Compaq ACMS for OpenVMS
Concepts and Design
Guidelines
6.3.3 Working in a Task or a Step Procedure
This section offers guidelines about choosing where to do work that
could be initiated either from a task or a step procedure. (See
Chapter 7 and Compaq ACMS for OpenVMS Writing Server Procedures for more information about step
procedures.)
Use step procedures for:
- Database I/0
Make database transactions as short as possible
and include only the work appropriate to the procedure server. For
example, if the procedure is in a server used for updates, do only
database I/O required for updates. Move all other I/O to another
procedure server, such as one used for reads.
- Calculations
Be careful not to do intensive calculations in a
procedure server that has limited server processes that also have I/O
procedures. You do not want tasks waiting to do updates while another
task does calculations.
- File opens or database binds
By moving this work to a server initialization procedure, you can
save the time that it takes to do this work when a task first calls a
step procedure.
Use tasks for:
- Flow control
It is usually preferable to have conditional logic
in the task definition rather than in the procedure. (See
Section 6.2.2.) However, sometimes conditional logic belongs in the
procedure:
- Complex business logic usually belongs in the procedure, not the
task.
-
Conditional logic requiring array addressing belongs in the procedure,
because the task does not allow for array addressing.
- If logic internal to a procedure can preclude the need to return to
the task definition, avoid the resulting reinvocation of the procedure
by keeping the logic in the procedure.
- Terminal I/O
When a step procedure does terminal I/O, the task ties up the
procedure for the lengthiest part of the task's work. Also, the task
cannot be distributed. The only reason to do terminal I/O in a
procedure is if you must have access to some capability outside ACMS
that requires terminal I/O.
Some types of work can be done either in the step procedure or the task
depending on circumstances:
- Data moves
Handle most data moves in the step procedure.
However, do not have a task call a step procedure just to do a simple
data move. Instead, use th MOVE statement in the task definition.
However, a step procedure must handle array element manipulation.
-
Data validation
You can put data validation in either the form or
the step procedure. The method you use can affect the performance and
maintainability of the application.
6.4 Designing and Using Workspaces
A workspace is a buffer used to pass data between the form and the
task, and between the task and the processing steps. A workspace can
also hold application parameters and status information. Workspaces are
passed to step procedures and tasks as parameters. You must define the
workspace structure and store in CDO or DMU format.
6.4.1 Workspace Size
In the execution of an application, workspaces pass from the Command
Process for exchange steps to the server process for processing steps,
and back throughout the execution of a task. Information for use by
these processes is stored within workspaces.
Part of the cost of communication across the network lies in the size
of these workspaces. Consider this network cost when you design
workspaces. Workspaces have to be stored in global sections or made up
into packets to be passed over the network in a distributed
transaction. Consider the total size of all the workspaces you are
passing to the form or processing step.
Note that passing one workspace of 500 bytes is less expensive than
passing 5 workspaces of 100 bytes each, providing all 500 bytes are
required. Avoid passing unnecessary data, however large or small the
workspace you use. Passing a 2250-byte workspace that requires three
network packets is not unduly costly, if you intend to use most or all
of the data in the workspace. Passing 250 bytes that require one
network packet is wasteful, if you do not need the data.
6.4.2 Workspace Structure
You can design your workspaces:
- To match exactly your database or file record descriptions
A
workspace containing exactly the same fields as a relation in an Rdb
database is easy to maintain. However, it may use more memory than
necessary and may pass more data then necessary.
- To contain only the data necessary to do the work at hand
Such
a workspace minimizes the use of memory and passes only the data
needed. It may be more difficult to maintain.
Note that no single workspace can be larger than 65,536 bytes. The
total size of all workspaces (including system workspaces) cannot
exceed 65,536 bytes for a task instance. This effectively limits the
size of a single workspace to 65,536 bytes, minus the size of all ACMS
system workspaces, because all system workspaces are always present
(for example, the system workspace size is 519 bytes in ACMS Version
4.2).
6.4.3 Using Task, Group, or User Workspaces
There are three types of workspaces:
- Task workspace
A task workspace stores database records and control information
required by the task. ACMS system workspaces are a special type of task
workspace, defined by ACMS.
