$ SORT NAMES.LST BYNAME.LST
このコマンドは,図 11-1に示すように, 出力ファイルBYNAME.LSTを作成します。
図 11-1 昇順にソートした結果
$ SORT NAMES.LST,NAMES2.LST BYNAME.LST
[ 前のページ ]
[ 次のページ ]
[ 目次 ]
[ 索引 ]
[ DOC Home ]
本章では,OpenVMSのSort/Mergeユーティリティ(SORT/MERGE)の使用方法について説明します。Sort/Merge ユーティリティは,次の2種類の作業を実行します。
Alphaシステムでは,高性能Sort/Mergeユーティリティを選択することもできます。 このユーティリティでは,Alphaアーキテクチャを活用することにより, ほとんどのSort操作およびMerge操作で性能を向上させることができます。 詳細は第11.1節を参照してください。
本章では,次のことを説明します。
その他の情報については,次のものを参照してください。
Alphaシステムでは,高性能Sort/Mergeユーティリティを選択することもできます。 このユーティリティでは,Alphaアーキテクチャを活用することにより, ほとんどのSort操作およびMerge操作で性能を向上させることができます。
高性能Sort/Mergeユーティリティは,SORT/MERGEと同じコマンド行インタフェースを使用します。 高性能Sort/MergeユーティリティとSORT/MERGEとの違いについては, 本章で紹介します。
高性能Sort/Mergeユーティリティを使用するときは,論理名SORTSHRを使用します。 次のようにSORTSHRを定義して,SYS$LIBRARYにある高性能ソート実行可能プログラムを指定します。
$ define sortshr sys$library:hypersort.exe
SORT/MERGEに戻るときは,SORTSHRの割り当てを解除します。SORTSHRが定義されていない場合,SORT/MERGE ユーティリティが省略時の値として設定されます。
高性能Sort/Mergeユーティリティの動作は,ほとんどSORT/MERGEユーティリティの動作と同じです。 相違点は,表 11-1に示します。
サポートされていない修飾子を使用しようとしたり,サポートされていない値を修飾子に指定しようとしたりすると, 高性能Sort/Mergeユーティリティはエラーを表示します。
| キー・データ・タイプ | H-FLOATINGおよびZONED
10進データ・タイプはサポートされていません。
BINARYデータ・タイプ・キーのサイズは,1バイト,2バイト,4バイト, 8バイトのいずれかでなければなりません。16バイトのバイナリ・キーはサポートされていません( これはOpenVMS Alphaの将来のリリースでサポートされる予定です) 。 |
| 照合順序 | NCS(National Character Set)照合順序はサポートされていません(
これはOpenVMS Alphaの将来のリリースでサポートされる予定です)。
/COLLATING_SEQUENCE修飾子にNCS照合順序を指定しないでください。
ASCII,EBCDIC,およびMULTINATIONAL照合順序はサポートされています。
省略時の設定はASCIIです。
指定ファイルを使用して,照合順序を定義したり変更したりすることはできません( これはOpenVMS Alphaの将来のリリースで解決される予定です) 。 |
| 指定ファイル | 指定ファイルはサポートされていません( これはOpenVMS Alphaの将来のリリースでサポートされる予定です) 。/SPECIFICATION修飾子は使用しないでください。 |
| 内部ソート・プロセス | レコードのソート・プロセスのみサポートされています( これはOpenVMS Alphaの将来のリリースで解決される予定です)。 /PROCESS=RECORD修飾子を指定することも,または/PROCESS修飾子を省略することもできます。/PROCESS 修飾子でTAG,ADDRESS,およびINDEXを指定しないでください。 |
| 統計情報 | 現在サポートされているのは次の統計情報です。
Records read (読み込まれたレコード数) Records sorted (ソートされたレコード数) Records output (出力されたレコード数) Input record length (入力レコード長) 次の統計情報は利用できません。 Internal length (内部長) Output record length (出力レコード長) Sort tree size (ソート・ツリー・サイズ) Number of initial runs (初期実行回数) Maximum merge order (最大マージ順) Number of merge passes (マージ・パス回数) Work file allocation (ワーク・ファイル割り当て) この機能の完全な実装は将来のOpenVMS Alphaリリースで行われる予定です。 |
ファイルをソートするときは,DCLのSORTコマンドを使用します。ソートする入力ファイルを複数指定するときは, それぞれのファイルをコンマで区切り, 最終的に作成されるソート済みの出力ファイルの名前をその後に続けます。
オプションとして,ソートに使用する各フィールドのキーを指定することができます。 それぞれのキーには,次の情報が含まれます。
キーを指定しないでソートを行う場合,キーが1つだけ存在しており,このキー・ フィールドが次のようになっているものと想定されます。
次の2つの例は,省略時のキーが使用されています。
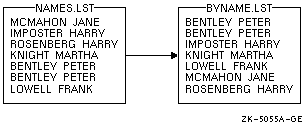
$ SORT NAMES.LST BYNAME.LST
このコマンドは,図 11-1に示すように, 出力ファイルBYNAME.LSTを作成します。
$ SORT NAMES.LST,NAMES2.LST BYNAME.LST
すべてのSORTの修飾子の一覧については,第11.9 節を参照してください。
キーを定義するときは,/KEY修飾子を使用します。複数のキーを指定するときは, それぞれのキーごとに/KEY修飾子を使用します。
