| Previous | Contents | Index |
This chapter discusses the following topics related to improving run-time performance of Compaq Fortran programs:
Before you attempt to analyze and improve program performance, you should:
To ensure that your software development environment can significantly improve the run-time performance of your applications, obtain and install the following optional software products:
$ Kfort /fkapargs=(verbose) for_cal.f90 |
About system-wide tuning and suggestions for other performance
enhancements on OpenVMS systems, see the OpenVMS System Manager's Manual: Tuning, Monitoring, and Complex Systems.
5.1.2 Compile Using Multiple Source Files and Appropriate FORTRAN Qualifiers
During the earlier stages of program development, you can use incremental compilation with minimal optimization. For example:
$ FORTRAN /OPTIMIZE=LEVEL=1 SUB2 $ FORTRAN /OPTIMIZE=LEVEL=1 SUB3 $ FORTRAN /OPTIMIZE=LEVEL=1 MAIN $ LINK MAIN SUB2 SUB3 |
During the later stages of program development, you should compile multiple source files together and use an optimization level of at least /OPTIMIZE=LEVEL=4 on the FORTRAN command line to allow more interprocedure optimizations to occur. For instance, the following command compiles all three source files together using the default level of optimization (/OPTIMIZE=LEVEL=4):
$ FORTRAN MAIN.F90+SUB2.F90+SUB3.F90 $ LINK MAIN.OBJ |
Compiling multiple source files using the plus sign (+) separator lets the compiler examine more code for possible optimizations, which results in:
When compiling all source files together is not feasible (such as for very large programs), consider compiling source files containing related routines together with multiple FORTRAN commands, rather than compiling source files individually.
Table 5-1 shows FORTRAN qualifiers that can improve performance. Most of these qualifiers do not affect the accuracy of the results, while others improve run-time performance but can change some numeric results.
Compaq Fortran performs certain optimizations unless you specify the appropriate FORTRAN command qualifiers. Additional optimizations can be enabled or disabled using FORTRAN command qualifiers.
Table 5-1 lists the FORTRAN qualifiers that can directly improve run-time performance.
| Qualifier Names | Description and For More Information |
|---|---|
| /ALIGNMENT= keyword |
Controls whether padding bytes are added between data items within
common blocks, derived-type data, and Compaq Fortran 77 record
structures to make the data items naturally aligned.
See Section 5.3. |
| /ASSUME=NOACCURACY_SENSITIVE |
Allows the compiler to reorder code based on algebraic identities to
improve performance, enabling certain optimizations. The numeric
results can be slightly different from the default
(/ASSUME=ACCURACY_SENSITIVE) because of the way intermediate results
are rounded. This slight difference in numeric results is acceptable to
most programs.
See Section 5.8.8. |
| /ARCHITECTURE= keyword |
Specifies the type of Alpha architecture code instructions to be
generated for the program unit being compiled; it uses the same options
(keywords) as used by the /OPTIMIZE=TUNE qualifier (which controls
instruction scheduling).
See Section 2.3.6. |
| /FAST |
Sets the following performance-related qualifiers:
/ALIGNMENT=(COMMONS=NATURAL, RECORDS=NATURAL, SEQUENCE) /ARCHITECTURE=HOST, /ASSUME=NOACCURACY_SENSITIVE, /MATH_LIBRARY=FAST, and /OPTIMIZE=TUNE=HOST. See Section 5.8.3. |
| /INTEGER_SIZE= nn |
Controls the sizes of INTEGER and LOGICAL declarations without a kind
parameter.
See Section 2.3.25. |
| /MATH_LIBRARY=FAST |
Requests the use of certain math library routines (used by intrinsic
functions) that provide faster speed. Using this option causes a slight
loss of accuracy and provides less reliable arithmetic exception
checking to get significant performance improvements in those functions.
See Section 2.3.29. |
| /OPTIMIZE=INLINE= keyword |
Specifies the types of procedures to be inlined. If omitted,
/OPTIMIZE=LEVEL=
n determines the types of procedures inlined. Certain INLINE
keywords are relevant only for /OPTIMIZE=LEVEL=1 or higher.
See Section 2.3.34. |
| /OPTIMIZE=LEVEL= n (n = 0 to 5) |
Controls the optimization level and thus the types of optimization
performed. The default optimization level is /OPTIMIZE=LEVEL=4. Use
/OPTIMIZE=LEVEL=5 to activate loop transformation optimizations.
See Section 5.7. |
| /OPTIMIZE=LOOPS |
Activates a group of loop transformation optimizations (a subset of
/OPTIMIZE=LEVEL=5).
See Section 5.7. |
| /OPTIMIZE=PIPELINE |
Activates the software pipelining optimization (a subset of
/OPTIMIZE=LEVEL=4).
See Section 5.7. |
| /OPTIMIZE=TUNE= keyword |
Specifies the target processor generation (chip) architecture on which
the program will be run, allowing the optimizer to make decisions about
instruction tuning optimizations needed to create the most efficient
code. Keywords allow specifying one particular Alpha processor
generation type, multiple processor generation types, or the processor
generation type currently in use during compilation. Regardless of the
setting of /OPTIMIZE=TUNE=
xxxx, the generated code will run correctly on all
implementations of the Alpha architecture.
See Section 5.8.6. |
| /OPTIMIZE=UNROLL= n |
Specifies the number of times a loop is unrolled (
n) when specified with optimization level /OPTIMIZE=LEVEL=3 or
higher. If you omit /OPTIMIZE=UNROLL=
n, the optimizer determines how many times loops are unrolled.
See Section 5.7.4.1. |
| /REENTRANCY |
Specifies whether code generated for the main program and any Fortran
procedures it calls will be relying on threaded or asynchronous
reentrancy.
See Section 2.3.38. |
Table 5-2 lists qualifiers that can slow program performance. Some applications that require floating-point exception handling or rounding need to use the /IEEE_MODE and /ROUNDING_MODE qualifiers. Other applications might need to use the /ASSUME=DUMMY_ALIASES qualifier for compatibility reasons. Other qualifiers listed in Table 5-2 are primarily for troubleshooting or debugging purposes.
| Qualifier Names | Description and For More Information |
|---|---|
| /ASSUME=DUMMY_ALIASES |
Forces the compiler to assume that dummy (formal) arguments to
procedures share memory locations with other dummy arguments or with
variables shared through use association, host association, or common
block use. These program semantics slow performance, so you should
specify /ASSUME=DUMMY_ALIASES only for the called subprograms that
depend on such aliases.
The use of dummy aliases violates the FORTRAN-77, Fortran 90, and Fortran 95 standards but occurs in some older programs. See Section 5.8.9. |
| /CHECK[=keyword] |
Generates extra code for various types of checking at run time. This
increases the size of the executable image, but may be needed for
certain programs to handle arithmetic exceptions. Avoid using
/CHECK=ALL except for debugging purposes.
See Section 2.3.11. |
| /IEEE_MODE= keyword other than /IEEE_MODE=FAST |
Using /IEEE_MODE=UNDERFLOW_TO_ZERO slows program execution (like
/SYNCHRONOUS_EXCEPTIONS). Using /IEEE_MODE=DENORM_RESULTS slows program
execution even more than /IEEE_MODE=UNDERFLOW_TO_ZERO.
See Section 2.3.23. |
| /ROUNDING_MODE=DYNAMIC |
Certain rounding modes and changing the rounding mode can slow program
execution slightly.
See Section 2.3.39. |
| /SYNCHRONOUS_EXCEPTIONS |
Generates extra code to associate an arithmetic exception with the
instruction that causes it, slowing program execution. Use this
qualifier only when troubleshooting, such as when identifying the
source of an exception.
See Section 2.3.45. |
|
/OPTIMIZE=LEVEL=0,
/OPTIMIZE=LEVEL=1, /OPTIMIZE=LEVEL=2, /OPTIMIZE=LEVEL=3 |
Minimizes the optimization level (and types of optimizations). Use
during the early stages of program development or when you will use the
debugger.
See Section 2.3.34 and Section 5.7. |
| /OPTIMIZE=INLINE=NONE, /OPTIMIZE=INLINE=MANUAL |
Minimizes the types of inlining done by the optimizer. Use such
qualifiers only during the early stages of program development. The
type of inlining optimizations are also controlled by the
/OPTIMIZE=LEVEL qualifier.
See Section 2.3.34 and Section 5.7. |
Certain DCL commands and system tuning can improve run-time performance:
$ DEFINE /USER FOR006 RESULTS.LIS $ RUN MYPROG $ TYPE/PAGE RESULTS.LIS |
About system-wide tuning and suggestions for other performance
enhancements on OpenVMS systems, see the OpenVMS System Manager's Manual: Tuning, Monitoring, and Complex Systems.
5.2 Analyze Program Performance
This section describes how you can:
Before you analyze program performance, make sure any errors you might
have encountered during the early stages of program development have
been corrected.
5.2.1 Measuring Performance Using LIB$xxxx_TIMER Routines or Command Procedures
You can use LIB$xxxx_TIMER routines or an equivalent DCL command procedure to measure program performance.
