![[Compaq]](../../images/compaq.gif)
![[Go to the documentation home page]](../../images/buttons/bn_site_home.gif)
![[How to order documentation]](../../images/buttons/bn_order_docs.gif)
![[Help on this site]](../../images/buttons/bn_site_help.gif)
![[How to contact us]](../../images/buttons/bn_comments.gif)
![[OpenVMS documentation]](../../images/ovmsdoc_sec_head.gif)
| Document revision date: 19 July 1999 | |
|
|
|
|
|
|
| Previous | Contents | Index |
This chapter describes how to use the OpenVMS Sort/Merge utility (SORT/MERGE). The Sort/Merge utility performs two operations:
On Alpha systems, you can also choose the high-performance Sort/Merge utility. This utility takes advantage of the Alpha architecture to provide better performance for most Sort and Merge operations. Refer to Section 11.1 for information.
This chapter describes:
For additional information, see the following:
On Alpha systems, you can also choose the high-performance Sort/Merge utility. This utility takes advantage of the Alpha architecture to provide better performance for most Sort and Merge operations.
The high-performance Sort/Merge utility uses the same command line interface as SORT/MERGE. Any differences between the high-performance Sort/Merge utility and SORT/MERGE are noted throughout this chapter.
Use the SORTSHR logical to select the high-performance Sort/Merge utility. Define SORTSHR to point to the high-performance sort executable in SYS$LIBRARY as follows:
$ define sortshr sys$library:hypersort.exe |
To return to SORT/MERGE, deassign SORTSHR. The SORT/MERGE utility is the default if SORTSHR is not defined.
The behavior of the high-performance Sort/Merge utility is the same as SORT/MERGE, except as shown in Table 11-1.
If you attempt to use an unsupported qualifier or assign an unsupported value to a qualifier, the high-performance Sort/Merge utility generates an error.
| Feature | High-Performance Sort/Merge Behavior |
|---|---|
| Key data types |
The H-FLOATING and ZONED decimal data types are not supported.
The size of a BINARY data type key must be 1, 2, 4, or 8 bytes. A 16-byte binary key is not supported. (Implementation of this feature is deferred to a future OpenVMS Alpha release.) |
| Collating sequences |
The National Character Set (NCS) collating sequences are not supported.
(Implementation of this feature is deferred to a future OpenVMS Alpha
release.) Do not specify the name of an NCS collating sequence for the
/COLLATING_SEQUENCE qualifier. The ASCII, EBCDIC, and MULTINATIONAL
collating sequences are supported. The default is ASCII.
You cannot define or modify your own collating sequence through the use of a specification file. (Implementation of this feature is deferred to a future OpenVMS Alpha release.) |
| Specification files | Specification files are not supported. (Implementation of this feature is deferred to a future OpenVMS Alpha release.) Do not use the /SPECIFICATION qualifier. |
| Internal sorting process | Only the record sort process is supported. (Implementation of this feature is deferred to a future OpenVMS Alpha release.) You can specify /PROCESS=RECORD or omit the /PROCESS qualifier. The TAG, ADDRESS, and INDEX values for the /PROCESS qualifier are not supported. |
| Statistical summary information |
The following statistics are currently supported:
The following statistics are unavailable:
Full implementation of this feature is deferred to a future OpenVMS Alpha release. |
To sort files, use the DCL command SORT. Specify the names of the files to be sorted, separated by commas, followed by the name of the ordered output file to be created.
Optionally, you can specify a key for each field on which you want to sort. Each key includes the following information:
If you do not specify any keys, Sort assumes there is only one key and that this key field:
The following two examples use the default key.
$ SORT NAMES.LST BYNAME.LST |
Figure 11-1 List Sorted in Ascending Order

$ SORT NAMES.LST,NAMES2.LST BYNAME.LST |
See Section 11.9 for a complete list of SORT qualifiers.
11.2.1 Defining a Key
Use the /KEY qualifier to define a key. When specifying multiple keys,
use a separate /KEY qualifier for each key.
Table 11-2 describes the five elements that comprise a key.
| Key Element | Value | Description | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Key position | POSITION: n | The position of the first byte of the key field within the record. The first byte in a record is position 1. POSITION: n is required. | |||||||||||||||
| Key size | SIZE: n |
The length of the key field. SIZE:
n is required except for floating-point data.
The data type you specify for the key determines what values are acceptable when specifying size. The following table lists the possible values for each type of data and the units used to specify the size of the key.
For decimal data, if the decimal sign is stored in a separate byte, that byte is not counted toward the size of the data. If you specify a key that extends beyond the end of a record, Sort treats the missing characters as null characters. |
|||||||||||||||
| Data type | CHARACTER | Character data. CHARACTER is the default data type. | |||||||||||||||
| BINARY |
Binary data.
