![[Compaq]](../../images/compaq.gif)
![[Go to the documentation home page]](../../images/buttons/bn_site_home.gif)
![[How to order documentation]](../../images/buttons/bn_order_docs.gif)
![[Help on this site]](../../images/buttons/bn_site_help.gif)
![[How to contact us]](../../images/buttons/bn_comments.gif)
![[OpenVMS documentation]](../../images/ovmsdoc_sec_head.gif)
| Document revision date: 19 July 1999 | |
|
|
|
|
|
|
| Previous | Contents | Index |
Much process context resides in P1 space, taking the form of data cells
and the process stacks. Some of these data cells need to be per-kernel
thread, as do the stacks. By calling the appropriate system service, a
kernel thread region in P1 space is initialized to contain the
per-kernel thread data cells and stacks. The region begins at the
boundary between P0 and P1 space at address 40000000x, and it grows
toward higher addresses and the initial thread's user stack. The region
is divided into per-kernel thread areas. Each area contains pages for
data cells and the four stacks.
6.2.4 Per-Kernel Thread Stacks
A process is created with four stacks; each access mode has one stack. All four of these stacks are located in P1 space. Stack sizes are either fixed, determined by a SYSGEN parameter, or expandable. The parameter KSTACKPAGES controls the size of the kernel stack. This parameter continues to control all kernel stack sizes, including those created for new execution contexts. The executive stack is a fixed size of two pages; with kernel threads implementation, the executive stack for new execution contexts continues to be two pages in size. The supervisor stack is a fixed size of four pages; with kernel threads implementation, the supervisor stack for new execution contexts is reduced to two pages in size.
For the user stack, a more complex situation exists. OpenVMS allocates
P1 space from high to lower addresses. The user stack is placed after
the lowest P1 space address allocated. This allows the user stack to
expand on demand toward P0 space. With the introduction of multiple
sets of stacks, the locations of these stacks impose a limit on the
size of each area in which they can reside. With the implementation of
kernel threads, the user stack is no longer boundless. The initial user
stack remains semiboundless; it still grows toward P0 space, but the
limit is the per-kernel thread region instead of P0 space.
6.2.5 Per-Kernel Thread Data Cells
Several pages in P1 space contain process state in the form of data
cells. A number of these cells must have a per-kernel thread
equivalent. These data cells do not all reside on pages with the same
protection. Because of this, the per-kernel area reserves approximately
two pages for these cells. Each page has a different page protection;
one page protection is user read, user write (URUW), the other is user
read, executive write (UREW). The top of the user stack is used for the
URUW data cells.
6.2.6 Layout of the Per-Kernel Thread
Each per-kernel thread area contains a set of stacks and two pages for data. Each area is a fixed size. For a system using the default values for the kernel stack and user stack size, each area has the layout shown in Figure 6-1.
Figure 6-1 Default Kernel Stack and User Stack Sizes
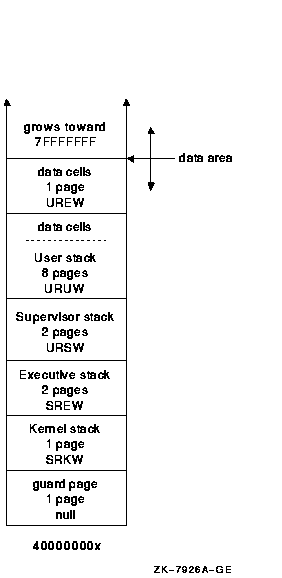
Process creation results in a PCB/KTB, a PHD/FRED, and a set of stacks. All processes have a single kernel thread, the initial thread. A multithreaded process always begins as a single threaded process. A multithreaded process contains a PCB/KTB pair and a PHD/FRED pair for the initial thread; for its other threads, it contains additional KTBs, additional FREDs, and additional sets of stacks. When the multithreaded application exists, the process returns to its single threaded state, and all additional KTBs, FREDs, and stacks are deleted.
Figure 6-2 shows the relationships and locations of a process's data structures.
