| Previous | Contents | Index |
The UNSTRING statement scans a sending item, searching for a match from a list of delimiters. This list can contain ALL delimiters and delimiters of various sizes. Delimiters in the list must be connected by the word OR.
The following sample statement unstrings a sending item into three receiving items. The sending item consists of three strings separated by one of the following: (1) any number of spaces, (2) a comma followed by a single space, (3) a single comma, (4) a tab character, or (5) a carriage-return character. The comma and space must precede the single comma in the list if the comma and space are to be recognized.
UNSTRING FIELD1 DELIMITED BY ALL SPACE
OR ", "
OR ","
OR TAB
OR CR
INTO FIELD2A FIELD2B FIELD2C.
|
Table 5-9 shows the potential of this statement. The tab and carriage-return characters represent single-character items containing the ASCII horizontal tab and carriage-return characters.
| FIELD1 PIC X(12) |
FIELD2A PIC XXX |
FIELD2B PIC 9999 |
FIELD2C PIC XXX |
|---|---|---|---|
| A,0,C [Return] | A## | 0000 | C## |
| A [Tab]456, E | A## | 0456 | E## |
| A 3 9 | A## | 0003 | 9## |
| A [Tab] [Tab] B [Return] | A## | 0000 | B## |
| A,,C | A## | 0000 | C## |
| ABCD, 4321,Z | ABC | 4321 | Z## |
Legend: # = space
The COUNT phrase keeps track of the size of the sending string and stores the length in a user-supplied data area.
The length of a delimited sending item can vary from zero to the full length of the item. Some programs require knowledge of this length. For example, some data is truncated if it exceeds the size of the receiving item, so the program's logic requires this information.
The COUNT phrase follows the receiving item. Consider the following example:
UNSTRING FIELD1 DELIMITED BY ALL "*"
INTO FIELD2A COUNT IN COUNT2A
FIELD2B COUNT IN COUNT2B
FIELD2C.
|
The compiler generates code that counts the number of characters between the leftmost position of FIELD1 and the first asterisk in FIELD1 and places the count into COUNT2A. The delimiter is not included in the count because it is not a part of the string. The data preceding the first asterisk is then moved into FIELD2A.
The compiler then counts the number of characters between the last contiguous asterisk in the first scan and the next asterisk in the second scan, and places the count in COUNT2B. The data between the delimiters of the second scan is moved into FIELD2B.
The third scan begins at the first character after the last contiguous asterisk in the second scan. Any data between the delimiters of this scan is moved to FIELD2C.
The COUNT phrase should be used only where it is needed. In this example, the length of the string moved to FIELD2C is not needed, so no COUNT phrase follows it.
If the receiving item is shorter than the value placed in the count item, the code truncates the sending string. If the number of integer positions in a numeric item is smaller than the value placed into the count item, high-order numeric digits have been lost. If a delimiter match is found on the first character examined, a zero is placed in the count item.
The COUNT phrase can be used only in conjunction with the DELIMITED BY
phrase.
5.2.4 Saving UNSTRING Delimiters Using the DELIMITER Phrase
The DELIMITER phrase causes the actual character or characters that delimited the sending item to be stored in a user-supplied data area. This phrase is most useful when:
By using the DELIMITER and COUNT phrases, you can make the flow of program logic dependent on both the size of the sending string and the delimiter terminating the string.
To use the DELIMITER phrase, follow the receiving item name with the words DELIMITER IN and an identifier. The compiler generates code that places the delimiter character in the area named by the identifier. Consider the following sample UNSTRING statement:
UNSTRING FIELD1 DELIMITED BY ","
OR TAB
OR ALL SPACE
OR CR
INTO FIELD2A DELIMITER IN DELIMA
FIELD2B DELIMITER IN DELIMB
FIELD2C.
|
After moving the first sending string to FIELD2A, the character (or characters) that delimited that string is placed in DELIMA. In this example, DELIMA contains either a comma, a tab, a carriage return, or any number of spaces. Because the delimiter string is moved under the rules of the elementary nonnumeric MOVE statement, the compiler truncates or space-fills with left or right justification.
The second sending string is then moved to FIELD2B and its delimiting character is placed into DELIMB.
When a sending string is delimited by the end of the sending item rather than by a match on a delimiter, the delimiter string is of zero length and the DELIMITER item is space-filled. The phrase should be used only where needed. In this example, the character that delimits the last sending string is not needed, so no DELIMITER phrase follows FIELD2C.