Using the LIB$xxxx_TIMER routines allows you to display timing and related statistics at various points in the program as well as at program completion, including elapsed time, actual CPU time, buffered I/O, direct I/O, and page faults. If needed, you can use other routines or system services to obtain and report other information.
You can measure performance for the entire program by using a DCL
command procedure (see Section 5.2.1.2). Although using a DCL command
procedure does not report statistics at various points in the program,
it can provide information for the entire program similar to that
provided by the LIB$xxxx_TIMER routines.
5.2.1.1 The LIB$xxxx_TIMER Routines
Use the following routines together to provide information about program performance at various points in your program:
Run program timings when other users are not active. Your timing results can be affected by one or more CPU-intensive processes also running while doing your timings.
Try to run the program under the same conditions each time to provide the most accurate results, especially when comparing execution times of a previous version of the same program. Use the same CPU system (model, amount of memory, version of the operating system, and so on) if possible.
If you do need to change systems, you should measure the time using the same version of the program on both systems, so you know each system's effect on your timings.
For programs that run for less than a few seconds, repeat the timings several times to ensure that the results are not misleading. Overhead functions might influence short timings considerably.
You can use the LIB$SHOW_TIMER (or LIB$STAT_TIMER) routine to return elapsed time, CPU time, buffered I/O, direct I/O, and page faults:
The Compaq Fortran program shown in Example 5-1 reports timings for the three different sections of the main program, including accumulative statistics (for a scalar program).
| Example 5-1 Measuring Program Performance Using LIB$SHOW_TIMER and LIB$INIT_TIMER |
|---|
! Example use of LIB$SHOW_TIMER to time a Compaq Fortran program
PROGRAM TIMER
INTEGER TIMER_CONTEXT
DATA TIMER_CONTEXT /0/
! Initialize default timer stats to 0
CALL LIB$INIT_TIMER
! Sample first section of code to be timed
DO I=1,100
CALL MOM
ENDDO
! Display stats
TYPE *,'Stats for first section'
CALL LIB$SHOW_TIMER
! Zero second timer context
CALL LIB$INIT_TIMER (TIMER_CONTEXT)
! Sample second section of code to be timed
DO I=1,1000
CALL MOM
ENDDO
! Display stats
TYPE *,'Stats for second section'
CALL LIB$SHOW_TIMER (TIMER_CONTEXT)
TYPE *,'Accumulated stats for two sections'
CALL LIB$SHOW_TIMER
! Re-Initialize second timer stats to 0
CALL LIB$INIT_TIMER (TIMER_CONTEXT)
! Sample Third section of code to be timed
DO I=1,1000
CALL MOM
ENDDO
! Display stats
TYPE *,'Stats for third section'
CALL LIB$SHOW_TIMER (TIMER_CONTEXT)
TYPE *,'Accumulated stats for all sections'
CALL LIB$SHOW_TIMER
END PROGRAM TIMER
! Sample subroutine performs enough processing so times aren't all 0.0
SUBROUTINE MOM
COMMON BOO(10000)
DOUBLE PRECISION BOO
BOO = 0.5 ! Initialize all array elements to 0.5
DO I=2,10000
BOO(I) = 4.0+(BOO(I-1)+1)*BOO(I)*COSD(BOO(I-1)+30.0)
BOO(I-1) = SIND(BOO(I)**2)
ENDDO
RETURN
END SUBROUTINE MOM
|
The LIB$xxxx_TIMER routines use a single default time when called without an argument. When you call LIB$xxxx_TIMER routines with an INTEGER argument whose initial value is 0 (zero), you enable use of multiple timers.
The LIB$INIT_TIMER routine must be called at the start of the timing. It can be called again at any time to reset (set to zero) the values.
In Example 5-1, LIB$INIT_TIMER is:
The LIB$SHOW_TIMER routine displays the timer values saved by LIB$INIT_TIMER to SYS$OUTPUT (or to a specified routine). Your program must call LIB$INIT_TIMER before LIB$SHOW_TIMER at least once (to start the timing).
Like LIB$INIT_TIMER:
The free-format source file, TIMER.F90, might be compiled and linked as follows:
$ FORTRAN/FLOAT=IEEE_FLOAT TIMER $ LINK TIMER |
When the program is run (on a low-end Alpha system), it displays timing statistics for each section of the program as well as accumulated statistics:
$ RUN TIMER Stats for first section ELAPSED: 0 00:00:02.36 CPU: 0:00:02.21 BUFIO: 1 DIRIO: 0 FAULTS: 23 Stats for second section ELAPSED: 0 00:00:22.31 CPU: 0:00:22.09 BUFIO: 1 DIRIO: 0 FAULTS: 0 Accumulated stats for two sections ELAPSED: 0 00:00:24.68 CPU: 0:00:24.30 BUFIO: 5 DIRIO: 0 FAULTS: 27 Stats for third section ELAPSED: 0 00:00:22.24 CPU: 0:00:21.98 BUFIO: 1 DIRIO: 0 FAULTS: 0 Accumulated stats for all sections ELAPSED: 0 00:00:46.92 CPU: 0:00:46.28 BUFIO: 9 DIRIO: 0 FAULTS: 27 $ |
You might:
Instead of the LIB$xxxx_TIMER routines (specific to the OpenVMS operating system), you might consider modifying the program to call other routines within the program to measure execution time (but not obtain other process information). For example, you might use Compaq Fortran intrinsic procedures, such as SYSTEM_CLOCK, DATE_AND_TIME, and TIME (see the Compaq Fortran Language Reference Manual).
Some of the information obtained by using the LIB$xxxx_TIMER routines can be obtained using a command procedure. You should be aware of the following:
Before using a command procedure to measure performance, define a foreign symbol that runs the program to be measured in a subprocess. In the following example, the name of the command procedure is TIMER:
$ TIMER :== SPAWN /WAIT /NOLOG @SYS$LOGIN:TIMER |
The command procedure shown in Example 5-2 uses the F$GETJPI lexical function to measure performance statistics and the F$FAO lexical function to report the statistics. Each output line is saved as a logical name, which can be saved by the parent process if needed.
| Example 5-2 Command Procedure that Measures Program Performance |
|---|
$ verify = 'f$verify(0)
$
$! Get initial values for stats (this removes SPAWN overhead or the current
$! process values).
$
$ bio1 = f$getjpi (0, "BUFIO")
$ dio1 = f$getjpi (0, "DIRIO")
$ pgf1 = f$getjpi (0, "PAGEFLTS")
$ vip1 = f$getjpi (0, "VIRTPEAK")
$ wsp1 = f$getjpi (0, "WSPEAK")
$ dsk1 = f$getdvi ("sys$disk:","OPCNT")
$ tim1 = f$time ()
$
$ set noon
$ tik1 = f$getjpi (0, "CPUTIM")
$ set noverify
$
$! User command being timed:
$
$ 'p1' 'p2' 'p3' 'p4' 'p5' 'p6' 'p7' 'p8'
$
$ tik2 = f$getjpi (0, "CPUTIM")
$
$ bio2 = f$getjpi (0, "BUFIO")
$ dio2 = f$getjpi (0, "DIRIO")
$ pgf2 = f$getjpi (0, "PAGEFLTS")
$ vip2 = f$getjpi (0, "VIRTPEAK")
$ wsp2 = f$getjpi (0, "WSPEAK")
$ dsk2 = f$getdvi ("sys$disk:","OPCNT")
$ tim2 = f$time ()
$
$ tim = f$cvtime("''f$cvtime(tim2,,"TIME")'-''f$cvtime(tim1,,"TIME")'",,"TIME")
$ thun = 'f$cvtime(tim,,"HUNDREDTH")
$ tsec = (f$cvtime(tim,,"HOUR")*3600) + (f$cvtime(tim,,"MINUTE")*60) + -
f$cvtime(tim,,"SECOND")
$
$ bio = bio2 - bio1
$ dio = dio2 - dio1
$ pgf = pgf2 - pgf1
$ dsk = dsk2 - dsk1
$ vip = ""
$ if vip2 .le. vip1 then vip = "*" ! Asterisk means didn't change (from parent)
$ wsp = ""
$ if wsp2 .le. wsp1 then wsp = "*"
$
$ tiks = tik2 - tik1
$ secs = tiks / 100
$ huns = tiks - (secs*100)
$ write sys$output ""
$!
$ time$line1 == -
f$fao("Execution (CPU) sec!5UL.!2ZL Direct I/O !7UL Peak working set!7UL!1AS", -
secs, huns, dio, wsp2, wsp)
$ write sys$output time$line1
$!
$ time$line2 == -
f$fao("Elapsed (clock) sec!5UL.!2ZL Buffered I/O!7UL Peak virtual !7UL!1AS", -
tsec, thun, bio, vip2, vip)
$ write sys$output time$line2
$!
$ time$line3 == -
f$fao("Process ID !AS SYS$DISK I/O!7UL Page faults !7UL", -
f$getjpi(0,"pid"), dsk, pgf)
$ write sys$output time$line3
$ if wsp+vip .nes. "" then write sys$output -
" (* peak from parent)"
$ write sys$output ""
$
$! Place these output lines in the job logical name table, so the parent
$! can access them (useful for batch jobs to automate the collection).
