| Previous | Contents | Index |
To assist you in designing fault-tolerant RTR transaction processing applications, this chapter addresses configuration and design topics. Specifying how your RTR components are deployed on physical systems is called configuration . Developing your application to exploit the benefits of using RTR is called design or application design. The following topics are addressed:
Short examples for both C++ and C APIs are available in appendices. The RTR C++ Foundation Classes manual and the RTR C Application Programmer's Reference Manual provide longer code examples. Code examples are also available with the RTR software kit in the examples directory.
To design an application to tolerate process failure, the application designer can use concurrent servers with partitions and possibly threads with RTR.
A concurrent server is an additional instance of a server application running on the same node as the original instance. If one concurrent server fails, the transaction in process is replayed to another server in the concurrent pool.
The main reason for using concurrent servers is to increase throughput by processing transactions in parallel, or to exploit Symmetric Multiprocessing (SMP) systems. The main constraint in using concurrent servers is the limit of available resources on the machine where the concurrent servers run. Concurrent servers deal with the same database partition. They may be implemented as multiple channels in a single process or as channels in separate processes. For an illustration of concurrent servers, see RTR Getting Started . By default, servers are declared concurrent.
When a concurrent server fails, the server application can fail over to another running concurrent server, if one exists. Concurrent servers are useful to improve throughput, to make process failover possible, and to help minimize timeout problems in certain server applications. For more information on this topic, see the section on Server-Side Transaction Timeouts later in this document.
Concurrent servers must not access the same file or the same record in a database table. This can cause contention for a single resource, with potential for performance bottleneck. The resources that you can usefully share include the database and access to global memory. However, an application may need to take out locks on global memory; this would need to be taken into account during design. With some applications, it may be possible to reduce operating system overhead by using multiple channels in a process.
Performance in a system is usually limited by the hardware in the configuration. Evaluating hardware constraints is described in the RTR System Manager's Manual. Given unlimited system resources, adding concurrency will usually improve performance. Before putting a new application or system built with RTR into production, the prudent approach is to test performance. You can then make adjustments to optimize performance. Do not design a system that immediately uses all the resources in the configuration because there will be no room for growth.
Using concurrency also improves reliability, because RTR provides server process failover (the )three strikes and you're out) rule) when you have concurrent servers.
In addition to using concurrent processes, an application can use the following methods to help improve performance:
An application designer may decide to use threads to have an application perform other tasks while waiting for RTR, for example, to process terminal input while waiting for RTR to commit a transaction or send a broadcast.
To use multiple threads, you write your application as a threaded application and use the shared thread library for the operating system on which your application runs. Use one channel per thread (with the C API), or one TransactionController per thread (with the C++ API). The application must manage the multiple processes.
To use multiple channels in a thread, with the RTR C API, use the polled receive method, polling for rtr_receive_message (C API) or Receive (C++ API). The application must contain code to handle the multiple channels or transaction controllers. This is by far the most complex solution and should only be used if it is not possible to use multiple threads or concurrent processes.
When using multiple threads in a process, the application must do the scheduling. One design using threads is to allocate a single channel for each thread. An alternative is to use multiple channels, each with a single thread. In this design, there are no synchronization issues, but the application must deal with different transactions on each thread.
Using multiple threads, design and processing is more streamlined. Within each thread, the application deals with only a single transaction at a time, but the application must deal with issues of access to common variables. It is often necessary to use mutexes (resource semaphores) and locks between resources.
When you have multiple databases to which transactions are posted, you can also design your RTR application to use partitions and thereby achieve better performance than without partitioning.
To configure a system that tolerates storage device failure well, consider incorporating the following in your configuration and software designs:
Further discussion of these devices is outside the scope of this document.RTR failover employs concurrent servers, standby servers, shadow servers, and journaling, or some combination of these.
To survive node failure, you can use standby and shadow servers in several configurations.
If the application starts up a second server for the partition, the server is a standby server by default.