SIGNED --- Signed binary or decimal data. SIGNED is the default for binary and decimal data. UNSIGNED --- Unsigned binary or decimal data. |
||||||||||||||||
| F_FLOATING | F_FLOATING format data. | ||||||||||||||||
| D_FLOATING | D_FLOATING format data. | ||||||||||||||||
| G_FLOATING | G_FLOATING format data. | ||||||||||||||||
| H_FLOATING | On VAX systems, H_FLOATING format data. (Not currently supported by the high-performance Sort/Merge utility.) | ||||||||||||||||
| S_FLOATING | On Alpha systems, IEEE S_FLOATING format data. | ||||||||||||||||
| T_FLOATING | On Alpha systems, IEEE T_FLOATING format data. | ||||||||||||||||
| DECIMAL |
Decimal data.
TRAILING_SIGN --- Trailing sign decimal data. TRAILING_SIGN is the default for decimal data. LEADING_SIGN --- Leading sign decimal data. The leading sign must be in the first position of the field and the field must be left zero padded. OVERPUNCHED_SIGN --- Overpunched decimal data. OVERPUNCHED_SIGN is the default for decimal data. SEPARATE_SIGN --- Separate sign decimal data. |
||||||||||||||||
| ZONED | Zoned decimal data. (Not currently supported by the high-performance Sort/Merge utility.) | ||||||||||||||||
| PACKED_DECIMAL | Packed decimal data. | ||||||||||||||||
| Sort order | ASCENDING | Orders the sorting operation in ascending alphabetical or numerical order. ASCENDING is the default order. | |||||||||||||||
| DESCENDING | Orders the sorting operation in descending alphabetical or numerical order. | ||||||||||||||||
| Key priority | NUMBER: n | Specifies the order of priority of each key if you do not list multiple keys in the order of their priority. A value of 1 to 255 can be specified. | |||||||||||||||
If the data in the key fields is not character data, you must specify the data type. The following data types are recognized by the Sort/Merge utility:
| BINARY, [SIGNED] | |
| BINARY, UNSIGNED | |
| CHARACTER | |
| DECIMAL, LEADING_SIGN, SEPARATE_SIGN [SIGNED] | |
| DECIMAL, LEADING_SIGN, [OVERPUNCHED_SIGN, SIGNED] | |
| DECIMAL [,SIGNED, TRAILING_SIGN, OVERPUNCHED_SIGN] | |
| DECIMAL, [TRAILING SIGN], SEPARATE_SIGN, [SIGNED] | |
| DECIMAL, UNSIGNED | |
| D_FLOATING | |
| F_FLOATING | |
| G_FLOATING | |
| H_FLOATING | |
| S_FLOATING, IEEE (Alpha systems only) | |
| T_FLOATING, IEEE (Alpha systems only) | |
| PACKED_DECIMAL | |
| ZONED |
The items in brackets are defaults and need not be specified.
For decimal string data, the Sort/Merge utility reports an invalid digit in the input string differently for VAX and Alpha systems. On VAX systems, you receive a message that the invalid digit (or reserved operand) is converted to a valid decimal string for comparison purposes. On Alpha systems, Sort/Merge performs the same conversion but does not display a message. In both cases, the data from the input file is written to the output file without change. |
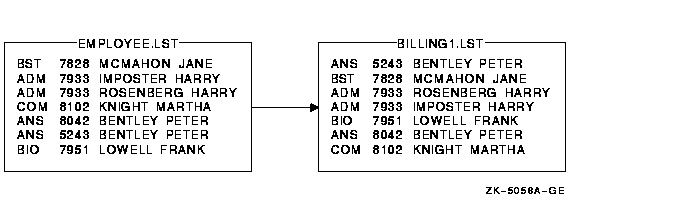
In Figure 11-2, each record in the file EMPLOYEE.LST consists of three fields: (1) a department name, (2) an account number, and (3) a customer name.
Figure 11-2 Record Fields in a List

The following examples illustrate how to sort the records in EMPLOYEE.LST both with, and without, a key field:
$ SORT/KEY=(POSITION:5,SIZE:4,DECIMAL) EMPLOYEE.LST BILLING1.LST |
Figure 11-3 Sorting by Key Field
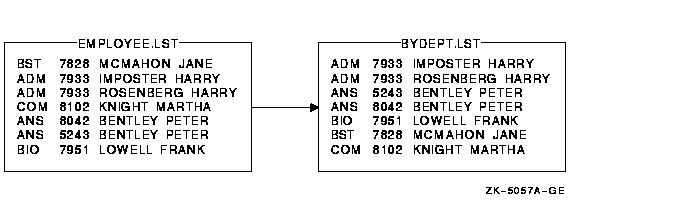
$ SORT EMPLOYEE.LST BYDEPT.LST |
Figure 11-4 Sorting with Default Key Records
You can sort with more than one key (up to a limit of 255 keys). You can specify multiple keys in order of their priority with the primary key first, the secondary key next, and so on. Alternately, you can specify a key's priority using NUMBER:n. Each key can be ascending or descending.
