| Previous | Contents | Index |
Under certain conditions, transactions may become blocked or hung, and applications can use certain RTR features to clear such roadblocks. Often, a blocked state can be cleared by the system manager using the SET TRANSACTION CLI command to change the state of a transaction, for example, to DONE. Only certain states, however, can be changed, and changing the state of a transaction manually can endanger the integrity of the application database. For information on using the SET TRANSACTION command from the CLI, see the Reliable Transaction Router System Manager's Manual.
To achieve a change of state within an application, the designer can use the rtr_set_info C API call. For example, the following code fragments illustrate how such application code could be written. Such code must be used in conjunction with a design that uses a change of state only when transactions are blocked.
rtr_tid_t tid;
rtr_channel_t pchannel;
rtr_qualifier_value_t select qualifiers[4];
rtr_qualifier_value_t set_qualifiers[3];
int select_idx = 0;
int set_idx = 0;
rtr_get_tid(pchannel, RTR_F_TID_RTR, &tid);
/* Transaction branch to get current state */
select_qualifiers[select_idx].qv_qualifier = rtr_txn_state;
select_qualifiers[select_idx].qv_value = &rtr_txn_state_commit;
select _ idx++;
/* Transaction branch to set new state */
set_qualifiers[set_idx].qv_qualifier = rtr_txn_state;
set_qualifiers[set_idx].qv_value = &rtr_txn_state_exception;
set_idx++;
sts = rtr_set_info(pchannel,
(rtr_flags_t) 0,
(rtr_verb_t)verb_set,
rtr_transaction_object,
select_qualifiers,
set_qualifiers);
if(sts != RTR_STS_OK)
write an error;
sts = rtr_receive_message(
/* channel */ &channel_id,
/* flags */ RTR_NO_FLAGS,
/* prcvchan */ pchannel,
/* pmsg */ msg,
/* maxlen */ RTR_MAX_MSGLEN,
/* timoutms */ 0,
/* pmsgsb */ &msgsb);
if (sts == RTR_STS_OK){
const rtr_status_data_t *pstatus = (rtr_status_data_t *)msg;
rtr_uns_32_t num;
switch(pstatus -> status)
{
case RTR_SETTRANDONE: /*Set Tran done successfully */
memcpy(&num,(char)msg+sizeof(rtr_status_data_t),
sizeof(rtr_uns_32_t));
printf(" %d transaction(s) have been processed\n");
break;
default;
}
}
|
RTR keeps track of how many times a transaction is presented to a server application before it is VOTED. The rule is: three strikes and you're out! After the third strike, RTR rejects the transaction with the reason RTR_STS_SRVDIED . The server application has committed the transaction and the client believes that the transaction is committed. The transaction is flagged as an exception and the database is not committed. Such an exception transaction can be manually committed if necessary. This process eliminates the possibility that a single rogue transaction can crash all available copies of a server application at both primary and secondary sites.
Application design can change this behavior. The application can specify the retry count to use when in recovery using the /recovery_retry_count qualifier in the rtr_set_info call, or the system administrator can set the retry count from the RTR CLI with the SET PARTITION command. If no recovery retry count is specified, RTR retries replay three times. For recovery, retries are infinite. For more information on the SET PARTITION command, refer to the Reliable Transaction Router System Manager's Manual; for more information on the rtr_set_info call, refer to the Reliable Transaction Router C Application Programmer's Reference Manual.
When a node is down, the operator can select a different backend to use for the server restart. To complete any incomplete transactions, RTR searches the journals of all backend nodes of a facility for any transactions for the key range specified in the server's rtr_open_channel call.
Use the rtr_broadcast_event call to broadcast a user event message.
A user broadcast is named or unnamed. An unnamed broadcast does a match on user event number. A named broadcast does a match on user event number and recipient name, a user-defined string. Named broadcasts provide greater control over who receives a particular broadcast. Named events specify an event number and a textual recipient name. The name can include wildcards (* and %).