Consider using a standby server to improve data availability, so that if your backend node fails or becomes unavailable, you can continue to process your transactions on the standby server. You can have multiple standby servers in your RTR configuration.
The time-to-failover on OpenVMS and Tru64 UNIX systems is virtually instantaneous; on other operating systems, this time is dictated by the cluster configuration that is in use.
The C++ API includes management classes that enable you to write management routines that can specify server type, while the C API uses flags on the open channel calls.
RTR deals with router failures automatically and transparently to the application. In the event of a router failure, neither client nor server applications need to do anything, and do not see an interruption in service. Consider router configuration when defining your RTR facility to minimize the impact of failure of the node where a router resides. If possible, place your routers on independent nodes, not on either the frontend or backend nodes of your configuration. If you do not have enough nodes to place routers on separate machines, configure routers with backends. This assumes a typical situation with many client applications on multiple frontends connecting to a few routers. For tradeoffs, see the sections on Design for Performance and Design for Operability sections of this chapter.
Provide multiple routers for redundancy. For configurations with a large number of frontends, the failure of a router causes many frontends to seek an alternate router. Therefore, configure sufficient routers to handle reconnection activity. When you configure multiple routers, one becomes the current router. If it fails, RTR automatically fails over to another.
For read-only applications, routers can be effective for establishing multiple sites for failover without using shadowing. To achieve this, define multiple, nonoverlapping facilities with the same facility name in your network. Then provide client applications in the facility with the list of routers. When the router for the active facility fails, client applications are automatically connected to an alternate site. Read-only transactions can alternatively be handled by a second partition running on a standby server. This can help reduce network traffic.
When a router fails, in-progress transactions are routed to another router if one is available in that facility.
Server failover in the RTR environment can occur with failure of concurrent, standby, transactional shadow servers, or a combination of these. Servers in a cluster have additional failover attributes. Conceptually, server process failures can be contrasted as follows:
A standby server can be configured over nodes that are not in the same cluster, but recovery of a failed node's journal is not possible until a server is restarted on the failed node. You may decide to use a standby server in another cluster to increase site-disaster tolerance. (See the section on Configuration for Tolerating Site Disaster for more details on this configuration.) |
Failover of any server is either event-driven or timer-based. For example, server loss due to process failure is event-driven and routinely handled by RTR. Server loss due to network link failure is timer-based, with timeout set by the SET LINK/INACTIVITY timer (default: 60 seconds). For more information on setting the inactivity timer, see the SET LINK command in the RTR System Manager's Manual.
The server type of a specific server depends on whether it is in a cluster environment and what other servers are declared for the same key range. In a cluster environment, a server declared as a standby and as a shadow becomes a standby server if there is another server for the same key range on the cluster. In a non-cluster environment, the server becomes a shadow server. For example, Figure 2-1 illustrates the use of concurrent servers to process transactions for Partition A.
Figure 2-1 Transaction Flow with Concurrent Servers and Multiple Partitions
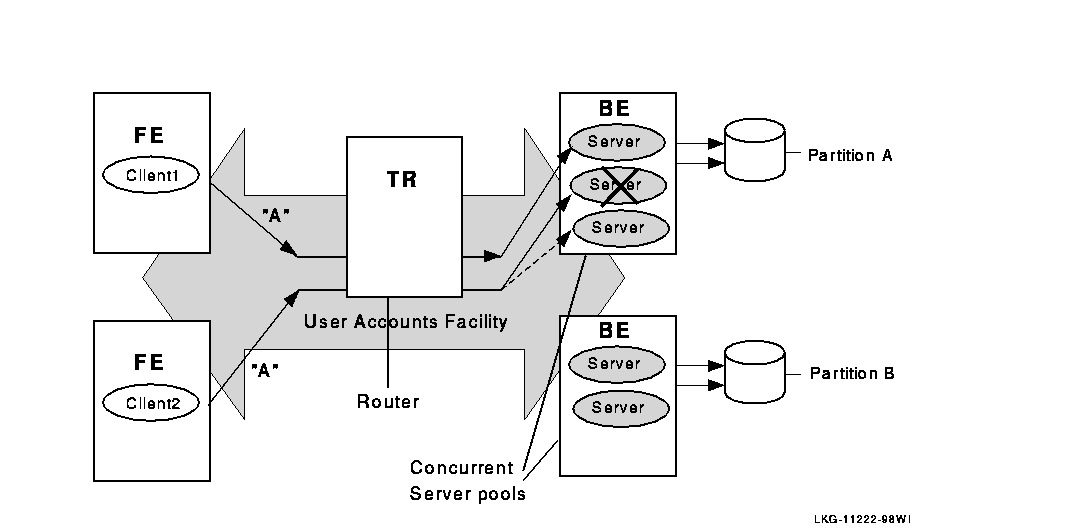
When one of the concurrent servers cannot service transactions going to partition A, another concurrent server (shown by the dashed line) processes the transaction. Failover to the concurrent server is transparent to the application and the user.
