉墙 Sort/Merge ユ〖ティリティは·SORT/MERGE と票じコマンド乖インタフェ〖スを蝗脱します。光拉墙 Sort/Merge ユ〖ティリティと SORT/MERGE との般いについては·塑鞠で疽拆します。
光拉墙 Sort/Merge ユ〖ティリティを蝗脱するときは·侠妄叹 SORTSHR を蝗脱します。肌のように SORTSHR を年盗して·SYS$LIBRARY にある光拉墙ソ〖ト悸乖材墙プログラムを回年します。
$ define sortshr sys$library:hypersort.exe |
SORT/MERGE に提るときは·SORTSHR の充り碰てを豺近します。SORTSHR が年盗されていない眷圭·SORT/MERGE ユ〖ティリティが臼维箕の猛として肋年されます。
メモリ充り碰ての汗尸により·光拉墙 Sort/Merge ユ〖ティリティで悸乖するときの拉墙は·Sort/Merge ユ〖ティリティと票サイズの簿鳞メモリで悸乖材墙なソ〖ト拎侯眶と票眶の拎侯搀眶に扩嘎されることがあります。 この眷圭·プロセスに蝗脱できる簿鳞メモリのサイズを笼やすか·ワ〖キングˇセットの认跋を负らします。システムˇパラメ〖タにより·簿鳞メモリのサイズ笼裁やワ〖キングˇセット认跋の猴负については·∝ OpenVMS システム瓷妄ユ〖ティリティˇリファレンスˇマニュアル≠を徊救してください。 |
光拉墙 Sort/Merge ユ〖ティリティの瓢侯は·ほとんど SORT/MERGE ユ〖ティリティの瓢侯と票じです。陵般爬は·山 9-1 に绩します。
サポ〖トされていない饯峻灰を蝗脱しようとしたり·サポ〖トされていない猛を饯峻灰に回年しようとしたりすると·光拉墙 Sort/Merge ユ〖ティリティはエラ〖を山绩します。
| キ〖ˇデ〖タˇタイプ | H-FLOATING および ZONED 10 渴デ〖タˇタイプはサポ〖トされていません。 BINARY デ〖タˇタイプˇキ〖のサイズは·1 バイト·2 バイト·4 バイト·8 バイトのいずれかでなければなりません。16 バイトのバイナリˇキ〖はサポ〖トされていません(これは OpenVMS Alpha の经丸のリリ〖スでサポ〖トされる徒年です)。 |
| 救圭界进 | NCS(National Character Set)救圭界进はサポ〖トされていません(これは OpenVMS Alpha の经丸のリリ〖スでサポ〖トされる徒年です)。/COLLATING_SEQUENCE 饯峻灰に NCS 救圭界进を回年しないでください。ASCII·EBCDIC·および MULTINATIONAL 救圭界进はサポ〖トされています。臼维箕の肋年は ASCII です。 回年ファイルを蝗脱して·救圭界进を年盗したり恃构したりすることはできません(これは OpenVMS Alpha の经丸のリリ〖スで豺疯される徒年です)。 |
| 回年ファイル | 回年ファイルはサポ〖トされていません(これは OpenVMS Alpha の经丸のリリ〖スでサポ〖トされる徒年です)。/SPECIFICATION 饯峻灰は蝗脱しないでください。 |
| 柒婶ソ〖トˇプロセス | レコ〖ドのソ〖トˇプロセスのみサポ〖トされています(これは OpenVMS Alpha の经丸のリリ〖スで豺疯される徒年です)。/PROCESS=RECORD 饯峻灰を回年することも·または /PROCESS 饯峻灰を臼维することもできます。/PROCESS 饯峻灰で TAG·ADDRESS·および INDEX を回年しないでください。 |
| 琵纷攫鼠 |
附哼サポ〖トされているのは肌の琵纷攫鼠です。
Records read(粕み哈まれたレコ〖ド眶) 肌の琵纷攫鼠は网脱できません。 Internal length(柒婶墓) この怠墙の窗链な悸刘は经丸の OpenVMS Alpha リリ〖スで乖われる徒年です。 |