For all unnamed events, specify the evtnum field and RTR_NO_RCPSPC (no recipient specification) for the recipient name.
For example, the following code specifies named events for all subscribers ( rcpnam="*" ):
rtr_status_t
rtr_open_channel {
...
rtr_rcpnam_t rcpnam = "*";
rtr_evtnum_t evtnum = {
RTR_EVTNUM_USERDEF,
RTR_EVTNUM_USERBASE,
RTR_EVTNUM_UP_TO,
RTR_EVTNUM_USERMAX,
RTR_EVTNUM_ENDLIST
};
rtr_evtnum_t *p_evtnum = &evtnum;
|
For a broadcast to be received by an application, the recipient name specified by the subscribing application on its rtr_open_channel call must match the recipient specifier used by the broadcast sender on the rtr_broadcast_event call.
RTR_NO_RCPSPC is not the same as "*". |
An application receives broadcasts with the rtr_receive_message call. A message type returned in the message status block informs the application of the type of broadcast received. Table 5-6 summarizes the rules.
| Broadcast Type | Match On | Specify |
|---|---|---|
| Named | user event number | evtnum field |
| recipient name | rcpspc= subscriber (for all subscribers use ="*") | |
| Unnamed | user event number | evtnum field |
| RTR_NO_RCPSPC |
RTR callout servers enable security checks to be carried out on all requests using a facility. Callout servers can run on either backend or router nodes. They receive a copy of every transaction delivered to, or passing through, the node, and they vote on every transaction. To enable a callout server, use the /CALLOUT qualifier when issuing the RTR CREATE FACILITY command. Callout servers are facility based, not key-range or partition based.
An application enables a callout server by setting a flag on the rtr_open_channel call.
For a router callout server, the application sets the following flag on the rtr_open_channel call:
rtr_ope_flag_t
flags=RTR_F_OPE_SERVER |RTR_F_OPE_TR_CALL_OUT
|
For a backend callout server, the application sets the following flag on the rtr_open_channel call:
rtr_ope_flag_t
flags=RTR_F_OPE_SERVER|RTR_F_OPE_BE_CALL_OUT
|
To provide information for the design of new applications, this section contains scenarios or descriptions of existing applications that use RTR for a variety of reasons. They include:
In the 1980s, a large railway system implemented a monolithic application in FORTRAN for local reservations with local databases separated into five administrative domains or regions: Site A, Site B, Site C, Site D, and Site E. By policy, rail travel for each region was controlled at the central site for each region, and each central site owned all trains leaving from that site. For example, all trains leaving from Site B were owned by Site B. The railway system supported reservations for about 1000 trains.
One result of this architecture was that for a passenger to book a round-trip journey, from, say, Site B to Site A and return, the passenger had to stand in two lines, one to book the journey from Site B to Site A, and the second to book the journey from Site A to Site B.
The implementation was on a Compaq OpenVMS cluster at each site, with a database engine built on RMS, using flat files. The application displayed a form for filling out the relevant journey and passenger information: (train, date, route, class, and passenger name, age, sex, concessions). The structure of the database was the same for each site, though the content was different. RTR was not used. Additionally, the architecture was not scalable; it was not possible to add more terminals for client access or add more nodes to the existing clusters without suffering performance degradation.
This example implements partitioned, distributed databases and surrogate clients.
New requirements from the railway system for a national passenger reservations system included the goal that a journey could be booked for any train from anywhere to anywhere within the system. Meeting this goal would also enable distributed processing and networking among all five independent sites. In addition to this new functionality, the new architecture had to be more scalable and adaptable for PCs to replace the current terminals, part of the long-term plan.
With these objectives, the development team rewrote their application in C, revamped their database structure, adopted RTR as their underlying middleware, and significantly improved their overall application. The application became scalable, and additional features could be introduced. Key objectives of the new design were improved performance, high reliability in a moderately unstable network, and high availability, even during network link loss.
