| Previous | Contents | Index |
This chapter presents the file formats supported by Multimedia Services for OpenVMS. The preferred format for multimedia files is the Resource Interchange File Format (RIFF). The RIFF format is a tagged-file structure.
Multimedia Services for OpenVMS reads the following types of RIFF files:
The remainder of this chapter discusses these types of RIFF files in
detail.
8.1 Resource Interchange File Format (RIFF)
The basic building block of a RIFF file is called a chunk. Each chunk consists of the following fields:
The only chunks allowed to contain other chunks (called
subchunks) are those with a chunk ID of
RIFF
or
LIST
. The first chunk in
a RIFF file must be a
RIFF
chunk. All other chunks in the
file are subchunks of the
RIFF
chunk.
8.1.1 RIFF Chunks
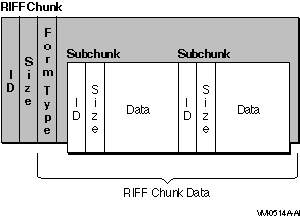
A RIFF chunk includes an additional field in the first four bytes of the data field. This additional field provides the form type of the field. The form type is a four-character code identifying the format of the data stored in the file. For example, Microsoft waveform audio files have a form type of WAVE.
Figure 8-1 shows a RIFF chunk containing two subchunks.
Figure 8-1 RIFF Chunk with Two Subchunks
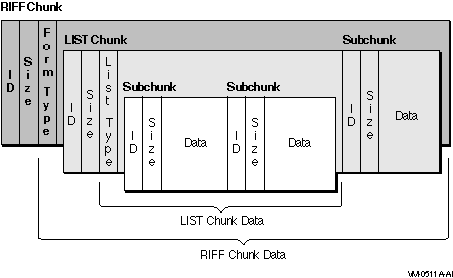
Like a RIFF chunk, a LIST chunk also includes an additional field in the first four bytes of the data field. This additional field contains the list type of the field. The list type is a four-character code identifying the contents of the list. For example, a LIST chunk with a list type of INFO can contain ICOP and ICRD chunks providing copyright and creation data information.
Figure 8-2 shows a RIFF chunk containing a LIST chunk and one other subchunk.
Figure 8-2 RIFF Chunk with LIST Subchunk
This section describes the standard notation used to present format samples of RIFF files. Because RIFF is a binary format, an ASCII representation of a RIFF file, which is easier to understand, is given here.
8.2.1 RIFF File Element Notation
Table 8-1 presents notation conventions used to describe RIFF file
elements.
| Notation | Description |
|---|---|
| <element label> | RIFF file element with the label "element label" |
| <element label:TYPE> | RIFF file element with data type "TYPE" |
| [<element label>] | Optional RIFF file element |
| <element label>... | One or more copies of the specified element |
| [<element label>]... | Zero or more copies of the specified element |
The following sections present additional conventions.
8.2.2 Basic Notation for Representing RIFF Files
Table 8-2 summarizes the basic elements of the RIFF notation necessary to represent sample RIFF files.
| Notation | Description | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| <ckID>(<ckData>) |
The chunk with ID
<ckID>
and data
<ckData>
. The
<ckID>
field is a four-character code that can be enclosed in single quotes
for emphasis.
For example, the following notation describes a
RIFF
chunk with a form type of
QRST.
The data portion of the chunk contains a
FOO
subchunk.
The following example describes an
ICOP
chunk containing the string "Copyright Encyclopedia
International.":
|
||||||||||||||
| <number>[<modifier>] |
A number consisting of an optional sign (+ or -) followed by one or
more digits and modified by the optional modifier. Valid
<modifier>
values are the following:
For example: Note that -1 and 65535 represent the same value. The application reading this file must know whether to interpret the number as signed or unsigned. |
||||||||||||||
| '<chars>' |
A four-character code (32-bit quantity) consisting of a sequence of
zero to four ASCII characters in the given order. If
<chars>
is fewer than four characters long, it is implicitly padded on the
right with blanks. Two single quotes are equivalent to four blanks. For
example:
'RIFF' <chars> can include escape sequences, which are combinations of characters introduced by a backslash (\) and are used to represent other characters. See Table 8-3 for a list of escape sequences. |
||||||||||||||
| "<string>"[<modifier>] |
The sequence of ASCII characters contained in
<string>
and modified by the optional modifiers
<modifier>
. The quoted text can include any of the escape sequences listed in
Table 8-3. Valid
<modifier>
values are the following:
A NULL-terminated string is a string that is followed by a character with ASCII value 0. A size prefix is an unsigned integer, stored as a byte or word, preceding the string characters that specifies the length of the string. In the case of BZ or WZ modifiers, the size prefix specifies the length of the string without the terminating NULL. For example: |
8.2.3 Escape Sequences
Table 8-3 lists the escape sequences that can be used in
four-character codes and
"<string>"
chunks.