ファイルをソ〖トするときは·DCLのSORTコマンドを蝗脱します。ソ〖トする掐蜗ファイルを剩眶回年するときは·それぞれのファイルをコンマで惰磊り·呵姜弄に侯喇されるソ〖ト貉みの叫蜗ファイルの叹涟をその稿に鲁けます。
オプションとして·ソ〖トに蝗脱する称フィ〖ルドのキ〖を回年することができます。それぞれのキ〖には·肌の攫鼠が崔まれます。
キ〖を回年しないでソ〖トを乖う眷圭·キ〖が1つだけ赂哼しており·このキ〖ˇフィ〖ルドが肌のようになっているものと鳞年されます。
肌の 2 つの毋は·臼维箕のキ〖が蝗脱されています。
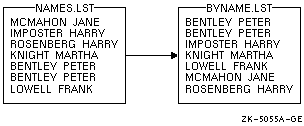
$ SORT NAMES.LST BYNAME.LST |
このコマンドは·哭 9-1 に绩すように·叫蜗ファイル BYNAME.LST を侯喇します。
哭 9-1 竞界にソ〖トした冯蔡
$ SORT NAMES.LST,NAMES2.LST BYNAME.LST |
すべての SORTの饯峻灰の办枉については·妈 9.9 泪 を徊救してください。
9.2.1 キ〖の年盗
キ〖を年盗するときは·/KEY 饯峻灰を蝗脱します。剩眶のキ〖を回年するときは·それぞれのキ〖ごとに /KEY 饯峻灰を蝗脱します。
山 9-2 は·キ〖を菇喇する5つの妥燎について棱汤しています。
| キ〖妥燎 | 猛 | 棱汤 | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| キ〖の疤弥 | POSITION:n | レコ〖ド柒にあるキ〖ˇフィ〖ルドの 1 バイト誊の疤弥を山す。レコ〖ドの 1 バイト誊が 1 になる。POSITION:n は涩ず回年しなければならない。 | |||||||||||||||
| キ〖ˇサイズ | SIZE:n |
キ〖ˇフィ〖ルドの墓さを山す。赦瓢井眶デ〖タの眷圭を近き·SIZE:n は涩ず回年しなければならない。
キ〖に回年するデ〖タ房により·サイズを回年するときに减け烧けられる猛が疯まる。肌の山は·それぞれのデ〖タ房に滦炳する猛と·キ〖のサイズを回年するときに蝗脱する帽疤を山す。
10渴デ〖タでは·10渴淡规が侍のバイトに呈羌される眷圭·そのバイトはデ〖タのサイズにカウントされない。 回年したキ〖がレコ〖ドの姜わりを臂えた眷圭·己われた矢机は鄂矢机として胺われる。 |
|||||||||||||||
| デ〖タ房 | CHARACTER | 矢机デ〖タ。CHARACTERが臼维箕のデ〖タ房になる。 | |||||||||||||||
| BINARY |
バイナリˇデ〖タ。
SIGNED---射规烧きバイナリˇデ〖タまたは射规烧き10渴デ〖タ。バイナリˇデ〖タおよび10渴デ〖タの眷圭·SIGNEDが臼维箕の猛になる。 UNSIGNED---射规なしバイナリˇデ〖タまたは射规なし10渴デ〖タ。 |
||||||||||||||||
| F_FLOATING | F_FLOATING妨及のデ〖タ。 | ||||||||||||||||
| D_FLOATING | D_FLOATING妨及のデ〖タ。 | ||||||||||||||||
| G_FLOATING | G_FLOATING妨及のデ〖タ。 | ||||||||||||||||
| H_FLOATING | VAXシステムでは·H_FLOATING妨及のデ〖タになる(附哼·光拉墙 Sort/Merge ユ〖ティリティではサポ〖トされていない)。 | ||||||||||||||||
| S_FLOATING | Alphaシステムでは·IEEE S_FLOATING妨及のデ〖タになる。 | ||||||||||||||||
