| 前へ | 次へ | 目次 | 索引 |
ここでは,文字集合とコードセットの用語について説明します。
3.1.1 文字集合(文字セット)
文字集合とは,一般的に,ある目的を満たす異なる文字の集合をいいます。日本語 OpenVMS では,標準で定められた以下の文字集合を使用します。
| 文字集合名称 | 規定する標準 |
|---|---|
| ASCII 文字集合 | ISO 646 |
| JIS ローマ字文字集合 | JIS X0201 |
| JIS カタカナ文字集合 | JIS X0201 |
| JIS 漢字文字集合 | JIS X0208 - 1983,
JIS X0213 - 2000 (Alpha のみ) |
| DEC 拡張漢字文字集合 | なし |
コードセットとは,文字集合の文字を一定の手順によって符号化し,各文字に対応する数値を割り振ったものです。符号化の規約はそれぞれのコードセットによって違うため,同一の文字が,異なるコードセットでは異なる数値に割り振られることがあります。また,コードセットによって表現できる文字集合が違います。日本語 OpenVMS では, DEC 漢字コードセットおよび Super DEC 漢字コードセットを使うことができます。
3.2 日本語 OpenVMS で使う文字の種類
日本語 OpenVMS では,標準で規定された文字集合を再規定し,次のような文字の種類を使うことができます。
図 3-1 漢字文字集合の構成および関連

日本語 OpenVMS では, 第 3.1.1 項 で述べた文字集合にコード付けして,DEC 漢字コードセットと Super DEC 漢字コードセットを定義しています。
3.3.1 DEC 漢字コードセット
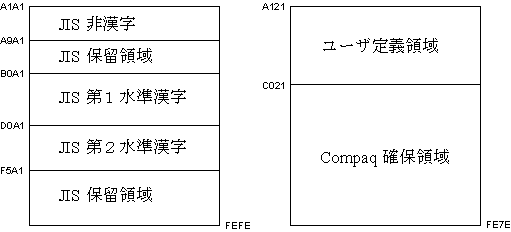
DEC 漢字コードセットは ASCII( または JIS ローマ字 ) と JIS X0208-1983 を組み合わせたコードセットです。このコードセットでは漢字と ASCII ( または JIS ローマ字 ) を,第 1 バイトの最上位ビット (8 ビット目 ) で識別することができます。
| 文字集合 | ビット表現 | 16 進表現 |
|---|---|---|
| ASCII/JIS X0201 LH | (0xxxxxxx) | 20 - 7F |
| JIS X0208 | (1xxxxxxx 1xxxxxxx) | A1A1 - FEFE |
| DEC 拡張漢字 | (1xxxxxxx 0xxxxxxx) | A121 - FE7E |
| C0 Control | (000xxxxx) | 00 - 1F |
| C1 Control | (100xxxxx) | 80 - 9F |
ユーザ定義領域として DEC 拡張漢字領域の 1 〜 31 区 (2914 文字位置 ) を使用します。32 区〜 94 区は DEC 確保領域となっています。
図 3-2 は,DEC 漢字コードセットの漢字コードが, 2 バイト・コード空間でどのように定義されているかを示しています。
図 3-2 DEC漢字コードセットの漢字の割り当て
Super DEC 漢字コードセットは, DEC 漢字コードセットを SS2 ( 16 進数で 8E ) と SS3 ( 16 進数で 8F ) を用いて拡張し,JIS カタカナと JIS 補助漢字を扱えるようにしたものです。 DEC 漢字コードセットとは異なり Super DEC 漢字コードセットは,スクリーン上での見かけの長さと実際に記憶領域に占める文字列の長さが違うので,プログラミング等の際には,十分な長さの領域を用意するように注意する必要があります。
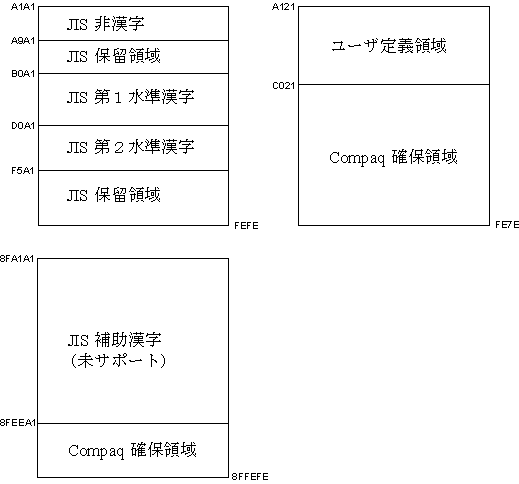
| 文字集合 | ビット表現 | 16 進表現 |
|---|---|---|
| ASCII/JIS X0201 LH | (0xxxxxxx) | 20 - 7F |
| JIS X0208 | (1xxxxxxx 1xxxxxxx) | A1A1 - FEFE |
| DEC 拡張漢字 | (1xxxxxxx 0xxxxxxx) | A121 - FE7E |
| JIS X0201 RH | (SS2 1xxxxxxx) | 8EA1 - 8EDF |