| Escape Sequence |
ASCII Value (Decimal) |
Description |
|---|---|---|
| \n | 10 | New-line character |
| \t | 9 | Horizontal tab character |
| \b | 8 | Backspace character |
| \r | 13 | Carriage return character |
| \f | 12 | Form-feed character |
| \\ | 92 | Backslash character |
| \' | 39 | Single-quote character |
| \" | 34 | Double-quote character |
| \ ddd | Octal ddd | Arbitrary character |
Table 8-4 shows the extended notation that can be used in conjunction with the standard notation to unambiguously define the structure of new (user-created) RIFF forms.
| Notation | Description |
|---|---|
| <name> |
A label that refers to some element of the file, where
name
is the name of the label. For example:
<NAME-ck> Conventionally, a label that refers to a chunk is named <ckID-ck> , where cKID is the chunk ID. Similarly, a label that refers to a RIFF form is named <formType-form> , where formType is the name of the form's type. |
| <name> ---> elements |
The actual data represented by
<name>
defined as elements. This states that
<name>
is an abbreviation for elements.
The following example defines label
<GOBL-form>
as representing a RIFF form with chunk ID
GOBL
and data equal to
<form-data>
, where
<form-data>
is a label that is defined in another rule. Note that a label can
represent any data, not just a
RIFF
chunk or form:
|
| Note: A number of atomic labels are defined in Section 8.2.5. These labels refer to primitive data types. | |
| <name:type> |
This is the same as
<name>
, but it also defines
<name>
as equivalent to
<type>
. This notation obviates the following rule:
<name> ---> <type> This allows a symbolic name to be given to an element of a file
format and the specification of the element data type. For example:
The previous example defines
<xyz-coordinate>
to consist of three parts concatenated together:
<x>
,
<y>
, and
<z>
. The definition also specifies that
<x>
,
<y>
, and
<z>
are integers. This notation is equivalent to the following:
|
| [elements] |
An optional sequence of labels and literal data. Surrounded by
brackets, it can be considered an element.
The following example defines form
FOO
with an optional
<header>
chunk followed by a mandatory
<data>
chunk:
|
| el1|el2|...|eln |
Exactly one of the listed elements must be present. The following
example defines the
hdr
chunk's data as containing either
<hdr-x>
,
<hdr-y>
, or
<hdr-z>
:
<hdr-ck> ---> hdr(<hdr-x> | <hdr-y> | <hdr-z>) |
| element... |
One or more occurrences of
element
can be present. Note that an ellipsis has this meaning if it follows an
element; in other cases, such as
A|B|...|Z
, the ellipsis retains its ordinary English meaning. To avoid
confusion, use an ellipsis to indicate one or more occurrences of
element
.
The following example defines the data of the
data
chunk to contain integer
count
followed by one or more occurrences of integer
item
:
|
| [element]... |
Zero or more occurrences of
element
can be present. The following example defines the data of the
data
chunk to contain integer
count
followed by zero or more occurrences of integer
item
:
<data-ck> ---> data(<count:INT> [<item:INT>]...) |
| {elements} |
The group of elements within the braces is considered a single element.
The following example defines
<blorg>
to be either
<this>
,
<that>
, or one or more occurrences of
<other>
:
<blorg> ---> <this> | <that> | <other>... The following example defines
<blorg>
to be either
<this>
or one or more occurrences of
<that>
or
<other>
, intermixed in any way:
|
| struct {...} name |
A structure defined using C syntax. This can be used instead of a
sequence of labels if a C header (include) file is available that
defines the structure. The label used to refer to the structure must be
the same as the structure's typedef name. For example:
<3D_POINT> ---> struct Wherever possible, the types used in the structure should be the types listed in Section 8.2.5 because these types are more portable that C types, such as int . The structure fields are assumed to be present in the file in the order given with no padding or forced alignments. |
| // comment |
An explanatory comment to a rule. For example:
<weekend> ---> 'Sat'|'Sun' // four- |
Table 8-5 lists atomic labels, which are labels that refer to primitive data types.
| Label | Meaning | C Type |
|---|---|---|
| <CHAR> | 8-bit signed integer | signed char |
| <BYTE> | 8-bit unsigned quantity | unsigned char |
| <INT> | 16-bit signed integer | signed int |
| <WORD> | 16-bit unsigned quantity | unsigned int |
| <LONG> | 32-bit signed integer | signed long |
| <DWORD> | 32-bit unsigned integer | unsigned long |
| <FLOAT> | 32-bit IEEE floating-point number | float |
| <DOUBLE> | 64-bit IEEE floating-point number | double |
| <STR> | String (sequence of characters) | -- -- |
| <ZSTR> | NULL-terminated string | -- -- |
| <BSTR> | String with byte (8-bit) size prefix | -- -- |
| <WSTR> | String with word (16-bit) size prefix | -- -- |
| <BZSTR> | NULL-terminated string with byte size prefix | -- -- |
| <WZSTR> | NULL-terminated string with word size prefix | -- -- |
A NULL-terminated string is a string that is followed by a character with ASCII value 0.
A size prefix is an unsigned integer, stored as a byte or a word, that specifies the length of the string. In the case of strings with BZ or WZ modifiers, the size prefix specifies the size of the string without the terminating NULL.
| Previous | Next | Contents | Index |