| Previous | Contents | Index |
The following is an example of the SET TRANSACTION command:
RTR> start rtr RTR> set log/file=settran RTR> set transaction/state=PRI_DONE/new_state=DONE/facility=Facility1/- _RTR> partition=Partition1 * |
This example would set all transactions with the current state of PRI_DONE (remember) to DONE on the facility Facility1 and the partition Partition1. The log file, settran , would record the transaction state changes. The changes could be viewed with the SHOW TRANSACTION command or the DUMP JOURNAL command. In a shadow recovery situation this would clear the journal of remember transactions and provide for a quick turnaround of the shadow site.
The following example shows how RTR commands monitor and manipulate three different transaction states. Consider a scenario where a distributed transaction accesses two RTR partitions. The multiple-participant distributed transaction would have two transaction branches accessing different RTR partitions, say part1 and part2, respectively.
The client commits the transaction and calls rtr_accept_tx() which prompts RTR to start the two-phase commit protocol. RTR sends a prepare message to the two participants. Upon receiving the prepare message ( mt_prepare ), one of the server applications is ready to commit and casts its vote by calling rtr_accept_tx() . RTR writes a VOTE record in the RTR journal and sends the vote message back to the router. However, due to an unexpected defect in the application software, the second server has not sent its VOTE message back to the RTR router. Thus, the transaction is stalled in the second server.
To examine this situation, an RTR system administrator should first use the SHOW TRANSACTION/BACKEND command on the backend node to analyze the transaction's status. As shown in the following example, the transaction runtime state is RECEIVING, indicating the distributed transaction is not yet committed. The server states for the transaction branches are VOTED and VREQ respectively, indicating that one of the transaction branches has been voted by the associated server whereas the other transaction branch is still in "Vote Request" state (VREQ). The journal states for the transaction branches are VOTED and SENDING, indicating that one transaction branch has voted and its VOTED record was written in the RTR journal. The other transaction branch's journal state is SENDING, indicating that transaction branch is still in the process of processing a message from the client and it has not yet advanced to the VOTED state. The journal states for the transaction branches that are recorded in the RTR journal are consistent with their server states.
A transaction branch's journal state is persistent and is therefore used by the SET TRANSACTION command to change a transaction's state. The DUMP JOURNAL command is also useful to examine each transaction branch's journal state.
Backend transactions on node nodea at Mon Mar 13 16:02:42 2000 Tid: 3ad01f10,0,0,0,0,3ad01f10,a08730b4 Facility: test Frontend: nodea FE-User: tu.7006 State: RECEIVING Start time: Mon Mar 13 16:00:08 2000 Key-Range-Id: 16777216,16777217 Router: nodea Invocation: ORIGINAL,ORIGINAL Active-Key-Ranges: 2 Recovering-Key-Ranges: 0 Total-Tx-Enqs: 2 Server-Pid: 7006,7006 Server-State: VOTED,VREQ Journal-Node: nodea.com,nodea.com Journal-State: VOTED,SENDING First-Enq: 1,2 Nr-Enqs: 1,1 Nr-Replies: 0,0 |
As previously described in this scenario, the transaction is stalled in one of the servers. To resolve this situation, use the RTR SET TRANSACTION command to abort this transaction. Change either one of the transaction branch's journal state to ABORT as shown in the following example:
RTR>set transaction/new=abort/state=voted/facility=test/partition=part1 %RTR-S-SETTRANDONE, 1 transaction(s) updated in partition part1 of facility test |
or
RTR>set transaction/new=abort/state=sending/facility=test/partition=part2 %RTR-S-SETTRANDONE, 1 transaction(s) updated in partition part2 of facility test |
See Chapter 7 for detailed information on these commands.
With RTR shadowing, your system can recover from a site disaster without the need for special coding within your application program.
