| Previous | Contents | Index |
When an INSPECT statement contains a REPLACING phrase, that statement selectively replaces characters or groups of characters in the designated item.
The REPLACING phrase names a search argument of one or more characters and a condition under which the string can be applied to the item being inspected. Associated with the search argument is the replacement value, which must be the same length as the search argument. Each time the search argument finds a match in the item being inspected, under the condition stated, the replacement value replaces the matched characters.
A BEFORE/AFTER phrase can be used to delimit the area of the item being
inspected. A search argument applies only to the delimited area of the
item.
5.3.6.1 The Search Argument
The search argument of the REPLACING phrase names a character string and a condition under which the character string should be compared to the delimited string being inspected.
The CHARACTERS form of the search argument specifies that every character in the delimited string being inspected should be considered to match an imaginary character that serves as the search argument. Thus, the replacement value replaces each character in the delimited string. For example:
INSPECT ITEMA REPLACING CHARACTERS ... |
The ALL, LEADING, and FIRST forms of the search argument specify a particular character string, which can be represented by a literal or an identifier. The search argument character string can be any length. However, each character of the argument must match a character in the delimited string before the compiler considers the argument matched. For example:
INSPECT ITEMA REPLACING ALL ... |
The necessary literal and identifier characteristics are as follows:
The words ALL, LEADING, and FIRST supply conditions that further delimit the inspection operation:
Whenever the search argument finds a match in the item being inspected, the matched characters are replaced by the replacement value. The word BY followed by an identifier or literal specifies the replacement value. For example:
INSPECT ITEMA REPLACING ALL "A" BY "X" ALL "D" BY "X". |
The replacement value must always be the same size as its associated search argument.
If the replacement value is a literal character-string, it must be either a nonnumeric literal or a figurative constant (other than ALL literal). A figurative constant represents as many characters as the length of the search argument requires.
If the replacement value is an identifier, it must be an elementary
item of DISPLAY usage. It can be any class. However, if it is not
alphanumeric, the compiler conducts an implicit redefinition of the
item. This redefinition is the same as the BEFORE/AFTER redefinition
discussed in Section 5.3.2.
5.3.6.3 The Replacement Argument
The replacement argument consists of the search argument (with its condition and character-string), the replacement value, and an optional BEFORE/AFTER phrase, as shown in Figure 5-5.
Figure 5-5 The Replacement Argument
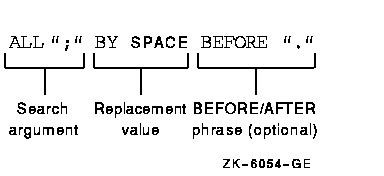
One INSPECT...REPLACING statement can contain more than one replacement argument. Several replacement arguments form an argument list, and the manner in which the list is processed affects the action of any given replacement argument.
The following examples show INSPECT statements with replacement argument lists. The text following each one tells how that list will be processed.
INSPECT FIELD1 REPLACING
ALL "," BY SPACE
ALL "." BY SPACE
ALL ";" BY SPACE.
|
The previous three replacement arguments all have the same replacement value, SPACE, and are active over the entire item being inspected. The statement replaces all commas, periods, and semicolons with space characters and leaves all other characters unchanged.
INSPECT FIELD1 REPLACING
ALL "0" BY "1"
ALL "1" BY "0".
|
Each of these two replacement arguments has its own replacement value and is active over the entire item being inspected. The statement exchanges zeros for 1s and 1s for zeros. It leaves all other characters unchanged.
INSPECT FIELD1 REPLACING
ALL "0" BY "1" BEFORE SPACE
ALL "1" BY "0" BEFORE SPACE.
|
When a search argument finds a match in the item being inspected, the code replaces that character-string and scans to the next position beyond the replaced characters. It ignores the remaining arguments and applies the first argument in the list to the character-string in the new position. Thus, it never inspects the new value that was supplied by the replacement operation. Because of this, the search arguments can have the same values as the replacement arguments with no chance of interference. |
The statement also exchanges zeros and 1s. Here, however, the first space in FIELD1 causes both arguments to become inactive.