$
$ define /job/nolog time$line1 "''time$line1'"
$ define /job/nolog time$line2 "''time$line2'"
$ define /job/nolog time$line3 "''time$line3'"
$
$ verify = f$verify(verify)
|
This example command procedure accepts multiple parameters, which include the RUN command, the name of the executable image to be run, and any parameters to be passed to the executable image.
$ TIMER RUN PROG_TEST $ $! User command being timed: $ $ RUN PROG_TEST.EXE; Execution (CPU) sec 45.39 Direct I/O 3 Peak working set 2224 Elapsed (clock) sec 45.96 Buffered I/O 18 Peak virtual 15808 Process ID 20A00999 SYS$DISK I/O 6 Page faults 64 |
If your program displays a lot of text, you can redirect the output from the program. Displaying text increases the buffered I/O count. Redirecting output from the program will change the times reported because of reduced screen I/O.
About system-wide tuning and suggestions for other performance
enhancements on OpenVMS systems, see the OpenVMS System Manager's Manual: Tuning, Monitoring, and Complex Systems.
5.2.2 The Performance and Coverage Analyzer (PCA)
To generate profiling information, you can use the optional Performance and Coverage Analyzer (PCA) tool.
Profiling helps you identify areas of code where significant program execution time is spent; it can also identify those parts of an application that are not executed (by a given set of test data). PCA has two components:
PCA works with related DECset tools LSE and the Test Manager. PCA provides a callable routine interface, as well as a command-line and DECwindows Motif graphical windowing interface. The following examples demonstrate the character-cell interface.
When compiling a program for which PCA will record and analyze data, specify the /DEBUG qualifier on the FORTRAN command line:
$ FORTRAN /DEBUG TEST_PROG.F90 |
On the LINK command line, specify the PCA debugging module PCA$OBJ using the Linker /DEBUG qualifier:
$ LINK /DEBUG=SYS$LIBRARY:PCA$OBJ.OBJ TEST_PROG |
When you run the program, the PCA$OBJ.OBJ debugging module invokes the Collector and is ready to accept your input to run your program under Collector control and gather the performance or coverage data:
$ RUN TEST_PROG PCAC> |
You can enter Collector commands, such as SET DATAFILE, SET PC_SAMPLING, GO, and EXIT.
To run the Analyzer, type the PCA command and specify the name of a performance data file, such as the following:
$ PCA TEST_PROG PCAA> |
You can enter the appropriate Analyzer commands to display the data in the performance data file in a graphic representation.
The Compaq Fortran compiler aligns most numeric data items on natural boundaries to avoid run-time adjustment by software that can slow performance.
A natural boundary is a memory address that is a multiple of the data item's size (data type sizes are described in Table 8-1). For example, a REAL (KIND=8) data item aligned on natural boundaries has an address that is a multiple of 8. An array is aligned on natural boundaries if all of its elements are.
All data items whose starting address is on a natural boundary are naturally aligned. Data not aligned on a natural boundary is called unaligned data.
Although the Compaq Fortran compiler naturally aligns individual data items when it can, certain Compaq Fortran statements (such as EQUIVALENCE) can cause data items to become unaligned (see Section 5.3.1).
Although you can use the FORTRAN command /ALIGNMENT qualifier to ensure
naturally aligned data, you should check and consider reordering data
declarations of data items within common blocks and structures. Within
each common block, derived type, or record structure, carefully specify
the order and sizes of data declarations to ensure naturally aligned
data. Start with the largest size numeric items first, followed by
smaller size numeric items, and then nonnumeric (character) data.
5.3.1 Causes of Unaligned Data and Ensuring Natural Alignment
Common blocks (COMMON statement), derived-type data, and Compaq Fortran 77 record structures (STRUCTURE and RECORD statements) usually contain multiple items within the context of the larger structure.
The following declaration statements can force data to be unaligned:
To avoid unaligned data in a common block, derived-type data, or record structure (extension), use one or both of the following:
Other possible causes of unaligned data include unaligned actual arguments and arrays that contain a derived-type structure or Compaq Fortran 77 record structure.
When actual arguments from outside the program unit are not naturally aligned, unaligned data access will occur. Compaq Fortran assumes all passed arguments are naturally aligned and has no information at compile time about data that will be introduced by actual arguments during program execution.
For arrays where each array element contains a derived-type structure or Compaq Fortran 77 record structure, the size of the array elements may cause some elements (but not the first) to start on an unaligned boundary.
Even if the data items are naturally aligned within a derived-type structure without the SEQUENCE statement or a record structure, the size of an array element might require use of the FORTRAN /ALIGNMENT qualifier to supply needed padding to avoid some array elements being unaligned.
If you specify /ALIGNMENT=RECORDS=PACKED (or equivalent qualifiers), no padding bytes are added between array elements. If array elements each contain a derived-type structure with the SEQUENCE statement, array elements are packed without padding bytes regardless of the FORTRAN command qualifiers specified. In this case, some elements will be unaligned.
When /ALIGNMENT=RECORDS=NATURAL is in effect (default), the number of padding bytes added by the compiler for each array element is dependent on the size of the largest data item within the structure. The compiler determines the size of the array elements as an exact multiple of the largest data item in the derived-type structure without the SEQUENCE statement or a record structure. The compiler then adds the appropriate number of padding bytes.
For instance, if a structure contains an 8-byte floating-point number followed by a 3-byte character variable, each element contains five bytes of padding (16 is an exact multiple of 8). However, if the structure contains one 4-byte floating-point number, one 4-byte integer, followed by a 3-byte character variable, each element would contain one byte of padding (12 is an exact multiple of 4).
On the FORTRAN command /ALIGNMENT qualifier, see Section 5.3.4.
5.3.2 Checking for Inefficient Unaligned Data
During compilation, the Compaq Fortran compiler naturally aligns as much data as possible. Exceptions that can result in unaligned data are described in Section 5.3.1.
Because unaligned data can slow run-time performance, it is worthwhile to:
There are two ways unaligned data might be reported:
On the /WARNINGS qualifier, see Section 2.3.50.
5.3.3 Ordering Data Declarations to Avoid Unaligned Data
For new programs or when the source declarations of an existing program can be easily modified, plan the order of your data declarations carefully to ensure the data items in a common block, derived-type data, record structure, or data items made equivalent by an EQUIVALENCE statement will be naturally aligned.
Use the following rules to prevent unaligned data:
Using the suggested data declaration guidelines minimizes the need to
use the /ALIGNMENT qualifier to add padding bytes to ensure naturally
aligned data. In cases where the /ALIGNMENT qualifier is still needed,
using the suggested data declaration guidelines can minimize the number
of padding bytes added by the compiler.
5.3.3.1 Arranging Data Items in Common Blocks
The order of data items in a COMMON statement determines the order in which the data items are stored. Consider the following declaration of a common block named X:
LOGICAL (KIND=2) FLAG INTEGER IARRY_I(3) CHARACTER(LEN=5) NAME_CH COMMON /X/ FLAG, IARRY_I(3), NAME_CH |
As shown in Figure 5-1, if you omit the appropriate FORTRAN command qualifiers, the common block will contain unaligned data items beginning at the first array element of IARRY_I.
Figure 5-1 Common Block with Unaligned Data
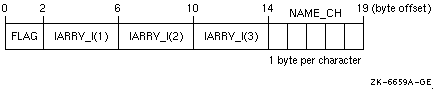
As shown in Figure 5-2, if you compile the program units that use the common block with the /ALIGNMENT=COMMONS=STANDARD qualifier, data items will be naturally aligned.
Figure 5-2 Common Block with Naturally Aligned Data
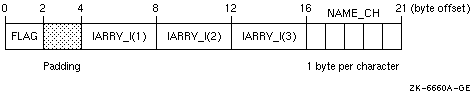
Because the common block X contains data items whose size is 32 bits or smaller, you can specify the /ALIGNMENT=COMMONS qualifier and still have naturally aligned data. If the common block contains data items whose size might be larger than 32 bits (such as REAL (KIND=8) data), specify /ALIGNMENT=COMMONS=NATURAL to ensure naturally aligned data.
If you can easily modify the source files that use the common block data, define the numeric variables in the COMMON statement in descending order of size and place the character variable last. This provides more portability, ensures natural alignment without padding, and does not require the FORTRAN command /ALIGNMENT=COMMONS=NATURAL (or equivalent) qualifier:
LOGICAL (KIND=2) FLAG INTEGER IARRY_I(3) CHARACTER(LEN=5) NAME_CH COMMON /X/ IARRY_I(3), FLAG, NAME_CH |
As shown in Figure 5-3, if you arrange the order of variables from largest to smallest size and place character data last, the data items will be naturally aligned.
Figure 5-3 Common Block with Naturally Aligned Reordered Data

When modifying or creating all source files that use common block data,
consider placing the common block data declarations in a module so the
declarations are consistent. If the common block is not needed for
compatibility (such as file storage or Compaq Fortran 77 use), you can
place the data declarations in a module without using a common block.