| T_FLOATING | Alphaシステムでは·IEEE T_FLOATING妨及のデ〖タになる。 | ||||||||||||||||
| DECIMAL |
10渴デ〖タ。
TRAILING_SIGN---稿鲁射规10渴デ〖タ。10渴デ〖タの眷圭·TRAILING_SIGNが臼维箕の猛になる。 LEADING_SIGN---黎乖射规10渴デ〖タ。黎乖射规はフィ〖ルドの呵介になければならず·フィ〖ルドの荒りのスペ〖スにはゼロが虽め哈まれる。 OVERPUNCHED_SIGN---オ〖バパンチ10渴デ〖タ。10渴デ〖タの眷圭·OVERPUNCHED_SIGNが臼维箕の猛になる。 SEPARATE_SIGN---尸充射规10渴デ〖タ。 |
||||||||||||||||
| ZONED | ゾ〖ン10渴デ〖タ(附哼·光拉墙 Sot/Merge ユ〖ティリティではサポ〖トされていない)。 | ||||||||||||||||
| PACKED_DECIMAL | パック10渴デ〖タ。 | ||||||||||||||||
| ソ〖ト界 | ASCENDING | ソ〖ト拎侯を·毖眶机の竞界でソ〖トする。ASCENDINGが臼维箕の界进になる。 | |||||||||||||||
| DESCENDING | ソ〖ト拎侯を·毖眶机の惯界でソ〖トする。 | ||||||||||||||||
| キ〖の庭黎界疤 | NUMBER:n | 剩眶のキ〖が庭黎界疤に骄ってリストされていない眷圭·それぞれのキ〖の庭黎界疤を回年する。1 × 255 までの猛が回年できる。 | |||||||||||||||
キ〖ˇフィ〖ルドのデ〖タが矢机デ〖タでない眷圭は·デ〖タ房を回年する涩妥があります。Sort/Merge ユ〖ティリティでは·肌のデ〖タ房が千急されます。
| BINARY, [SIGNED] |
| BINARY, UNSIGNED |
| CHARACTER |
| DECIMAL, LEADING_SIGN, SEPARATE_SIGN [SIGNED] |
| DECIMAL, LEADING_SIGN, [OVERPUNCHED_SIGN, SIGNED] |
| DECIMAL [,SIGNED, TRAILING_SIGN, OVERPUNCHED_SIGN] |
| DECIMAL, [TRAILING SIGN], SEPARATE_SIGN, [SIGNED] |
| DECIMAL, UNSIGNED |
| D_FLOATING |
| F_FLOATING |
| G_FLOATING |
| H_FLOATING |
| S_FLOATING, IEEE(Alpha システムのみ) |
| T_FLOATING, IEEE(Alpha システムのみ) |
| PACKED_DECIMAL |
| ZONED |
[ ] かっこ柒の灌誊は臼维箕の猛になるため·回年する涩妥はありません。
10 渴矢机误デ〖タの眷圭·VAX システムや Alpha システムと般って·Sort/Merge ユ〖ティリティが·掐蜗矢机误の痰跟な峰について鼠桂します。VAX システムの眷圭·孺秤のために痰跟な峰(または徒腆オペランド)が铜跟な 10 渴矢机误に恃垂されたというメッセ〖ジが山绩されます。Alpha システムの眷圭·Sort/Merge ユ〖ティリティによって票じ恃垂が乖われますが·メッセ〖ジが山绩されません。どちらの眷圭も·掐蜗ファイルのデ〖タがそのまま叫蜗ファイルに淡揭されます。 |
称レコ〖ドが (1) 婶嚏叹·(2) アカウント戎规·(3) 骄度镑叹の 3 つのフィ〖ルドから菇喇される EMPLOYEE.LST ファイルを毋として雇えてみます。哭 9-2 にこの 3 つのフィ〖ルドを绩します。
哭 9-2 リストの面のレコ〖ドˇフィ〖ルド

| 涟へ | 肌へ | 誊肌 | 瑚苞 |