Concurrent servers are useful in environments where more than one transaction can be performed on a database partition at one time to increase throughput.
Standby servers provide additional availability and node- failure tolerance. Figure 2-2 illustrates the processing of transactions for two partitions using standby servers.
Figure 2-2 Transaction Flow on Standby Servers
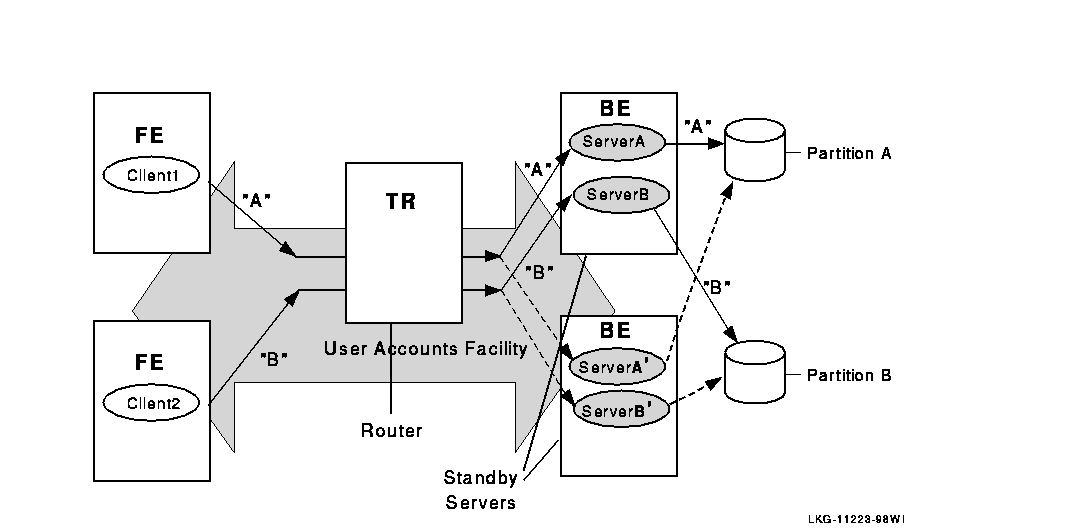
When the configuration is operating normally, the primary servers send transactions to the designated partition (solid lines); transactions "A" proceed through primary server A to database partition A and transactions "B" proceed through primary server B to database partition B. However, when the primary server fails, the router reroutes transactions "A" through the standby server A' to partition A, and transactions "B" through the standby server B' to database partition B. Note that standby servers for different partitions can be on different nodes to improve throughput and availability. For example, the bottom node could be the primary server for partition B, with the top node the standby. The normal route is shown with a solid line, the standby route with a dashed line.
When the primary path for transactions intended for a specific partition fails, the standby server can still process the transactions. Standby servers automatically take over from the primary server if it fails, transparently to the application. Standby servers recover all in-progress transactions and replay them to complete the transactions.
As shown in Figure 2-2, there can be multiple standby servers for a partition.