5.3.3.2 Arranging Data Items in Derived-Type Data
Like common blocks, derived-type data may contain multiple data items (members).
Data item components within derived-type data will be naturally aligned on up to 64-bit boundaries, with certain exceptions related to the use of the SEQUENCE statement and FORTRAN qualifiers. See Section 5.3.4 for information about these exceptions.
Compaq Fortran stores a derived data type as a linear sequence of values, as follows:
Consider the following declaration of array CATALOG_SPRING of derived-type PART_DT:
MODULE DATA_DEFS
TYPE PART_DT
INTEGER IDENTIFIER
REAL WEIGHT
CHARACTER(LEN=15) DESCRIPTION
END TYPE PART_DT
TYPE (PART_DT) CATALOG_SPRING(30)
.
.
.
END MODULE DATA_DEFS
|
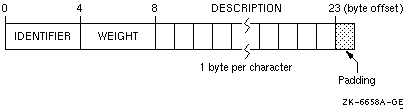
As shown in Figure 5-4, the largest numeric data items are defined first and the character data type is defined last. There are no padding characters between data items and all items are naturally aligned. The trailing padding byte is needed because CATALOG_SPRING is an array; it is inserted by the compiler when the /ALIGNMENT=RECORDS=NATURAL qualifier (default) is in effect.
Figure 5-4 Derived-Type Naturally Aligned Data (in CATALOG_SPRING : ( ,))
Compaq Fortran supports record structures provided by Compaq Fortran 77. Compaq Fortran 77 record structures use the RECORD statement and optionally the STRUCTURE statement, which are extensions to the FORTRAN-77, Fortran 90, and Fortran 95 standards. The order of data items in a STRUCTURE statement determines the order in which the data items are stored.
Compaq Fortran stores a record in memory as a linear sequence of values, with the record's first element in the first storage location and its last element in the last storage location. Unless you specify the /ALIGNMENT=RECORDS=PACKED qualifier, padding bytes are added if needed to ensure data fields are naturally aligned.
The following example contains a structure declaration, a RECORD statement, and diagrams of the resulting records as they are stored in memory:
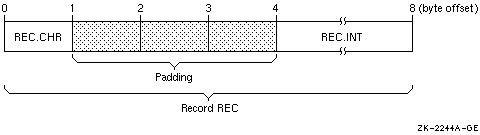
STRUCTURE /STRA/ CHARACTER*1 CHR INTEGER*4 INT END STRUCTURE . . . RECORD /STRA/ REC |
Figure 5-5 shows the memory diagram of record REC for naturally aligned records.
Figure 5-5 Memory Diagram of REC for Naturally Aligned Records
On data declaration statements, see the Compaq Fortran Language Reference Manual.
5.3.4 Qualifiers Controlling Alignment
The following qualifiers control whether the Compaq Fortran compiler adds padding (when needed) to naturally align multiple data items in common blocks, derived-type data, and Compaq Fortran 77 record structures:
The default behavior is that multiple data items in derived-type data and record structures will be naturally aligned; data items in common blocks will not be naturally aligned (/ALIGNMENT=(COMMONS=(PACKED, NOMULTILANGUAGE), RECORDS=NATURAL).
In derived-type data, using the SEQUENCE statement prevents /ALIGNMENT=RECORDS=NATURAL from adding needed padding bytes to naturally align data items.
On the /ALIGNMENT qualifier, see Section 2.3.3.
5.4 Use Arrays Efficiently
The following sections discuss these topics:
Many of the array access efficiency techniques described in this section are applied automatically by the Compaq Fortran loop transformation optimizations (see Section 5.8.1) or by the Compaq KAP for Fortran 90 for OpenVMS Alpha Systems performance preprocessor (described in Section 5.1.1).
Several aspects of array use can improve run-time performance. The following sections describe these aspects.
Array Access
The fastest array access occurs when contiguous access to the whole array or most of an array occurs. Perform one or a few array operations that access all of the array or major parts of an array instead of numerous operations on scattered array elements.
Rather than use explicit loops for array access, use elemental array operations, such as the following line that increments all elements of array variable A:
A = A + 1. |
When reading or writing an array, use the array name and not a DO loop or an implied DO-loop that specifies each element number. Fortran 90/95 array syntax allows you to reference a whole array by using its name in an expression. For example:
REAL :: A(100,100)
A = 0.0
A = A + 1. ! Increment all elements of A by 1
.
.
.
WRITE (8) A ! Fast whole array use
|
Similarly, you can use derived-type array structure components, such as:
TYPE X
INTEGER A(5)
END TYPE X
.
.
.
TYPE (X) Z
WRITE (8) Z%A ! Fast array structure component use
|
Make sure multidimensional arrays are referenced using proper array syntax and are traversed in the "natural" ascending order column major for Fortran. With column-major order, the leftmost subscript varies most rapidly with a stride of one. Writing a whole array uses column-major order.
Avoid row-major order, as is done by C, where the rightmost subscript varies most rapidly.
For example, consider the nested DO loops that access a two-dimension array with the J loop as the innermost loop:
INTEGER X(3,5), Y(3,5), I, J
Y = 0
DO I=1,3 ! I outer loop varies slowest
DO J=1,5 ! J inner loop varies fastest
X (I,J) = Y(I,J) + 1 ! Inefficient row-major storage order
END DO ! (rightmost subscript varies fastest)
END DO
.
.
.
END PROGRAM
|
Since J varies the fastest and is the second array subscript in the expression X (I,J), the array is accessed in row-major order.
To make the array accessed in natural column-major order, examine the array algorithm and data being modified.
Using arrays X and Y, the array can be accessed in natural column-major order by changing the nesting order of the DO loops so the innermost loop variable corresponds to the leftmost array dimension:
INTEGER X(3,5), Y(3,5), I, J
Y = 0
DO J=1,5 ! J outer loop varies slowest
DO I=1,3 ! I inner loop varies fastest
X (I,J) = Y(I,J) + 1 ! Efficient column-major storage order
END DO ! (leftmost subscript varies fastest)
END DO
.
.
.
END PROGRAM
|
The Fortran 90/95 whole array access ( X = Y + 1 ) uses efficient column major order. However, if the application requires that J vary the fastest or if you cannot modify the loop order without changing the results, consider modifying the application program to use a rearranged order of array dimensions. Program modifications include rearranging the order of:
In this case, the original DO loop nesting is used where J is the innermost loop:
INTEGER X(5,3), Y(5,3), I, J
Y = 0
DO I=1,3 ! I outer loop varies slowest
DO J=1,5 ! J inner loop varies fastest
X (J,I) = Y(J,I) + 1 ! Efficient column-major storage order
END DO ! (leftmost subscript varies fastest)
END DO
.
.
.
END PROGRAM
|
Code written to access multidimensional arrays in row-major order (like C) or random order can often make inefficient use of the CPU memory cache. For more information on using natural storage order during record I/O operations, see Section 5.5.3.
Use the available Fortran 90/95 array intrinsic procedures rather than create your own.
Whenever possible, use Fortran 90/95 array intrinsic procedures instead of creating your own routines to accomplish the same task. Compaq Fortran array intrinsic procedures are designed for efficient use with the various Compaq Fortran run-time components.
Using the standard-conforming array intrinsics can also make your program more portable.
Noncontiguous Access
With multidimensional arrays where access to array elements will be noncontiguous, avoid left-most array dimensions that are a power of two (such as 256, 512).
Since the cache sizes are a power of two, array dimensions that are also a power of two may make inefficient use of cache when array access is noncontiguous. If the cache size is an exact multiple of the leftmost dimension, your program will probably make little use of the cache. This does not apply to contiguous sequential access or whole array access.
One work-around is to increase the dimension to allow some unused elements, making the leftmost dimension larger than actually needed. For example, increasing the leftmost dimension of A from 512 to 520 would make better use of cache:
REAL A (512,100)
DO I = 2,511
DO J = 2,99
A(I,J)=(A(I+1,J-1) + A(I-1, J+1)) * 0.5
END DO
END DO
|
In this code, array A has a leftmost dimension of 512, a power of two. The innermost loop accesses the rightmost dimension (row major), causing inefficient access. Increasing the leftmost dimension of A to 520 (REAL A (520,100)) allows the loop to provide better performance, but at the expense of some unused elements.
Because loop index variables I and J are used in the calculation,
changing the nesting order of the DO loops changes the results.
5.4.2 Passing Array Arguments Efficiently
In Compaq Fortran, there are two general types of array arguments:
When passing arrays as arguments, either the starting (base) address of the array or the address of an array descriptor is passed:
Passing an assumed-shape array or array pointer to an explicit-shape array can slow run-time performance. This is because the compiler needs to create an array temporary for the entire array. The array temporary is created because the passed array may not be contiguous and the receiving (explicit-shape) array requires a contiguous array. When an array temporary is created, the size of the passed array determines whether the impact on slowing run-time performance is slight or severe.
