| 前へ | 次へ | 目次 | 索引 |
例 3-1 では,2つのスレッドはどちらも同じ変数をアクセスします。しかし,AXPシステムでは,暗黙のうちに共有される変数に対してアプリケーションで不可分性を持たせることが可能です。この例では,2つの変数はロングワードまたはクォドワードの境界内で物理的に隣接しています。VAXシステムでは,各変数は個別に処理できます。AXPシステムでは,ロングワード・データとクォドワード・データのみ,不可分な読み込み操作と書き込み操作がサポートされるため,処理の対象となるバイトを変更する前に,ロングワード全体をフェッチしなければなりません(データ・アクセス粒度の変更についての詳しい説明は,第 4 章 を参照してください)。
この問題を示すために,例 3-1 のプログラムを変更したバージョンについて考えてみましょう。このバージョンでは,メイン・スレッドとASTスレッドはそれぞれデータ構造体で宣言された別々のカウンタ変数をインクリメントします。カウンタ変数は次の文によって宣言されます。
struct {
short int flag;
short int ast_flag;
};
|
メイン・スレッドとASTスレッドがどちらも,処理の対象となるワードを同時に変更しようとした場合には,2つの操作が実行されるタイミングに応じて,結果は予想できなくなります。
同期に関するこの問題を解決するには,次の処理を実行してください。
データ構造の各要素が自然なクォドワード境界に強制的にアラインされるように,データの間にバイトを挿入することもできます。OpenVMS AXP コンパイラは省略時の設定により,データを自然な境界にアラインします。
たとえば,他の実行スレッドからの妨害を受けずに,データ構造の各フラグ変数を確実に変更できるようにするには,64ビットの値となるように変数の宣言を変更します。DEC C を使えば,doubleデータ型を使用できます。次の例を参照してください。
struct {
double flag;
double ast_flag;
};
|
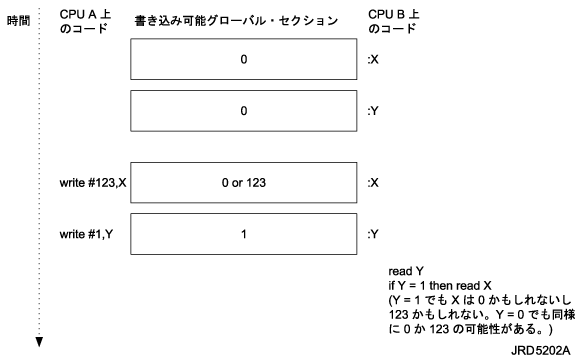
VAXマルチプロセシング・システムは従来,マルチプロセシング・システム内の1つのプロセッサが複数のデータを書き込むときに,これらのデータが書き込まれた順序と同じ順序で,他のすべてのプロセッサから確認できるように設計されていました。たとえば,CPU Aがデータ・バッファを書き込み(図 3-3 でXによって表現されるもの),その後でフラグを書き込んだ場合(図 3-3 で Yによって表現されるもの),CPU Bはフラグの値を確認することにより,データ・バッファが変更されたことを判断できます。
AXPシステムでは,メモリ・サブシステム全体の性能を向上するために,メモリとの間の読み込み操作および書き込み操作の順序が変更される可能性があります。単一プロセッサで実行されるプロセスの場合には,そのプロセッサからの書き込み操作は要求された順に読み込み可能になることを仮定できます。しかし,マルチプロセッサ・アプリケーションの場合には,メモリに対する書き込み操作の結果がシステム全体から確認できるようになる順序を,前もって判断できません。つまり,CPU Aによって実行される書き込み操作は,実際に書き込まれた順序とは異なる順序でCPU Bから見える場合もあります。
図 3-3 はこの問題を示しています。CPU AはXに対する書き込み操作を要求し,その後,Yに対する書き込み操作を要求します。CPU BはYからの読み込み操作を要求し,Yの新しい値を確認し,Xの読み込み操作を開始します。Xの新しい値がまだメモリに書き込まれていない場合には,CPU Bは前の値を読み込みます。この結果,CPU AとCPU Bで実行されるプロシージャが依存するトークン受け渡しプロトコルは正しく機能しなくなります。CPU Aはデータを書き込み,フラグ・ビットをセットできますが,CPU Bは,データが実際に書き込まれる前にフラグ・ビットがセットされていることを確認する可能性があり,その結果,誤ったメモリの内容を使用してしまいます。
図 3-3 AXPシステムでの読み込み/書き込み操作の順序
並列に実行され,読み込み/書き込みの順序に依存するプログラムは,AXPシステムで正しく実行するために何らかの設計変更が必要です。アプリケーションに応じて,次の方法を使用してください。
