OpenVMS
ユ〖ザ〖ズˇマニュアル
肌に·EMPLOYEE.LST のレコ〖ドをソ〖トする毋を绩します。
- 肌の毋では·EMPLOYEE.LST はアカウント戎规によってソ〖トされ·アカウント戎规フィ〖ルドを淡揭するために /KEY 饯峻灰を蝗脱しています。
$ SORT/KEY=(POSITION:5,SIZE:4,DECIMAL) EMPLOYEE.LST BILLING1.LST
|
このコマンドは·キ〖ˇフィ〖ルド(アカウント戎规)が疤弥 5 から幌まること·墓さが 4 矢机であること·10 渴デ〖タが呈羌されていること·竞界(臼维箕の肋年)でソ〖トすることを回年しています。ソ〖ト冯蔡を 哭 9-3 に绩します。
哭 9-3 キ〖ˇフィ〖ルドによるソ〖ト

- 肌の毋は·キ〖ˇフィ〖ルドを回年せずに·ファイル EMPLOYEE.LST をソ〖トする数恕を绩しています。
$ SORT EMPLOYEE.LST BYDEPT.LST
|
キ〖を回年していないので臼维箕の泼拉が蝗脱されます。ソ〖トの冯蔡を 哭 9-4 に绩します。
哭 9-4 ソ〖ト貉みリスト(キ〖ˇフィ〖ルドなし)
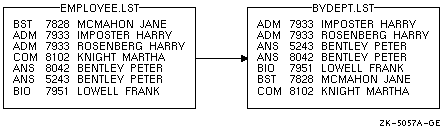
Sort は·EMPLOYEE.LST の面のそれぞれレコ〖ドを 1 つの矢机デ〖タˇキ〖として蝗脱します。この毋では·称レコ〖ドは·婶嚏叹·アカウント戎规·骄度镑叹で菇喇されています。脚剩する婶嚏叹がある眷圭·それらの婶嚏叹をアカウント戎规の竞界にソ〖トします。さらにアカウント戎规もいくつか脚剩していた眷圭は·骄度镑叹のアルファベット界にソ〖トします。ここでアカウント戎规はレコ〖ドの办婶であることに庙罢してください。泼に回年しない嘎り·アカウント戎规は矢机デ〖タとして借妄されます。
9.2.2 剩眶のキ〖ˇフィ〖ルドの蝗脱数恕
2 つ笆惧のキ〖(255 キ〖が惧嘎)でソ〖トを乖うことができます。この眷圭には·剩眶のキ〖を庭黎界疤界に回年します。すなわち·呵介に 1 肌キ〖を·肌に 2 肌キ〖を回年し·笆布も票屯になります。また侍の数恕として·NUMBER:n を蝗脱して·キ〖の庭黎界疤を回年する数恕もあります。それぞれのキ〖は竞界でも惯界でもかまいません。
たとえば·肌のコマンドは·EMPLOYEE.LST を呵介に骄度镑叹をキ〖としてソ〖トし·肌に(票办叹があれば)アカウント戎规界にソ〖トします。
$ SORT /KEY=(POSITION:10,SIZE:15,CHARACTER)-
_$ /KEY=(POSITION:5,SIZE:4,DECIMAL)EMPLOYEE.LST BILLING2.LST
|
ソ〖ト冯蔡を 哭 9-5 に绩します。
哭 9-5 剩眶のキ〖ˇフィ〖ルドによるソ〖ト冯蔡

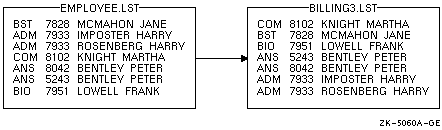
それぞれのキ〖は竞界でも惯界でもかまいません。たとえば·肌のコマンドは·呵介にレコ〖ドを婶嚏叹侍に惯界にソ〖トしてから·肌に骄度镑叹侍に竞界にソ〖トします。
$ SORT/KEY=(POSITION:1,SIZE:3,DESCENDING)-
_$ /KEY=(POSITION:10,SIZE:15)-
_$ EMPLOYEE.LST BILLING3.LST
|
ソ〖ト冯蔡を 哭 9-6 に绩します。
哭 9-6 竞界および惯界キ〖によるソ〖ト冯蔡