INSPECT FIELD1 REPLACING
ALL "0" BY "1" BEFORE SPACE
ALL "1" BY "0" BEFORE SPACE
CHARACTERS BY "*" BEFORE SPACE.
|
The first space causes the three replacement arguments to become
inactive. This argument list exchanges zeros for 1s, 1s for zeros, and
asterisks for all other characters in the delimited area. If the BEFORE
phrase is removed from the third argument, that argument will remain
active across all of FIELD1. Within the area delimited by the first
space character, the third argument replaces all characters except 1s
and zeros with asterisks. Beyond this area, it replaces all characters
(including the space that delimited FIELD1 for the first two arguments,
and any zeros and 1s) with asterisks.
5.3.6.5 Interference in Replacement Argument Lists
When several search arguments, all active at the same time, contain one or more identical characters, they can interfere with each other---and consequently affect the replacement operation. This interference is similar to the interference that occurs between tally arguments.
The action of a search argument is never affected by the BEFORE/AFTER delimiters of other arguments, because the compiler scans for delimiter matches before it scans for replacement operations.
The action of a search argument is never affected by the characters of any replacement value, because the scanner does not inspect the replaced characters again during execution of the INSPECT statement. Interference between search arguments, therefore, depends on the order of the arguments, the values of the arguments, and the active/inactive status of the arguments. The discussion in Section 5.3.5.4 about interference in tally argument lists generally applies to replacement arguments as well.
The following rules help minimize interference in replacement argument lists:
When an INSPECT statement contains a CONVERTING phrase, that statement selectively replaces characters or groups of characters in the designated item; it executes as if it were a Format 2 INSPECT statement with a series of ALL phrases. (See the INSPECT statement formats in the Compaq COBOL Reference Manual.)
An example of the use of the CONVERTING phrase follows:
IDENTIFICATION DIVISION.
PROGRAM-ID. PROGX.
ENVIRONMENT DIVISION.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 X PIC X(28).
PROCEDURE DIVISION.
A.
MOVE "ABC*ABC*ABC ABC@ABCABC" TO X.
INSPECT X CONVERTING "ABC" TO "XYZ"
AFTER "*" BEFORE "@".
DISPLAY X.
STOP RUN.
X before INSPECT executes X after INSPECT executes
ABC*ABC*ABC ABC@ABCABC ABC*XYZ*XYZ XYZ@ABCABC
|
Programmers most commonly make the following errors when writing INSPECT statements:
The Compaq COBOL I/O system offers you a wide range of record management techniques while remaining transparent to you. You can select one of several file organizations and access modes, each of which is suited to a particular application. The file organizations available through Compaq COBOL are sequential, line sequential, relative, and indexed. The access modes are sequential, random, and dynamic.
This chapter introduces you to the following Compaq COBOL I/O features:
For information about low-volume or terminal screen I/O using the ACCEPT and DISPLAY statements, see Chapter 11 and the Compaq COBOL Reference Manual.
The operating system provides you with I/O services for handling, controlling, and spooling your I/O needs or requests. Compaq COBOL, through the I/O system, provides you with extensive capabilities for data storage, retrieval, and modification.
On the OpenVMS Alpha operating system, the Compaq COBOL I/O system consists of the Run-Time Library (RTL), which accesses Record Management Services (RMS). Refer to the OpenVMS Record Management Utilities Reference Manual and the OpenVMS Record Management Services Reference Manual for more information about RMS. <>
On the Tru64 UNIX operating system, the Compaq COBOL I/O system consists of the
Run-Time Library (RTL) and facilities of Tru64 UNIX. In addition,
the facilities of a third-party ISAM package are required for any use
of ORGANIZATION INDEXED. <>
6.1 Defining Files and Records
A file is a collection of related records. You can specify the organization and size of a file as well as the record format and physical record size. The system creates a file with these characteristics and stores them with the file. Any program that accesses a file must specify the same characteristics as those that the system stored for that file when creating it.
A record is a group of related data elements. The space a record needs on a physical device depends on the file organization, the record format, and the number of bytes the record contains.
File organization is described in Section 6.1.1. Record format is
described in Section 6.1.2.