VESTコマンドの/PRESERVE修飾子は,VAXシステムで提供されるのと同じ不可分性を保証して,AXPシステムでトランスレートされたVAXイメージを実行できるようにするためのキーワードを受け付けます。/PRESERVE修飾子のキーワードは複数のタイプの不可分性保護機能を提供します。ただし,これらの/PRESERVE修飾子のキーワードを指定すると,アプリケーションの性能が低下する可能性があります(/PRESERVE修飾子の指定についての詳しい説明は,『DECmigrate for OpenVMS AXP Systems Translating Images』を参照してください)。
VAXシステムでVAX命令が不可分な方法で実行できる操作を,トランスレートされたイメージでもできるようにするには,/PRESERVE修飾子に対してINSTRUCTION_ATOMICITYキーワードを指定します。
ロングワードまたはクォドワードに格納された隣接バイトを同時に更新し,これらの各バイトが相互に妨害しないようにするには,/PRESERVE修飾子に対して MEMORY_ATOMICITYキーワードを指定します。
読み込み/書き込み操作が実行される順序が要求した順序と同じ順序で実行されるように見えるようにするには,/PRESERVE修飾子に対して READ_WRITE_ORDERINGキーワードを指定します。
この章では,アプリケーションが使用する VAXアーキテクチャに依存したデータを確認する方法について説明します。この章ではまた,データ型の選択が AXPシステムでアプリケーションのサイズと性能にどのような影響を与えるかについても説明します。
4.1 概要
Cのintや,FORTRANのINTEGER*4など,高級プログラミング言語でサポートされるデータ型は,アプリケーションに対して高度なデータの移植性 (portability)を保証します。なぜなら,これらのデータ型を用いていれば,マシン内部のデータ型を意識しなくてもよいからです。各高級言語は,ターゲット・プラットホームでサポートされるデータ型に対し,各言語の持つデータ型をマッピングします。この理由から,VAXシステムのアプリケーションは,データ宣言をまったく変更せずに AXPシステムで正しく再コンパイルし,実行することが可能です。
しかし,アプリケーションでデータ型に関して次のような仮定を設定している場合には,ソース・コードを変更しなければなりません。
データの互換性を維持するために,Alpha AXPアーキテクチャはVAXアーキテクチャと同じデータ型の多くをサポートするように設計されています。表 4-1 は,2つのアーキテクチャがどちらもサポートするネイティブなデータ型を示しています(データ型のフォーマットについての詳しい説明は『Alpha Architecture Reference Manual』を参照してください)。
| VAXデータ型 | AXPデータ型 |
|---|---|
| バイト | バイト |
| ワード | ワード |
| ロングワード | ロングワード |
| クォドワード | クォドワード |
| オクタワード | -- |
| F浮動小数点 | F浮動小数点 |
| D浮動小数点(56ビットの精度) | D浮動小数点(53ビットの精度) |
| G浮動小数点 | G浮動小数点 |
| H浮動小数点 | -- |
| -- | S浮動小数点(IEEE) |
| -- | T浮動小数点(IEEE) |
| 可変長ビット・フィールド | -- |
| 絶対キュー | 絶対ロングワード・キュー |
| -- | 絶対クォドワード・キュー |
| 自己相対キュー | 自己相対ロングワード・キュー |
| -- | 自己相対クォドワード・キュー |
| 文字列 | -- |
| トレーリング数字列 | -- |
| リーディング・セパレート数字列 | -- |
| パック10進数(packed decimal)字列 | -- |
