| 前へ | 次へ | 目次 | 索引 |
この章では,日本語ソート/マージ (SORT/MERGE) について説明します。
3.1 機能概要
日本語ソート/マージは漢字が持つ属性(音読み,訓読み,部首,総画数)および振り仮名フィールドによる国語辞典方式にしたがってソート/マージ処理を行うものです。
本書は Compaq OpenVMS オペレーティング・システムの SORT/MERGE のマニュアルを読んでいることを前提にして記述されていますので,必要に応じて次のマニュアルを参照してください。
Compaq OpenVMS 標準版SORT/MERGEは次の日本語用機能も認識するようになっています。
これらの機能は,OpenVMS の SORT/MERGE の漢字属性内部辞書を使うことにより行われます。
図 3-1 日本語ソート /マージ処理フロー
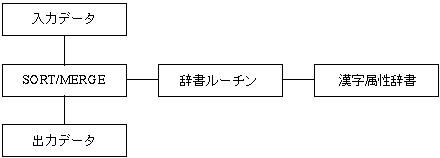
つまり日本語ソート/マージは,標準版SORT/MERGEに日本語用のモジュールを追加したものであり,標準版SORT/MERGEの DCL コマンドである SORT,MERGE により,日本語データも日本語以外のデータと同じように処理できるようになっています。
3.2 日本語ソート機能の方式
3.2.1 基本方式
KEY フィールドによって指定されたフィールドを漢字の音読み,訓読み,部首コード,総画数あるいは,JIS コード・テーブルの順に並べかえることができます。
| 音読み | 漢字属性辞書の第1音読みによる。 |
| 訓読み | 漢字属性辞書の第1訓読みによる。 |
| 部首コード | JIS 部首コードによる。 |
| 総画数 | 画数による。 |
| JIS コード・テーブル | JIS X 0208 コード・テーブルによる。 |
ユーザが指定した全角(ひらがなか,カタカナ)または半角(カタカナ)の振り仮名フィールドを次の照合順序によって並べかえることができます。
また,繰り返し記号は,1文字前の文字を使い,長音符号については1文字前の文字の母音が使われます。
したがって
カート カァト ガード ガート カアト カヽト カカト カガト ガアド ガヽド ガァト
を / KEY = (POSITION:1, SIZE:6, KOKUGO) でソートすると,次のようになります。
カアト カート カァト ガート ガァト ガアド ガード カカト カヽト カガト ガヽド
この節では,SORT と MERGE コマンドの使用方法および日本語ソート/マージ・サブルーチンについて説明します。
3.3.1 日本語用機能
KEY 修飾子に日本語用として次のものを追加しています。
以下に使用例を示します。
SORT/KEY=(POSITION:1, SIZE:2, ONYOMI) INDATA.DAT ONDATA.DAT |
SORT/KEY=(POSITION:1, SIZE:2, KUNYOMI) INDATA.DAT KUNDATA.DAT |
MERGE/KEY=(POSITION:1, SIZE:2, BUSHU) IN1.DAT, IN2.DAT BUSHDATA.DAT |
MERGE/KEY=(POSITION:1, SIZE:2, SOKAKU) IN1.DAT, IN2.DAT SOKADATA.DAT |
SORT/KEY=(POSITION:10, SIZE:6, KOKUGO) INDATA.DAT SOKADATA.DAT |
MERGE/KEY=(POSITION:20, SIZE:8, KANA8BIT) IN1.DAT, IN2.DAT SOKADATA.DAT |
SORT/KEY=(POSITION:1, SIZE:2, JISCODE) INDATA.DAT SOKADATA.DAT |
また,日本語フィールドの場合には,DCLより同時に複数のソート方式を指定することが可能です。たとえば次のように指定できます。
SORT/KEY=(POSITION:30, SIZE:6, SOKAKU, ONYOMI, JISCODE) IN.DAT OUT.DAT |
これは次の指定方法と同等です。
SORT/KEY=(POSITION:30, SIZE:6, SOKAKU) -
/KEY=(POSITION:30, SIZE:6, ONYOMI) -
/KEY=(POSITION:30, SIZE:6, JISCODE) IN.DAT OUT.DAT
|
3.3.3 仕様ファイル (Specification file) 中の使用方法
仕様ファイルの中でも,日本語データ・タイプを使用できます。標準版のドキュメントであげてあるデータ・タイプ(『 OpenVMS ユーザーズ・マニュアル』を参照)以外に,次の疑似データ・タイプを使用できます。
| ONYOMI | (音読み) |
| KUNYOMI | (訓読み) |
| BUSHU | (部首コード) |
| SOKAKU | (総画数) |
| KOKUGO | (国語辞典方式全角振り仮名) |
| KANA8BIT | (国語辞典方式半角振り仮名) |
| JISCODE | (JIS コード・テーブル) |
以下に使用例を示します。
$ SORT/SPECIFICATION=SPEC.SRT DATA.DAT OUT.DAT |
SPEC.SRT は以下のとおりです。