Figure 6-2 Structure of a Multithreaded Process
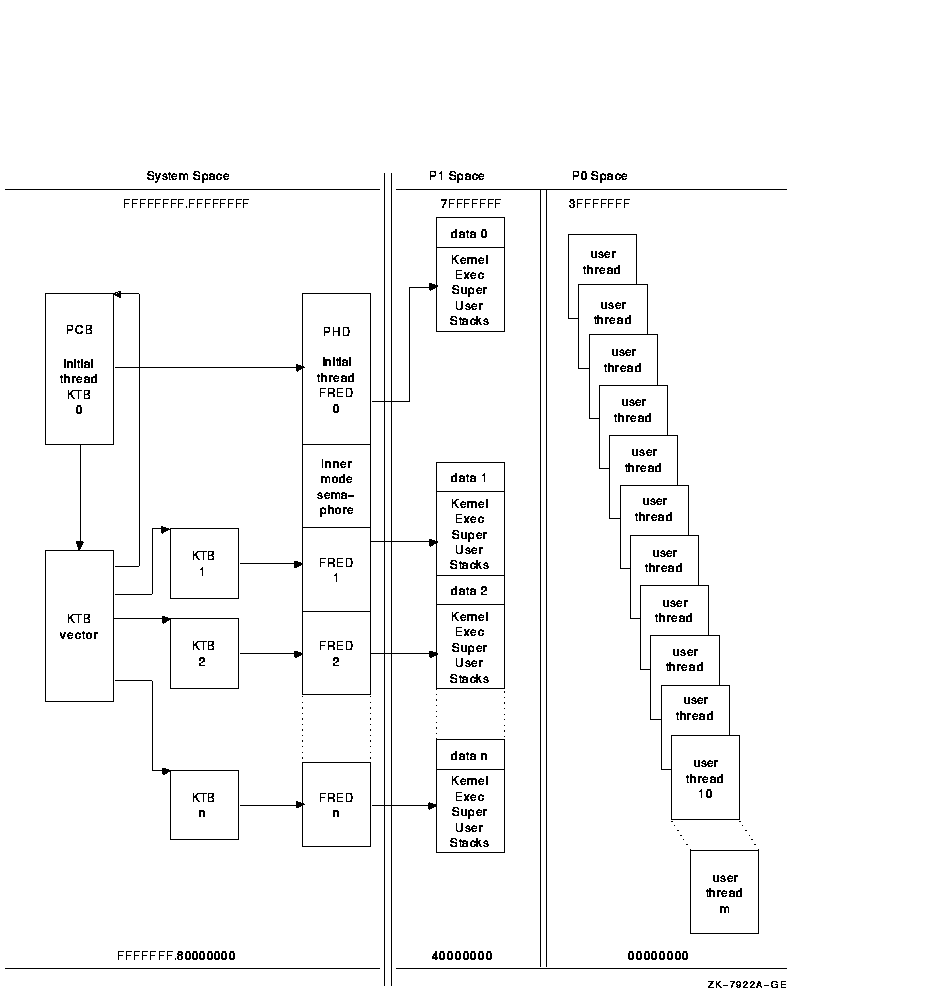
OpenVMS qualifies much context by the process ID (PID). With the implementation of kernel threads, much of that process context moves to the thread level. With kernel threads, the basic unit of scheduling is no longer the process but rather the kernel thread. Because of this, kernel threads needs a method to identify them which is similar to the PID. To satisfy this need, the meaning of the PID is extended. The PID continues to identify a process, but can also identify a kernel thread within that process. An overview follows that presents the features of the PID, and the extended process ID (EPID), which is the cluster-visible extension of the PID.
The PID in this form is typically know as the internal PID (IPID). It consists of two pieces of information, both one word in length. Figure 6-3 shows the layout.
Figure 6-3 Process ID (PID)
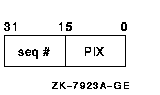
The low word is the process index (PIX). The PIX is used as an index into the PCB vector. This is a vector of PCB addresses. Therefore the PIX gives a quick method of determining the PCB address given a PID.
Another array, also indexed by PIX, contains a sequence number entry for each PIX. The sequence number increments every time a PIX is reused. The high word of the IPID is a copy of the value in the array for a particular PIX. This feature validates a PID to ensure that the ID is not for a process which has been deleted. The sequence number in the IPID must match the one in the sequence number array for that PIX.
The EPID is the cluster-visible PID. It consists of five parts, as Figure 6-4 shows.