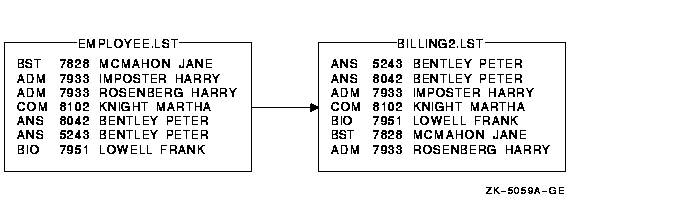
In the following example, the file EMPLOYEE.LST is sorted by the customer name key first and then (where there are identical names), by the account number:
$ SORT /KEY=(POSITION:10,SIZE:15,CHARACTER) - _$ /KEY=(POSITION:5,SIZE:4,DECIMAL) EMPLOYEE.LST BILLING2.LST |
Figure 11-5 shows the results of this Sort operation.
Figure 11-5 Sorting with Multiple Key Fields
In the following example, records are sorted first by the department name in descending order, then by the customer name in ascending order:
$ SORT/KEY=(POSITION:1,SIZE:3,DESCENDING) - _$ /KEY=(POSITION:10,SIZE:15) - _$ EMPLOYEE.LST BILLING3.LST |
Figure 11-6 shows the results of this Sort operation.
Figure 11-6 Sorting with Multiple Key Fields (Ascending and Descending Order)

By default, Sort/Merge keeps records with identical key fields but does not necessarily maintain the same order in which they appeared in the input file. To control the way in which records with identical keys are sorted, specify one of the following qualifiers:
The /STABLE and /NODUPLICATES qualifiers are incompatible. You cannot specify both qualifiers on the same command line.
In the following example, records with duplicate account numbers are eliminated from the file EMPLOYEE.LST:
$ SORT /KEY=(POSITION:5,SIZE:4)/NODUPLICATES EMPLOYEE.LST BUDGET.LST |
Figure 11-7 shows the results of this Sort operation.
Figure 11-7 Sorting with Identical Key Fields

If you sort records that contain items other than character data, specify the data type of each key. In addition, take care in calculating starting positions and sizes because the items being compared can occupy more than 1 byte.
If you are sorting a file that contains 20 characters followed by 3 floating-point numbers in F_floating format, the positions are as follows:
To sort the file by the third floating-point number, specify the key field as follows:
$ SORT/KEY=(POSITION:29,F_FLOATING) STATS.RAW STATS.SOR |
You do not need to specify the size of the floating-point number
because it is fixed at four bytes.
11.2.5 Output File Organization
By default, Sort produces an output file with the same file organization as that of the first input file. To specify a different output file organization, include one of the following qualifiers after the output file specification on the Sort command line:
In the following example, a sequential file is produced after the indexed sequential file EMPLOYEE.LST is sorted:
$ SORT/KEY=(POSITION:10,SIZE:15) - _$ EMPLOYEE.LST BYNAME.LST/SEQUENTIAL |
Sort arranges files using one of the internal processes: record, tag, address, or indexed. (The high-performance Sort/Merge utility supports only the record process. Implementation of tag, address, and index processes is deferred to a future OpenVMS Alpha release.) The process you specify can affect the efficiency of the Sort operation. Refer to Section 11.8 for information about optimizing a Sort or Merge operation.
The following table describes the four types of process. Use the /PROCESS=type qualifier to specify the sort process.
| Sort Process | type | Description |
|---|---|---|
| Record | RECORD | Keeps records intact while sorting and produces an output file consisting of complete records. Record is the default sorting process. |
| Tag | TAG |
Sorts the key fields only and then rereads the input file to produce an
output file of complete records. The net result is the same as for a
complete record sort.
A tag sort is useful if disk space is low because it typically uses less work file space during the sorting. In most cases, a tag sort is slower than a record sort because it requires extra time to reread the input file. |
| Address | ADDRESS |
Sorts the key fields only and produces an output file that is an index
of
record file addresses (RFAs) in binary format.
An address sort is faster than a record sort but you must write a program to associate the record addresses with the records of the input file. |
| Indexed | INDEX |
Sorts the key fields only and produces an output file of keys and RFAs
(in binary format).
As with an address sort, an index sort is faster than a record sort, but you must write a program to associate the record addresses with the records of the input file. |
| Previous | Next | Contents | Index |
|
|
| privacy and legal statement | ||
| 6489PRO_024.HTML | ||