![[Compaq]](../../images/compaq.gif)
![[Go to the documentation home page]](../../images/buttons/bn_site_home.gif)
![[How to order documentation]](../../images/buttons/bn_order_docs.gif)
![[Help on this site]](../../images/buttons/bn_site_help.gif)
![[How to contact us]](../../images/buttons/bn_comments.gif)
![[OpenVMS documentation]](../../images/ovmsdoc_sec_head.gif)
| Document revision date: 30 March 2001 | |
|
|
|
|
|
|
| Previous | Contents | Index |
The run-time library heap management routines LIB$GET_VM and LIB$FREE_VM provide the mechanism for allocating and freeing blocks of memory.
The LIB$GET_VM and LIB$FREE_VM routines are fully reentrant, so they can be called either by code running at AST level or in an Ada multitasking environment. Several threads of execution can be allocating or freeing memory simultaneously either in the same zone or in different zones.
All memory allocated by LIB$GET_VM has user-mode read/write access, even if the call to LIB$GET_VM is made from a more privileged access mode.
The rules for using LIB$GET_VM and LIB$FREE_VM are as follows:
The run-time library heap management routines provide four algorithms, listed in Table 14-4, that are used to allocate and free memory and that are used to manage blocks of free memory.
| Code | Symbol | Description |
|---|---|---|
| 1 | LIB$K_VM_FIRST_FIT | First Fit |
| 2 | LIB$K_VM_QUICK_FIT | Quick Fit (maintains lookaside list) |
| 3 | LIB$K_VM_FREQ_SIZES | Frequent Sizes (maintains lookaside list) |
| 4 | LIB$K_VM_FIXED | Fixed Size Blocks |
The Quick Fit and Frequent Sizes algorithms use lookaside lists to speed allocation and freeing for certain request sizes. A lookaside list is the software analog of a hardware cache. It takes less time to allocate or free a block that is on a lookaside list.
For each of the algorithms, LIB$GET_VM performs one or more of the following operations:
For each of the algorithms, LIB$FREE_VM performs one or more of the following operations:
The First Fit algorithm (LIB$K_VM_FIRST_FIT) maintains a linked list of
free blocks. If the zone does not have boundary tags, the free list is
kept sorted in order of increasing memory address. An allocation
request is satisfied by the first block on the free list that is large
enough; if the first free block is larger than the request size, it is
split and the fragment is kept on the free list. When a block is freed,
it is inserted in the free list at the appropriate point; adjacent free
blocks are merged to form larger free blocks.
14.6.2 Quick Fit Algorithm
The Quick Fit algorithm (LIB$K_VM_QUICK_FIT) maintains a set of lookaside lists indexed by request size for request sizes in a specified range. For request sizes that are not in the specified range, a First Fit list of free blocks is maintained. An allocation request is satisfied by removing a block from the appropriate lookaside list; if the lookaside list is empty, a First Fit allocation is done. When a block is freed, it is placed on either a lookaside list or the First Fit list according to its size.
Free blocks that are placed on a lookaside list are neither merged with
adjacent free blocks nor split to satisfy a request for a smaller block.
14.6.3 Frequent Sizes Algorithm
The Frequent Sizes algorithm (LIB$K_VM_FREQ_SIZES) is similar to the
Quick Fit algorithm in that it maintains a set of lookaside lists for
some block sizes. You specify the number of lookaside lists when you
create the zone; the sizes associated with those lists are determined
by the actual sizes of blocks that are freed. An allocation request is
satisfied by searching the lookaside lists for a matching size; if no
match is found, a First Fit allocation is done. When a block is freed,
the block is placed on a lookaside list with a matching size, on an
empty lookaside list, or on the First Fit list if no lookaside list is
available. As with the Quick Fit algorithm, free blocks on lookaside
lists are not merged or split.
14.6.4 Fixed Size Algorithm
The Fixed Size algorithm (LIB$K_VM_FIXED) maintains a single queue of
free blocks. There is no First Fit free list, and splitting or merging
of blocks does not occur.