/FIELD=(NAME=KASHIRA, POSITION:1, SIZE:2, SOKAKU) ------(1) /FIELD=(NAME=NAMAE, POSITION:1, SIZE:20, BUSHU) ------(2) /FIELD=(NAME=JUSHO, POSITION:21, SIZE:56) ------(3) /KEY=NAMAE ------(4) /DATA=JUSHO ------(5) /DATA=" " ------(6) /DATA=NAMAE ------(7) /CONDITION=(NAME=LEIWA, TEST=(KASHIRA LE "岩")) ------(8) /INCLUDE=(CONDITION=LEIWA) ------(9) |
(1), (2), (3) は "KASHIRA","NAMAE","JUSHO" という3つのフィールドを定義します。 (4)によって,"NAMAE" フィールドを使って1バイト目から 20 バイトを部首順にソートすることが指定されます。この例では,全部のレコードを出力するのではなく, (8), (9) で選択したレコードのみを出力します。つまり,"NAMAE" フィールドの先頭の文字の総画数が, "岩" の総画数 8 と同じか,または少ないレコードのデータだけを出力するということです。出力フォーマットは (5),(6),(7) によって指定されています。
以下の DATA-1 が DATA.DAT の場合, DATA-2 が結果として OUT.DAT に出力されます。
<DATA-1>
| 岩田誠 | 東京都世田谷区桜上水5丁目3−5 |
| 山本武則 | 東京都杉並区下高井戸1丁目12−35 |
| 白鹿正通 | 東京都葛飾区亀有2丁目24−10 清風荘203号室 |
| 米沢佳美 | 千葉県千葉市板倉町1丁目2−5 |
| 藤井久継 | 東京都練馬区豊玉中2丁目25 JBLコーポ102号室 |
| 飯田秀一 | 東京都世田谷区代田1丁目2−35 豊中マンション801号 |
| 南野陽子 | 東京都新宿区馬場下町3丁目1−1 |
| 近藤佳明 | 東京都杉並区大宮1丁目3−13 壬生川コーポ304号室 |
| 波頭陽一 | 東京都葛飾区柴又5丁目10−22 |
| 田窪健三 | 東京都杉並区永福3丁目32−14 |
<DATA-2>
| 東京都杉並区下高井戸1丁目12−35 | 山本武則 |
| 東京都葛飾区柴又5丁目10−22 | 波頭陽一 |
| 東京都杉並区永福3丁目32−14 | 田窪健三 |
| 東京都葛飾区亀有2丁目24−10 清風荘203号室 | 白鹿正通 |
| 東京都世田谷区桜上水5丁目3−5 | 岩田誠 |
| 千葉県千葉市板倉町1丁目2−5 | 米沢佳美 |
| 東京都杉並区大宮1丁目3−13 壬生川コーポ3O4号室 | 近藤佳明 |
3.4 日本語ソート/マージ・サブルーチン
3.4.1 日本語ソート/マージ・サブルーチンの機能
標準版SORT/MERGE は以下のサブルーチンを提供しています。
これらのサブルーチンの使い方やパラメータなどについては,『 OpenVMS Utility Routines Manual 』または『 OpenVMS Programming Enviroment Manual 』を参照してください。日本語ソート/マージでは,標準版 SORT/MERGE サブルーチンの機能に加えて次の日本語機能が追加されています。
| SOR$K_SEQ_ONYOMI | 音読み |
| SOR$K_SEQ_KUNYOMI | 訓読み |
| SOR$K_SEQ_BUSHU | 部首コード |
| SOR$K_SEQ_SOKAKU | 総画数 |
| SOR$K_SEQ_KOKUGO | 国語辞典方式全角振り仮名 |
| SOR$K_SEQ_KANA8BIT | 国語辞典方式半角振り仮名 |
| SOR$K_SEQ_JISCODE | JIS コード・テーブル |
これらのコードは SYS$LIBRARY:IMAGELIB.OLB に含まれているので,特別な指定なしにリンク時に自動的にセットされます。長さはワード( 16 ビット)です。
3.4.2 ソート/マージ・サブルーチンの使用例
このプログラムは,ファイル " EXAM1.DAT " の最初の 12 バイト,つまり6文字の振り仮名フィールドを国語辞典順にソートし " EXAM1OUT.DAT " に出力します。
IMPLICIT INTEGER*4 (A-Z)
INTEGER*2 KEYBUFF(5)
CHARACTER*9 IN_FILE
CHARACTER*12 OUT_FILE
EXTERNAL SOR$K_SEQ_KOKUGO
DATA IN_FILE, OUT_FILE /'EXAM1.DAT', 'EXAM1OUT.DAT'/
KEYBUFF(1) = 1 ! Number of KEY
KEYBUFF(2) = %LOC(SOR$K_SEQ_KOKUGO) ! Kokugo dictionary sequence
KEYBUFF(3) = 0 ! Ascending sort
KEYBUFF(4) = 0 ! Key offset
KEYBUFF(5) = 12 ! Size in bytes
STATUS = SOR$PASS_FILES(IN_FILE, OUT_FILE)
IF (.NOT. STATUS) GOTO 10
STATUS = SOR$BEGIN_SORT(KEYBUFF)
IF (.NOT. STATUS) GOTO 10
STATUS = SOR$SORT_MERGE( )
IF (.NOT. STATUS) GOTO 10
STATUS = SOR$END_SORT( )
IF (.NOT. STATUS) GOTO 10
STOP 'SUCCESS'
10 CONTINUE
STOP 'FAILURE'
END
|