Table 5-3 summarizes what happens with the various combinations of array types. The amount of run-time performance inefficiency depends on the size of the array.
| Input Arguments Array Types | Explicit-Shape Arrays | Deferred-Shape and Assumed-Shape Arrays |
|---|---|---|
| Explicit-Shape Arrays | Very efficient. Does not use an array temporary. Does not pass an array descriptor. Interface block optional. | Efficient. Only allowed for assumed-shape arrays (not deferred-shape arrays). Does not use an array temporary. Passes an array descriptor. Requires an interface block. |
| Deferred-Shape and Assumed-Shape Arrays |
When passing an allocatable array, very efficient. Does not use an
array temporary. Does not pass an array descriptor. Interface block
optional.
When not passing an allocatable array, not efficient. Instead use allocatable arrays whenever possible. Uses an array temporary. Does not pass an array descriptor. Interface block optional. |
Efficient. Requires an assumed-shape or array pointer as dummy argument. Does not use an array temporary. Passes an array descriptor. Requires an interface block. |
On arrays and their data declaration statements, see the Compaq Fortran Language Reference Manual.
5.5 Improve Overall I/O Performance
Improving overall I/O performance can minimize both device I/O and actual CPU time. The techniques listed in this section can greatly improve performance in many applications.
A bottleneck determines the maximum speed of execution by being the slowest process in an executing program. In some programs, I/O is the bottleneck that prevents an improvement in run-time performance. The key to relieving I/O bottlenecks is to reduce the actual amount of CPU and I/O device time involved in I/O. Bottlenecks may be caused by one or more of the following:
Improved coding practices can minimize actual device I/O, as well as the actual CPU time.
Compaq offers software solutions to system-wide problems like
minimizing device I/O delays (see Section 5.1.1).
5.5.1 Use Unformatted Files Instead of Formatted Files
Use unformatted files whenever possible. Unformatted I/O of numeric data is more efficient and more precise than formatted I/O. Native unformatted data does not need to be modified when transferred and will take up less space on an external file.
Conversely, when writing data to formatted files, formatted data must be converted to character strings for output, less data can transfer in a single operation, and formatted data may lose precision if read back into binary form.
To write the array A(25,25) in the following statements, S1 is more efficient than S2:
S1 WRITE (7) A
S2 WRITE (7,100) A
100 FORMAT (25(' ',25F5.21))
|
Although formatted data files are more easily ported to other systems,
Compaq Fortran can convert unformatted data in several formats (see
Chapter 9).
5.5.2 Write Whole Arrays or Strings
The general guidelines about array use discussed in Section 5.4 also apply to reading or writing an array with an I/O statement.
To eliminate unnecessary overhead, write whole arrays or strings at one
time rather than individual elements at multiple times. Each item in an
I/O list generates its own calling sequence. This processing overhead
becomes most significant in implied-DO loops. When accessing whole
arrays, use the array name (Fortran 90/95 array syntax) instead of
using implied-DO loops.
5.5.3 Write Array Data in the Natural Storage Order
Use the natural ascending storage order whenever possible. This is column-major order, with the leftmost subscript varying fastest and striding by 1 (see Section 5.4). If a program must read or write data in any other order, efficient block moves are inhibited.
If the whole array is not being written, natural storage order is the
best order possible.
5.5.4 Use Memory for Intermediate Results
Performance can improve by storing intermediate results in memory
rather than storing them in a file on a peripheral device. One
situation that may not benefit from using intermediate storage is a
disproportionately large amount of data in relation to physical memory
on your system. Excessive page faults can dramatically impede virtual
memory performance.
5.5.5 Defaults for Blocksize and Buffer Count
Compaq Fortran provides OPEN statement defaults for BLOCKSIZE and BUFFERCOUNT that generally offer adequate I/O performance. The default for BLOCKSIZE and BUFFERCOUNT is determined by SET RMS_DEFAULT command default values.
Specifying a BUFFERCOUNT of 2 (or 3) allows Record Management Services (RMS) to overlap some I/O operations with CPU operations. For sequential and relative files, specify a BLOCKSIZE of at least 1024 bytes. For indexed files, consult the Guide to OpenVMS File Applications for information on file tuning and specifying the optimal BUFFERCOUNT and BLOCKSIZE.
Any experiments to improve I/O performance should try to increase the amount of data read by each disk I/O. For large indexed files, you can reduce disk I/O by specifying enough buffers (BUFFERCOUNT) to keep most of the index portion of the file in memory.
When creating a file, you should consider specifying a RECL value that provides for adequate I/O performance. The RECL value unit differs for unformatted files (4-byte units) and formatted files (1-byte units).
The RECL value unit for formatted files is always 1-byte units. For unformatted files, the RECL unit is 4-byte units, unless you specify the /ASSUME=BYTERECL qualifier to request 1-byte units (see Section 2.3.7).
When porting unformatted data files from non-Compaq systems, see Section 9.4.6.
Unless a certain record type is needed for portability reasons (see Section 6.4.3), choose the most efficient type, as follows:
DO loop collapsing reduces a major overhead in I/O processing. Normally, each element in an I/O list generates a separate call to the Compaq Fortran RTL. The processing overhead of these calls can be most significant in implied-DO loops.
Compaq Fortran reduces the number of calls in implied-DO loops by replacing up to seven nested implied-DO loops with a single call to an optimized run-time library I/O routine. The routine can transmit many I/O elements at once.
Loop collapsing can occur in formatted and unformatted I/O, but only if certain conditions are met:
Variable format expressions (a Compaq Fortran 77 extension) are almost as flexible as run-time formatting, but they are more efficient because the compiler can eliminate run-time parsing of the I/O format. Only a small amount of processing and the actual data transfer are required during run time.
On the other hand, run-time formatting can impair performance significantly. For example, in the following statements, S1 is more efficient than S2 because the formatting is done once at compile time, not at run time:
S1 WRITE (6,400) (A(I), I=1,N)
400 FORMAT (1X, <N> F5.2)
.
.
.
S2 WRITE (CHFMT,500) '(1X,',N,'F5.2)'
500 FORMAT (A,I3,A)
WRITE (6,FMT=CHFMT) (A(I), I=1,N)
|
Other source coding guidelines can be implemented to improve run-time performance.
The amount of improvement in run-time performance is related to the
number of times a statement is executed. For example, improving an
arithmetic expression executed within a loop many times has the
potential to improve performance more than improving a similar
expression executed once outside a loop.
5.6.1 Avoid Small Integer and Small Logical Data Items
Avoid using integer or logical data less than 32 bits, because the smallest unit of efficient access on Alpha systems is 32 bits.
Accessing a 16-bit (or 8-bit) data type can result in a sequence of machine instructions to access the data, rather than a single, efficient machine instruction for a 32-bit data item.
To minimize data storage and memory cache misses with arrays, use
32-bit data rather than 64-bit data, unless you require the greater
numeric range of 8-byte integers or the greater range and precision of
double precision floating-point numbers.
5.6.2 Avoid Mixed Data Type Arithmetic Expressions
Avoid mixing integer and floating-point (REAL) data in the same computation. Expressing all numbers in a floating-point arithmetic expression (assignment statement) as floating-point values eliminates the need to convert data between fixed and floating-point formats. Expressing all numbers in an integer arithmetic expression as integer values also achieves this. This improves run-time performance.
For example, assuming that I and J are both INTEGER variables, expressing a constant number (2.) as an integer value (2) eliminates the need to convert the data:
| Original Code: |
INTEGER I, J
I = J / 2. |
| Efficient Code: |
INTEGER I, J
I = J / 2 |
For applications with numerous floating-point operations, consider using the /ASSUME=NOACCURACY_SENSITIVE qualifier (see Section 5.8.8) if a small difference in the result is acceptable.
You can use different sizes of the same general data type in
an expression with minimal or no effect on run-time performance. For
example, using REAL, DOUBLE PRECISION, and COMPLEX floating-point
numbers in the same floating-point arithmetic expression has minimal or
no effect on run-time performance.
5.6.3 Use Efficient Data Types
In cases where more than one data type can be used for a variable, consider selecting the data types based on the following hierarchy, listed from most to least efficient:
However, keep in mind that in an arithmetic expression, you should
avoid mixing integer and floating-point (REAL) data (see Section 5.6.2).
5.6.4 Avoid Using Slow Arithmetic Operators
Before you modify source code to avoid slow arithmetic operators, be aware that optimizations convert many slow arithmetic operators to faster arithmetic operators. For example, the compiler optimizes the expression H=J**2 to be H=J*J.
Consider also whether replacing a slow arithmetic operator with a faster arithmetic operator will change the accuracy of the results or impact the maintainability (readability) of the source code.
Replacing slow arithmetic operators with faster ones should be reserved for critical code areas. The following hierarchy lists the Compaq Fortran arithmetic operators, from fastest to slowest:
Avoid using EQUIVALENCE statements. EQUIVALENCE statements can:
Whenever the Compaq Fortran compiler has access to the use and definition of a subprogram during compilation, it may choose to inline the subprogram. Using statement functions and internal subprograms maximizes the number of subprogram references that will be inlined, especially when multiple source files are compiled together at optimization level /OPTIMIZE=LEVEL=4 or higher.