14.7 User-Defined Zones
When you create a zone by calling LIB$CREATE_VM_ZONE, you must select an allocation algorithm from the fixed set provided by the run-time library. You can tailor the characteristics of the zone by specifying various zone attributes. User-defined zones provide additional flexibility and control by letting you supply routines for the allocation and deallocation algorithms.
You create a user-defined zone by calling LIB$CREATE_USER_VM_ZONE. Instead of supplying values for a fixed set of zone attributes, you provide routines that perform the following operations for the zone:
Each time that one of the run-time library heap management routines (LIB$GET_VM, LIB$FREE_VM, LIB$RESET_VM_ZONE, LIB$DELETE_VM_ZONE) is called to perform an operation on a user-defined zone, the corresponding routine that you specified is called to perform the actual operation. You need not make any changes in the calling program to use user-defined zones; their use is transparent.
You do not need to provide routines for all four of the preceding operations if you know that your program will not perform certain operations. If you omit some of the operations and your program attempts to use them, an error status is returned.
Applications of user-defined zones include the following:
| Example 14-1 Monitoring Heap Operations with a User-Defined Zone | |||
|---|---|---|---|
C+
C This is the main program that creates a zone and exercises it.
C
C Note that the main program simply calls LIB$GET_VM and LIB$FREE_VM.
C It contains no special coding for user-defined zones.
C-
PROGRAM MAIN
IMPLICIT INTEGER(A-Z)
CALL MAKE_ZONE(ZONE)
CALL LIB$GET_VM(10, I1, ZONE)
CALL LIB$GET_VM(20, I2, ZONE)
CALL LIB$FREE_VM(10, I1, ZONE)
CALL LIB$RESET_VM_ZONE(ZONE)
CALL LIB$DELETE_VM_ZONE(ZONE)
END
C+
C This is the subroutine that creates a user-defined zone for monitoring.
C Each GET, FREE, or RESET prints a line of output on the terminal.
C Errors are signaled.
C-
SUBROUTINE MAKE_ZONE(ZONE)
IMPLICIT INTEGER (A-Z)
EXTERNAL GET_RTN, FREE_RTN, RESET_RTN, LIB$DELETE_VM_ZONE
C+
C Create the primary zone. The primary zone supports
C the actual allocation and freeing of memory.
C-
STATUS = LIB$CREATE_VM_ZONE(REAL_ZONE)
IF (.NOT. STATUS) CALL LIB$SIGNAL(%VAL(STATUS))
C+
C Create a user-defined zone that monitors operations on REAL_ZONE.
C-
STATUS = LIB$CREATE_USER_VM_ZONE(USER_ZONE, REAL_ZONE,
1 GET_RTN,
1 FREE_RTN,
1 RESET_RTN,
1 LIB$DELETE_VM_ZONE)
IF (.NOT. STATUS) CALL LIB$SIGNAL(%VAL(STATUS))
C+
C Return the zone-id of the user-defined zone to the caller to use.
C-
ZONE = USER_ZONE
END
C+
C GET routine for user-defined zone.
C-
FUNCTION GET_RTN(SIZE, ADDR, ZONE)
IMPLICIT INTEGER(A-Z)
STATUS = LIB$GET_VM(SIZE, ADDR, ZONE)
IF (.NOT. STATUS) THEN
CALL LIB$SIGNAL(%VAL(STATUS))
ELSE
TYPE 10, SIZE, ADDR
10 FORMAT(' Allocated ',I4,' bytes at ',Z8)
ENDIF
GET_RTN = STATUS
END
C+
C FREE routine for user-defined zone.
C-
FUNCTION FREE_RTN(SIZE, ADDR, ZONE)
IMPLICIT INTEGER(A-Z)
STATUS = LIB$FREE_VM(SIZE, ADDR, ZONE)
IF (.NOT. STATUS) THEN
CALL LIB$SIGNAL(%VAL(STATUS))
ELSE
TYPE 20, SIZE, ADDR
20 FORMAT(' Freed ',I4,' bytes at ',Z8)
ENDIF
FREE_RTN = STATUS
END
C+
C RESET routine for user-defined zone.