表 11-2は,キーを構成する5つの要素について説明しています。
| キー要素 | 値 | 説明 | ||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| キーの位置 | POSITION:n | レコード内にあるキー・フィールドの1バイト目の位置を表す。 レコードの1バイト目が1になる。 POSITION:n は必ず指定しなければならない。 | ||||||||||||||||||||||||
| キー・サイズ | SIZE:n | キー・フィールドの長さを表す。
浮動小数データの場合を除き,SIZE:n は必ず指定しなければならない。
キーに指定するデータ型により,サイズを指定するときに受け付けられる値が決まる。 次の表は,それぞれのデータ型に対応する値と, キーのサイズを指定するときに使用する単位を表す。
10進データでは,10進記号が別のバイトに格納される場合,そのバイトはデータのサイズにカウントされない。 指定したキーがレコードの終わりを越えた場合,失われた文字は空文字として扱われる。 | ||||||||||||||||||||||||
| データ型 | CHARACTER | 文字データ。CHARACTERが省略時のデータ型になる。 | ||||||||||||||||||||||||
| BINARY | バイナリ・データ。
SIGNED-符号付きバイナリ・データまたは符号付き10進データ。バイナリ・ データおよび10進データの場合,SIGNEDが省略時の値になる。 UNSIGNED-符号なしバイナリ・データまたは符号なし10進データ。 | |||||||||||||||||||||||||
| F_ FLOATING | F_FLOATING形式のデータ。 | |||||||||||||||||||||||||
| D_FLOATING | D_FLOATING 形式のデータ。 | |||||||||||||||||||||||||
| G_ FLOATING | G_FLOATING形式のデータ。 | |||||||||||||||||||||||||
| H_FLOATING | VAXシステムでは,H_FLOATING 形式のデータになる(現在,高性能Sort/Mergeユーティリティではサポートされていない) 。 | |||||||||||||||||||||||||
| S_FLOATING | Alphaシステムでは,IEEE S_FLOATING 形式のデータになる。 | |||||||||||||||||||||||||
| T_FLOATING | Alphaシステムでは,IEEE T_FLOATING 形式のデータになる。 | |||||||||||||||||||||||||
| DECIMAL | 10進データ。
TRAILING_SIGN-後続符号10進データ。10進データの場合,TRAILING_SIGN が省略時の値になる。 LEADING_SIGN-先行符号10進データ。先行符号はフィールドの最初になければならず, フィールドの残りのスペースにはゼロが埋め込まれる。 OVERPUNCHED_SIGN-オーバパンチ10進データ。10進データの場合, OVERPUNCHED_SIGNが省略時の値になる。 SEPARATE_SIGN-分割符号10進データ。 | |||||||||||||||||||||||||
| ZONED | ゾーン10進データ(現在,高性能Sot/Merge ユーティリティではサポートされていない)。 | |||||||||||||||||||||||||
| PACKED_DECIMAL | パック10 進データ。 | |||||||||||||||||||||||||
| ソート順 | ASCENDING | ソート操作を,英数字の昇順でソートする。ASCENDING が省略時の順序になる。 | ||||||||||||||||||||||||
| DESCENDING | ソート操作を,英数字の降順でソートする。 | |||||||||||||||||||||||||
| キーの優先順位 | NUMBER:n | 複数のキーが優先順位に従ってリストされていない場合, それぞれのキーの優先順位を指定する。1 〜255までの値が指定できる。 | ||||||||||||||||||||||||
キー・フィールドのデータが文字データでない場合は,データ型を指定する必要があります。Sort/Merge ユーティリティでは,次のデータ型が認識されます。
| BINARY, [SIGNED] |
| BINARY, UNSIGNED |
| CHARACTER |
| DECIMAL, LEADING_SIGN, SEPARATE_SIGN [SIGNED] |
| DECIMAL, LEADING_SIGN, [OVERPUNCHED_SIGN, SIGNED] |
| DECIMAL [,SIGNED, TRAILING_SIGN, OVERPUNCHED_ SIGN] |
| DECIMAL, [TRAILING SIGN], SEPARATE_SIGN, [SIGNED] |
| DECIMAL, UNSIGNED |
| D_FLOATING |
| F_FLOATING |
| G_FLOATING |
| H_ FLOATING |
| S_FLOATING, IEEE (Alphaシステムのみ) |
| T_FLOATING, IEEE (Alphaシステムのみ) |
| PACKED_DECIMAL |
| ZONED |
[ ]かっこ内の項目は省略時の値になるため,指定する必要はありません。
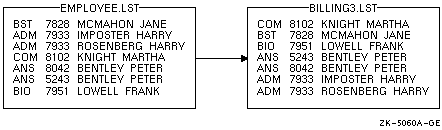
各レコードが(1)部門名,(2)アカウント番号, (3)カスタマ名の3つのフィールドから構成されるEMPLOYEE.LST ファイルを例として考えてみます。図 11-2 にこの3つのフィールドを示します。

次に,EMPLOYEE.LSTのレコードをソートする例を示します。
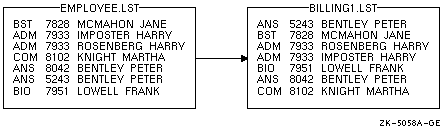
$ SORT/KEY=(POSITION:5,SIZE:4,DECIMAL) EMPLOYEE.LST BILLING1.LST