For more information, see Section 5.1.2.
5.6.7 Code DO Loops for Efficiency
Minimize the arithmetic operations and other operations in a DO loop whenever possible. Moving unnecessary operations outside the loop will improve performance (for example, when the intermediate nonvarying values within the loop are not needed).
Compaq Fortran performs many optimizations by default. You do not have to recode your program to use them. However, understanding how optimizations work helps you remove any inhibitors to their successful function.
Generally, Compaq Fortran increases compile time in favor of decreasing run time. If an operation can be performed, eliminated, or simplified at compile time, Compaq Fortran does so, rather than have it done at run time. The time required to compile the program usually increases as more optimizations occur.
The program will likely execute faster when compiled at /OPTIMIZE=LEVEL=4, but will require more compilation time than if you compile the program at a lower level of optimization.
The size of the object file varies with the optimizations requested. Factors that can increase object file size include an increase of loop unrolling or procedure inlining.
Table 5-4 lists the levels of Compaq Fortran optimization with different /OPTIMIZE=LEVEL=n levels. For example, /OPTIMIZE=LEVEL=0 specifies no selectable optimizations (certain optimizations always occur); /OPTIMIZE=LEVEL=5 specifies all levels of optimizations including loop transformation and software pipelining.
| /OPTIMIZE=LEVEL=n | ||||||
|---|---|---|---|---|---|---|
| Optimization Type | n=0 | n=1 | n=2 | n=3 | n=4 | n=5 |
| Loop transformation | X | |||||
| Software pipelining | X | X | ||||
| Automatic inlining | X | X | ||||
| Loop unrolling | X | X | X | |||
| Additional global optimizations | X | X | X | |||
| Global optimizations | X | X | X | X | ||
| Local (minimal) optimizations | X | X | X | X | X | |
The default is /OPTIMIZE=LEVEL=4.
In Table 5-4, the following terms are used to describe the levels of optimization (described in detail in Section 5.7.1 to Section 5.7.6):
The following optimizations occur at any optimization level (0 through 5):
SUM(A,B) = A+B . . . Y = 3.14 X = SUM(Y,3.0) ! With value propagation, becomes: X = 6.14 |
To enable local optimizations, use /OPTIMIZE=LEVEL=1 or a higher optimization level (LEVEL=2, LEVEL=3, LEVEL=4, LEVEL=5).
To prevent local optimizations, specify /NOOPTIMIZE (/OPTIMIZE=LEVEL=0).
5.7.2.1 Common Subexpression Elimination
If the same subexpressions appear in more than one computation and the values do not change between computations, Compaq Fortran computes the result once and replaces the subexpressions with the result itself:
DIMENSION A(25,25), B(25,25) A(I,J) = B(I,J) |
Without optimization, these statements can be compiled as follows:
t1 = ((J-1)*25+(I-1))*4 t2 = ((J-1)*25+(I-1))*4 A(t1) = B(t2) |
Variables t1 and t2 represent equivalent expressions. Compaq Fortran eliminates this redundancy by producing the following:
t = ((J-1)*25+(I-1)*4 A(t) = B(t) |
Expansion of multiplication and division refers to bit shifts that allow faster multiplication and division while producing the same result. For example, the integer expression (I*17) can be calculated as I with a 4-bit shift plus the original value of I. This can be expressed using the Compaq Fortran ISHFT intrinsic function:
J1 = I*17 J2 = ISHFT(I,4) + I ! equivalent expression for I*17 |
The optimizer uses machine code that, like the ISHFT intrinsic
function, shifts bits to expand multiplication and division by literals.
5.7.2.3 Compile-Time Operations
Compaq Fortran does as many operations as possible at compile time rather than having them done at run time.
Compaq Fortran can perform many operations on constants (including PARAMETER constants):
PARAMETER (NN=27) I = 2*NN+J ! Becomes: I = 54 + J |
REAL X, Y X = 10 * Y ! Becomes: X = 10.0 * Y |
INTEGER I(10,10) I(1,2) = I(4,5) ! Compiled as a direct load and store |
Algebraic Reassociation Optimizations
Compaq Fortran delays operations to see whether they have no effect or can be transformed to have no effect. If they have no effect, these operations are removed. A typical example involves unary minus and .NOT. operations:
X = -Y * -Z ! Becomes: Y * Z |
Compaq Fortran tracks the values assigned to variables and constants, including those from DATA statements, and traces them to every place they are used. Compaq Fortran uses the value itself when it is more efficient to do so.
When compiling subprograms, Compaq Fortran analyzes the program to ensure that propagation is safe if the subroutine is called more than once.
Value propagation frequently leads to more value propagation. Compaq Fortran can eliminate run-time operations, comparisons and branches, and whole statements.
In the following example, constants are propagated, eliminating multiple operations from run time:
| Original Code | Optimized Code |
|---|---|
|
PI = 3.14
.
. . PIOVER2 = PI/2 . . . I = 100 . . . IF (I.GT.1) GOTO 10 10 A(I) = 3.0*Q |
.
. . PIOVER2 = 1.57 . . . I = 100 . . . 10 A(100) = 3.0*Q |
If a variable is assigned but never used, Compaq Fortran eliminates the entire assignment statement:
X = Y*Z . . .=Y*Z is eliminated. X = A(I,J)* PI |
Some programs used for performance analysis often contain such
unnecessary operations. When you try to measure the performance of such
programs compiled with Compaq Fortran, these programs may show
unrealistically good performance results. Realistic results are
possible only with program units using their results in output
statements.
5.7.2.6 Register Usage
A large program usually has more data that would benefit from being held in registers than there are registers to hold the data. In such cases, Compaq Fortran typically tries to use the registers according to the following descending priority list:
Compaq Fortran uses heuristic algorithms and a modest amount of computation to attempt to determine an effective usage for the registers.
Holding Variables in Registers
Because operations using registers are much faster than using memory, Compaq Fortran generates code that uses the Alpha 64-bit integer and floating-point registers instead of memory locations. Knowing when Compaq Fortran uses registers may be helpful when doing certain forms of debugging.
Compaq Fortran uses registers to hold the values of variables whenever the Fortran language does not require them to be held in memory, such as holding the values of temporary results of subexpressions, even if /NOOPTIMIZE (same as /OPTIMIZE=LEVEL=0 or no optimization) was specified.
Compaq Fortran may hold the same variable in different registers at different points in the program:
V = 3.0*Q . . . X = SIN(Y)*V . . . V = PI*X . . . Y = COS(Y)*V |
Compaq Fortran may choose one register to hold the first use of V and another register to hold the second. Both registers can be used for other purposes at points in between. There may be times when the value of the variable does not exist anywhere in the registers. If the value of V is never needed in memory, it is never stored.
Compaq Fortran uses registers to hold the values of I, J, and K (so long as there are no other optimization effects, such as loops involving the variables):
A(I) = B(J) + C(K) |
More typically, an expression uses the same index variable:
A(K) = B(K) + C(K) |
In this case, K is loaded into only one register and is used to index
all three arrays at the same time.
5.7.2.7 Mixed Real/Complex Operations
In mixed REAL/COMPLEX operations, Compaq Fortran avoids the conversion and performs a simplified operation on:
For example, if variable R is REAL and A and B are COMPLEX, no conversion occurs with the following:
COMPLEX A, B . . . B = A + R |
To enable global optimizations, use /OPTIMIZE=LEVEL=2 or a higher optimization level (LEVEL=3, LEVEL=4, or LEVEL=5). Using /OPTIMIZE= LEVEL=2 or higher also enables local optimizations (LEVEL=1).
Global optimizations include:
Data-flow and split lifetime analysis (global data analysis) traces the values of variables and whole arrays as they are created and used in different parts of a program unit. During this analysis, Compaq Fortran assumes that any pair of array references to a given array might access the same memory location, unless a constant subscript is used in both cases.
To eliminate unnecessary recomputations of invariant expressions in loops, Compaq Fortran hoists them out of the loops so they execute only once.
Global data analysis includes which data items are selected for analysis. Some data items are analyzed as a group and some are analyzed individually. Compaq Fortran limits or may disqualify data items that participate in the following constructs, generally because it cannot fully trace their values.
Data items in the following constructs can make global optimizations less effective:
COMMON /X/ I DO J=1,N I = J CALL FOO A(I) = I ENDDO |
To enable additional global optimizations, use /OPTIMIZE=LEVEL=3 or a higher optimization level (LEVEL=4 or LEVEL=5). Using /OPTIMIZE= LEVEL=3 or higher also enables local optimizations (LEVEL=1) and global optimizations (LEVEL=2).
Additional global optimizations improve speed at the cost of longer
compile times and possibly extra code size.
5.7.4.1 Loop Unrolling
At optimization level /OPTIMIZE=LEVEL=3 or above, Compaq Fortran attempts to unroll certain innermost loops, minimizing the number of branches and grouping more instructions together to allow efficient overlapped instruction execution (instruction pipelining). The best candidates for loop unrolling are innermost loops with limited control flow.