- Group workspace
Group workspaces store relatively static application-wide
information (such as the interest rate for a financial application).
- User workspace
User workspaces store static user information (such as a user
security profile) or information specific to the user that changes
during the session (such as an accounting of the kind of work done by
the user).
Use task workspaces whenever possible. Task workspaces have the lowest
CPU and memory costs. If you need group and user workspaces, use them
for relatively static information. Table 6-2 summarizes the
features of each type of workspace.
Table 6-2 Workspace Types
| Characteristic |
Task |
Group |
User |
|
Availability
|
For the duration of the task instance
|
For as long as the application is started (active)
|
For the user's ACMS session within the application
|
|
Purpose
|
Passes information between:
- Steps in a task
- Exchange steps and forms
- Processing steps and procedure servers
- Parent tasks and called tasks
|
Stores relatively static information required by many tasks in a group
|
Stores user-specific information
|
|
CPU cost
|
Copied once from the .TDB at task start, not copied back at
taskcompletion.
|
Copied from the permanent workspace pool to the temporary pool at task
start. Copied back to the permanent workspace pool only if accessed for
update by the task.
|
Copied from the permanent workspace pool to the temporary pool at task
start. Copied back to the permanent workspace pool only if accessed for
update by the task.
|
|
Memory cost
|
Exists only in the temporary workspace pool
|
One copy in the permanent pool and one copy for each task referring to
the workspace in the temporary pool
|
One copy for each user in the permanent workspace pool, one copy for
each task instance referring to the workspace for each user in the
temporary workspace pool
|
6.4.4 Declaring and Referring to Workspaces
You can declare a workspace in the task definition using the WORKSPACE
IS clause. Or you can declare the workspace in the task group
definition with WORKSPACE IS and then refer to the workspace in the
task definition with the USE WORKSPACE clause. It is usually more
efficient to declare the workspaces in the task group definition rather
than in the task definition. The difference s in these two approaches
for each type of workspace are as follows:
-
Task workspaces
If you declare a workspace in the task definition,
at the task group build, ADU stores in the .TDB file one copy of the
workspace each time it is declared in a task. When you declare a
workspace in the task group definition and refer to it in the task
definition, the task refers to a single definition of the workspace
that exists in the .TDB file.
Therefore, declaring the workspace in
the task group definition rather than the task definition decreases
.TDB size (resulting in a decrease in the EXC and server process
working set requirements) and improves run-time performance. For
maintainability, define workspaces in the group and refer to them in
the task definitions, even if the workspace is used in only one task.
- Group workspaces
If you declare a group workspace in the task definition, there is
one copy of the workspace in the permanent workspace pool for each
task. In effect, the workspace becomes task-specific rather than being
shared by all tasks. However, all users running a specific task see the
same copy.
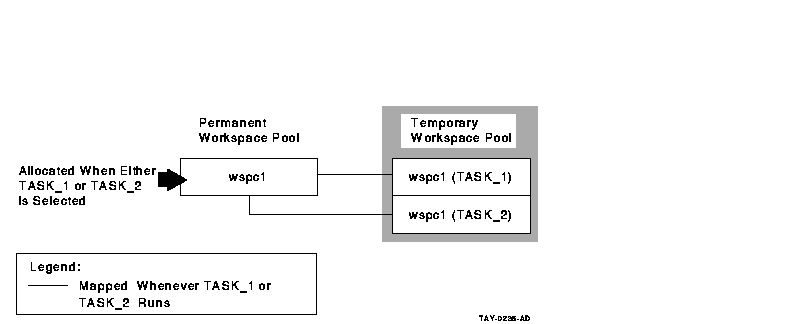
If you declare a group workspace in the task group, each
task uses a single copy of the workspace in the permanent workspace
pool. As a result, all tasks referring to the workspace see the same
copy.
Figure 6-3 and Figure 6-4 illustrate the differences
between declaring and referring to group workspaces.