Failover and transaction recovery behave differently depending on whether server nodes are in a cluster configuration. Not all "cluster" systems are recognized by RTR; RTR recognizes only the more advanced or "true" cluster systems. Figure 2-2 shows the components that form an RTR standby server configuration. Two nodes, N1 and N2, in a cluster configuration are connected to shared disks D1, D2 and D3. Disks D1 and D2 are dedicated to the RTR journals for nodes N1 and N2 respectively, and D3 is the disk that hosts the clustered database. This is a partitioned database with two partitions, P1 and P2. Under normal operating conditions, the RTR active server processes for each partition, P1A and P2A run on nodes N1 and N2 respectively. The standby server processes for each partition run on the other node, that is, P1S runs on N2 and P2S runs on N1. In this way, both nodes in the cluster actively participate in the transactions and at the same time provide redundancy for each other. In case of failure of a node, say N1, the standby server P1S is activated by RTR and becomes P1A and continues processing transactions without any loss of service or loss of in-flight transactions. Both the active and standby servers have access to the same database and therefore both can process the same transactions.
Figure 2-3 RTR Standby Servers
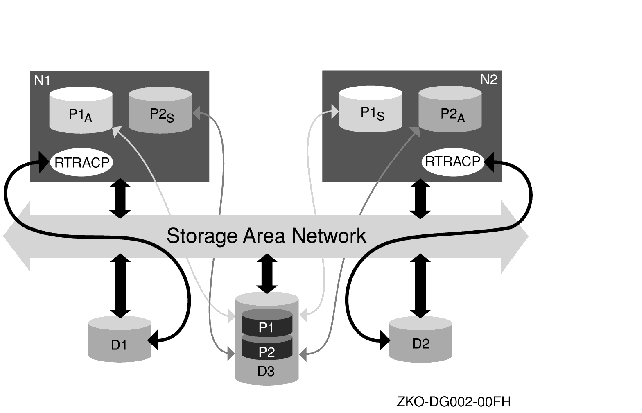
Failover between RTR standby servers behaves differently depending on the type of cluster where RTR is running. Actual configuration and behavior of each type of cluster depends on the operating system and the physical devices deployed. For RTR, configurations are either true clusters or host-based clusters.
True clusters are systems that allow direct and equal access to shared disks by all the nodes in the cluster, for example OpenVMS and Tru64 UNIX (Version 5.0). Since concurrent access to files must be managed across the cluster, a distributed lock manager (DLM) is typically used as well. Since all cluster members have equal access to the shared disks, a failure of one member does not affect the accessibility of other members to the shared disks. This is the best configuration for smooth operation of RTR standby servers. In such a cluster configuration, RTR failover occurs immediately if the active node goes down.
Host-based clusters include MSCS on Windows NT, Veritas for Solaris, IBM AIX and Tru64 UNIX (versions before 5.0). These clusters do not allow equal access to the disks among cluster members. There is always one host node that mounts the disk locally. This node then makes this disk available to other cluster members as a shared disk. All cluster members accessing this disk communicate through the host. In such a configuration, failure of the host node affects accessibility of the disks by the other members. They will not be able to access the disks until the host-based cluster software appoints another host node and this node has managed to mount the disks and export them. This will cause a delay in the failover, and also introduces additional network overhead for the other cluster members that need to access the shared disks.
The cluster systems currently recognized by RTR are: OpenVMS, TruCluster systems on Tru64 UNIX and Wolfpack on NT. Cluster behavior affects how the standby node fails over and how transactions are recovered from the RTR journal. For RTR to coordinate access to the shared file system across the clustered nodes, it uses the Distributed Lock Manager on both OpenVMS and Tru64 UNIX. On NT, RTR uses file-based locking.
When the active server goes down, RTR fails over to the standby server. Before that, RTR on the upcoming active node attempts to perform a scan of the failed node's journal. Since this is a clustered system, the cluster manager fails over the disks as well to the new active node. RTR will wait for this failover to happen before it starts processing new transactions.