As more loops are unrolled, the average size of basic blocks increases. Loop unrolling generates multiple copies of the code for the loop body (loop code iterations) in a manner that allows efficient instruction pipelining.
The loop body is replicated a certain number of times, substituting index expressions. An initialization loop might be created to align the first reference with the main series of loops. A remainder loop might be created for leftover work.
The number of times a loop is unrolled can be determined either by the optimizer or by using the /OPTIMIZE=UNROLL=n qualifier, which can specify the limit for loop unrolling. Unless the user specifies a value, the optimizer unrolls a loop four times for most loops or two times for certain loops (large estimated code size or branches out the loop).
Array operations are often represented as a nested series of loops when expanded into instructions. The innermost loop for the array operation is the best candidate for loop unrolling (like DO loops). For example, the following array operation (once optimized) is represented by nested loops, where the innermost loop is a candidate for loop unrolling:
A(1:100,2:30) = B(1:100,1:29) * 2.0
|
In addition to loop unrolling and other optimizations, the number of branches are reduced by replicating code that will eliminate branches. Code replication decreases the number of basic blocks and increases instruction-scheduling opportunities.
Code replication normally occurs when a branch is at the end of a flow of control, such as a routine with multiple, short exit sequences. The code at the exit sequence gets replicated at the various places where a branch to it might occur.
For example, consider the following unoptimized routine and its optimized equivalent that uses code replication (R0 is register 0):
| Unoptimized Instructions | Optimized (Replicated) Instructions |
|---|---|
. |
. |
Similarly, code replication can also occur within a loop that contains
a small amount of shared code at the bottom of a loop and a case-type
dispatch within the loop. The loop-end test-and-branch code might be
replicated at the end of each case to create efficient instruction
pipelining within the code for each case.
5.7.5 Automatic Inlining and Software Pipelining
To enable optimizations that perform automatic inlining and software pipelining, use /OPTIMIZE=LEVEL=4 or a higher optimization level (LEVEL=5). Using /OPTIMIZE=LEVEL=4 also enables local optimizations (LEVEL=1), global optimizations (LEVEL=2), and additional global optimizations (LEVEL=3).
The default is /OPTIMIZE=LEVEL=4 (same as /OPTIMIZE).
5.7.5.1 Interprocedure Analysis
Compiling multiple source files at optimization level /OPTIMIZE=LEVEL=4 or higher lets the compiler examine more code for possible optimizations, including multiple program units. This results in:
As more procedures are inlined, the size of the executable program and
compile times may increase, but execution time should decrease.
5.7.5.2 Inlining Procedures
Inlining refers to replacing a subprogram reference (such as a CALL statement or function invocation) with the replicated code of the subprogram. As more procedures are inlined, global optimizations often become more effective.
The optimizer inlines small procedures, limiting inlining candidates based on such criteria as:
You can specify:
Software pipelining applies instruction scheduling to certain innermost loops, allowing instructions within a loop to "wrap around" and execute in a different iteration of the loop. This can reduce the impact of long-latency operations, resulting in faster loop execution.
Software pipelining also enables the prefetching of data to reduce the impact of cache misses.
A group of optimizations known as loop transformation optimizations with its associated additional software dependence analysis are enabled by using the /OPTIMIZE=LEVEL=5 qualifier. In certain cases, this improves run-time performance.
The loop transformation optimizations apply to array references within loops and can apply to multiple nested loops. These optimizations can improve the performance of the memory system.
In addition to the /OPTIMIZE=LEVEL qualifiers (discussed in
Section 5.7), several other FORTRAN command qualifiers and /OPTIMIZE
keywords can prevent or facilitate improved optimizations.
5.8.1 Loop Transformation
The loop transformation optimizations are enabled by using the /OPTIMIZE=LOOPS qualifier or the /OPTIMIZE=LEVEL=5 qualifier. Loop transformation attempts to improve performance by rewriting loops to make better use of the memory system. By rewriting loops, the loop transformation optimizations can increase the number of instructions executed, which can degrade the run-time performance of some programs.
To request loop transformation optimizations without software pipelining, do one of the following:
The loop transformation optimizations apply to array references within loops. These optimizations can improve the performance of the memory system and usually apply to multiple nested loops. The loops chosen for loop transformation optimizations are always counted loops. Counted loops use a variable to count iterations, thereby determining the number before entering the loop. For example, most DO loops are counted loops.
Conditions that typically prevent the loop transformation optimizations from occurring include subprogram references that are not inlined (such as an external function call), complicated exit conditions, and uncounted loops.
The types of optimizations associated with /OPTIMIZE=LOOPS include the following:
On the interaction of command-line options and timing programs compiled
with the loop transformation optimizations, see Section 5.7.
5.8.2 Software Pipelining
Software pipelining and additional software dependence analysis are enabled by using the /OPTIMIZE=PIPELINE qualifier or by the /OPTIMIZE=LEVEL=4 qualifier. Software pipelining in certain cases improves run-time performance.
The software pipelining optimization applies instruction scheduling to certain innermost loops, allowing instructions within a loop to "wrap around" and execute in a different iteration of the loop. This can reduce the impact of long-latency operations, resulting in faster loop execution.
Loop unrolling (enabled at /OPTIMIZE=LEVEL=3 or above) cannot schedule across iterations of a loop. Because software pipelining can schedule across loop iterations, it can perform more efficient scheduling to eliminate instruction stalls within loops.
For instance, if software dependence analysis of data flow reveals that certain calculations can be done before or after that iteration of the loop, software pipelining reschedules those instructions ahead of or behind that loop iteration, at places where their execution can prevent instruction stalls or otherwise improve performance.
Software pipelining also enables the prefetching of data to reduce the impact of cache misses.
Software pipelining can be more effective when you combine /OPTIMIZE=PIPELINE (or /OPTIMIZE=LEVEL=4) with the appropriate OPTIMIZE=TUNE=keyword for the target Alpha processor generation (see Section 5.8.6).
To specify software pipelining without loop transformation optimizations, do one of the following:
For this version of Compaq Fortran, loops chosen for software pipelining:
By modifying the unrolled loop and inserting instructions as needed before and/or after the unrolled loop, software pipelining generally improves run-time performance, except where the loops contain a large number of instructions with many existing overlapped operations. In this case, software pipelining may not have enough registers available to effectively improve execution performance. Run-time performance using /OPTIMIZE=LEVEL=4 (or /OPTIMIZE=PIPELINE) may not improve performance, as compared to using /OPTIMIZE=(LEVEL=4,NOPIPELINE).
For programs that contain loops that exhaust available registers, longer execution times may result with /OPTIMIZE=LEVEL=4 or /OPTIMIZE=PIPELINE. In cases where performance does not improve, consider compiling with the OPTIMIZE=UNROLL=1 qualifier along with /OPTIMIZE=LEVEL=4 or /OPTIMIZE=PIPELINE, to possibly improve the effects of software pipelining.
On the interaction of command-line options and timing programs compiled
with software pipelining, see Section 5.7.
5.8.3 Setting Multiple Qualifiers with the /FAST Qualifier
Specifying the /FAST qualifier sets the following qualifiers:
You can specify individual qualifiers on the command line to override
the /FAST defaults. Note that /FAST/ALIGNMENT=COMMONS=PACKED sets
/ALIGNMENT=NOSEQUENCE.
5.8.4 Controlling Loop Unrolling
You can specify the number of times a loop is unrolled by using the /OPTIMIZE=UNROLL=n qualifier (see Section 2.3.34).
Using /OPTIMIZE=UNROLL=n can also influence the run-time results of software pipelining optimizations performed when you specify /OPTIMIZE=LEVEL=5.
Although unrolling loops usually improves run-time performance, the size of the executable program may increase.
On loop unrolling, see Section 5.7.4.1.
5.8.5 Controlling the Inlining of Procedures
To specify the types of procedures to be inlined, use the /OPTIMIZE=INLINE=keyword keywords. Also, compile multiple source files together and specify an adequate optimization level, such as /OPTIMIZE=LEVEL=4.
If you omit /OPTIMIZE=INLINE=keyword, the optimization level /OPTIMIZE=LEVEL=n qualifier used determines the types of procedures that are inlined.
The /OPTIMIZE=INLINE=keyword keywords are as follows:
For information on the inlining of other procedures (inlined at optimization level /OPTIMIZE=LEVEL=4 or higher), see Section 5.7.5.2.
Maximizing the types of procedures that are inlined usually improves run-time performance, but compile-time memory usage and the size of the executable program may increase.
To determine whether using /OPTIMIZE=INLINE=ALL benefits your
particular program, time program execution for the same program
compiled with and without /OPTIMIZE=INLINE=ALL.
5.8.6 Requesting Optimized Code for a Specific Processor Generation
You can specify the types of optimized code to be generated by using the /OPTIMIZE=TUNE=keyword keywords. Regardless of the specified keyword, the generated code will run correctly on all implementations of the Alpha architecture. Tuning for a specific implementation can improve run-time performance; it is also possible that code tuned for a specific target may run slower on another target.