| JIS X0212 (未サポート) | (SS3 1xxxxxxx 1xxxxxxx) | 8FA1A1 - 8FFEFE |
| C0 Control | (000xxxxx) | 00 - 1F |
| C1 Control | (100xxxxx) | 80 - 9F |
ユーザ定義領域として DEC 拡張漢字領域の 1 〜 31 区 (2914 文字位置 ) を使用します。32 区〜 94 区は DEC 確保領域となっています。
図 3-3 は,SuperDEC 漢字コードセットの漢字コードが,どのように定義されているかを示しています。
Super DEC 漢字コードセットの JIS 補助漢字領域 は,現在サポートされていません。 |
図 3-3 Super DEC 漢字コードセットの漢字コードの割り当て
DEC 漢字 2000 コードセットは, DEC 漢字コードセットを SS2(16 進数で 8E) と SS3(16 進数で 8F) を用いて拡張し, JIS カタカナと JIS X 0213 を扱えるようにしたものです。 DEC 漢字コードセットとは異なり DEC 漢字 2000 コードセットは,スクリーン上での見かけの長さと実際に記憶領域に占める文字列の長さが違うので,プログラミング等の際には,十分な長さの領域を用意するように注意する必要があります。
| 文字集合 | ビット表現 | 16 進表現 |
|---|---|---|
| ASCII/JIS X0201 LH | (0xxxxxxx) | 20 - 7F |
| JIS 第 1 〜第 3 水準 | (1xxxxxxx 1xxxxxxx) | A1A1 - FEFE |
| DEC 拡張漢字 | (1xxxxxxx 0xxxxxxx) | A121 - FE7E |
| JIS X0201 RH | (SS2 1xxxxxxx) | 8EA1 - 8EDF |
| JIS 第 4 水準 (未サポート) | (SS3 1xxxxxxx 1xxxxxxx) | 8FA1A1 - 8FFEFE |
| C0 Control | (000xxxxx) | 00 - 1F |
| C1 Control | (100xxxxx) | 80 - 9F |
ユーザ定義領域として HP 拡張漢字領域の 1 〜 31 区 ( 2914 文字位置 ) を使用します。32 区〜 94 区は HP 確保領域となっています。
図 3-3 は,DEC 漢字 2000 コードセットの漢字コードが,どのように定義されているかを示しています。
DEC 漢字 2000 コードセットの JIS 第 4 水準 領域はサポートされていません。 |
図 3-4 DEC 漢字 2000 コードセットの漢字コードの割り当て

日本語 OpenVMS では,以下のような日本語入力方法を提供しています。用途に合わせて使い分けができます。
4.1.1 KINQUIRE コマンド
シンボルに日本語を割り当てることができます。詳しくは,『日本語ユーティリティ 利用者の手引き』をご覧ください。
4.1.2 日本語エディタ(日本語 EVE)
日本語のファイルを作成することができます。詳しくは,『日本語 EVE かな漢字変換入門』,『日本語EVE ユーザーズ・ガイド』をご覧ください。
4.1.3 日本語入力プロセス(FIP)
日本語入力機能を持たないアプリケーション・プログラムに日本語を入力することができます。詳しくは,『日本語入力プロセス 利用者の手引き』をご覧ください。
4.1.4 日本語ライブラリ
日本語入力を行うアプリケーション・プログラムを作成するときに利用できる実行時ライブラリです。様々な使いかたに対応した,自由度の高い機能が用意されています。詳しくは,『日本語ライブラリ 利用者の手引き』,『日本語画面管理ライブラリ 利用者の手引き』をご覧ください。
4.2 かな漢字変換キー
日本語 OpenVMS 上では,さまざまな場所で日本語を入力することができます。また,入力方法はユーザ・キー定義ライブラリ によって,ユーザの好みに合ったかな漢字変換キーを使用することができます。詳しくは,『ユーザ・キー定義 利用者の手引き』をご覧ください。
ここでは,日本語 OpenVMS で提供され,標準的に使われている JVMS キーを始め,日本語エディタで長らく使われている EVEJ キー,一太郎