The structure of the database at all sites was the same, but the data were for each local region only. The database was partitioned by train ID (which included departure time), date, and class of service, and RTR data content routing was used to route a reservation to the correct domain, and bind reservation transactions as complete transactions across the distributed sites to ensure booking without conflicts. This neatly avoided booking two passengers in the same seat, for example. Performance was not compromised, and data partitioning provided efficiency in database access, enabling the application to scale horizontally as load increased. This system currently deals with approximately three million transactions per day. One passenger reservation represents a single business transaction, but may be multiple RTR transactions. An inquiry is a single transaction.
An important new feature was the use of surrogate clients at each local site that act as clients of the remote sites using a store and forward mechanism. The implementation of these surrogate clients made it possible to book round-trip tickets to any of the regions from a single terminal. This design addressed the problem of frequent RTR quorum negotiations caused by network link drops and ensured that these would not affect local transactions.
The local facility defined in one location (say, Site B) includes a gateway server acting as a surrogate client that communicates with the reservation server at the remote site (say, Site C). For example, to make a round-trip reservation in one client request from Site B to Site C and return, the reservation agent enters the request with passenger ID, destination, and date. For the Site B to Site C trip, the destination is Site C, and for the Site C to Site B trip, the destination is Site B. This information is entered only at Site B. The reservation transaction is made for the Site-B-to-Site-C trip locally, and the transaction for the return trip goes first to the surrogate client for Site C.
The surrogate forwards the transaction to the real Site C server that makes the reservation in the local Site C database. The response for the successful transaction is then sent back to the surrogate client at Site B, which passes the confirmation back to the real client, completing the reservation. There are extensive recovery mechanisms at the surrogate client for transaction binding and transaction integrity. When transaction recovery fails, a locally developed store- and-forward mechanism ensures smooth functioning at each site.
The system configuration is illustrated in Figure A-1. For clarity, only three sites are shown, with a single set of connections. All other connections are in use, but not shown in the figure. Local connections are shown with single-headed arrows, though all are duplex; connections to other sites by network links are shown with double-headed arrows. Connections to the local databases are shown with solid lines. Reservations agents connect to frontends.
Figure A-1 Transportation Example Configuration

Currently the two transactions (the local and the remote) are not related to each other. The application has to make compensations in case of failure because RTR does not know that the second transaction is a child of the first. This ensures that reservations are booked without conflicts.
The emphasis in configurations is on availability; local sites keep running even when network links to other sites are not up. The disaster-tolerant capabilities of RTR and the system architecture made it easy to introduce site-disaster tolerance, when needed, virtually without redesign.
For a number of years, a group of banks relied on traditional open-outcry stock exchanges in several cities for their trades in stocks and other financial scrip (paper). These were three separate markets, with three floor-trading operations and three order books. In the country, financial institutions manage a major portion of international assets, and this traditional form of stock trading inhibited growth. When the unified stock exchange opened, they planned to integrate these diverse market operations into a robust and standards-compliant system, and to make possible electronic trading between financial institutions throughout the country.
The stock exchange already had an implementation based on OpenVMS, but this system could not easily be extended to deal with other trading environments and different financial certificates.
This example implements reliable broadcasts, database partitioning, and uses both standby and concurrent servers.
For their implementation using RTR, the stock exchange introduced a wholly electronic exchange that is a single market for all securities listed in the country, including equities, options, bonds, and futures. The hardware superstructure is a cluster of 64-bit Compaq AlphaServer systems with a network containing high-speed links with up to 120 gateway nodes connecting to over 1000 nodes at financial institutions throughout the country.
The stock exchange platform is based on the Compaq OpenVMS cluster technology, which achieves high performance and extraordinary availability by combining multiple systems into a fault-tolerant configuration with redundancy to avoid any single point of failure. The standard trading configuration is either high-performance AlphaStations or Sun workstations, and members with multi-seat operations such as banks use AlphaServer 4100 systems as local servers. Due to trading requirements that have strict time dependency, shadowing is not used. For example, it would not be acceptable for a trade to be recorded on the primary server at exactly 5:00:00 PM and at 5:00:01 PM on the shadow.