A database is said to be shadowed when two copies of the same database are deployed on separate nodes at two different locations, typically two different sites. Each location maintains a copy of the database used by the server application, and RTR keeps the database copies synchronized. Shadow site configurations can contain two nodes at separate sites, two nodes in a cluster, or two clusters at separate sites. When setting up a shadow configuration for two nodes in a cluster, the syntax must explicitly state that the nodes are not to be standby nodes.
Concurrent servers handle similar transactions, (that is, in
the same key range but not the same transactions). Standby servers do
not handle transactions at all (for the given key range) and shadow
servers handle the same transactions.
5.1 Primary and Secondary Roles
There is a concept of primary and secondary roles for the shadow server pair, although in most cases this is transparent to the user when the processing is the same on both sites.
The assignment of primary and secondary roles to partitions can be
managed by the partition priority list, or left to RTR. If left to RTR,
initial role assignment is arbitrary, in that the first server of a
shadow pair to start is given the primary role, and the second the
secondary. The assigned roles may change, as servers come and go. Roles
are required, since RTR needs to determine the voting order on the
primary site before the transaction is presented to the secondary site.
5.2 Automatic Features
Shadow sites each have an identical copy of the customer's database.
Transactions are sent by RTR to both sites. RTR ensures that they are processed by the servers in the same order on each site, so that both copies of the customer database remain up to date.
A transaction is sent to the secondary site only after the primary has accepted it, or if the primary fails before being asked to vote.
RTR suppresses replies and broadcasts issued by the secondary shadow
server.
5.2.1 Shadow Events
RTR provides the following shadowing events:
| RTR_EVTNUM_SRPRIMARY | Server is in primary mode |
| RTR_EVTNUM_SRSTANDBY | Server is in standby mode |
| RTR_EVTNUM_SRSECONDARY | Server is in secondary mode |
| RTR_EVTNUM_SRSHADOWLOST | Server has lost its shadow partner |
| RTR_EVTNUM_SRSHADOWGAIN | Server has gained its shadow partner |
| RTR_EVTNUM_SRRECOVERCMPL | Server has completed recovery |
The shadow events are delivered with no special status and no data. They are delivered only to the servers whose state has changed.
A server receives RTR_EVTNUM_SRPRIMARY under the following circumstances:
A server receives RTR_EVTNUM_SRSTANDBY when it starts up and servers already exist for the same key range on another node in the same cluster.
A server receives RTR_EVTNUM_SRSECONDARY when it starts up and a shadow primary set of servers exist elsewhere.
A server receives RTR_EVTNUM_SRSHADOWLOST if it is running as primary and the secondary goes away.
A server receives RTR_EVTNUM_SRSHADOWGAIN if it is running as primary and a secondary node starts up.
A server receives RTR_EVTNUM_SRRECOVERCMPL when it has finished doing
recovery operations and is ready to start processing new transactions.
5.3 RTR Journal System
The RTR journal is used for the following purposes:
The amount of space required for the journal depends upon the:
The /MAXIMUM_BLOCKS qualifier on the CREATE JOURNAL command controls how large a journal may become. The /MAXIMUM_BLOCKS qualifier defines the maximum number of blocks which the journal is allowed to occupy on any one disk. RTR does not check if this amount of space is actually available, as the disk space specified by /MAXIMUM_BLOCKS is used only on demand by RTR when insufficient space is available in the space allocated by the /BLOCKS qualifier.
The number of blocks specified by the /BLOCKS qualifier specifies the maximum size of the journal that RTR attempts to use. The actual number of blocks used may vary, depending upon the load on RTR.
The command MODIFY JOURNAL also accepts the /BLOCKS and /MAXIMUM_BLOCKS qualifiers.
Journal file extension occurs on demand when RTR detects that a "write to journal" would otherwise fail due to lack of space. Journal file truncation takes place automatically when blocks are freed.
Refer to MODIFY JOURNAL for the syntax description of the MODIFY JOURNAL command.