Figure 6-4 Extended Process ID (EPID)
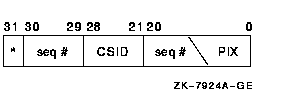
The EPID takes its low 21 bits from the two word IPID fields seen in
Figure 6-3. The value of MAXPROCESSCNT determines the number of bits
within the 21 bits used for the PIX (5 to 13 bits). The sequence number
uses the remaining bits (8 to 16 bits). The PIX cannot be larger than
8192; the sequence number no larger than 32767. If the system is an
OpenVMS cluster member, the next 10 bits of the EPID uniquely identify
the PID within the cluster. They contain 8 bits of the cluster system
ID (CSID) for the system, and a 2 bit sequence number. The system
service SYS$GETJPI uses the high bit (31). If set, the bit specifies
that the PID is a wildcard context value. This allows collecting
information for all processes in the system.
6.3.1 Multithread Effects on the PID
With kernel threads implementation, the PID's definition undergoes two changes:
Every process has at least one kernel thread, the initial thread, which is always thread ID zero; therefore, given a particular PID, the PIX continues to be used as an index into the PCB and sequence vectors. A range check validates the sequence numbers.
Before kernel threads implementation, the sequence number vector (SCH$GL_SEQVEC) was a vector of words. After kernel threads implementation, it is a vector of longwords that enables range checking for sequence number validation. The low word in each longword is the base sequence number for a particular PIX, and the upper word is the next sequence number for that PIX. The sequence number for a single-threaded process must be equal to the base value. Kernel threads PID sequence numbers must fall within the base and next values.
Figure 6-5 shows the flow of range checking of sequence numbers.
Figure 6-5 Range Checking and Sequence Vectors
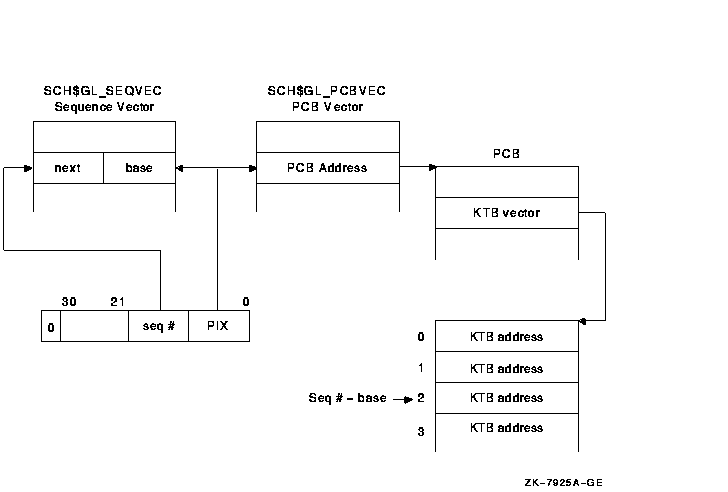
Similar to the fields in the PCB that migrate to the KTB, there are several status bits that need to be per thread. The interface for the SYS$GETJPI and SYS$PROCESS_SCAN system services indicates that the entire longword fields that contain the status bits can be returned. Therefore, all the status bits must remain defined as they are. The PCB specific bits are "reserved" in the KTB structure definition. Likewise, the KTB specific bits are "reserved" in the PCB. Because the PCB is really an overlaid structure with the initial thread's KTB, just the PCB status bits need to be returned for the initial thread. The status longword returned for other threads is built by first masking out the initial thread's bits, and then OR'ing the remainder with the status longword in the appropriate KTB.
If a thread in a multithreaded process requests information about itself using SYS$GETJPI (passes PID=0), then the status bits for the kernel thread it's running on are returned. Since each kernel thread has its own PID, SYS$GETJPI can be called for each of the kernel threads in a process. The return status bits are the combination of the PCB status bits and those in the KTB associated with the input PID.
This appendix contains descriptions of the OpenVMS Alpha Version 7.0 I/O data structure changes made to support 64-bit addressing.
The data structures are listed in alphabetical order. However, the
individual structure members are listed in the order in which they are
defined within each data structure. Note, however, that the following
sections only describe new or changed structure members. Existing
unchanged members are not described. In addition, unused or
"fill" structure members that might be added to obtain
natural alignment are not listed. Thus, you can not use the following
descriptions to calculate the precise memory layout of the structures.