From their desks, traders enter orders with a few keystrokes on customized trading workstation software running UNIX that displays a graphical user interface. The stock exchange processes trades in order of entry, and within seconds:
Traders further have access to current and complete market data and can therefore more effectively monitor and manage risks. The implementation ensures that all members receive the same information at the same time, regardless of location, making fairness a major benefit of this electronic exchange. (In RTR itself, fairness is achieved using randomization, so that no trader would receive information first, all the time. Using RTR alone, no trader would be favored.)
The stock exchange applications work with RTR to match, execute, and confirm buy/sell orders, and dispatch confirmed trades to the portfolio management system of the securities clearing organization, and to the international settlement system run by participating banks.
The stock exchange designed their client/server frontend to interface with the administrative systems of most banks; one result of this is that members can automate back-room processing of trades and greatly reduce per-order handling expenses. Compaq server reliability, Compaq clustering capability, and cross- platform connectivity are critical to the success of this implementation. RTR client application software resides on frontends on the gateways that connect to routers on access nodes. The access nodes connect to a 12-node Compaq OpenVMS cluster where the RTR server application resides. The configuration is illustrated in Figure A-2. Only nine trader workstations are shown at each site, but many more are in the actual configuration. The frontends are gateways, and the routers are access points to the main system.
Figure A-2 Stock Exchange Example
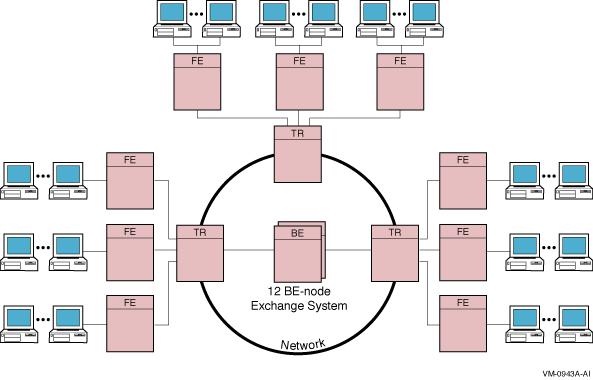
A further advantage of the RTR implementation is that the multivendor, multiprotocol 1000-node environment can be managed with only five staff people. This core staff can manage the network, the operating systems, and the applications with their own software that detects anomalies and alerts staff members by pagers and mobile computers. Using RTR also employs standard two-phase-commit processing, providing complete transaction integrity across the distributed systems. With this unique implementation, RTR swiftly became the underpinning of nationwide stock exchanges. RTR also provides ease of management, and with two-phase commit, makes it easier than previously to manage and control the databases.
The implementation using RTR also enables the stock exchange to provide innovative services and tools based on industry and technology standards, cooperate with other exchanges, and introduce new services without reengineering existing systems. For example, with RTR as the foundation of their systems, they plan an Oracle 7 data warehouse of statistical data off a central Oracle Rdb database, with Compaq Object Broker tools to offer users rapid and rich ad-hoc query capabilities. Part of a new implementation includes the disaster-tolerant Compaq Business Recovery Server solution and replication of its OpenVMS cluster configuration across two data centers, connected with the Compaq DEChub 900 GIGAswitch/ATM networking technology.
The unique cross-platform scalability of these systems further enables the stock exchange to select the right operating system for each purpose. Systems range from the central OpenVMS cluster, to frontends based on UNIX or Microsoft Windows NT. To support trader desktops with spreadsheets, an in-process implementation uses Windows NT with Microsoft Office to report trading results to the trader workstation.
Several years ago a large bank recognized the need to devise and deliver more convenient and efficient banking services to their customers. They understood both the expense of face-to-face transactions at a bank office and wanted to explore new ways to reduce these expenses and to improve customer convenience with 24-hour service, a level of service not available at a bank office or teller window.
This example shows use of application multithreading in an FDDI cluster.