Figure 6-3 Declaring Group Workspaces in the Task
Definition
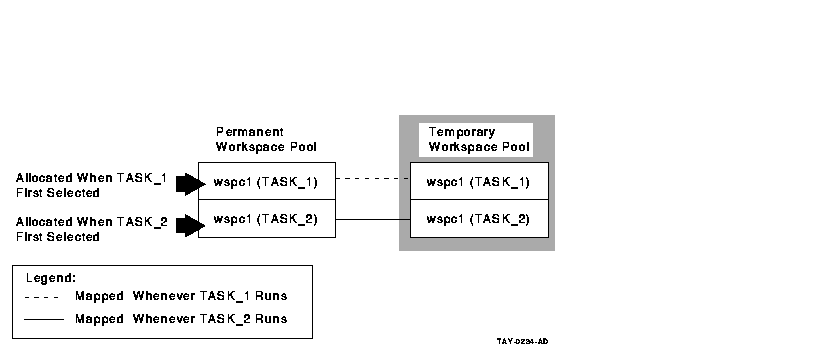
Figure 6-4 Declaring Group Workspaces in the Task Group
Definition
- User workspaces
If you declare a user workspace in multiple task definitions, the
same user will have multiple copies of the workspace in the permanent
workspace pool. In effect, the workspace becomes both user-specific and
task-specific rather than just user-specific.
If you declare a user
workspace in the task group definition, each user has just one copy of
that workspace in the permanent workspace pool. As a result, ACMS
maintains a single copy of the workspace for each user. This copy is
used by all tasks selected by a particular user. For example, use this
method to store user profile information in a single workspace.
Figure 6-5 and Figure 6-6 illustrate the differences between
declaring user workspaces in the task, or declaring them in the task
group and referring to them in the task.
Figure 6-5 Declaring User Workspaces in the Task
Definition
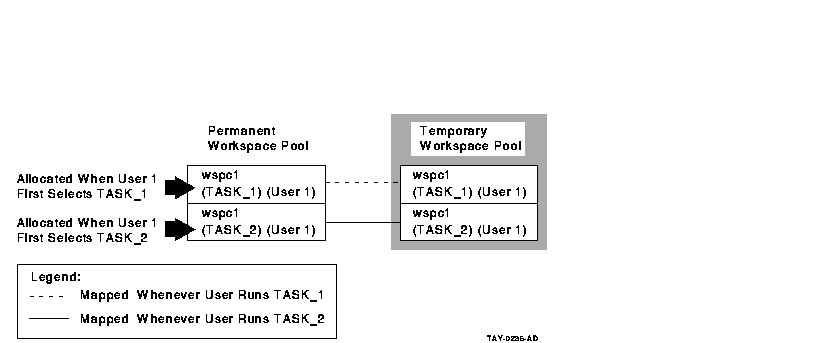
Figure 6-6 Declaring User Workspaces in the Task Group
Definition
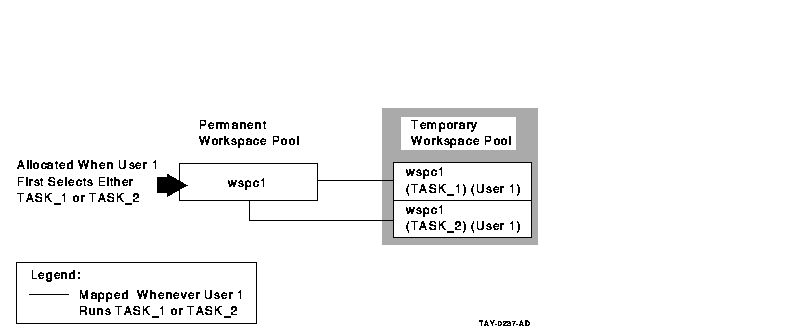
The AVERTZ application declares all workspaces in the task group
definition, and refers to them as needed in the task definition.
6.4.5 Specifying Access for Workspaces
ACMS allows a called task to accept arguments in the form of task
workspaces. User-written agents or tasks may pass workspaces to other
tasks. You can specify READ, WRITE, or MODIFY access for each workspace
you include in a TASK ARGUMENT clause. Use MODIFY for passing and
returning data, READ for passing data, and WRITE for returning data.
Specifying READ access on task workspace arguments can provide
performance benefits, since ACMS does not have to return the workspace
to the parent task or agent when the called task completes.