The data item named in the DELIMITER phrase must be described as an alphanumeric item. It can contain editing characters, and it can also be a group item.
When you use both DELIMITER and COUNT phrases, the DELIMITER phrase
must precede the COUNT phrase. Both of the data items named in these
phrases can be subscripted or indexed. If they are subscripted, the
subscript can be varied as a side effect of the UNSTRING operation.
5.2.5 Controlling UNSTRING Scanning Using the POINTER Phrase
Although the UNSTRING statement scan usually starts at the leftmost position of the sending item, the POINTER phrase lets you control the character position where the scan starts. Scanning, however, remains left to right.
When a sending item is to be unstrung into multiple receiving items, the choice of delimiters and the size of subsequent receiving items depends on the size of the first sending string and the character that delimited that string. Thus, the program needs to move the first sending item, hold its scanning position in the sending item, and examine the results of the operation to determine how to handle the sending items that follow.
This is done by using an UNSTRING statement with a POINTER phrase that fills only the first receiving item. When the first string has been moved to a receiving item, the compiler begins the next scanning operation one character beyond the delimiter that caused the interruption. The program examines the new position, the receiving item, the delimiter value, and the sending string size. It resumes the scanning operation by executing another UNSTRING statement with the same sending item and pointer data item. In this way, the UNSTRING statement moves one sending string at a time, with the form of each succeeding move depending on the context of the preceding string of data.
The POINTER phrase must follow the last receiving item in the UNSTRING statement. You are responsible for initializing the pointer before the UNSTRING statement executes. Consider the following two UNSTRING statements with their accompanying POINTER phrases and tests:
MOVE 1 TO PNTR.
UNSTRING FIELD1 DELIMITED BY ":"
OR TAB
OR CR
OR ALL SPACE
INTO FIELD2A DELIMITER IN DELIMA COUNT IN LSIZEA
WITH POINTER PNTR.
IF LSIZEA = 0 GO TO NO-LABEL-PROCESS.
IF DELIMA = ":"
IF PNTR > 8 GO TO BIG-LABEL-PROCESS
ELSE GO TO LABEL-PROCESS.
IF DELIMA = TAB GO TO BAD-LABEL PROCESS.
.
.
.
UNSTRING FIELD1 DELIMITED BY ... WITH POINTER PNTR.
|
PNTR contains the current position of the scanner in the sending item. The second UNSTRING statement uses PNTR to begin scanning the additional sending strings in FIELD1.
Because the compiler considers the leftmost character to be character position 1, the value of PNTR can be used to examine the next character. To do this, describe the sending item as a table of characters and use PNTR as a sending item subscript. This is shown in the following example:
01 FIELD1.
02 FIELD1-CHAR OCCURS 40 TIMES.
.
.
.
UNSTRING FIELD1
.
.
.
WITH POINTER PNTR.
IF FIELD1-CHAR(PNTR) = "X" ...
|
Another way to examine the next character of the sending item is to use the UNSTRING statement to move the character to a 1-character receiving item:
UNSTRING FIELD1
.
.
.
WITH POINTER PNTR.
UNSTRING FIELD1 INTO CHAR1 WITH POINTER PNTR.
SUBTRACT 1 FROM PNTR.
IF CHAR1 = "X" ...
|
The program must decrement PNTR by 1 to work, because the second UNSTRING statement increments the pointer by 1.
The program must initialize the POINTER phrase data item before the
UNSTRING statement uses it. The compiler will terminate the UNSTRING
operation if the initial value of the pointer is less than one or
greater than the length of the sending item. Such a pointer value
causes an overflow condition. Overflow conditions are discussed in
Section 5.2.7.
5.2.6 Counting UNSTRING Receiving Items Using the TALLYING Phrase
The TALLYING phrase counts the number of receiving items that received data from the sending item.
When an UNSTRING statement contains several receiving items, there are not always as many sending strings as there are receiving items. The TALLYING phrase provides a convenient method for keeping a count of how many receiving items actually received strings. The following example shows how to use the TALLYING phrase:
MOVE 0 TO RCOUNT.
UNSTRING FIELD1 DELIMITED BY ","
OR ALL SPACE
INTO FIELD2A
FIELD2B
FIELD2C
FIELD2D
FIELD2E
TALLYING IN RCOUNT.
|
If the compiler has moved only three sending strings when it reaches the end of FIELD1, it adds 3 to RCOUNT. The first three receiving items (FIELD2A, FIELD2B, and FIELD2C) contain data from the UNSTRING operation, but the last two (FIELD2D and FIELD2E) do not.