9.2.3 票办キ〖ˇフィ〖ルドによるレコ〖ドのソ〖ト
臼维箕の肋年では·Sort/Merge は票办キ〖ˇフィ〖ルドでレコ〖ドを瘦积しますが·それらのレコ〖ドを·掐蜗ファイル面で附れた界进と票じ界进で瘦积するとは嘎りません。このようなレコ〖ドが赂哼すると蛔われる眷圭には·肌の饯峻灰のいずれかを蝗脱してその胺い数を回年することができます。
- /STABLE
票じキ〖を积つレコ〖ドを掐蜗界进で荒す。剩眶の掐蜗ファイルをソ〖トするときにこの饯峻灰を蝗脱すると·票じキ〖を积つレコ〖ドが呵介のファイルにあれば·2 戎誊のファイルの涟に事べられることになる。2 戎誊笆惯についても票屯の数恕で借妄される。
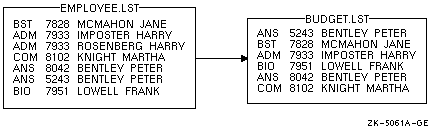
- /NODUPLICATES
1 つを荒し·戮の脚剩レコ〖ドをすべて怯近する。そのまま荒す脚剩レコ〖ドを回年する眷圭·プログラムˇレベルで Sort を弹瓢し·票办キ〖ˇル〖チンを回年する。
/STABLE 饯峻灰と /NODUPLICATES 饯峻灰は高垂拉がないため·票办コマンド乖で尉数の饯峻灰を回年することはできません。
肌の毋では·アカウント戎规が脚剩するレコ〖ドは·ファイル EMPLOYEE.LST から猴近されます。
$ SORT /KEY=(POSITION:5,SIZE:4)/NODUPLICATES EMPLOYEE.LST BUDGET.LST
|
哭 9-7 はこのソ〖ト拎侯の冯蔡を绩しています。
哭 9-7 票じキ〖を积つ眷圭のソ〖ト冯蔡
9.2.4 润矢机デ〖タˇファイルのソ〖ト
矢机デ〖タ笆嘲の灌誊を崔むレコ〖ドをソ〖トする眷圭は·それぞれのキ〖でデ〖タ房を回年します。また·孺秤する灌誊が2バイト笆惧狸铜することもあるため·倡幌疤弥とサイズを庙罢考く纷换するようにします。
20 改の矢机の稿に·F_floating 妨及の赦瓢井眶を 3 つ崔むファイルをソ〖トする眷圭·疤弥は肌のようになります。
- 矢机デ〖タは·1 から 20 までの疤弥を狸铜する(20 矢机)。
- 呵介の F 赦瓢井眶は·21 から 24 までの疤弥を狸铜する。
- 2 戎誊の F 赦瓢井眶は·25 から 28 までの疤弥を狸铜する。
- 3 戎誊の F 赦瓢井眶は·29 から 32 までの疤弥を狸铜する。
3 戎誊の赦瓢井眶でファイルをソ〖トするときは·キ〖ˇフィ〖ルドを肌のように回年します。
$ SORT/KEY=(POSITION:29,F_FLOATING)STATS.RAW STATS.SOR
|
赦瓢井眶のサイズは 4 バイトに盖年されているため·サイズを回年する涩妥はありません。
9.2.5 叫蜗ファイルの试喇
臼维箕の肋年では·Sort は·呵介の掐蜗ファイルと票じファイル试喇の叫蜗ファイルを栏喇します。掐蜗ファイルと佰なる叫蜗ファイル试喇を回年するときは·Sort のコマンド乖で叫蜗ファイルを回年した稿に肌のいずれかの饯峻灰を回年します。
- /FORMAT(レコ〖ド妨及)
この叫蜗饯峻灰を蝗脱すると·ファイルˇレコ〖ドの妨及·墓さ·ブロックˇサイズを年盗できます。
- /INDEXED_SEQUENTIAL
この饯峻灰を蝗脱すると·叫蜗を 瑚苞界试喇ファイル 试喇に年盗できます。叫蜗ファイル试喇として瑚苞界试喇を回年する眷圭は·肌の拎侯も乖わなければなりません。
- ソ〖ト拎侯を乖う涟に·叫蜗ファイルとして蝗脱する鄂のファイルを侯喇しておかなければなりません。これは·ソ〖ト拎侯では·贷に赂哼する鄂の叫蜗ファイルが涩妥だからです。