In creating workspaces for task calls, bear in mind the trade-off
between workspace size and the various access types. For large
workspaces, it is more efficient to pass data using a READ workspace
and return data using a WRITE workspace than it is to pass and return
data in a single MODIFY workspace. Conversely, it is more efficient to
pass a single MODIFY workspace containing a small amount of data than
it is to pass several separate READ and WRITE workspaces. The default
is MODIFY.
The called tasks in the AVERTZ application are the Get Reservation task
and the Complete Checkout task. Both tasks receive data from a parent
task in the VR_SENDCTRL_WKSP workspace. However, neither task needs to
return any data to the parent task in this workspace. Therefore, the
VR_SENDCTRL_WKSP workspace is defined in both tasks as a task argument
workspace with READ access. Both tasks also receive data from a parent
task in the VR_CONTROL_WKSP workspace. Also, both tasks return
information to the parent task in this workspace. Therefore, the
VR_CONTROL_WKSP workspace is defined in both tasks as a task argument
workspace with MODIFY access.
The Get Reservation task returns information to the parent task in the
VR_RESERVATIONS_WKSP workspace after reading reservation information
from the database. The VR_RESERVATIONS_WKSP workspace is defined as a
task argument workspace with WRITE access in the Get Reservation task,
because the task does not receive any data from the parent task in this
workspace. However, the Complete Checkout task also receives data from
the parent task in the VR_RESERVATIONS_WKSP workspace, in addition to
returning information to the parent task in this workspace. Therefore,
the VR_RESERVATIONS_WKSP workspace is defined as a task argument with
MODIFY access in the Complete Checkout task.
See Compaq ACMS for OpenVMS Writing Applications for a complete description of workspaces.
6.5 Using Task Queuing
ACMS typically does interactive processing of the tasks in your
application, but you may find that certain tasks have requirements that
you can meet through the use of task queues.
These requirements include:
- Data capture and deferred processing of data
Queue the data
with a task name in an ACMS task queue and process it at a later time
when the demand for resources is less, if the application has the
following requirements:
- Needs to collect a large amount of data in a short time
- Does not need to process the data immediately
- Needs to allow the users to continue without delay
For example, an application has hundreds of time cards that must be
processed in a very short amount of time during a shift change. In this
type of application, processing each data item immediately has adverse
effects on the performance of the system, so it is useful to capture
the data and store it for future processing. This type of processing is
known as desynchronized processing, because the data capture
and the data processing are not synchronized.
- High application availability
Queuing is an important feature in distributed environments that
allow users to continue working even if an application is not
available. For example, an application uses a front-end node for data
entry and queues these tasks for processing by a back-end node. When
both nodes are up, the back-end node processes the queued tasks at
regular intervals. If the back-end node goes down, the front-end node
continues to queue the tasks, thus providing uninterrupted access to
the application for terminal users entering data on the front end.
These tasks remain queued until the back-end node becomes available and
the front-end node can submit them.
- Transaction persistence
If a system failure interrupts the processing of a queued task, the
queuing facilities continue to dequeue and submit that task until the
task succeeds. If the task fails for a different reason and cannot be
resubmitted, ACMS writes the queue entry to an error queue, where it
can be subsequently retrieved and processed by the application, based
on the error status.
For these and other similar requirements, you can use the ACMS queuing
facility to capture and initiate the tasks in your ACMS application.
Combine queuing with normal processing within a task when the data does
not need to be synchronized. For example, in a task that ends with an
update of multiple records, you can put the final processing step into
a queued task; all the preceding steps can be interactive, even if they
included write or modify operations. See the Compaq ACMS for OpenVMS Writing Applications for details
about implementing a queued task, as well as a queued task example
based on the AVERTZ application. The AVERTZ company offers a
quick-checkin service for its customers. During peak periods, when many
cars are being returned at the same time, customers can enter into the
system their reservation information and the odometer reading from the
car. The application stores the checkin information as a queued task
that is processed at a later, less busy time. Section 6.6 describes
the use of a queued task within a distributed transaction.
6.6 Designing Distributed Transactions
A business function usually involves several database operations. By
including a set of operations within the bounds of a transaction, you
are instructing ACMS to ensure that all updates are performed as an
atomic transaction. ACMS uses the DECdtm services to ensure the
integrity of a distributed transaction. Chapter 4 describes how to
identify transactions for your business functions, including
distributed transactions. This section offers details about the design
of distributed transactions.