このコマンドは,キー・フィールド(アカウント番号)が位置5から始まること, 長さが4文字であること,10進データが格納されていること, 昇順(省略時の設定)でソートすることを指定しています。ソート結果を 図 11-3に示します。
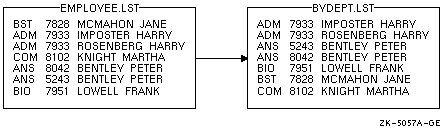
$ SORT EMPLOYEE.LST BYDEPT.LST
キーを指定していないので省略時の特性が使用されます。ソートの結果を 図 11-4に示します。
Sortは,EMPLOYEE.LSTの中のそれぞれレコードを1つの文字データ・ キーとして使用します。この例では,各レコードは,部門名,アカウント番号, カスタマ名で構成されています。重複する部門名がある場合, それらの部門名をアカウント番号の昇順にソートします。さらにアカウント番号もいくつか重複していた場合は, カスタマ名のアルファベット順にソートします。 ここでアカウント番号はレコードの一部であることに注意してください。 特に指定しない限り,アカウント番号は文字データとして処理されます。
2つ以上のキー(255キーが上限)でソートを行うことができます。この場合には, 複数のキーを優先順位順に指定します。すなわち,最初に1次キーを, 次に2次キーを指定し,以下も同様になります。また別の方法として,NUMBER: nを使用して,キーの優先順位を指定する方法もあります。 それぞれのキーは昇順でも降順でもかまいません。
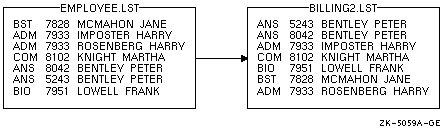
たとえば,次のコマンドは,EMPLOYEE.LSTを最初にカスタマ名をキーとしてソートし, 次に(同一名があれば)アカウント番号順にソートします。
$ SORT /KEY=(POSITION:10,SIZE:15,CHARACTER) -
_$ /KEY=(POSITION:5,SIZE:4,DECIMAL) EMPLOYEE.LST BILLING2.LST
ソート結果を図 11-5に示します。
それぞれのキーは昇順でも降順でもかまいません。たとえば,次のコマンドは, 最初にレコードを部門名別に降順にソートしてから,次にカスタマ名別に昇順にソートします。
$ SORT/KEY=(POSITION:1,SIZE:3,DESCENDING) -
_$ /KEY=(POSITION:10,SIZE:15) -
_$ EMPLOYEE.LST BILLING3.LST
ソート結果を図 11-6に示します。
省略時の設定では,Sort/Mergeは同一キー・フィールドでレコードを保持しますが, それらのレコードを,入力ファイル中で現れた順序と同じ順序で保持するとは限りません。 このようなレコードが存在すると思われる場合には, 次の修飾子のいずれかを使用してその扱い方を指定することができます。
同じキーを持つレコードを入力順序で残す。複数の入力ファイルをソートするときにこの修飾子を使用すると, 同じキーを持つレコードが最初のファイルにあれば,2 番目のファイルの前に並べられることになる。2 番目以降についても同様の方法で処理される。
1つを残し,他の重複レコードをすべて排除する。そのまま残す重複レコードを指定する場合, プログラム・レベルでSortを起動し,同一キー・ ルーチンを指定する。
/STABLE修飾子と/NODUPLICATES修飾子は互換性がないため,同一コマンド行で両方の修飾子を指定することはできません。
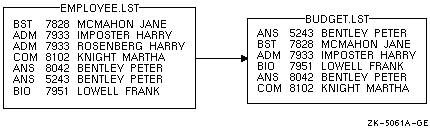
次の例では,アカウント番号が重複するレコードは,ファイルEMPLOYEE.LST から削除されます。
$ SORT /KEY=(POSITION:5,SIZE:4)/NODUPLICATES EMPLOYEE.LST BUDGET.LST
図 11-7はこのソート操作の結果を示しています。
文字データ以外の項目を含むレコードをソートする場合は,それぞれのキーでデータ型を指定します。 また,比較する項目が2バイト以上占有することもあるため, 開始位置とサイズを注意深く計算するようにします。
20個の文字の後に,F_floating形式の浮動小数を3つ含むファイルをソートする場合, 位置は次のようになります。
3番目の浮動小数でファイルをソートするときは,キー・フィールドを次のように指定します。
$ SORT/KEY=(POSITION:29,F_FLOATING) STATS.RAW STATS.SOR
浮動小数のサイズは4バイトに固定されているため,サイズを指定する必要はありません。
省略時の設定では,Sortは,最初の入力ファイルと同じファイル編成の出力ファイルを生成します。 入力ファイルと異なる出力ファイル編成を指定するときは,Sort のコマンド行で出力ファイルを指定した後に次のいずれかの修飾子を指定します。
この出力修飾子を使用すると,ファイル・レコードの形式,長さ,ブロック・ サイズを定義できます。
この修飾子を使用すると,出力を索引順編成ファイル編成に定義できます。 出力ファイル編成として索引順編成を指定する場合は, 次の操作も行わなければなりません。
この修飾子を使用すると,出力を相対ファイル編成に定義できます。
この修飾子を使用すると,出力を順ファイル編成に定義できます。
次の例では,索引付き順編成ファイルEMPLOYEE.LSTをソートした後,順編成ファイルが作成されます。
$ SORT/KEY=(POSITION:10,SIZE:15) -
_$ EMPLOYEE.LST BYNAME.LST/SEQUENTIAL
Sortは,レコード,タグ,アドレス,索引などの内部プロセスを1つ使用して, ファイルの整列を行います。(高性能Sort/Mergeユーティリティでは, レコード・プロセスのみがサポートされます。タグ,アドレス,索引の各プロセスについては,OpenVMS Alpha の将来のリリースでサポートされる予定です。) 指定するプロセスによっては,Sort操作の効率が変わることもあります。Sort 操作,Merge操作の最適化については,第11.8節を参照してください。
次の表は,プロセスの4つのタイプを示しています。ソート・プロセスを指定するときは,/PROCESS= タイプ修飾子を使用します。
| ソート・プロセス | タイプ | 説明 |
|---|---|---|