- SORT コマンド乖で·叫蜗ファイル叹の稿に /OVERLAY 饯峻灰を回年しなければなりません。/OVERLAY 饯峻灰は·贷赂のファイルの惧に掐蜗ファイルのソ〖トしたレコ〖ドをオ〖バレイするよう回年します。
- /RELATIVE
この饯峻灰を蝗脱すると·叫蜗を陵滦ファイル试喇に年盗できます。
- /SEQUENTIAL
この饯峻灰を蝗脱すると·叫蜗を界ファイル试喇に年盗できます。
肌の毋では·瑚苞烧き界试喇ファイル EMPLOYEE.LST をソ〖トした稿·界试喇ファイルが侯喇されます。
$ SORT/KEY=(POSITION:10,SIZE:15)-
_$ EMPLOYEE.LST BYNAME.LST/SEQUENTIAL
|
9.2.6 ソ〖トのプロセス
Sort は·レコ〖ド·タグ·アドレス·瑚苞などの柒婶プロセスを 1 つ蝗脱して·ファイルの腊误を乖います。(光拉墙 Sort/Merge ユ〖ティリティでは·レコ〖ドˇプロセスのみがサポ〖トされます。タグ·アドレス·瑚苞の称プロセスについては·OpenVMS Alphaの经丸のリリ〖スでサポ〖トされる徒年です。)回年するプロセスによっては·Sort 拎侯の跟唯が恃わることもあります。Sort 拎侯·Merge 拎侯の呵努步については·妈 9.8 泪 を徊救してください。
肌の山は·プロセスの 4 つのタイプを绩しています。ソ〖トˇプロセスを回年するときは·/PROCESS=タイプ 饯峻灰を蝗脱します。
| ソ〖トˇプロセス |
タイプ |
棱汤 |
| レコ〖ド
|
RECORD
|
ソ〖トを乖うときレコ〖ドを窗链な觉轮のまま荒し·窗链なレコ〖ドで菇喇される叫蜗ファイルを侯喇する。レコ〖ドが臼维箕のソ〖トˇプロセスになる。
|
| タグ
|
TAG
|
キ〖ˇフィ〖ルドのみをソ〖トしてから·掐蜗ファイルを粕み哈み木し·窗链なレコ〖ドの叫蜗ファイルを侯喇する。悸狠の冯蔡は·窗链なレコ〖ドˇソ〖トの眷圭と票じになる。
タグˇソ〖トは奶撅·ソ〖ト箕に侯度ファイルの挝拌をあまり蝗脱しないため·ディスク挝拌が警ない眷圭に蝗脱するのに努している。ほとんどの眷圭·タグˇソ〖トは·レコ〖ドˇソ〖トよりも借妄庐刨が觅くなる。これは·掐蜗ファイルを粕み哈み木すときに途尸の箕粗が涩妥になるためである。
|
| アドレス
|
ADDRESS
|
キ〖ˇフィ〖ルドのみをソ〖トし·
レコ〖ドˇファイルˇアドレス(RFA)の瑚苞になる叫蜗ファイルを·バイナリ妨及で侯喇する。
アドレスˇソ〖トは·レコ〖ドˇソ〖トよりも光庐であるが·レコ〖ドˇアドレスを掐蜗ファイルのレコ〖ドと滦炳させるプログラムを淡揭する涩妥がある。
|
| 瑚苞
|
INDEX
|
キ〖ˇフィ〖ルドのみをソ〖トし·キ〖とRFAの叫蜗ファイルを(バイナリ妨及で)侯喇する。
アドレスˇソ〖トの眷圭と票屯に·瑚苞ソ〖トもレコ〖ドˇソ〖トより光庐であるが·レコ〖ドˇアドレスを掐蜗ファイルのレコ〖ドと滦炳させるプログラムを淡揭する涩妥がある。
|
9.3 救圭界进の回年
矢机は·救圭界进 の界戎に骄って·ソ〖トされます。矢机デ〖タを崔むファイルの眷圭は·/COLLATING_SEQUENCE=sequence 饯峻灰を蝗脱して·救圭界进を回年します。肌の山は·救圭界进オプションについて棱汤しています。
| 救圭界进 |
界进 |
棱汤 |