Specifying the correct keyword for /OPTIMIZE=TUNE=keyword for the target processor generation type usually slightly improves run-time performance. Unless you request software pipelining, the run-time performance difference for using the wrong keyword for /OPTIMIZE=TUNE=keyword (such as using /OPTIMIZE=TUNE=EV4 for an EV5 processor) is usually less than 5%. When using software pipelining (using /OPTIMIZE=LEVEL=5) with /OPTIMIZE=TUNE=keyword, the difference can be more than 5%.
The combination of the specified keyword for /OPTIMIZE=TUNE=keyword and the type of processor generation used has no effect on producing the expected correct program results.
The /OPTIMIZE=TUNE=keyword keywords are as follows:
If you omit /OPTIMIZE=TUNE=keyword, if /FAST is specified,
then HOST is used; otherwise, GENERIC is used.
5.8.7 Requesting Generated Code for a Specific Processor Generation
You can specify the types of instructions that will be generated for the program unit being compiled by using the /ARCHITECTURE qualifier. Unlike the /OPTIMIZE=TUNE=keyword option that helps with proper instruction scheduling, the /ARCHITECTURE qualifier specifies the type of Alpha chip instructions that can be used.
Programs compiled with the /ARCHITECTURE=GENERIC option (default) run on all Alpha processors without instruction emulation overhead.
For example, if you specify /ARCHITECTURE=EV6, the code generated will run very fast on EV6 systems, but may run slower on older Alpha processor generations. Because instructions used for the EV6 chip may be present in the program's generated code, code generated for an EV6 system may slow program execution on older Alpha processors when EV6 instructions are emulated by the OpenVMS Alpha Version 7.1 (or later) instruction emulator.
This instruction emulator allows new instructions, not implemented on the host processor chip, to execute and produce correct results. Applications using emulated instructions will run correctly, but may incur significant software emulation overhead at runtime.
The keywords used by /ARCHITECTURE=keyword are the same as
those used by /OPTIMIZE=TUNE=keyword. If you omit
/ARCHITECTURE=keyword, if /FAST is specified then HOST is used;
otherwise, GENERIC is used. For more information on the /ARCHITECTURE
qualifier, see Section 2.3.6.
5.8.8 Arithmetic Reordering Optimizations
If you use the /ASSUME=NOACCURACY_SENSITIVE qualifier, Compaq Fortran may reorder code (based on algebraic identities) to improve performance. For example, the following expressions are mathematically equivalent but may not compute the same value using finite precision arithmetic:
X = (A + B) + C X = A + (B + C) |
The results can be slightly different from the default (ACCURACY_SENSITIVE) because of the way intermediate results are rounded. However, the NOACCURACY_SENSITIVE results are not categorically less accurate than those gained by the default. In fact, dot product summations using NOACCURACY_SENSITIVE can produce more accurate results than those using ACCURACY_SENSITIVE.
The effect of /ASSUME=NOACCURACY_SENSITIVE is important when Compaq Fortran hoists divide operations out of a loop. If NOACCURACY_SENSITIVE is in effect, the unoptimized loop becomes the optimized loop:
| Unoptimized Code | Optimized Code |
|---|---|
| T = 1/V | |
| DO I=1,N | DO I=1,N |
| . | . |
| . | . |
| . | . |
| B(I) = A(I)/V | B(I) = A(I)*T |
| END DO | END DO |
The transformation in the optimized loop increases performance
significantly, and loses little or no accuracy. However, it does have
the potential for raising overflow or underflow arithmetic exceptions.
5.8.9 Dummy Aliasing Assumption
Some programs compiled with Compaq Fortran (or Compaq Fortran 77) may have results that differ from the results of other Fortran compilers. Such programs may be aliasing dummy arguments to each other or to a variable in a common block or shared through use association, and at least one variable access is a store.
This program behavior is prohibited in programs conforming to the Fortran 90 and Fortran 95 standards, but not by Compaq Fortran. Other versions of Fortran allow dummy aliases and check for them to ensure correct results. However, Compaq Fortran assumes that no dummy aliasing will occur, and it can ignore potential data dependencies from this source in favor of faster execution.
The Compaq Fortran default is safe for programs conforming to the Fortran 90 and Fortran 95 standards. It will improve performance of these programs, because the standard prohibits such programs from passing overlapped variables or arrays as actual arguments if either is assigned in the execution of the program unit.
The /ASSUME=DUMMY_ALIASES qualifier allows dummy aliasing. It ensures correct results by assuming the exact order of the references to dummy and common variables is required. Program units taking advantage of this behavior can produce inaccurate results if compiled with /ASSUME=NODUMMY_ALIASES.
Example 5-3 is taken from the DAXPY routine in the Fortran-77 version of the Basic Linear Algebra Subroutines (BLAS).
| Example 5-3 Using the /ASSUME =DUMMY_ALIASES Qualifier |
|---|
SUBROUTINE DAXPY(N,DA,DX,INCX,DY,INCY)
! Constant times a vector plus a vector.
! uses unrolled loops for increments equal to 1.
DOUBLE PRECISION DX(1), DY(1), DA
INTEGER I,INCX,INCY,IX,IY,M,MP1,N
!
IF (N.LE.0) RETURN
IF (DA.EQ.0.0) RETURN
IF (INCX.EQ.1.AND.INCY.EQ.1) GOTO 20
! Code for unequal increments or equal increments
! not equal to 1.
.
.
.
RETURN
! Code for both increments equal to 1.
! Clean-up loop
20 M = MOD(N,4)
IF (M.EQ.0) GOTO 40
DO I=1,M
DY(I) = DY(I) + DA*DX(I)
END DO
IF (N.LT.4) RETURN
40 MP1 = M + 1
DO I = MP1, N, 4
DY(I) = DY(I) + DA*DX(I)
DY(I + 1) = DY(I + 1) + DA*DX(I + 1)
DY(I + 2) = DY(I + 2) + DA*DX(I + 2)
DY(I + 3) = DY(I + 3) + DA*DX(I + 3)
END DO
RETURN
END SUBROUTINE
|
The second DO loop contains assignments to DY. If DY is overlapped with DA, any of the assignments to DY might give DA a new value, and this overlap would affect the results. If this overlap is desired, then DA must be fetched from memory each time it is referenced. The repetitious fetching of DA degrades performance.
Linking Routines with Opposite Settings
You can link routines compiled with the /ASSUME=DUMMY_ALIASES qualifier to routines compiled with /ASSUME=NODUMMY_ALIASES. For example, if only one routine is called with dummy aliases, you can use /ASSUME=DUMMY_ALIASES when compiling that routine, and compile all the other routines with /ASSUME=NODUMMY_ALIASES to gain the performance value of that qualifier.
Programs calling DAXPY with DA overlapping DY do not conform to the
FORTRAN-77, Fortran 90, and Fortran 95 standards. However, they are
supported if /ASSUME=DUMMY_ALIASES was used to compile the DAXPY
routine.
5.9 Compiler Directives Related to Performance
Certain compiler source directives (cDEC$ prefix) can be used in place of some performance-related compiler options and provide more control of certain optimizations, as discussed in the following sections:
5.9.1, Using the cDEC$ OPTIONS Directive
5.9.2, Using the cDEC$ UNROLL Directive to Control Loop Unrolling
5.9.3, Using the cDEC$ IVDEP Directive to Control Certain Loop Optimizations
The cDEC$ OPTIONS directive allows source code control of the alignment of fields in record structures and data items in common blocks. The fields and data items can be naturally aligned (for performance reasons) or they can be packed together on arbitrary byte boundaries.
Using this directive is an alternative to the compiler option /[NO]ALIGNMENT, which affects the alignment of all fields in record structures and data items in common blocks in the current program unit.
For more information:
See the description of the OPTIONS directive in the Compaq Fortran Language Reference Manual.
5.9.2 Using the cDEC$ UNROLL Directive to Control Loop Unrolling
The cDEC$ UNROLL directive allows you to specify the number of times certain counted DO loops will be unrolled. Place the cDEC$ UNROLL directive before the DO loop you want to control the unrolling of.
Using this directive for a specific loop overrides the value specified by the compiler option /OPTIMIZE=UNROLL= for that loop. The value specified by unroll affects how many times all loops not controlled by their respective cDEC$ UNROLL directives are unrolled.
For more information:
See the the description of the UNROLL directive in the Compaq Fortran Language Reference Manual.
5.9.3 Using the cDEC$ IVDEP Directive to Control Certain Loop Optimizations
The cDEC$ IVDEP directive allows you to help control certain optimizations related to dependence analysis in a DO loop. Place the cDEC$ IVDEP directive before the DO loop you want to help control the optimizations for. Not all DO loops should use this directive.
The cDEC$ IVDEP directive tells the optimizer to begin dependence analysis by assuming all dependences occur in the same forward direction as their appearance in the normal scalar execution order. This contrasts with normal compiler behavior, which is for the dependence analysis to make no initial assumptions about the direction of a dependence.
For more information:
See the the description of the IVDEP directive in the Compaq Fortran Language Reference Manual.
| Previous | Next | Contents | Index |