RTR> show journal/files/full RTR journal:- Disk: /dev/rz3a Blocks: 2500 Allocated: 1253 Maximum: 3500 File: //rtrjnl/anders/BRONZE.J00 RTR> |
If a shadow site fails, RTR allows transactions to continue to be processed on the remaining site. The intermediate transactions processed by the remaining server or servers are retained by RTR; when the failed site restarts, these transactions are sent to this site as part of a shadow-recovery operation, thus bringing the failed site back up to date.
Since the transactions are stored in the RTR journal, it must be created with enough disk space in reserve to store data for the longest expected outage. It can be calculated using:
( Nr. transaction messages per second
multiplied by ( transaction message length + 70 )
multiplied by seconds of outage
) + 5% file overhead.
|
The result in bytes must be divided by 512 to obtain size in blocks.
The overhead required when calculating journal size comes from internal journal data (block stamping) of approximately 3%. In addition, there is internal transaction data per (client to server) transactional message, and some further data per transaction (concerning voting and transaction completion).
Also, RTR prevents further transactional data from being written to the journal when it is nearly full, but continues to allow deletes from the journal (deletes also cause data to be written to the journal). Ten segments are held in reserve for storing information about deleted transactions even when RTR cannot accept further transactions because the journal is full.
If the journal disk becomes full, transactions are aborted until the shadow partner restarts and empties the journal of transactions to be replayed. |
The current maxima for the size of a journal are:
Number of blocks per disk: 524288
(This is max_segments_per_disk * disk_blocks_per_segment , or 16384 times 32.)
Number of disks per journal: 16.
Shadowed sites can either be two nodes within a single cluster, or can be two separate clusters. In the second case you can also configure standby servers on one or more of the other cluster members, so that failure of a single node within one of the shadow sites does not stop the shadow site from functioning. Multiple concurrent copies of the server processes are allowed on each site (see Figure 5-1).
Standby servers can also be configured on nodes not in the same cluster, but RTR does not guarantee transactions consistent failover in this case. |
Figure 5-1 Four Node Shadow/Standby Configuration

The performance of a shadow pair compares with a transaction that spans two nodes, with the addition of one extra protocol message which is required to ensure that the transactions are presented in the same order.
RTR does not have to wait for the secondary shadow server to complete its processing. It only needs to know that the primary has committed the transaction and that the journal file of the secondary shadow server contains the final vote status.
The two partners in a shadow pair should be connected with sufficient
bandwidth to allow for the large amounts of data which may need to be
transferred during a shadow catchup operation.
5.7 Shadows in Action
The first node on which a shadow server for a particular key range starts is arbitrarily designated by RTR to be the primary site for that key range.
Initially RTR searches the journals of other backend sites to find any recoverable transactions left over from a previous invocation of the server. Once these have been processed (or RTR determines that no such transactions exist), the server becomes active and available to handle new transactions sent by clients.
While no other server site for this key range is available, the server runs in REMEMBER mode. RTR saves transactions processed on this site in the RTR journal (together with the order in which they should be committed), so that when the other site servers start, they can be sent to this site.
When a server starts on a second site, it begins processing the transactions saved in the primary site's journal. These are deleted from the journal as they are processed. When the second site servers have caught up, the second site enters SECONDARY ACTIVE state and the original site servers enter PRIMARY ACTIVE state. In this mode, new transactions are sent to both sites in parallel. They are executed first on the primary site, and shortly afterward on the secondary site in the same order. The primary site commits transactions as soon as it knows that the secondary site has hardened (i.e., written to the journal) the order in which the transaction is to be committed.
If a failure occurs at this point, the remaining site executes a short cleanup operation. After completing the cleanup operation and determining that the other site is really down, it reverts to the REMEMBER state and continues processing new transactions autonomously, saving the transaction information in its journal for when the other site restarts.
The execution order is determined for transactions issued to concurrent
servers on a particular node by recording the order in which the
individual servers issue
rtr_accept_tx()
calls. RTR knows that at the time a correctly written server
application calls
rtr_accept_tx()
, it has already accessed (and therefore locked) any database records
it uses, and that it will release these records after RTR causes the
rtr_accept_tx()
call to complete. Any conflicting transaction would not be able to issue
rtr_accept_tx()
concurrently. Therefore a correct serialization order for issuing the
transactions on the shadow site can be determined.