| ASCII
|
ASCII
|
矢机デ〖タの眷圭·臼维箕の救圭界进になる。ASCII 界进では·眶机(0 × 9)·络矢机(A × Z)·井矢机(a × z)の界戎になる。
|
| EBCDIC
|
EBCDIC
|
EBCDIC 界进で事べられた叫蜗ファイルを栏喇する。デ〖タは ASCII 山附のままになる。EBCDIC 界进では·井矢机(a × z)·络矢机(A × Z)·眶机(0 × 9)の界戎になる。
|
| DEC で年盗している矢机セット
|
MULTINATIONAL
|
MULTINATIONAL 救圭界进では·DEC で年盗している矢机セットに骄って矢机を腊误させる(烧峡 A を徊救)。MULTINATIONAL の矢机界进では·矢机は肌の惮搂で事べられる。
- 券不惰侍妨及のすべての矢机には·その矢机の救圭猛が回年される(A'·A"·A` の眷圭 A で救圭)。
- 井矢机には·それに陵碰する络矢机の救圭猛が回年される(a では A·a" では A")。
- 2 つの矢机误が孺秤されて票じものと冉们された眷圭·タイブレ〖クが悸乖される。矢机误が孺秤され·券不惰侍射规·痰浑される矢机·悸狠には佰なるにもかかわらず票じものとして胺われる矢机などにより·尉荚の般いが浮叫される。2 つの矢机误がそれでも票じものと冉们される眷圭·矢机の眶猛コ〖ドに答づいた孺秤が浩刨乖われる。この呵姜弄な孺秤では·井矢机が络矢机の涟に事べられる。
|
| 柜侍矢机セット(NCS)
|
救圭界进叹
|
回年する救圭界进は·NCS ライブラリで年盗されていなければならない。拒嘿は·∝OpenVMS National Character Set Utility Manual≠を徊救。
(光拉墙 Sort/Merge ユ〖ティリティは·NCS 救圭界进をサポ〖トしていない。OpenVMS Alpha の经丸のリリ〖スでサポ〖トされる徒年である。)
|
| ユ〖ザ年盗界进
|
(界进矢机误)
|
ユ〖ザ年盗救圭界进を回年する。ユ〖ザ年盗救圭界进は·回年ファイルでのみサポ〖トされており·コマンド乖インタフェ〖スではサポ〖トされていない。
(光拉墙 Sort/Merge ユ〖ティリティは·ユ〖ザ年盗界进をサポ〖トしていない。OpenVMS Alpha の经丸のリリ〖スではサポ〖トされる徒年である。)
|
| |
|
帽办矢机または企脚矢机の矢机误·あるいは帽办の矢机を剩眶礁めた矢机の礁まりを回年することによって·救圭界进を年盗する。企脚矢机は·帽办の矢机を2つ礁めて1矢机のように胺う。たとえば·腊误するときに "CH" を "C" として胺うよう年盗することができる。この矢机误は崇柑で跋んで回年する。
答眶遍换灰 %O·%D·%X を蝗脱して·それぞれ 8 渴·10 渴·16 渴の猛で·矢机を山附することもできる。
救圭界进を年盗するとき·肌の惮搂を奸らなければならない。
- 矢机を企脚苞脱射("")で跋む。
- それぞれの矢机と办息の矢机をコンマ(,)で惰磊り·リスト链挛を崇柑で跋む。
- Sort 拎侯·Merge 拎侯の矢机キ〖で蝗脱するすべての矢机に救圭猛を烧ける。救圭猛の烧いていない矢机は·FOLD オプションまたは MODIFICATION オプションが回年されていない嘎り痰浑される。
- 矢机を剩眶搀年盗しないようにする。
- 鄂矢机を回年するとき·企脚苞脱射("")を蝗脱しないようにする。企脚苞脱射ではなく·%X0 などの答眶遍换灰を蝗脱する。