In all the recognized clusters, whenever a failover occurs, RTR attempts to recover all the in-doubt transactions from the failed node's journal and replay them to the new active node. If RTR on the upcoming active server node cannot access the journal of the node that failed, it waits until the journal becomes accessible. This wait allows for any failover time in the cluster disks. This is particularly relevant in host-based clusters (for example, NT clusters) where RTR must allow time for a new host to mount and export the disks. If after a certain time the journal is still inaccessible, the partition state goes into local recovery fail. In such a situation, the system manager must complete the failover of the cluster disks manually. If this succeeds, RTR can complete the recovery process and continue processing new transactions.
The current version of RTR does not recognize the cluster systems available for Sun Solaris.
When the active server goes down, RTR fails over to the standby server. RTR treats unrecognized cluster systems as independent non-clustered nodes. In this case, RTR scans for the failed node's journal among the valid disks accessible to it. However if it does not find it, it does not wait for it, as with recognized clusters. Instead, it changes to the active state and continues processing new transactions.
As in the case of recognized clusters, whenever a failover occurs, RTR attempts to recover all the in-doubt transactions from the failed node's journal and replay them to the new active node. If the failover of the cluster disks happens fast enough so that when the new active node does the journal scan, the journal is visible, RTR will recover any in-doubt transactions from the failed node's journal. However, if the cluster disk failover has not yet happened, RTR does not wait. RTR changes the standby server to the active state and continues processing new transactions. Note that this does not mean that the transactions in the failed node's journal have been lost, as they will remain in the journal and can be recovered. See the RTR System Manager's Manual for information on how to do this.
When RTR standby servers work in conjunction with clustered resource managers such as Oracle RDB or Oracle Parallel Server, additional considerations apply. These affect mainly the performance of the application and are relevant only to those cluster systems that do not have "true" cluster file systems. OpenVMS and Tru64 UNIX V5.0 both have "true" cluster file systems.
Other cluster file systems host their file systems on one node and export the file system to the remaining nodes. In such a scenario, the RTR server could be working with a resource manager on one node that has its disks hosted on another node; not an optimal situation. Ideally, disks should be local to the RTR server that is active. Since RTR only waits for the journals to become available, this is not synchronized with the failover of the Resource Manager's disks. An even worse scenario occurs if both the RTR journal and the database disks are hosted on a remote node. In this case, the use of failover scripts is recommended to assist switching over in the most optimal way. Subsequent sections discuss this in more detail.
In this section the various failure situations are analyzed in more detail. This can help system managers to configure the system in an optimal way.
When the active server fails in the midst of a transaction, if there are other RTR servers for that partition on the same node (concurrent servers), RTR simply reissues the transaction to one of the other servers. Transaction processing is continued with the remaining servers. If the server fails due to a programming error, all the servers are likely to have the same error. Thus reissuing the same transaction to the remaining servers could cause all the concurrent servers to fail, one after another. RTR has a built-in protection against this so that if the same transaction knocks out three servers in a row, that transaction is aborted. The count three is the default value and can be configured to suit the application requirements. This behavior is the same whether or not RTR is run in a cluster.
After the last available active server for a specific partition has failed, RTR tries to fail over to a standby server, if any exist. If no standby servers have been configured, the transaction is aborted. Take the case of the configuration shown in Standby Servers. Assume that P1A (active server process for partition 1) has crashed on node N1. RTR will attempt to fail over to P1S. Before P1S can be given new transactions to process, it has to resolve any in-doubt transactions that are in N1's journal sitting on D1. Therefore RTR on N2 scans the journal of N1 looking for any in-doubt transactions. If it finds any, these are reissued to the P1S. Once transaction recovery is completed, P1S then changes state to active and becomes the new P1A. In this case, since the RTR ACP is still alive, and since it is the RTR ACP on N1 that owns the journal on D1, RTR on N2 will do a journal scan via the RTR ACP on N1. This behavior is the same for both recognized and unrecognized clusters.
| Previous | Next | Contents | Index |