6.6.1 Locating Transaction Control
A distributed transaction must start and end in the same part of the
application. You can start and stop a distributed transaction in a:
- Task
Declaring the distributed transaction in the task definition
ensures full ACMS functionality. For example, you can use the Oracle
Trace
software to track the distributed transaction if the transaction starts
on a block step or a processing step. Also, if you always declare the
distributed transaction in the task definition, you maintain consistent
task definitions. Declaring the distributed transaction in the task
definition contributes to ease of maintenance, because control of the
transaction remains with the task and is insulated from changes to the
procedure code. Within the task definition, you declare the distributed
transaction either at the:
- Block step
If the task has more than one processing step participating in the
distributed transaction, the transaction must start on the block step.
- Processing step
If only a single processing step participates in a distributed
transaction, you can start the distributed transaction on the
processing step. This method offers the advantage of allowing the use
of one-phase commit if only a single local resource manager is being
used. In such a case, two-phase commit is not required. For example,
consider a banking transaction that consists of debiting of one account
and crediting another. If the transaction involves the accounts of two
patrons of the same branch (and the data is stored within the same
resource manager), the local transaction requires only one-phase
commit. If the transaction involves the accounts of patrons of
different branches (and the data is in different resource managers),
the two-phase commit functionality of a distributed transaction is
required.
If you start the transaction at the block step, the
transaction starts in a different process (the Application Execution
Controller) than the one in which the resource manager is executing
(the server process). Therefore, you assume the full overhead of two
phase commit. If you start the transaction at the processing step in
the task, the transaction starts in the server process. By using
conditional logic in your step procedure, you can make use of one-phase
commit where appropriate.
- Step procedure
Declaring the distributed transaction in a step procedure makes
transaction retries easier to handle. However, the transaction is not
under the control of ACMS. Therefore, you must code all the DECdtm
service calls and assume responsibility for the integrity of the
transaction. Also, you lose some ACMS functionality, such as the use of
Oracle Trace.
- Agent
Using a distributed transaction started in an agent, you can
coordinate the database modifications made by a task with modifications
made to a local database or file by the agent. For example, the ACMS
Queued Task Initiator (QTI) uses a distributed transaction to
coordinate the removal of a queued task element from an ACMS task queue
with the modifications made to a database by the queued task instance.
You can also use distributed transactions started in an agent in the
design of a highly-available system using a fault-tolerant machine as a
front-end system. For example, an agent on a front-end system collects
information that is processed in a database by a system on a back-end
VMScluster. After collecting the appropriate information, the agent
starts a distributed transaction and then calls a task on a back-end
system as part of the distributed transaction. When the task completes,
the agents ends the distributed transaction. If the transaction commits
successfully, the agent can process the next task. If the transaction
aborts, perhaps because the back-end system fails, then the agent can
retry the operation by calling the same task on a different system in
the back-end VMScluster. By calling the task in a distributed
transaction, the agents knows with absolute certainty whether or not
the database operations performed by the task on the back-end system
were successful, or if they failed and need to be retried.