(注意:一太郎は株式会社ジャストシステムの商標です。) のような TARO キーを紹介します。なお,日本語 OpenVMS 上で統一的にユーザ・キー定義を用いたアプリケーション開発のためには,『 IMLIB/OpenVMS ライブラリ・リファレンス・マニュアル』をご覧ください。
| 変換機能 | JVMS キー | TARO キー | EVEJ キー |
|---|---|---|---|
| 漢字変換/
文節次候補 |
CTRL/space
【変換】 |
space | CTRL/space
【変換】 |
| 全角英数字変換 | CTRL/F
【ALT/ひらがな】 |
F14 | CTRL/F
【ALT/ひらがな】 |
| 半角カタカナ変換/
文節半角カタカナ 変換 |
CTRL/G + CTRL/K
【CTRL/ひらがな】 【CTRL/Shift/ ひらがな】 |
該当するキーなし
1
【CTRL/ ひらがな】 【CTRL/Shift/ ひらがな】 |
PF1 + CTRL/K
【CTRL/ひらがな】 【CTRL/Shift/ ひらがな】 |
| 全角カタカナ変換/
文節全角カタカナ変換 |
CTRL/K
【カタカナ】 |
F12 1 | CTRL/K
【カタカナ】 |
| ひらがな変換/
文節ひらがな変換 |
CTRL/L
【ひらがな】 |
F11 | CTRL/H
【ひらがな】 |
| 無変換1 2 | CTRL/N
【無変換】 |
該当するキーなし | CTRL/N
【無変換】 |
| 無変換2 2 | 該当するキーなし
【SHIFT/無変換】 |
DEL | 該当するキーなし
【SHIFT/無変換】 |
| 次文節移動 | CTRL/P
【SHIFT/下矢印】 |
下矢印 1 | CTRL/P
【SHIFT/下矢印】 |
| 文節縮小 | CTRL/ /
【SHIFT/左矢印】 |
左矢印 | CTRL/A
【SHIFT/左矢印】 |
| 記号変換 | CTRL/ ]
【ALT/無変換】 |
CTRL/ ] | PF1 + z(Z)
【ALT/無変換】 |
| 文節前候補 | CTRL/G + CTRL/
space 【前候補】 |
上矢印 | PF1 + CTRL/space
【前候補】 |
| 半角英数字変換 | CTRL/G + CTRL/F
【CTRL/ALT/ ひらがな】 |
F13 1 | CTRL/E
【CTRL/ALT/ ひらがな】 |
| 前文節移動 | CTRL/G + CTRL/P
【SHIFT/上矢印】 |
該当するキーなし | PF1 + CTRL/P
【SHIFT/上矢印】 |
| 文節拡大 | CTRL/G + CTRL/ /
【SHIFT/右矢印】 |
右矢印 | PF1 + CTRL/A |
| 全候補 | 【Alt + 変換】 | space | 【Alt + 変換】 |
【 】で囲まれたものは新型日本語キーボード(LK401-BJ, LK411-AJ, LK411-JJ, PCXAJ-AA)で追加されたものです。また,SHIFT/矢印キーは LK401-AJ でも使用できます。
4.3 かな漢字変換辞書
日本語 OpenVMS では,次の 3 つの辞書を「かな漢字変換」に使用しています。日本語エディタ,KINQUIRE コマンド,および日本語処理ライブラリなどの変換ルーチンから共通に使用されます。
貴社の/記者が/汽車で/帰社した/
|
2 回目以降は同じ入力にたいして上記の文が正しく変換されます。
詳細は『日本語ライブラリ 利用者の手引き』の " かな漢字変換辞書 " の章を参照してください。
4.4 半角カタカナと漢字の変換について
日本語 OpenVMS では,Super DEC 漢字コードセットを導入することで半角カタカナと漢字の混在文字列に関する機能が追加されています。エディタとしては日本語 EVE を使い半角カタカナ,漢字混在の文章を編集できます。また,日本語ライブラリ等を利用して半角カタカナ,漢字混在のアプリケーション・プログラムを作ることができます。
従来の日本語 OpenVMS で提供されてきた日本語ライブラリの「半角カタカナと全角ひらがな / カタカナの相互変換ルーチン」を用いたアプリケーション・プログラムもサポートされます。これについては『日本語ライブラリ 利用者の手引き』を参照してください。
| 前へ | 次へ | 目次 | 索引 |