The UNSTRING statement does not initialize the TALLYING data item. The TALLYING data item always contains the sum of its initial contents plus the number of receiving items receiving data. Thus, you might want to initialize the tally count before each use.
You can use the POINTER and TALLYING phrases together in the same
UNSTRING statement, but the POINTER phrase must precede the TALLYING
phrase. Both phrases must follow all of the item names, the DELIMITER
phrase, and the COUNT phrase. The data items for both phrases must
contain numeric integers without editing characters or the symbol P in
their PICTURE character-strings; both data items can be either COMP or
DISPLAY usage. They can be signed or unsigned and, if they are DISPLAY
usage, they can contain any desired sign option.
5.2.7 Exiting an UNSTRING Statement Using the OVERFLOW Phrase
The OVERFLOW phrase detects the overflow condition and causes an imperative statement to be executed when it detects the condition. An overflow condition exists when:
If the UNSTRING operation causes the scan to move past the rightmost position of the sending item (thus exhausting it), the compiler does not execute the OVERFLOW phrase.
The following set of instructions causes program control to execute the UNSTRING statement repeatedly until it exhausts the sending item. The TALLYING data item is a subscript that indexes the receiving item. Compare this loop with the previous loop, which accomplishes the same thing:
MOVE 1 TO TLY PNTR.
PAR1. UNSTRING FIELD1 DELIMITED BY ","
OR CR
INTO FIELD2(TLY) WITH POINTER PNTR
TALLYING IN TLY
ON OVERFLOW GO TO PAR1.
|
The most common errors made when writing UNSTRING statements are as follows:
UNSTRING FIELD1 DELIMITED BY SPACE
OR TAB
INTO FIELD2A DELIMITER IN DELIMA
INTO FIELD2B DELIMITER IN DELIMB
INTO FIELD2C DELIMITER IN DELIMC.
|
The INSPECT statement examines the character positions in an item and counts or replaces certain characters (or groups of characters) in that item.
Like the STRING and UNSTRING operations, INSPECT operations scan across
the item from left to right. Included in the INSPECT statement is an
optional phrase that allows scanning to begin or terminate upon
detection of a delimiter match. This feature allows scanning to begin
within the item, as well as at the leftmost position.
5.3.1 Using the TALLYING and REPLACING Options of the INSPECT Statement
The TALLYING operation, which counts certain characters in the item, and the REPLACING operation, which replaces certain characters in the item, can be applied either to the characters in the delimited area of the item being inspected, or to only those characters that match a given character string or strings under stated conditions. Consider the following sample statements, both of which cause a scan of the complete item:
INSPECT FIELD1 TALLYING TLY FOR ALL "B". INSPECT FIELD1 REPLACING ALL SPACE BY ZERO. |
The first statement causes the compiler to scan FIELD1 looking for the character B. Each time a B is found, TLY is incremented by 1.
The second statement causes the compiler to scan FIELD1 looking for spaces. Each space found is replaced with a zero.
The TALLYING and REPLACING phrases support both single and multiple arguments. For example, both of the following statements are valid:
INSPECT FIELD1 TALLYING TLY FOR ALL "A" "B" "C". INSPECT FIELD1 REPLACING ALL "A" "B" "C" BY "D". |
You can use both the TALLYING and REPLACING phrases in the same INSPECT
statement. However, when used together, the TALLYING phrase must
precede the REPLACING phrase. An INSPECT statement with both phrases is
equivalent to two separate INSPECT statements. In fact, the compiler
compiles such a statement into two distinct INSPECT statements. To
simplify debugging, write the two phrases in separate INSPECT
statements.
5.3.2 Restricting Data Inspection Using the BEFORE/AFTER Phrase
The BEFORE/AFTER phrase acts as a delimiter and can restrict the area of the item being inspected.
The following sample statement counts only the zeros that precede the percent sign (%) in FIELD1:
INSPECT FIELD1 TALLYING TLY
FOR ALL ZEROS BEFORE "%".
|
The delimiter (the percent sign in the preceding sample statement) can be a single character, a string of characters, or any figurative constant. Furthermore, it can be either an identifier or a literal.
The compiler repeatedly compares the delimiter characters against an equal number of characters in the item being inspected. If none of the characters matches the delimiter, or if too few characters remain in the rightmost position of the item for a full comparison, the compiler considers the comparison to be unequal.