6.1.1 File Organization
Compaq COBOL supports the following four types of file organization:
On Tru64 UNIX, a third-party product is required for INDEXED runtime support. See the Read Before Installing... letter for up-to-date details on how to obtain the INDEXED runtime support. <> |
Table 6-1 summarizes the advantages and disadvantages of these file organizations.
| File Organizations | Advantages | Disadvantages |
|---|---|---|
| Sequential | Uses disk and memory efficiently | Allows sequential access only |
| Provides optimal usage if the application accesses all records sequentially on each run | Allows records to be added only to the end of a file | |
| Provides the most flexible record format | ||
| Allows READ/WRITE sharing | ||
| Allows data to be stored on many types of media, in a device-independent manner | ||
| Allows easy file extension | ||
|
Line Sequential
|
Most efficient storage format | Allows sequential access only |
| Compatible with text editors | Used for printable characters only | |
| Open Mode I/O is not allowed | ||
| Relative | Allows sequential, random, and dynamic access | Allows data to be stored on disk only |
| Provides random record deletion and insertion | Requires that record cells be the same size | |
| Allows READ/WRITE sharing | ||
| Indexed | Allows sequential, random, and dynamic access | Allows data to be stored on disk only |
| Allows random record deletion and insertion on the basis of a user-supplied key | Requires more disk space | |
| Allows READ/WRITE sharing | Uses more memory to process records | |
| Allows variable-length records to change length on update | Generally requires multiple disk accesses to randomly process a record | |
| Allows easy file extension |
Sequential input/output, in which records are written and read in sequence, is the simplest and most common form of I/O. It can be performed on all I/O devices, including magnetic tape, disk, terminals, and line printers.
Sequential files consist of records that are arranged in the order in which they were written to the file. Figure 6-1 illustrates sequential file organization.
Figure 6-1 Sequential File Organization
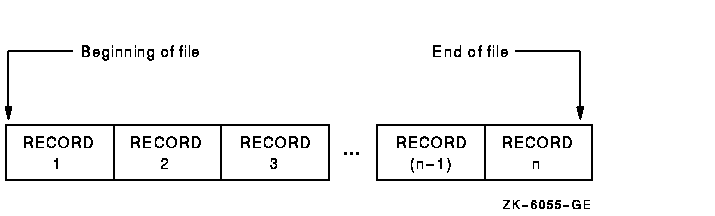
Sequential files always contain an end-of-file (EOF) indication. On magnetic tapes, it is the EOF mark; on disk, it is a counter in the file header that designates the end of the file. Compaq COBOL statements can write over the EOF mark and, thus, extend the length of the file. Because the EOF indicates the end of useful data, Compaq COBOL provides no method for reading beyond it, even though the amount of space reserved for the file exceeds the amount actually used.
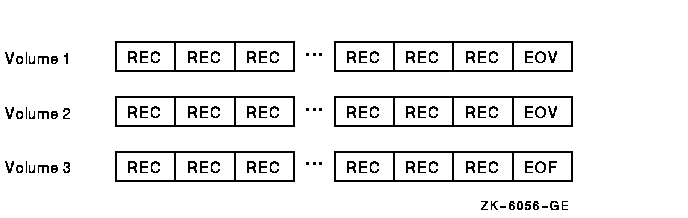
Occasionally a file with sequential organization, for example, a multiple-reel magnetic tape file, is so large that it requires more than one volume. An end-of-volume (EOV) label marks the end of recorded information on each volume and signals the file system to switch to a new volume. On multiple-volume files, the EOF mark appears only once, at the end of the last record on the last volume. Figure 6-2 depicts a multiple-volume, sequential file.
Figure 6-2 A Multiple-Volume, Sequential File
When you select the medium for your sequential file, consider the following:
See the OpenVMS I/O User's Reference Manual or the ltf(4) manpage for more information on magnetic tape formats.
Line Sequential File Organization
Line sequential file structure is essentially similar to the structure of sequential files, with the major difference being record length. Figure 6-3 illustrates line sequential file organization.
Figure 6-3 Line Sequential File Organization
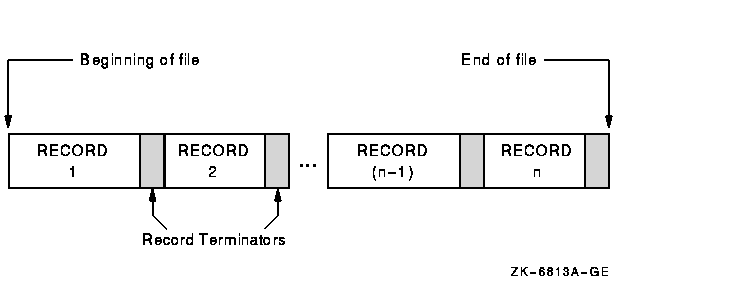
A line sequential file consists of records of varying lengths arranged in the order in which they were written to the file. Each record is terminated with a "newline" character. The newline character is a line feed record terminator ('0A' hex).