| レコード | RECORD | ソートを行うときレコードを完全な状態のまま残し,完全なレコードで構成される出力ファイルを作成する。 レコードが省略時のソート・ プロセスになる。 |
| タグ | TAG | キー・フィールドのみをソートしてから,入力ファイルを読み込み直し,
完全なレコードの出力ファイルを作成する。実際の結果は,
完全なレコード・ソートの場合と同じになる。
タグ・ソートは通常,ソート時に作業ファイルの領域をあまり使用しないため, ディスク領域が少ない場合に使用するのに適している。ほとんどの場合, タグ・ソートは,レコード・ソートよりも処理速度が遅くなる。これは, 入力ファイルを読み込み直すときに余分の時間が必要になるためである。 |
| アドレス | ADDRESS | キー・フィールドのみをソートし,レコード・ファイル・
アドレス(RFA)の索引になる出力ファイルを,バイナリ形式で作成する。
アドレス・ソートは,レコード・ソートよりも高速であるが,レコード・ アドレスを入力ファイルのレコードと対応させるプログラムを記述する必要がある。 |
| 索引 | INDEX | キー・フィールドのみをソートし,キーとRFAの出力ファイルを(
バイナリ形式で)作成する。
アドレス・ソートの場合と同様に,索引ソートもレコード・ソートより高速であるが, レコード・アドレスを入力ファイルのレコードと対応させるプログラムを記述する必要がある。 |
文字は,照合順序の順番に従って,ソートされます。文字データを含むファイルの場合は,/COLLATING_SEQUENCE= sequence修飾子を使用して, 照合順序を指定します。次の表は,照合順序オプションについて説明しています。
| 照合順序 | 順序 | 説明 |
|---|---|---|
| ASCII | ASCII | 文字データの場合,省略時の照合順序になる。 ASCII順序では,数字(0〜9),大文字(A〜Z),小文字(a〜z)の順番になる。 |
| EBCDIC | EBCDIC | EBCDIC順序で並べられた出力ファイルを生成する。データはASCII 表現のままになる。EBCDIC順序では,小文字(a〜z),大文字(A 〜Z),数字(0〜9)の順番になる。 |
| DECで定義している文字セット | MULTINATIONAL | MULTINATIONAL照合順序では,DECで定義している文字セットに従って文字を整列させる(
付録 Bを参照)。
MULTINATIONALの文字順序では,文字は次の規則で並べられる。
|
| 国別文字セット(NCS) | 照合順序名 | 指定する照合順序は,NCSライブラリで定義されていなければならない。
詳細は,『OpenVMS National
Character Set Utility Manual』を参照。NCS照合順序は,`でサポートされており,
指定ファイルではサポートされていない。
(高性能Sort/Mergeユーティリティは,NCS照合順序をサポートしていない。 OpenVMS Alpha の将来のリリースでサポートされる予定である。) |
| ユーザ定義順序 | (順序文字列) | ユーザ定義照合順序を指定する。ユーザ定義照合順序は,
指定ファイルでのみサポートされており,コマンド行インタフェースではサポートされていない。
(高性能Sort/Mergeユーティリティは,ユーザ定義順序をサポートしていない。 OpenVMS Alpha の将来のリリースではサポートされる予定である。) |
| 単一文字または二重文字の文字列,あるいは単一の文字を複数集めた文字の集まりを指定することによって,
照合順序を定義する。二重文字は,
単一の文字を2つ集めて1文字のように扱う。たとえば,整列するときに"CH"
を"C"として扱うよう定義することができる。この文字列は括弧で囲んで指定する。
基数演算子%O,%D,%Xを使用して,それぞれ8進,10進,16進の値で,文字を表現することもできる。 照合順序を定義するとき,次の規則を守らなければならない。
次の文字列は,二重文字LLがLとMの間の単一文字として照合される照合順序を定義する。
("A"-"L","LL","M"-"Z")
|
次の例は,指定ファイルで使用するために,ユーザ定義照合順序を作成する方法を示しています。 指定ファイルについての詳細は,第11.7節を参照してください。
(/COLLATING_SEQUENCE=(SEQUENCE=ASCII,IGNORE=("-"," "))
このように,/COLLATING_SEQUENCE修飾子にIGNOREオプションを指定した場合, 次のフィールドが比較されるとき同じものとして扱われ,タイブレークになります。
252-3412
252 3412
2523412
/COLLATING_SEQUENCE=(SEQUENCE=("A"-"L","LL","M"-"R","RR","S"-"Z"))
この/COLLATING_SEQUENCE修飾子は,二重文字LLがLとMの間の単一文字として照合され, 二重文字RRがRとSの間の単一文字として照合される順序を定義します。 このような定義がなければ,これらの二重文字は, 通常のアルファベット順と同様になります。省略時の場合,このユーザ定義順序によって, 小文字のaからzのような,他の文字が定義されることはありません。
バッチ・ジョブとは,現在のセッションとは独立して実行するプログラムや DCL コマンド・プロシージャのことです。大きなファイルをソートする場合には, ソート操作を終了するまでに時間がかかるので,ソート操作をバッチ・ ジョブとして登録することを検討してみてください。 バッチ・ジョブは,現在のセッションとは独立してバッチ・ジョブとコマンド・ プロシージャについての詳細は,第18 章,第15章,および第16章を参照してください。
コマンドを画面に記述するのと同様の方法で,コマンド・プロシージャにSORT コマンドを指定します。省略時のディレクトリにソートするファイルがない場合は, コマンド・プロシージャで省略時のディレクトリを明示的に設定するか, コマンド・ファイル指定にディレクトリを入れるようにします。
次の例では,DCLコマンド・プロシージャSORTJOB.COMをバッチ・ジョブとして登録しています。 コマンド・プロシージャのテキストをコマンド行の後に示します。
$ SUBMIT SORTJOB
! SORTJOB.COM
!