The examples of the INSPECT statement in Figure 5-2 illustrate the way the delimiter character finds a match in the item being inspected. The underlined characters indicate the portion of the item the statement inspects as a result of the delimiters of the BEFORE and AFTER phrases. The remaining portion of the item is ignored by the INSPECT statement.
Figure 5-2 Matching Delimiter Characters to Characters in a Field
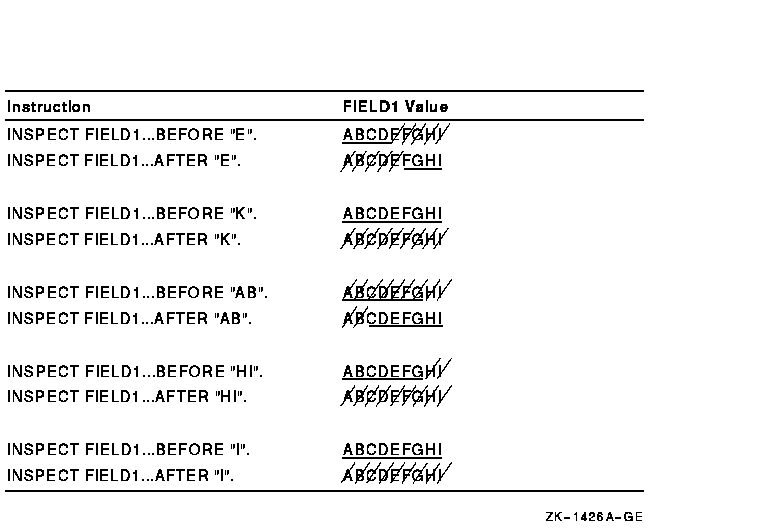
The ellipses represent the position of the TALLYING or REPLACING
phrase. The compiler generates code that scans the item for a delimiter
match before it scans for the inspection operation (TALLYING or
REPLACING), thus establishing the limits of the operation before
beginning the actual inspection. Section 5.3.4.1 further describes the
separate scan.
5.3.3 Implicit Redefinition
The compiler requires that certain items referred to by the INSPECT statement be alphanumeric items. If one of these items is described as another data class, the compiler implicitly redefines that item so the INSPECT statement can handle it as an alphanumeric string as follows:
The compiler alters the digit position containing the sign before beginning the INSPECT operation and restores it to its former value after the operation. If the sign's digit position does not contain a valid ASCII signed numeric digit, redefinition causes the value to change.
Table 5-10 shows these original, altered, and restored values.
The compiler never moves an implicitly redefined item from its storage position. All redefinition occurs in place.
The position of an implied decimal point on numeric quantities does not affect implicit redefinition.
| Original Value | Altered Value | Restored Value |
|---|---|---|
| } (173) | 0 (60) | } (173) |
| A (101) | 1 (61) | A (101) |
| B (102) | 2 (62) | B (102) |
| C (103) | 3 (63) | C (103) |
| D (104) | 4 (64) | D (104) |
| E (105) | 5 (65) | E (105) |
| F (106) | 6 (66) | F (106) |
| G (107) | 7 (67) | G (107) |
| H (110) | 8 (70) | H (110) |
| I (111) | 9 (71) | I (111) |
| { (175) | 0 (60) | { (175) |
| J (112) | 1 (61) | J (112) |
| K (113) | 2 (62) | K (113) |
| L (114) | 3 (63) | L (114) |
| M (115) | 4 (64) | M (115) |
| N (116) | 5 (65) | N (116) |
| O (117) | 6 (66) | O (117) |
| P (120) | 7 (67) | P (120) |
| Q (121) | 8 (70) | Q (121) |
| R (122) | 9 (71) | R (122) |
| 0 (60) | 0 (60) | } (173) |
| 1 (61) | 1 (61) | A (101) |
| 2 (62) | 2 (62) | B (102) |
| 3 (63) | 3 (63) | C (103) |
| 4 (64) | 4 (64) | D (104) |
| 5 (65) | 5 (65) | E (105) |
| 6 (66) | 6 (66) | F (106) |
| 7 (67) | 7 (67) | G (107) |
| 8 (70) | 8 (70) | H (110) |
| 9 (71) | 9 (71) | I (111) |
| All other values | 0 (60) | } (173) |
| Previous | Next | Contents | Index |