However, you can assume that any new or changed structure members will
be naturally aligned within the structure.
A.1 Pointer Size Conventions
Any unqualified use of the term "pointer" implies a 32-bit pointer. All 64-bit pointers will be explicitly identified as either a 64-bit or quadword pointer.
As of OpenVMS Alpha Version 7.0, a new C compiler pragma controls the pointer size. To facilitate the use of 64-bit pointers, a new header file, far_pointers.h in SYS$STARLET_C.TLB, defines types for 64-bit pointers to the intrinsic C data types.
Table A-1 summarizes the 64-bit pointer data types.
| Type Name | 32-Bit Analog | Description | Defined by |
|---|---|---|---|
| CHAR_PQ | char * | 64-bit pointer to a char | far_pointers.h |
| CHAR_PPQ | char ** | 64-bit pointer to a CHAR_PQ | far_pointers.h |
| INT_PQ | int * | 64-bit pointer to a 32-bit int | far_pointers.h |
| INT64_PQ | int64 * | 64-bit pointer to a 64-bit int | far_pointers.h |
| UINT64_PQ | uint64 * | 64-bit pointer to a 64-bit int | far_pointers.h |
| VOID_PQ | void * | 64-bit pointer to arbitrary data | far_pointers.h |
| VOID_PPQ | void ** | 64-bit pointer to a VOID_PQ | far_pointers.h |
| IOSB_PQ | IOSB * | 64-bit pointer to an IOSB structure | iosbdef.h |
| IOSB_PPQ | IOSB ** | 64-bit pointer to an IOSB_PQ | iosbdef.h |
| PTE_PQ | PTE * | 64-bit pointer to a PTE | ptedef.h |
| PTE_PPQ | PTE ** | 64-bit pointer to a PTE_PQ | ptedef.h |
This section describes the additions and changes to cells in the buffer object descriptor (BOD) structure (see Table A-2).
| Field | Type | Comments |
|---|---|---|
| bod$v_s2_window | Bit |
A bit equal to BOD$M_S2_WINDOW in the
bod$l_flags cell.
When this bit is clear, the buffer object is mapped into the S0/S1 portion of system space and the bod$ps_svapte and bod$l_basesva cells are valid. When this bit is set, the buffer object is mapped into the S2 portion of system space and the bod$pq_va_pte and bod$pq_basesva cells are valid. |
| bod$pq_basepva | VOID_PQ | Process virtual address for the start of the buffer object. This cell replaces the bod$l_basepva cell. |
| bod$l_basepva | - | This cell will be removed. It will be replaced by the bod$pq_basepva cell. |
| bod$pq_basesva | VOID_PQ | System virtual address for the start of the buffer object. This cell is overlaid on the bod$l_basesva cell and this use is valid only if BOD$M_S2_WINDOW is set in bod$l_flags. |
| bod$pq_va_pte | PTE_PQ | Virtual address for the first system PTE that maps the buffer object. This cell is overlaid on the bod$ps_svapte cell and this use is valid only if BOD$M_S2_WINDOW is set in bod$l_flags. |
The existing 32-bit Buffered I/O (BUFIO) packet format will continue to be supported. In addition, a new 64-bit BUFIO packet format will be supported. These BUFIO packets are "self identifying". That is, it is possible to distinguish a 32-bit from a 64-bit format BUFIO packet from information in the packet.
Although the structure type code DYN$C_BUFIO is defined and there is an expected layout for the header of buffered I/O packet there currently is no formal definition of a structure. Existing code in drivers and IOCIOPOST.MAR uses numeric constants as offsets.
The existing 32-bit BUFIO packet will be formally defined along with a new 64-bit BUFIO packet format. The 64-bit BUFIO structure format will also be used for 64-bit diagnostic buffer packets (see Table A-3).