$ SET DEFAULT [USER.PER] ! Set default to location of input files
$ SORT/KEY=(POSITION:10,SIZE:15) EMPLOYEE.LST BYNAME.LST
$ TYPE BYNAME.LST
$ EXIT
バッチ・ジョブには,入力レコードを含めておくことができます。これには,SORT コマンドの後に入力レコードを1行に1つずつ指定します。ただし, 個々のソート・レコードは2行以上になってもかまいません。
レコードをターミナルから入力する場合と同様に,入力ファイル・パラメータにはSYS$INPUT を指定します。その後に/FORMAT修飾子を使用して,レコード・ サイズ(バイト数)とおおよそのファイル・サイズ(ブロック数)を指定します。80 文字の行が6行で1ブロックとほぼ等しくなります。
次の例は,入力レコードを含めたコマンド・プロシージャを示しています。
$ SUBMIT SORTJOB
! SORTJOB.COM
!
$ SET DEFAULT [USER.PER]
$ SORT/KEY=(POSITION:10,SIZE:15) -
SYS$INPUT-
/FORMAT=(RECORD_SIZE:24,FILE_SIZE:10) -
BYNAME.LST
$ DECK
BST 7828 MCMAHON JANE
ADM 7933 ROSENBERG HARRY
COM 8102 KNIGHT MARTHA
ANS 8042 BENTLEY PETER
BIO 7951 LOWELL FRANK
$ EOD
MERGEコマンドは,最大で10個(高性能Sort/Mergeユーティリティの場合は, 最高で12個)のソート済みのファイルをまとめて,レコードが順に並べられた1 つの出力ファイルを作成します。マージする入力ファイルは, 同じ形式を持ち,同じキー・フィールドに基づいてソートされていなければなりません。
省略時の設定では,Mergeは,入力ファイルの中のレコードをチェックして, 正しい順序で並べられているかどうかを確認します。Mergeで順序をチェックするときは,/CHECK_SEQUENCE 修飾子を指定します。この修飾子を指定しているにもかかわらず, レコードが正しく並んでいない場合(たとえばソートされていない入力ファイルがある場合) ,次のエラーが報告されます。
%SORT-W-BAD_ORDER, merge input is out of order
MERGEコマンドとSORTコマンドは,同じ修飾子を使用できます。ただし, 次の2つの例外があります。
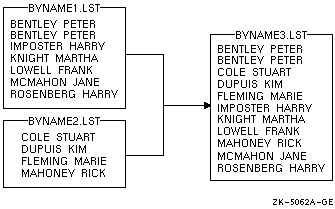
次の例では,ファイルBYNAME1.LSTとBYNAME2.LSTは,顧客名によってすでに昇順にソートされています。 ここに示したコマンドは,これらをマージします。
$ MERGE BYNAME1.LST,BYNAME2.LST BYNAME3.LST
出力ファイルBYNAME3.LSTには,次の図に示すように,BYNAME1.LSTとBYNAME2.LST
の両方のファイルのすべてのレコードが含まれます。
特定のキーを使用してソートしたファイルをマージする場合は,MERGEコマンド行の/KEY 修飾子で同じキーを指定する必要があります。
キーを指定しない場合は,Mergeは第11.2 節で説明している省略時設定のキーを使用します。
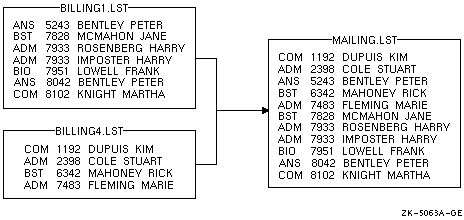
たとえば,ファイルBILLING1.LSTとBILLING4.LSTがアカウント番号によってソート済み(/KEY=POSITION:5,SIZE:4,DECIMAL) であるとします。この2 つのファイルを出力ファイルMAILING.LSTにマージするには,次のコマンド行を入力します。
$ MERGE/KEY=(POSITION:5,SIZE:4,DECIMAL) -
_$ BILLING1.LST,BILLING4.LST MAILING.LST
マージ結果は次のとおりです。
マージしたいファイルがソート順になっていることを知っている場合は,/NOCHECK_SEQUENCE 修飾子を指定することにより,順序チェックを省略することができます。
ソート操作の場合と同様に,入力ファイルに同じキー・フィールドを持つレコードが2 つ以上ある場合,レコード順序が入力ファイルと同じになるとはかぎりません。 同じキーを持つレコードの入力順序をそのまま残すには,MERGE コマンド行に/STABLE修飾子を指定します。同じキーを持つレコードのうち1 つだけを残すには,/NODUPLICATES修飾子を指定します。
ソートまたはマージしようとするレコードは,ファイルに格納されている必要はありません。SORT またはMERGEコマンドを入力するときに,ターミナルからレコードを直接入力することができます。 次の表に,その手順を示します。
| 手順 | 操作 |
|---|---|
| 1 | SORTまたはMERGEコマンド行で,入力ファイルとしてSYS$INPUT
を指定する。
入力ファイル修飾子/FORMATを使用して,最も長いレコードのサイズ(バイト数) とそれに対応する入力ファイルのサイズ(ブロック数)を指定する。 |
| 2 | 後続の行にレコードを入力する。
Returnを押して各レコードを終了させる。 |
| 3 | Ctrl/Zを押してファイルを終了させる。 |
次の例は,ソートしようとする入力レコードを,ターミナルから直接に入力する場合のソート操作を示しています。
$ SORT/KEY=(POSITION:8,SIZE:15) -
_$ SYS$INPUT/FORMAT=(RECORD_SIZE:24,FILE_SIZE:10) BYNAME.LST
BST 7828 MCMAHON JANE <Return>
ADM 7933 ROSENBERG HARRY<Return>
COM 8102 KNIGHT MARTHA<Return>
ANS 8042 BENTLEY PETER<Return>
BIO 7951 LOWELL FRANK<Return>