C-
FUNCTION RESET_RTN(ZONE)
IMPLICIT INTEGER(A-Z)
STATUS = LIB$RESET_VM_ZONE(ZONE)
IF (.NOT. STATUS) THEN
CALL LIB$SIGNAL(%VAL(STATUS))
ELSE
TYPE 30, ZONE
30 FORMAT(' Reset zone at ', Z8)
ENDIF
RESET_RTN = STATUS
END
|
14.8 Debugging Programs That Use Virtual Memory Zones
This section discusses some methods and aids for debugging programs
that use virtual memory zones. Note that this information is
implementation dependent and may change at any time.
The following list offers some suggestions for discovering and tracking problems with memory zone usage:
This chapter describes the importance and techniques of alignment for both OpenVMS VAX and OpenVMS Alpha systems.1 It contains the following subsections:
Section 15.1 describes alignment on OpenVMS VAX and OpenVMS Alpha systems.
Section 15.2 describes using compilers for alignment.
Section 15.3 describes using various tools to uncover unaligned data.
1 Reprinted from an article in the March/April 1993 issue of Digital Systems Journal, Volume 15, Number 2, titled "Alpha AXP(TM) Migration: Understanding Data Alignment on OpenVMS AXP Systems" by Eric M. LaFranchi and Kathleen D. Morse. Copyright 1993 by Cardinal Business Media, Inc., 101 Witmer Road, Horsham, PA 19044. |
Alignment is an aspect of a data item that refers to its placement in memory. The mixing of byte, word, longword, and quadword data types can lead to data that is not aligned on natural boundaries. A naturally aligned datum of size 2**N is stored in memory at a starting byte address that is a multiple of 2**N, that is, an address that has N low-order zero bits. Data is naturally aligned when its address is an integral multiple of the size of the data in bytes (for example, when the following occurs):
Data that is not aligned is referred to as unaligned. Throughout this chapter, the term aligned is used instead of naturally aligned.
Table 15-1 shows examples of common data sizes, their alignment, the number of zero bits in an aligned address for that data, and a sample aligned address in hexadecimal.
| Data Size | Alignment | Zero Bits | Aligned Address Example |
|---|---|---|---|
| Byte | Byte | 0 | 10001, 10002, 10003, 10004 |
| Word | Word | 1 | 10002, 10004, 10006, 10008 |
| Longword | Longword | 2 | 10004, 10008, 1000C, 10010 |
| Quadword | Quadword | 4 | 10008, 10010, 10018, 10020 |
An aligned structure has all its members aligned. An unaligned structure has one or more unaligned members. Figure 15-1 shows examples of aligned and unaligned structures.
Figure 15-1 Aligned and Unaligned Structures
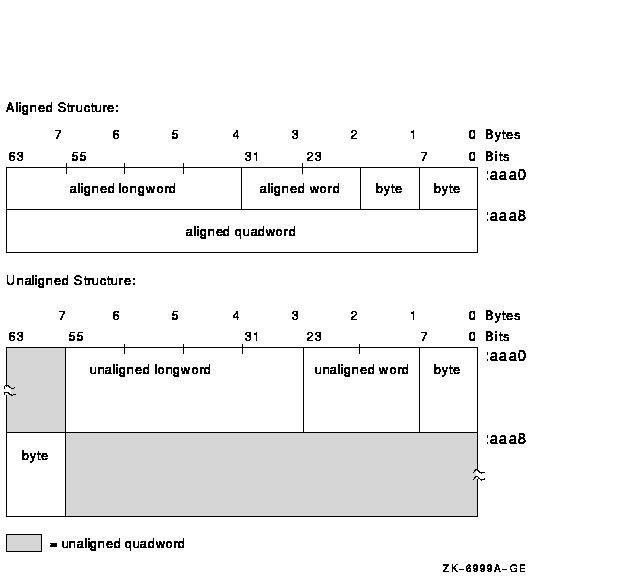
To achieve optimal performance, use aligned instruction sequence references and naturally aligned data. When unaligned data is referenced, more overhead is required than when referencing aligned data. This condition is true for both OpenVMS VAX and Alpha systems. On both VAX and Alpha systems, data need not be aligned to obtain correct processing results. Alignment is a concern for performance, not program correctness. Because natural alignment is not always possible, both OpenVMS VAX and Alpha systems provide help to manage the impact of unaligned data references.