5.8 Application Considerations
Although applications need not be directly concerned about shadowing matters, certain points must be considered when implementing performance boosting optimizations:
For more information on designing applications, see the Design for
Tolerating Site Disaster section in the RTR Application Design
Guide.
5.9 Server States
The current state of a server can be examined as follows:
RTR> show server/full Servers: Process-id: 13340 Facility: RTR$DEFAULT_FACILITY Channel: 131073 Flags: SRV State: active Low Bound: High Bound: 87 13 rcpnam: "RTR$DEFAULT_CHANNEL" User Events: 0 RTR Events: 0 Partition-Id: 16777216 Process-id: 13340 Facility: RTR$DEFAULT_FACILITY Channel: 196610 Flags: SRV State: active Low Bound: 88 13 High Bound: 0f' rcpnam: "CHAN2" User Events: 0 RTR Events: 0 Partition-Id: 16777217 |
Figure 5-2 gives an overview of the server state changes which appear in the State: field.
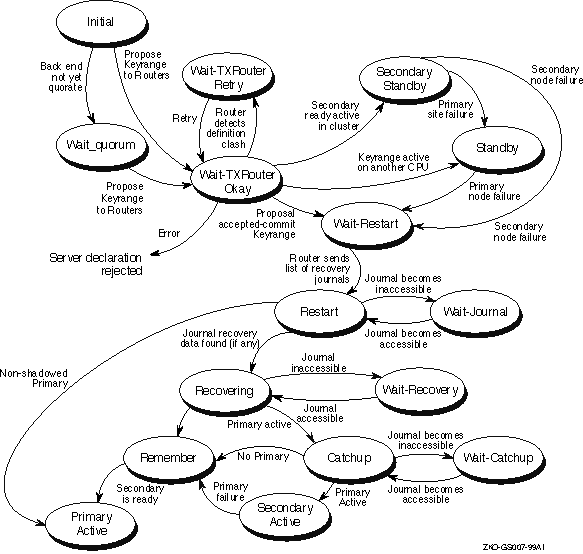
5.10 Client States
The current state of a client process can be examined as follows:
RTR> show client/full Clients: Process-id: 13340 Facility: RTR$DEFAULT_FACILITY Channel: 458755 Flags: CLI State: declared rcpnam: "CHAN3" User Events: 255 RTR Events: 0 |
Figure 5-3 describes the client state changes which appear in the State: field.
Figure 5-3 Client States

5.11 Partition States
The current state of a key range partition can be examined using the
SHOW PARTITION/FULL command for the routers and the backends:
RTR> show partition/router/full Facility: RTR$DEFAULT_FACILITY State: ACTIVE Low Bound: 0 High Bound: 4294967295 Failover policy: fail_to_standby Backends: node10 States: active Primary Main: node10 Shadow Main: |
Backend partitions:
RTR> show partition/backend/full Partition name: RTR$DEFAULT_PARTITION_16777217 Facility: RTR$DEFAULT_FACILITY State: active Low Bound: "aaaa" High Bound: "mmmm" Active Servers: 0 Free Servers: 1 Transaction presentation: active Last Rcvy BE: Txns Active: 0 Txns Rcvrd: 0 Failover policy: fail_to_standby Key range ID: 16777217 Partition name: RTR$DEFAULT_PARTITION_16777218 Facility: RTR$DEFAULT_FACILITY State: active Low Bound: "nnnn" High Bound: "zzzz" Active Servers: 0 Free Servers: 1 Transaction presentation: active Last Rcvy BE: Txns Active: 0 Txns Rcvrd: 0 Failover policy: fail_to_standby Key range ID: 16777218 |
Figure 5-4 describes the partition state changes which appear in the State: field.
Figure 5-4 Router Partition States

| Previous | Next | Contents | Index |