6.6.2 Choosing an Access Method to Remote Data
You have access to remote data included in a distributed transaction by
using:
Figure 6-9 Using Rdb Remote Access for a Distributed
Transaction
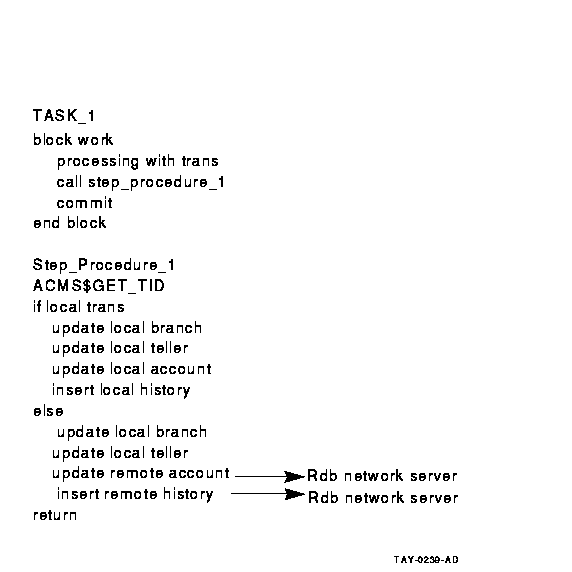
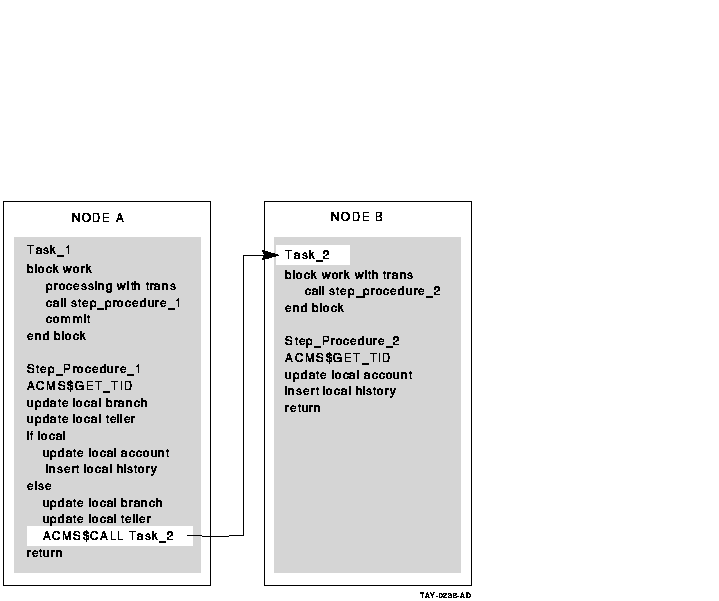
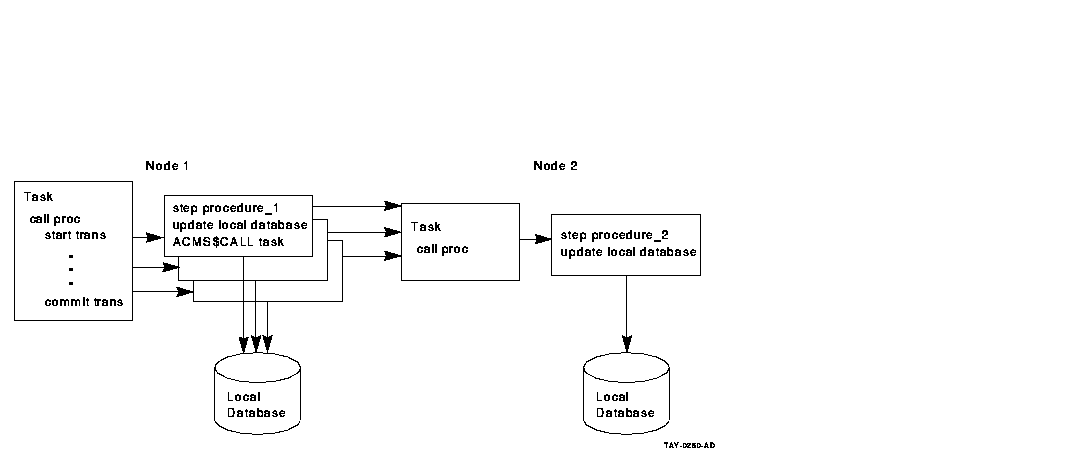
Figure 6-8 and Figure 6-10 illustrate the advantages of using the
step procedure as an agent. In the example illustrated by
Figure 6-8, using the ACMS SI:
- Minimizes server processes and lock contention on the remote node
In Figure 6-8, the ACMS$CALL in the step procedure on Node 1
calls the task on Node 2. The remote task on Node 2 uses the same
server process to access the database as the local tasks on Node 2. In
Figure 6-10, each server process on Node 1 requires an Rdb server
process on Node 2, in addition to the ACMS procedure server processes
(not shown). These additional processes lead to increased contention in
the database.
- Minimizes network traffic
ACMS$CALL results in a single
network transmission in each direction. Remote updates require network
transmissions for each database verb. The result can be multiple
network transmissions for each update.