| 前へ | 次へ | 目次 | 索引 |
省略時の設定では,Sort/Merge は同一キー・フィールドでレコードを保持しますが,それらのレコードを,入力ファイル中で現れた順序と同じ順序で保持するとは限りません。このようなレコードが存在すると思われる場合には,次の修飾子のいずれかを使用してその扱い方を指定することができます。
同じキーを持つレコードを入力順序で残す。複数の入力ファイルをソートするときにこの修飾子を使用すると,同じキーを持つレコードが最初のファイルにあれば, 2番目のファイルの前に並べられることになる。 2番目以降についても同様の方法で処理される。
1 つを残し,他の重複レコードをすべて排除する。そのまま残す重複レコードを指定する場合,プログラム・レベルでSortを起動し,同一キー・ルーチンを指定する。
/STABLE修飾子と/NODUPLICATES修飾子は互換性がないため,同一コマンド行で両方の修飾子を指定することはできません。
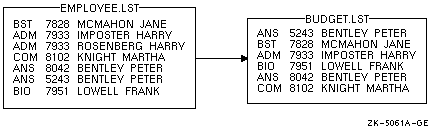
次の例では,アカウント番号が重複するレコードは,ファイル EMPLOYEE.LST から削除されます。
$ SORT /KEY=(POSITION:5,SIZE:4)/NODUPLICATES EMPLOYEE.LST BUDGET.LST |
図 11-7 はこのソート操作の結果を示しています。
図 11-7 同じキーを持つ場合のソート結果
文字データ以外の項目を含むレコードをソートする場合は,それぞれのキーでデータ型を指定します。また,比較する項目が2バイト以上占有することもあるため,開始位置とサイズを注意深く計算するようにします。
20個の文字の後に,F_floating形式の浮動小数を3つ含むファイルをソートする場合,位置は次のようになります。
3番目の浮動小数でファイルをソートするときは,キー・フィールドを次のように指定します。
$ SORT/KEY=(POSITION:29,F_FLOATING) STATS.RAW STATS.SOR |
浮動小数のサイズは4バイトに固定されているため,サイズを指定する必要はありません。
11.2.5 出力ファイルの編成
省略時の設定では,Sort は,最初の入力ファイルと同じファイル編成の出力ファイルを生成します。入力ファイルと異なる出力ファイル編成を指定するときは, Sortのコマンド行で出力ファイルを指定した後に次のいずれかの修飾子を指定します。
この出力修飾子を使用すると,ファイル・レコードの形式,長さ,ブロック・サイズを定義できます。
この修飾子を使用すると,出力を索引順編成ファイル編成に定義できます。出力ファイル編成として索引順編成を指定する場合は,次の操作も行わなければなりません。
この修飾子を使用すると,出力を相対ファイル編成に定義できます。
この修飾子を使用すると,出力を順ファイル編成に定義できます。
次の例では,索引付き順編成ファイル EMPLOYEE.LST をソートした後,順編成ファイルが作成されます。
$ SORT/KEY=(POSITION:10,SIZE:15) - _$ EMPLOYEE.LST BYNAME.LST/SEQUENTIAL |
Sortは,レコード,タグ,アドレス,索引などの内部プロセスを1つ使用して,ファイルの整列を行います。 (高性能Sort/Mergeユーティリティでは,レコード・プロセスのみがサポートされます。タグ,アドレス,索引の各プロセスについては, OpenVMS Alphaの将来のリリースでサポートされる予定です。) 指定するプロセスによっては,Sort操作の効率が変わることもあります。 Sort操作,Merge操作の最適化については, 第 11.8 節 を参照してください。
次の表は,プロセスの4つのタイプを示しています。ソート・プロセスを指定するときは, /PROCESS=タイプ修飾子を使用します。
| ソート・プロセス | タイプ | 説明 |
|---|---|---|
| レコード | RECORD | ソートを行うときレコードを完全な状態のまま残し,完全なレコードで構成される出力ファイルを作成する。レコードが省略時のソート・プロセスになる。 |
| タグ | TAG | キー・フィールドのみをソートしてから,入力ファイルを読み込み直し,完全なレコードの出力ファイルを作成する。実際の結果は,完全なレコード・ソートの場合と同じになる。
タグ・ソートは通常,ソート時に作業ファイルの領域をあまり使用しないため,ディスク領域が少ない場合に使用するのに適している。ほとんどの場合,タグ・ソートは,レコード・ソートよりも処理速度が遅くなる。これは,入力ファイルを読み込み直すときに余分の時間が必要になるためである。 |
| アドレス | ADDRESS | キー・フィールドのみをソートし,
レコード・ファイル・アドレス(RFA)の索引になる出力ファイルを,バイナリ形式で作成する。
アドレス・ソートは,レコード・ソートよりも高速であるが,レコード・アドレスを入力ファイルのレコードと対応させるプログラムを記述する必要がある。 |