<Ctrl/Z>
このコマンド・シーケンスは,レコードをソートし,その結果をBYNAME.LST という名前のファイルに格納します。
Sort/Mergeでは,指定ファイルを使用してソート定義を格納しておき, 必要があればさらに複雑なソート条件を指定することができます。( 高性能Sort/Mergeユーティリティでは,指定ファイルはサポートされていません。 この機能は,OpenVMS Alphaの将来のリリースでサポートされる予定です。) 指定ファイルを作成するときは,任意の標準エディタやDCL のCREATEコマンドが使用できます。
Sort/Merge指定ファイルを使用すると,次の操作を行えます。
指定ファイルを作成したら, /SPECIFICATION修飾子を使用してファイル名を指定します。 指定ファイルの省略時のファイル・タイプは.SRTです。
指定ファイル内では,各コマンドの先頭にスラッシュ(/)を付けます。コマンドが2 行以上にわたる場合でも,行継続文字は必要ありません。
コマンド行で指定するDCLコマンド修飾子は,指定ファイルの中の対応する項目を無効にします。 たとえば,DCLコマンド行で/KEY修飾子を指定しても,Sort/Merge は指定ファイルの中の/KEY修飾子を無視します。
一般に,指定ファイルの中の修飾子はどのような順序で指定してもかまいません。 ただし,次のような場合には,順序が重要になります。
/COLLATING_SEQUENCE修飾子と同時にFOLD,MODIFICATION,およびIGNORE キーワードを指定する場合には, MODIFICATION句とIGNORE句をすべて指定してからFOLD 句を指定します。/COLLATING_SEQUENCE修飾子についての詳細は, 第11.9.3項を参照してください。
指定ファイルの中にコメントを挿入するには,各コメント行の先頭に感嘆符(!) を付けます。DCLのコマンド行と異なり,指定ファイルは行を継続するときにハイフン(-) を必要としません。
例
! Specification file for sorting negative and positive data
! in ascending order
!
/FIELD=(NAME=SIGN,POS:1,SIZ:1) 【1】
/FIELD=(NAME=AMT,POS:2,SIZ:4) 【2】
/CONDITION=(NAME=CHECK1, 【3】
TEST=(SIGN EQ "-"))
/CONDITION=(NAME=CHECK2, 【4】
TEST=(SIGN EQ " "))
/INCLUDE=(CONDITION=CHECK1, 【5】
KEY=(AMT,DESCENDING),
DATA=SIGN,
DATA=AMT)
/INCLUDE=(CONDITION=CHECK2, 【6】
KEY=(AMT,ASCENDING),
DATA=SIGN,
DATA=AMT)
指定ファイルを確認する際には,次の点に注意してください。
図 11-8は,上の指定ファイルの例をBALANCES.LIS という入力ファイルに使用した結果を示しています。
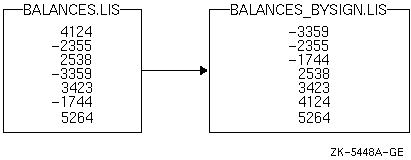
/FIELD=(NAME=RECORD_TYPE,POS:1,SIZ:1) ! Record type, 1-byte
/FIELD=(NAME=PRICE,POS:2,SIZ:8) ! Price, both files
/FIELD=(NAME=TAXES,POS:10,SIZ:5) ! Taxes, both files
/FIELD=(NAME=STYLE_A,POS:15,SIZ:10) ! Style, format A file
/FIELD=(NAME=STYLE_B,POS:20,SIZ:10) ! Style, format B file
/FIELD=(NAME=ZIP_A,POS:25,SIZ:5) ! Zip code, format A file
/FIELD=(NAME=ZIP_B,POS:15,SIZ:5) ! Zip code, format B file
/CONDITION=(NAME=FORMAT_A, ! Condition test, format A
TEST=(RECORD_TYPE EQ "A"))
/CONDITION=(NAME=FORMAT_B, ! Condition test, format B
TEST=(RECORD_TYPE EQ "B"))
/INCLUDE=(CONDITION=FORMAT_A, ! Output format, type A
KEY=ZIP_A,
DATA=PRICE,
DATA=TAXES,
DATA=STYLE_A,
DATA=ZIP_A)
/INCLUDE=(CONDITION=FORMAT_B, ! Output format, type B
KEY=ZIP_B,
DATA=PRICE,
DATA=TAXES,
DATA=STYLE_B,
DATA=ZIP_B)
この例では,不動産代理店の2つの支社から送られた2つの入力ファイルが, 指定ファイルの指示に従ってソートされます。1つ目のファイルのレコードは, 最初の位置にAがついており,次の形式になっています。
|A|PRICE|TAXES|STYLE|ZIP|
1 2 10 15 25
2つ目のファイルのレコードは,最初の位置にBがつき,styleフィールドとzip code フィールドが,次のように逆になっています。
|B|PRICE|TAXES|ZIP|STYLE|
1 2 10 15 20
これらの2つのファイルを,レコードAの形式のzip codeフィールドでソートするとき, 最初に両方のレコードのフィールドを,/FIELD修飾子で定義します。 その後,/CONDITION修飾子で,2つのタイプのレコードを区別するためのテストを指定します。 最後に/INCLUDE修飾子を指定して, タイプBのレコード形式をタイプAのレコード形式に変更して出力します。
/INCLUDE修飾子でキー・フィールドまたはデータ・フィールドのいずれかを指定する場合,/INCLUDE 修飾子のSort操作で明示的にすべてのキー・ フィールドとデータ・フィールドを指定する必要があります。
