[ 前のページ ]
[ 次のページ ]
[ 目次 ]
[ 索引 ]
[ DOC Home ]
この章では,日本語OpenVMSで使用される文字について説明します。
ここでは,文字集合とコードセットの用語について説明します。
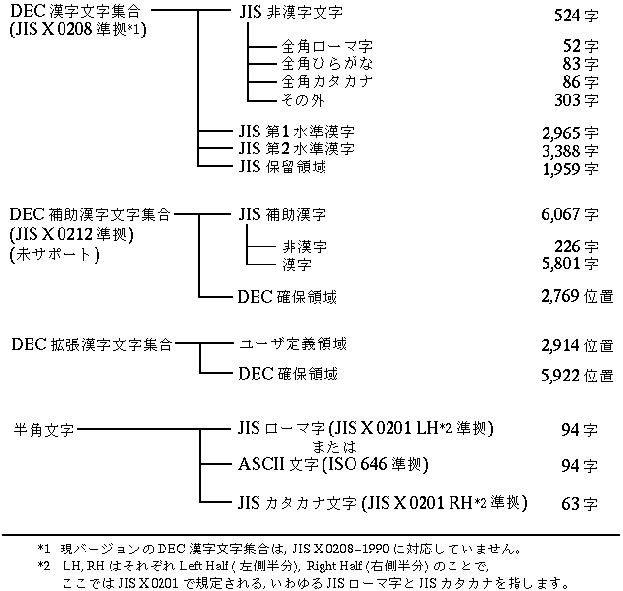
文字集合とは,一般的に,ある目的を満たす異なる文字の集合をいいます。 日本語OpenVMSでは,標準で定められた以下の文字集合を使用します。
| 文字集合名称 | 規定する標準 |
|---|---|
| ASCII文字集合 | ISO 646 |
| JISローマ字文字集合 | JIS X0201 |
| JISカタカナ文字集合 | JIS X0201 |
| JIS漢字文字集合 | JIS X0208 - 1983 |
| JIS補助漢字文字集合( 未サポート) | JIS X0212 - 1990 |
| DEC拡張漢字文字集合 | なし |
コードセットとは,文字集合の文字を一定の手順によって符号化し,各文字に対応する数値を割り振ったものです。 符号化の規約はそれぞれのコードセットによって違うため, 同一の文字が,異なるコードセットでは異なる数値に割り振られることがあります。 また,コードセットによって表現できる文字集合が違います。 日本語OpenVMS では,DEC漢字コードセットおよびSuper DEC漢字コードセットを使うことができます。
日本語OpenVMSでは,標準で規定された文字集合を再規定し, 次のような文字の種類を使うことができます。
日本語OpenVMSでは,第3.1.1項で述べた文字集合にコード付けして,DEC 漢字コードセットとSuper DEC漢字コードセットを定義しています。
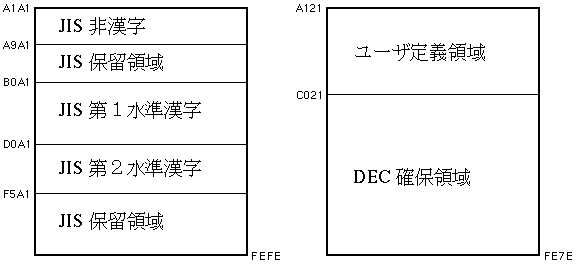
DEC漢字コードセットはASCII (またはJISローマ字)とJIS X0208-1983を組み合わせたコードセットです。 このコードセットでは漢字とASCII (またはJIS ローマ字)を,第1バイトの最上位ビット(8ビット目)で識別することができます。
| 文字集合 | ビット表現 | 16 進表現 |
|---|---|---|
| ASCII/JIS X0201 LH | (0xxxxxxx) | 20 - 7F |
| JIS X0208 | (1xxxxxxx 1xxxxxxx) | A1A1 - FEFE |
| DEC拡張漢字 | (1xxxxxxx 0xxxxxxx) | A121 - FE7E |
| C0 Control | (000xxxxx) | 00 - 1F |
| C1 Control | (100xxxxx) | 80 - 9F |
ユーザ定義領域としてDEC拡張漢字領域の1〜31区(2914文字位置)を使用します。32 区〜94区はDEC確保領域となっています。
図 3-2は,DEC漢字コードセットの漢字コードが,2 バイト・コード空間でどのように定義されているかを示しています。
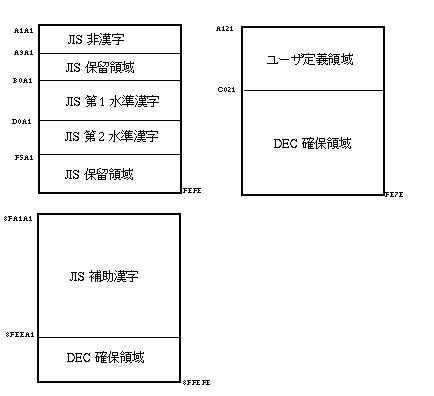
Super DEC漢字コードセットは,DEC漢字コードセットをSS2(16進数で8E) と SS3(16進数で8F)を用いて拡張し,JISカタカナとJIS補助漢字を扱えるようにしたものです。DEC 漢字コードセットとは異なりSuper DEC漢字コードセットは, スクリーン上での見かけの長さと実際に記憶領域に占める文字列の長さが違うので, プログラミング等の際には,十分な長さの領域を用意するように注意する必要があります。
| 文字集合 | ビット表現 | 16 進表現 |
|---|---|---|
| ASCII/JIS X0201 LH | (0xxxxxxx) | 20 - 7F |
| JIS X0208 | (1xxxxxxx 1xxxxxxx) | A1A1 - FEFE |
| DEC拡張漢字 | (1xxxxxxx 0xxxxxxx) | A121 - FE7E |
| JIS X0201 RH | (SS2 1xxxxxxx) | 8EA1 - 8EDF |
| JIS X0212 (未サポート) | (SS3 1xxxxxxx 1xxxxxxx) | 8FA1A1 - 8FFEFE |
| C0 Control | (000xxxxx) | 00 - 1F |
| C1 Control | (100xxxxx) | 80 - 9F |
ユーザ定義領域としてDEC拡張漢字領域の1〜31区(2914文字位置)を使用します。32 区〜94区はDEC確保領域となっています。
図 3-3は,SuperDEC漢字コードセットの漢字コードが, どのように定義されているかを示しています。
[ 前のページ ]
[ 次のページ ]
[ 目次 ]
[ 索引 ]
[ DOC Home ]