| 索引 | INDEX | キー・フィールドのみをソートし,キーとRFAの出力ファイルを(バイナリ形式で)作成する。
アドレス・ソートの場合と同様に,索引ソートもレコード・ソートより高速であるが,レコード・アドレスを入力ファイルのレコードと対応させるプログラムを記述する必要がある。 |
11.3 照合順序の指定
文字は,照合順序の順番に従って,ソートされます。文字データを含むファイルの場合は, /COLLATING_SEQUENCE=sequence修飾子を使用して,照合順序を指定します。次の表は,照合順序オプションについて説明しています。
| 照合順序 | 順序 | 説明 |
|---|---|---|
| ASCII | ASCII | 文字データの場合,省略時の照合順序になる。 ASCII順序では,数字(0〜9),大文字(A〜Z),小文字(a〜z)の順番になる。 |
| EBCDIC | EBCDIC | EBCDIC 順序で並べられた出力ファイルを生成する。データはASCII表現のままになる。 EBCDIC順序では,小文字(a〜z),大文字(A〜Z),数字(0〜9)の順番になる。 |
| DEC で定義している文字セット | MULTINATIONAL | MULTINATIONAL照合順序では,DEC で定義している文字セットに従って文字を整列させる( 付録 B を参照)。 MULTINATIONALの文字順序では,文字は次の規則で並べられる。
|
| 国別文字セット(NCS) | 照合順序名 | 指定する照合順序は,NCSライブラリで定義されていなければならない。詳細は,『OpenVMS National Character Set Utility Manual』を参照。 NCS照合順序は,` でサポートされており,指定ファイルではサポートされていない。
(高性能 Sort/Merge ユーティリティは,NCS 照合順序をサポートしていない。 OpenVMS Alpha の将来のリリースでサポートされる予定である。) |
| ユーザ定義順序 | (順序文字列) | ユーザ定義照合順序を指定する。ユーザ定義照合順序は,指定ファイルでのみサポートされており,コマンド行インタフェースではサポートされていない。
(高性能 Sort/Merge ユーティリティは,ユーザ定義順序をサポートしていない。 OpenVMS Alpha の将来のリリースではサポートされる予定である。) |
| 単一文字または二重文字の文字列,あるいは単一の文字を複数集めた文字の集まりを指定することによって,照合順序を定義する。二重文字は,単一の文字を2つ集めて1文字のように扱う。たとえば,整列するときに"CH"を"C"として扱うよう定義することができる。この文字列は括弧で囲んで指定する。
基数演算子%O,%D,%Xを使用して,それぞれ8進,10進,16進の値で,文字を表現することもできる。 照合順序を定義するとき,次の規則を守らなければならない。
次の文字列は,二重文字LLがLとMの間の単一文字として照合される照合順序を定義する。
|
DEC で定義している照合順序を使用して,ファイルをソートまたはマージするときには注意が必要です。ほとんどのプログラミング言語のシーケンス・チェック・プロシージャは,数字を比較します。 DEC で定義している照合順序は,グラフィック文字を表すコードを比較するのではなく,実際のグラフィック文字を比較するため,通常のシーケンス・チェックは正しく動作しません。 |
次の例は,指定ファイルで使用するために,ユーザ定義照合順序を作成する方法を示しています。指定ファイルについての詳細は, 第 11.7 節 を参照してください。
(/COLLATING_SEQUENCE=(SEQUENCE=ASCII,IGNORE=("-"," "))
|
このように,/COLLATING_SEQUENCE修飾子にIGNOREオプションを指定した場合,次のフィールドが比較されるとき同じものとして扱われ,タイブレークになります。
252-3412
252 3412
2523412
|
/COLLATING_SEQUENCE=(SEQUENCE=("A"-"L","LL","M"-"R","RR","S"-"Z"))
|
この/COLLATING_SEQUENCE修飾子は,二重文字LLがLとMの間の単一文字として照合され,二重文字RRがRとSの間の単一文字として照合される順序を定義します。このような定義がなければ,これらの二重文字は,通常のアルファベット順と同様になります。省略時の場合,このユーザ定義順序によって,小文字のaからzのような,他の文字が定義されることはありません。
バッチ・ジョブとは,現在のセッションとは独立して実行するプログラムや DCL コマンド・プロシージャのことです。大きなファイルをソートする場合には,ソート操作を終了するまでに時間がかかるので,ソート操作をバッチ・ジョブとして登録することを検討してみてください。バッチ・ジョブは,現在のセッションとは独立してバッチ・ジョブとコマンド・プロシージャについての詳細は, 第 18 章 , 第 15 章 ,および 第 16 章 を参照してください。