Although alignment is not required on VAX systems for stack, data, or
instruction stream references, Alpha systems require that the stack and
instructions be longword aligned.
15.1.1.1 Alignment on OpenVMS VAX (VAX Only)
On VAX systems, memory references that are not longword aligned result
in a transparent performance degradation. The full effect of unaligned
memory references is hidden by microcode, which detects the unaligned
reference and generates a microtrap to handle the alignment correction.
This fix of alignment is done entirely in microcode. Aligned
references, on the other hand, avoid the microtraps to handle fixes.
Even with this microcode fix, an unaligned reference can take up to
four times longer than an aligned reference.
15.1.1.2 Alignment on OpenVMS Alpha (Alpha Only)
On Alpha systems, you can check and correct alignment the following three ways:
Though Alpha systems do not use microcode to automatically handle unaligned references, PALcode traps the faults and corrects unaligned references as the data is processed. If you use the shorter load/store instruction sequences and your data in unaligned, then you incur an alignment fault PALcode fixup. The use of PALcode to correct alignment faults results in the slowest of the three ways to process your data.
By using directives to the compiler, you can tell your compiler to create a safe set of instructions. If it is unaligned, the compiler uses a set of unaligned load/store instructions. These unaligned load/store instructions are called safe sequences because they never generate unaligned data exceptions. Code sequences that use the unaligned load/store instructions are longer than the aligned load/store instruction sequences. By using unaligned load/store instructions and longer instruction sequences, you can obtain the desired results without incurring an alignment trap. This technique allows you to avoid the significant performance impact of a trap and subsequent data fixes.
By fixing the data yourself so that it is aligned, you can use a short instruction stream. This results in the fastest way to process your data. When aligning data, the following recommendations are suggested:
To detect unaligned reference information, you can use utilities such
as the OpenVMS Debugger and Performance and Coverage Analyzer (PCA).
You can also use the OpenVMS Alpha handler to generate optional
informational exceptions for process space references. This allows
condition handlers to track unaligned references. Alignment fault
system services allow you to enable and disable the delivery of these
informational exceptions. Section 15.3.3 discusses system services that
you can use to report both image and systemwide alignment problems.
15.2 Using Compilers for Alignment (Alpha Only)
On Alpha systems, compilers automatically align data by default. If
alignment problems are not resolved, they are at least flagged. The
following sections present how the compilers for Compaq C, BLISS,
Compaq Fortran, and MACRO-32 deal with alignment.
15.2.1 The Compaq C Compiler (Alpha Only)
On Alpha systems, the Compaq C compiler naturally aligns all explicitly declared data, including the elements of data structures. The pragmas member_alignment and nomember_alignment allow data structures to be aligned or packed (putting the next piece of data on the next byte boundary) in the same manner as the VAX C compiler. Additional pragmas of member_alignment save and member_alignment restore exist to save and restore the state of member alignment. These prevent alignment assumptions in one include file from affecting other source code. The following program examples show the use of these pragmas:
#pragma member_alignment save (1)
#pragma nomember_alignment (2)
struct
{
char byte;
short word;
long longword;
} mystruct;
#pragma member_alignment restore (3)
|
The base alignment of a data structure is set to be the alignment of the largest member in the structure. If the largest element of a data structure is a longword, for example, then the base alignment of the data structure is longword alignment.
The malloc() function of the Compaq C Run-Time Library retrieves pointers that are at least quadword aligned. Because it is the exception rather than the rule to encounter unaligned data in C programs, the compiler assumes most data references are aligned. Pointers, for example, are always assumed to be aligned; only data structures declared with the pragma nomember_alignment are assumed to contain unaligned data. If the Compaq C compiler believes the data might be unaligned, it generates the safe instruction sequences; that is, it uses the unaligned load/store instructions. Also, you can use the /WARNING=ALIGNMENT compiler qualifier to turn on alignment checking by the compiler. This results in a compiler warning for unaligned data references.
| Previous | Next | Contents | Index |
|
|
| privacy and legal statement | ||
| 5841PRO_046.HTML | ||