The bank had confidence in the technology, and with RTR, was able to implement the world's first secure internet banking service. This enabled them to lower their costs as much as 80% and provide 24 x 365 convenience to their customers. They were additionally able to implement a global messaging backbone that links 20,000 users on a broad range of popular mail systems to a common directory service.
With the bank's electronic banking service, treasurers and CEOs manage corporate finances, and individuals manage their own personal finances, from the convenience of their office or home. Private customers use a PC- based software package to access their account information, pay bills, download or print statements, and initiate transactions to any bank in the country, and to some foreign banks.
For commercial customers, the bank developed software interfaces that provide import and export links between popular business financial packages and the electronic banking system. Customers can use their own accounting system software and establish a seamless flow of data from their bank account to their company's financial system and back again.
The bank developed its customized internet applications based on Microsoft Internet Information Server (IIS) and RTR, using Compaq Prioris servers running Windows NT as frontend web servers. The client application runs on a secure HTTP system using 128-bit encryption and employs CGI scripts in conjunction with RTR client code. All web transactions are routed by RTR through firewalls to the electronic banking cluster running OpenVMS. The IIS environment enabled rapid initial deployment and contains a full set of management tools that help ensure simple, low-cost operation. The service handles 8,000 to 12,000 users per day and is growing rapidly. Figure A-3 illustrates the deployment of this banking system.
Figure A-3 Banking Example Configuration
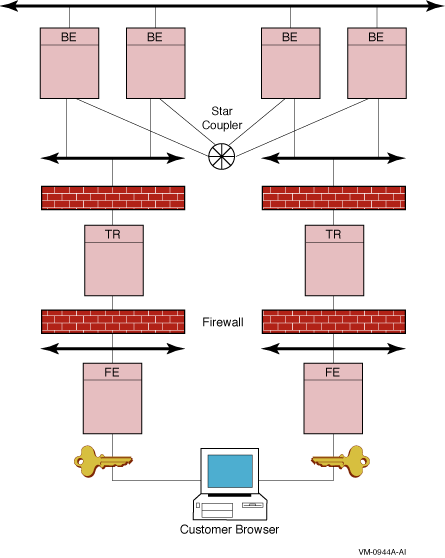
The RTR failure-tolerant, transaction-messaging middleware is the heart of the internet banking service. Data is shadowed at the transactional level, not at the disk level, so that even with a network failure, in-progress transactions are completed with integrity in the transactional shadow environment.
The banking application takes full advantage of the multiplatform support provided by RTR; it achieves seamless transaction-processing flow across the backend OpenVMS clusters and secure web servers based on Windows NT frontends. With RTR scalability, backends can be added as volume increases, load can be balanced across systems, and maintenance can be performed during full operation.
For the electronic banking application, the bank used RTR in conjunction with an Oracle Rdb database. The security and high availability of RTR and OpenVMS clusters provided what was needed for this sensitive financial application, which supports more than a quarter million customer accounts, and up to 38 million transactions a month with a total value of U.S. $300 to $400 million.
The bank's electronic banking cluster is distributed across two data centers located five miles apart and uses Compaq GIGAswitch/FDDI systems for ultra-fast throughput and instant failover across sites without data loss. The application also provides redundancy into many elements of the cluster. For example, each data center has two or more computer systems linked by dual GIGAswitch systems to multiple FDDI rings, and the cluster is also connected by an Ethernet link to the LAN at bank headquarters.
The cluster additionally contains 64-bit Very Large Memory (VLM) capabilities for its Oracle database ; this has increased database performance by storing frequently used files and data in system memory rather than on disk. All systems in the electronic banking cluster share access to 350 gigabytes of SCSI-based disks. Storage is not directly connected to the cluster CPUs, but connected to the network through the FDDI backbone. Thus, if a CPU goes down, storage survives, and is accessible to other systems in the cluster.
The multi-operating system cluster is very economical to run, supported by a small staff of four system managers who handle all the electronic banking systems. Using clusters and RTR enables the bank to provide very high levels of service with a very lean staff.
| Previous | Next | Contents | Index |