また,タイプAでもタイプBでもないレコードは,ソート時に排除されます。
/COLLATING_SEQUENCE=(SEQUENCE=
("AN","EB","AR","PR","AY","UN","UL",
"UG","EP","CT","OV","EC","0"-"9"),
MODIFICATION=("'"="19"),
FOLD)
この/COLLATING_SEQUENCE修飾子では,ユーザ定義順序を指定します。 この指定により,それぞれの月に,日付順の固有の値が定義されます。 たとえば,SEMINAR.DATというファイルを日付順に並べたい場合, SEMINAR.DATファイルは次のようになっています。
16 NOV 1983 Communication Skills
05 APR 1984 Coping with Alcoholism
11 Jan '84 How to Be Assertive
12 OCT 1983 Improving Productivity
15 MAR 1984 Living with Your Teenager
08 FEB 1984 Single Parenting
07 Dec '83 Stress --- Causes and Cures
14 SEP 1983 Time Management
一次キーがyearフィールドで,二次キーがmonthフィールドです。 monthフィールドは数値ではありませんが,日付順に並べたいため,独自の照合順序を定義する必要があります。 この場合,それぞれの月に固有のキー値を指定して, それぞれの月の2番目と3番目の文字を(日付順に) ソートすることにより,これを行います。
MODIFICATIONオプションでは,アポストロフィ(')が19と同等になるよう指定していますが, これによって,'83と1984が比較できるようになります。 またFOLDオプションは,大文字と小文字が同等に扱われるよう指定します。
このSort操作の出力は,次のようになります。
14 SEP 1983 Time Management
12 OCT 1983 Improving Productivity
16 NOV 1983 Communication Skills
07 Dec '83 Stress --- Causes and Cures
11 Jan '84 How to Be Assertive
08 FEB 1984 Single Parenting
15 MAR 1984 Living with Your Teenager
05 APR 1984 Coping with Alcoholism
ユーザ定義照合順序の他の例については,第11.3節を参照してください。
/FIELD=(NAME=AGENT,POSITION:20,SIZE:15)
/CONDITION=(NAME=AGENCY,
TEST=(AGENT EQ "Real-T Trust"
OR
AGENT EQ "Realty Trust"))
/DATA=(IF AGENCY THEN "Realty Trust" ELSE AGENT)
この例では,2つの不動産ファイルをソートします。1つのファイルは, ある代理店がReal-T Trustと呼ぶもので,もう1つのファイルはRealty Trust と呼ばれます。/CONDITION修飾子と/DATA修飾子により, Realty Trustのソート出力ファイルにAGENTフィールドがリストされることになります。
/FIELD=(NAME=ZIP,POSITION:60,SIZE:6)
/CONDITION=(NAME=LOCATION,
TEST=(ZIP EQ "01863"))
/KEY=(IF LOCATION THEN 1
ELSE 2)
この例では,郵便番号01863を持つすべてのレコードがソート出力ファイルの最初にリストされます。 条件テストは,/FIELD修飾子で定義されているようにZIP フィールドで行われます。条件名はLOCATIONになっています。/KEY 修飾子にある値1と2は,条件を満たすレコードと条件を満たさないレコードの相対順序を表すものです。
/FIELD=(NAME=ZIP,POSITION:60,SIZE:6)
/CONDITION=(NAME=LOCATION,
TEST=(ZIP EQ "01863"))
/DATA=(IF LOCATION THEN "NORTH CHELMSFORD"
ELSE "Outside district")
この例では,/CONDITION修飾子により,郵便番号01863についてテストが行われます。/DATA 修飾子は,テスト結果に従って,townフィールドの名前が出力レコードに追加されるよう指定します。
/FIELD=(NAME=FFLOAT,POS:1,SIZ:0,F_FLOATING)
/CONDITION=(NAME=CFFLOAT,TEST=(FFLOAT GE 100))
/OMIT=(CONDITION=CFFLOAT)
この例では,/FIELD修飾子でフィールドFFLOATがF_FLOATINGと定義されているため, 数値100がF_FLOATINGデータ型とみなされます。
/FIELD=(NAME=AGENT,POSITION:1,SIZE:5)
/FIELD=(NAME=ZIP,POSITION:6,SIZE:3)
/FIELD=(NAME=STYLE,POSITION:10,SIZE:5)
/FIELD=(NAME=CONDITION,POSITION:16,SIZE:9)
/FIELD=(NAME=PRICE,POSITION:26,SIZE:5)
/FIELD=(NAME=TAXES,POSITION:32,SIZE:5)
/DATA=PRICE
/DATA=" "
/DATA=TAXES
/DATA=" "
/DATA=STYLE
/DATA=" "
/DATA=ZIP
/DATA=" "
/DATA=AGENT
この/FIELD修飾子は,次の形式を持つ入力ファイルのレコードのフィールドを定義します。
AGENT ZIP STYLE CONDITION PRICE TAXES