このプログラムは,入力はファイル渡し,出力はレコード渡しを使っています。またキーは2つあり,第1キーは総画数で昇順,第2キーは部首コードで降順となっています。
C Define external functions and data and initialize
IMPLICIT INTEGER*4 (A-Z)
CHARACTER*80 RECBUF
CHARACTER*9 INPUTNAME !Input file name
INTEGER*2 KEYBUF(9) !Key definition buffer
EXTERNAL SS$_ENDOFFILE
EXTERNAL SOR$GK_RECORD
EXTERNAL SOR$K_SEQ_BUSHU !Bushu collating sequence
EXTERNAL SOR$K_SEQ_SOKAKU !Sokaku collating sequence
DATA INPUTNAME/'EXAM2.DAT'/
KEYBUF(1) = 2
KEYBUF(2) = %LOC(SOR$K_SEQ_SOKAKU) !Primary key SOKAKU
KEYBUF(3) = 0 !Ascending
KEYBUF(4) = 0 !offset 0
KEYBUF(5) = 10 !size 10
KEYBUF(6) = %LOC(SOR$K_SEQ_BUSHU) !Secondary key BUSHU
KEYBUF(7) = 1 !Descending
KEYBUF(8) = 0 !offset 0
KEYBUF(9) = 10 !size 10
SRTTYPE = %LOC(SOR$GK_RECORD)
C Pass SORT the file names.
ISTATUS = SOR$PASS_FILES(INPUTNAME)
IF (.NOT. ISTATUS) GOTO 10
C Initialize the work areas and keys.
ISTATUS = SOR$BEGIN_SORT(KEYBUF, , , , , , SRTTYPE, %REF(3))
IF (.NOT. ISTATUS) GOTO 10
C Sort the records.
ISTATUS = SOR$SORT_MERGE( )
IF (.NOT. ISTATUS) GOTO 10
C Now retrieve the individual records and display them.
5 ISTATUS = SOR$RETURN_REC(RECBUF)
IF (.NOT. ISTATUS) GOTO 6
ISTATUS = LIB$PUT_OUTPUT(RECBUF)
GOTO 5
6 IF (ISTATUS .EQ. %LOC(SS$_ENDOFFILE)) GOTO 7
GOTO 10
C Clean up the work areas and files.
7 ISTATUS = SOR$END_SORT()
IF (.NOT. ISTATUS) GOTO 10
STOP 'SORT SUCCESSFUL'
10 STOP 'SORT UNSUCCESSFUL'
END
|
このプログラムは,2つの入力ファイルのマージを行います。キーはオフセット5より 6バイトつまり漢字3文字で入力ファイルが正確に順番どおりになっているかをチェックします。
#include <stsdef.h>
struct DESCRIPTOR {
int leng ;
char *ptr ;
};
globalvalue SOR$K_SEQ_ONYOMI,
SOR$M_SEQ_CHECK;
main(){
char infile1[] = "EXAM31.DAT" ,
infile2[] = "EXAM32.DAT" ,
outfile[]= "EXAM3OUT.DAT" ;
struct DESCRIPTOR
inptr1 ={strlen(infile1) , infile1},
inptr2 ={strlen(infile2) , infile2},
outptr ={strlen(outfile) , outfile};
short lrl, key[5] ;
int status, option;
/* initialize the key */
key[0] = 1 ; /* key no. */
key[1] = SOR$K_SEQ_ONYOMI ; /* onyomi */
key[2] = 0 ; /* ascend */
key[3] = 5 ; /* offset */
key[4] = 6 ; /* size */
lrl = 131; /* LRL */
option = SOR$M_SEQ_CHECK; /* check input sequence */
/* merge the files */
if (!((status=sor$pass_files(&inptr1, &outptr)) & STS$M_SUCCESS))
lib$stop(status);
if (!((status=sor$pass_files(&inptr2)) & STS$M_SUCCESS))
lib$stop(status);
if (!((status=sor$begin_merge(key, &lrl, &option)) & STS$M_SUCCESS))
lib$stop(status);
if (!((status=sor$end_sort()) & STS$M_SUCCESS))
lib$stop(status);
}
|
| 前へ | 次へ | 目次 | 索引 |