| Field | Type | Comments |
|---|---|---|
| bufio$ps_pktdata | void * | Pointer to the buffered data within the packet. |
| bufio$ps_uva32 | void * | 32-bit pointer to user's address space. On a read function data is transfered from that user virtual address to the buffer packet during FDT processing. On a write function data is transfered to that user virtual address from the buffer packet during I/O Postprocessing. If this cell contains the value BUFIO$K_64 (-1) then the pointer to the user buffer is in bufio$pq_uva64. |
| bufio$w_size | unsigned short | Size of the BUFIO packet in bytes. |
| bufio$b_type | unsigned char | Nonpaged pool packet type code, DYN$C_BUFIO |
| BUFIO$K_HDRLEN32 | constant | Size in bytes of the minimal buffered I/O packet header with a 32-bit user virtual address (12). |
| bufio$pq_uva64 | VOID_PQ | 64-bit pointer to user's address space. On a read function data is transfered from that user virtual address to the buffer packet during FDT processing. On a write function data is transfered to that user virtual address from the buffer packet during I/O Postprocessing. This cell contains a valid address only if the bufio$ps_uva32 cell contains the value BUFIO$K_64 (-1). |
| BUFIO$K_HDRLEN64 | constant | Size in bytes of the minimal buffered I/O packet header with a 64-bit user virtual address (24). |
The CXB structure defines the format of entries that are linked together to build a complex chained buffered I/O packet.
The CXB structure will be enhanced such that it can be used by existing code with no source changes to support a 32-bit caller's buffer address. However, the same enhanced CXB structure can be used to support a 64-bit caller's buffer address as well (see Table A-4).
| Field | Type | Comments |
|---|---|---|
| cxb$ps_pktdata | void * | Pointer to the buffered data within the packet. This cell will be overlaid on the existing cxb$l_fl cell to reflect its current alternate use. |
| cxb$ps_uva32 | void * | 32-bit pointer to user's address space. If this cell contains the value BUFIO$K_64 (-1) then the pointer to the user buffer is in cxb$pq_uva64. This cell will be overlaid on the existing cxb$l_bl cell to reflect its current alternate use. |
| cxb$pq_uva64 | VOID_PQ | 64-bit pointer to user's address space. This cell contains a valid address only if the cxb$ps_uva32 cell contains the value BUFIO$K_64 (-1). This cell will be inserted as the last aligned quadword just before the end of the standard CXB header which is CXB$K_LENGTH bytes long. |
The DCBE structure is the Data Chain Block that is used by the OpenVMS LAN driver VMS Communications Interface (VCI). A DCBE is used to connect to a VCRP all or part of the data to be transmitted. A chain of DCBEs is used when the data is contained in more than one discontiguous buffer in virtual memory.1
There are two mutually exclusive methods that a DCBE can use to identify the start of the buffer:
Because a VCRP can also be used as a DCBE, the named DCBE cells must be at the same offsets as their VCRP counterparts. Therefore, DCBE changes are reflected in the VCRP and changes to the common portion of the VCRP are reflected in the DCBE.
In addition, SYS$PEDRIVER overlays a DCBE with the vcrp$t_internal_stack area within the VCRP. Therefore, an increase in the size of the DCBE must be reflected by a corresponding increase in the size of the internal stack area within the VCRP (see Table A-5).
| Field | Type | Comments |
|---|---|---|
| dcbe$l_reserved | int32[13] | This existing vector of 6 filler longwords has been increased to 13 fill longwords to reflect the increased size of the common portion of the VCRP. The common portion of the VCRP has been increased to accommodate either an ACB64 or ACB structure. |
| dcbe$pq_buffer_addr64 | VOID_PQ | 64-bit buffer address. This cell is available for use by upper-level VCMs only. Note that this cell does not replace the dcbe$l_buffer_address cell which continues to be used by lower-level VCMs. The dcbe$pq_buffer_addr64 cell has been added after the dcbe$l_bcnt cell. |
| dcbe$r_diobm | DIOBM | Embedded fixed-size primary "direct I/O buffer map" structure. This DIOBM structure is available for use by upper-level VCMs that need to lock down a buffer and provide a value for the dcbe$l_svapte cell. This structure has been added just before the end of the DCBE header. |
1 The DCBE should not be confused with the similarly named DCB structure. The DCB is used internally by the DECnet Phase IV NETDRIVER. As described in Section 2.2.3, the dcb$l_svapte cell value will be derived from the irp$l_svapte cell in the associated IRP and will rely on the DIOBM that's embedded in the IRP. For this reason there is no need for an embedded DIOBM in the DCB structure. |
| Previous | Next | Contents | Index |
|
|
| privacy and legal statement | ||
| 6466PRO_006.HTML | ||