11.4.1 コマンド・プロシージャ
コマンドを画面に記述するのと同様の方法で,コマンド・プロシージャにSORTコマンドを指定します。省略時のディレクトリにソートするファイルがない場合は,コマンド・プロシージャで省略時のディレクトリを明示的に設定するか,コマンド・ファイル指定にディレクトリを入れるようにします。
次の例では,DCLコマンド・プロシージャSORTJOB.COMをバッチ・ジョブとして登録しています。コマンド・プロシージャのテキストをコマンド行の後に示します。
$ SUBMIT SORTJOB |
! SORTJOB.COM ! $ SET DEFAULT [USER.PER] ! Set default to location of input files $ SORT/KEY=(POSITION:10,SIZE:15) EMPLOYEE.LST BYNAME.LST $ TYPE BYNAME.LST $ EXIT |
バッチ・ジョブには,入力レコードを含めておくことができます。これには,SORT コマンドの後に入力レコードを 1 行に 1 つずつ指定します。ただし,個々のソート・レコードは 2 行以上になってもかまいません。
レコードをターミナルから入力する場合と同様に,入力ファイル・パラメータには SYS$INPUT を指定します。その後に/FORMAT修飾子を使用して,レコード・サイズ(バイト数)とおおよそのファイル・サイズ(ブロック数)を指定します。 80 文字の行が 6 行で 1 ブロックとほぼ等しくなります。
次の例は,入力レコードを含めたコマンド・プロシージャを示しています。
$ SUBMIT SORTJOB |
! SORTJOB.COM ! $ SET DEFAULT [USER.PER] $ SORT/KEY=(POSITION:10,SIZE:15) - SYS$INPUT- /FORMAT=(RECORD_SIZE:24,FILE_SIZE:10) - BYNAME.LST $ DECK BST 7828 MCMAHON JANE ADM 7933 ROSENBERG HARRY COM 8102 KNIGHT MARTHA ANS 8042 BENTLEY PETER BIO 7951 LOWELL FRANK $ EOD |
MERGEコマンドは,最大で10個 (高性能Sort/Mergeユーティリティの場合は,最高で12個) のソート済みのファイルをまとめて,レコードが順に並べられた1つの出力ファイルを作成します。マージする入力ファイルは,同じ形式を持ち,同じキー・フィールドに基づいてソートされていなければなりません。
省略時の設定では,Merge は,入力ファイルの中のレコードをチェックして,正しい順序で並べられているかどうかを確認します。 Merge で順序をチェックするときは,/CHECK_SEQUENCE修飾子を指定します。この修飾子を指定しているにもかかわらず,レコードが正しく並んでいない場合 (たとえばソートされていない入力ファイルがある場合),次のエラーが報告されます。
%SORT-W-BAD_ORDER, merge input is out of order |
MERGE コマンドと SORT コマンドは,同じ修飾子を使用できます。ただし,次の 2 つの例外があります。
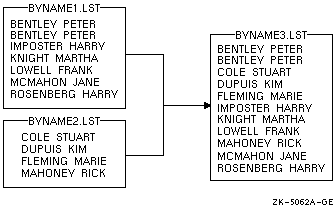
次の例では,ファイル BYNAME1.LST と BYNAME2.LST は,顧客名によってすでに昇順にソートされています。ここに示したコマンドは,これらをマージします。
$ MERGE BYNAME1.LST,BYNAME2.LST BYNAME3.LST |
出力ファイル BYNAME3.LST には,次の図に示すように, BYNAME1.LST とBYNAME2.LST の両方のファイルのすべてのレコードが含まれます。
特定のキーを使用してソートしたファイルをマージする場合は, MERGEコマンド行の/KEY修飾子で同じキーを指定する必要があります。
キーを指定しない場合は, Merge は 第 11.2 節 で説明している省略時設定のキーを使用します。
たとえば,ファイルBILLING1.LST と BILLING4.LST がアカウント番号によってソート済み(/KEY=POSITION:5,SIZE:4,DECIMAL)であるとします。この 2 つのファイルを出力ファイル MAILING.LST にマージするには,次のコマンド行を入力します。
$ MERGE/KEY=(POSITION:5,SIZE:4,DECIMAL) - _$ BILLING1.LST,BILLING4.LST MAILING.LST |
マージ結果は次のとおりです。

マージしたいファイルがソート順になっていることを知っている場合は, /NOCHECK_SEQUENCE修飾子を指定することにより,順序チェックを省略することができます。
| 前へ | 次へ | 目次 | 索引 |