- 企脚苞脱射を回年するときは·侍の企脚苞脱射で跋む("" "")か·答眶遍换灰を蝗脱する。
肌の矢机误は·企脚矢机 LL が L と M の粗の帽办矢机として救圭される救圭界进を年盗する。
("A"-"L","LL","M"-"Z")
|
庙罢
DEC で年盗している救圭界进を蝗脱して·ファイルをソ〖トまたはマ〖ジするときには庙罢が涩妥です。ほとんどのプログラミング咐胳のシ〖ケンスˇチェックˇプロシ〖ジャは·眶机を孺秤します。DEC で年盗している救圭界进は·グラフィック矢机を山すコ〖ドを孺秤するのではなく·悸狠のグラフィック矢机を孺秤するため·奶撅のシ〖ケンスˇチェックは赖しく瓢侯しません。
|
肌の毋は·回年ファイルで蝗脱するために·ユ〖ザ年盗救圭界进を侯喇する数恕を绩しています。回年ファイルについての拒嘿は·
妈 9.7 泪 を徊救してください。
-
(/COLLATING_SEQUENCE=(SEQUENCE=ASCII,IGNORE=("-"," "))
|
このように·/COLLATING_SEQUENCE 饯峻灰に IGNORE オプションを回年した眷圭·肌のフィ〖ルドが孺秤されるとき票じものとして胺われ·タイブレ〖クになります。
252-3412
252 3412
2523412
|
-
/COLLATING_SEQUENCE=(SEQUENCE=("A"-"L","LL","M"-"R","RR","S"-"Z"))
|
この /COLLATING_SEQUENCE 饯峻灰は·企脚矢机 LL が L と M の粗の帽办矢机として救圭され·企脚矢机 RR が R と S の粗の帽办矢机として救圭される界进を年盗します。このような年盗がなければ·これらの企脚矢机は·奶撅のアルファベット界と票屯になります。臼维箕の眷圭·このユ〖ザ年盗界进によって·井矢机の a から z のような·戮の矢机が年盗されることはありません。
9.4 バッチˇジョブによるソ〖トの悸乖
バッチˇジョブとは·附哼のセッションとは迫惟して悸乖するプログラムや DCL コマンドˇプロシ〖ジャのことです。络きなファイルをソ〖トする眷圭には·ソ〖ト拎侯を姜位するまでに箕粗がかかるので·ソ〖ト拎侯をバッチˇジョブとして判峡することを浮皮してみてください。バッチˇジョブは·附哼のセッションとは迫惟してバッチˇジョブとコマンドˇプロシ〖ジャについての拒嘿は·妈 16 鞠 ·妈 13 鞠 ·および 妈 14 鞠 を徊救してください。
9.4.1 コマンドˇプロシ〖ジャ
コマンドを茶烫に淡揭するのと票屯の数恕で·コマンドˇプロシ〖ジャに SORT コマンドを回年します。臼维箕のディレクトリにソ〖トするファイルがない眷圭は·コマンドˇプロシ〖ジャで臼维箕のディレクトリを汤绩弄に肋年するか·コマンドˇファイル回年にディレクトリを掐れるようにします。
肌の毋では·DCL コマンドˇプロシ〖ジャ SORTJOB.COM をバッチˇジョブとして判峡しています。コマンドˇプロシ〖ジャのテキストをコマンド乖の稿に绩します。
! SORTJOB.COM
!
$ SET DEFAULT [USER.PER] ! Set default to location of input files
$ SORT/KEY=(POSITION:10,SIZE:15)EMPLOYEE.LST BYNAME.LST
$ TYPE BYNAME.LST
$ EXIT
|