Each record in a line sequential file should contain only printable characters and should not be written with a WRITE statements that contains either a BEFORE ADVANCING or AFTER ADVANCING statement.
Record length is determined by the maximum record length in the FD entry in the FILE-CONTROL section and the number of characters in a line (not including the record terminator).
When your Compaq COBOL program reads a line from a line sequential file that is shorter than the record area, it reads up to the record terminator, discards the record terminator, and pads the rest of the record with a number of spaces necessary to equal the record's specified length. When your program reads a line from a line sequential file that is longer than the record area, it reads the number of characters necessary to fill the record area. The next READ, if any, will begin at the next printable character in the file that is not a record terminator.
Line sequential file organization is useful in reading and printing files that were created by an editor or word processor, which typically do not write fixed-length records.
A relative file consists of fixed-size record cells and uses a key to retrieve its records. The key, called a relative key, is an integer that specifies the record's storage cell or record number within the file. It is analogous to the subscript of a table. Relative file processing is available only on disk devices.
Any record on a relative file (unlike a sequential file) can be accessed with one READ operation. Also, relative files allow the program to read forward with respect to the current relative key. In addition to random access by relative key, relative files also permit you to delete and update records by relative key. Relative files are used primarily when records must be accessed in random order and the records can easily be associated with numbers that give the relative positions in the file.
In relative file organization, not every cell must contain a record. Although each cell occupies one record space, a field preceding the record on the storage medium indicates whether or not that cell contains a valid record. Thus, a file can contain fewer records than it has cells, and the empty cells can be anywhere in the file.
The numerical order of the cells remains the same during all operations on a relative file. However, accessing statements can move a record from one cell to another, delete a record from a cell, insert new records into empty cells, or rewrite existing cells.
With relative file processing, the I/O system organizes a file as a series of fixed-sized record cells. Cell size is based on the size specified as the maximum permitted length for a record in the file. The I/O system considers these cells as successively numbered from 1 (the first) to n (the last). A cell's relative record number (RRN) represents its location relative to the beginning of the file.
Because cell numbers in a relative file are unique, they can be used to identify both the cell and the record (if any) occupying that cell. Thus, record number 1 occupies the first cell in the file, record number 21 occupies the twenty-first cell, and so forth. Figure 6-4 illustrates relative file organization.
Figure 6-4 Relative File Organization
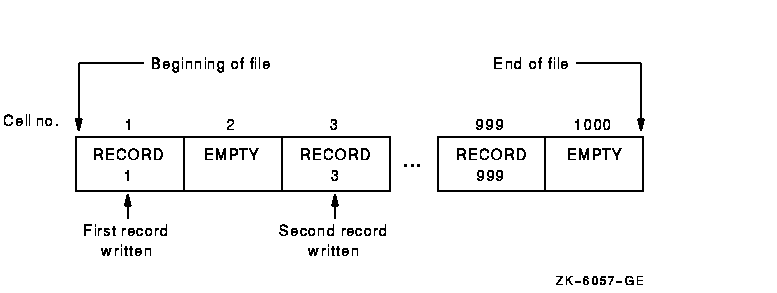
Relative files are used like tables. Their advantage over tables is that their size is limited to disk space rather than memory space. Also, their information can be saved from run to run. Relative files are best for records that are easily associated with ascending, consecutive numbers (so that the program conversion from data to cell number is easy), such as months (record keys 1 to 12), or the 50 U.S. states (record keys 1 to 50).
An indexed file uses primary and alternate keys in the record to retrieve the contents of that record. Compaq COBOL allows sequential, random, and dynamic access to records. You access each record by one of its primary or alternate keys. Indexed file processing is available only on disk devices.
Unlike the sequential ordering of records in a sequential file or the relative positioning of records in a relative file, the physical location of records in indexed file organization is transparent to the program. You can add new records to an indexed file without recreating the file. You can also delete records, making room for new records.
Indexed file organization allows you to use a key to uniquely identify a record within the file. The location and length of the key are identical in all records. When creating an indexed file, you must select the data items to be the keys. Selecting such a data item indicates to the I/O system that the contents (key value) of that data item in any record written to the file can be used by the program to identify that record for subsequent retrieval. For more information, see the Environment Division clauses RECORD KEY IS and ALTERNATE RECORD KEY IS in the Compaq COBOL Reference Manual.
| Previous | Next | Contents | Index |