アプリケーションがVAXデータ型のフォーマットやサイズに依存していない限り,データ型のマッピングは自動的に変更されるため,アプリケーションを変更する必要はありません。可能な場合,AXPシステムのコンパイラは,そのデータ型を VAXシステムと同じやり方で,同じネイティブ・データ型にマッピングします。VAXデータ型がAlpha AXPアーキテクチャでサポートされない場合には,コンパイラはそれらのデータ型を対応するAXPデータ型にマッピングします(AXPシステムのコンパイラがサポートするデータ型をネイティブなAXPデータ型に対しどのような方法でマッピングするかについての詳しい説明は,付録 A とコンパイラの解説書を参照してください)。
次のリストは,データ型宣言に有効なガイドラインを示しています。
ほとんどのアプリケーションにとって,この変更はまったく影響ありません。しかし,G浮動小数点データ型から戻される値(小数点以下15桁の有効桁数)は D浮動小数点データ型から戻される値(小数点以下16桁の有効桁数)より,少し精度が低くなります。
OpenVMSランタイム・ライブラリは変換ルーチン(CVT$CONVERT_FLOAT)をサポートし,これらのルーチンを使用すれば,浮動小数点データを1つのフォーマットから別のフォーマットに変換できます。たとえば,このルーチンを使用すれば,D浮動小数点形式のデータをIEEE形式に変換したり,その逆に変換することができます。また,Alpha AXPアーキテクチャはIEEE倍精度浮動小数点形式(T浮動小数点)もサポートします。
DEC C for OpenVMS AXPシステムは,long floatデータ型を使用する宣言を見つけると警告メッセージを出します。VAXシステムでは,long floatデータ型はdoubleと同意語です。AXPシステムでは,DEC C コンパイラがVAX Cモードで使用されていても,long floatデータ型はサポートされません。
たとえば,VAX Cでは,一部のプログラムでこのような仮定をしています。例 4-1 を参照してください。
| 例 4-1 VAX Cコードでのデータ型に関する仮定 |
|---|
typedef struct {
char small;
short medium;
long large;
} MYSTRUCT ;
main()
{
int a1;
long b1;
MYSTRUCT c1;
(1) a1 = &c1;
(2) b1 = &c1;
(3) a1->small = 1;
b1->small = 2;
}
|
次のリストの各項目は 例 4-1 に示した番号に対応しています。
この例をAXPシステムに移行するには,次に示すように,a1とb1の宣言を,データ構造体(MYSTRUCT)に対するポインタに変更しなければなりません。
MYSTRUCT *a1,*b2; |
アプリケーションがAXPシステムで再コンパイルし,正しく実行できる場合でも,データ型の選択のためにOpenVMS AXPアーキテクチャの特徴を完全に利用できていない可能性があります。特に,データ型の選択はAXPシステムでのアプリケーションの最終的なサイズと性能に影響を与える可能性があります。
4.3.1 データ型の選択がコード・サイズに与える影響
VAXシステムでは,アプリケーションは通常,データにとって適切な最小サイズのデータ型が使用されます。たとえば,32,768〜-32,767の範囲の値を表現する場合,Cで作成したアプリケーションではshortデータ型の変数を宣言します。VAXシステムでは,このようにすれば必要な記憶空間を節約でき,また,VAXアーキテクチャがすべてのサイズのデータ型に対して動作する命令をサポートするので,効率を損いません。
AXPシステムでは,バイト・サイズとワード・サイズのデータを使用すると,ロングワード・サイズやクォドワード・サイズのデータを使用したときより多くのオーバーヘッドが発生します。これは,Alpha AXPアーキテクチャでこれらの小さいサイズのデータ型を操作できる命令がサポートされないからです。バイトやワードを参照する操作は,VAXシステムでは1つの命令として実現されますが,AXPシステムでは,対象となるバイトまたはワードを格納したロングワードのフェッチ,対象となるバイト,ワードの操作,ロングワード全体の格納といった一連の命令として実現されます。頻繁に参照されるデータの場合には,AXPシステムでこれらの追加された命令によって,アプリケーションのサイズが大幅に大きくなる可能性があります。
| 前へ | 次へ | 目次 | 索引 |