/DATA修飾子では,/FIELD修飾子で定義されているフィールド名を使用しますが, レコードを再フォーマットして,次の形式の出力レコードを作成します。
PRICE TAXES STYLE ZIP AGENT
ソート操作またはマージ操作の効率は,ソート環境により,いくつかの方法で向上させることができます。SORT コマンドまたはMERGEコマンドに/STATISTICS 修飾子を使用すると,ソート環境の変数を表示できます。
この統計情報を調べてから,この後に説明する最適化オプションの使用を検討してみてください。
SORTコマンドまたはMERGEコマンドに/STATISTICS修飾子を指定すると,次のような出力が表示されます。
$ SORT/STATISTICS PAGEANT.LIS DOCUMENT.LIS
OpenVMS Sort/Merge Statistics
Records read: 3 【1】 Input record length: 26
Records sorted: 3 Internal length: 28
Records output: 3 Output record length: 26
Working set extent: 16384 【2】 Sort tree size: 42
Virtual memory: 392 Number of initial runs: 0
Direct I/O: 10 Maximum merge order: 0
Buffered I/O: 11 Number of merge passes: 0
Page faults: 158 【3】 Work file allocation: 0 【4】
Elapsed time: 00:00:00.54 Elapsed CPU: 00:00:00.03 【5】
この統計表示から次のことが分かります。
ソート操作中に読み込まれたレコードの数を示す。ソート操作で特定のレコードを省略する方法についての詳細は, 第11.8.2項を参照。
ソート操作を実行するために確保されたブロックの数を示す。 ワーキング・セットを大きくする方法についての詳細は,第11.8.4項を参照。
オペレーティング・システムが,物理メモリからページング・デバイスへプロセスを転送した回数を示す。 ページングをしないようにする方法についての詳細は, 第11.8.4項を参照。
作業ファイルのために確保されたディスク領域のサイズを示す。作業ファイルについての詳細は, 第11.8.3 項を参照。
オペレーティング・システムがソート操作の処理に費やしたCPU時間を示す。 別のソート方法を選択して時間を節約する方法についての詳細は,第11.8.1項を参照。
Sortでは,内部でデータをソートするときに使用する,レコード,タグ, アドレス,索引の4つのプロセスを定義します。(高性能Sort/Mergeユーティリティでは, レコード・プロセスのみがサポートされます。タグ,アドレス, 索引の各プロセスについては,OpenVMS Alphaの将来のリリースでサポートされる予定です。) RECORD が省略時のプロセスになります。指定するプロセスのタイプによっては, 必要な記憶域の量と同様に,Sort操作の効率も変わることがあります。 その他のソート・プロセスについての詳細は, 第11.2.6項を参照してください。
どのタイプのソート方法を使用するかは,次の点を考慮して決定してください。
あるファイルのレコードを様々な目的で並べ換える必要がある場合には, アドレス・ソートまたは索引順編成ソートによって生成された複数の出力ファイルを格納する。 望ましい順序で並べられたメイン・ファイルの中のレコードにアクセスするには, この出力ファイルを使用する。
タグ・ソートは,レコード・ソートに比べて,使用する一時格納領域が少なくてすむ。 レコード・ソートは,ソート中はレコードに手を加えないので, ファイルが大きい場合には使用する作業領域が多くなる。 アドレス・ソートと索引順編成ソートは,一時格納領域をほとんど使用しない。
カード,磁気テープ,ディスクから入力を受け付けるプロセスは,レコード・ ソートだけである。タグ・ソートとレコード・ソートの結果はどの出力デバイスにも出力できるが, アドレス・ソートと索引順編成ソートの結果は, バイナリ・データを受け付けるデバイスに出力しなければならない。
ソートしたレコードを操作の最中に検索する予定がある場合,通常, レコード・ソートが最も処理速度が速くなる。それ以外の場合には, アドレス・ソートと索引順編成ソートの処理速度が速くなる。
Sortの効率は,指定ファイルを使用して高めることもできます。 /CONDITION,/INCLUDE,/OMIT修飾子を使用すると,必要なレコードだけを選択して出力ファイルに格納できます。( 高性能Sort/Mergeユーティリティでは, 指定ファイルはサポートされていません。この機能は, OpenVMS Alphaの将来のリリースでサポートされる予定です。)また,指定ファイル修飾子を使用すれば, レコードのフォーマットを変更して,不必要なフィールドを出力ファイルに出さないようにすることもできます。 これらの修飾子は, コマンド行修飾子として使用することはできません。
ソート中,入力ファイルのレコードはメモリに読み込まれています。Sort では,割り当てられたメモリにすべてのレコードを収めることができない場合は, ソート済みのデータが,1つまたは複数の一時的作業ファイルに転送されます。Merge の場合は,作業ファイルが使用されません。
作業ファイルの数を変更し,それらのファイルを特定のデバイスに割り当てることにより, ソートの効率を向上させることができます。
作業ファイルに対応するユーザ指定デバイス名を識別するときは, SORTWORKn論理名が使用される。この場合nは0 から9までのいずれかの値になる。(高性能Sort/Mergeユーティリティでは, nは0から254までのいずれかの値になる)。 SORTWORKn論理名を次のように定義する。
ASSIGNデバイス: SORTWORKn
例
$ ASSIGN WORK$2: SORTWORK1
$ ASSIGN WORK$3: SORTWORK2
この例では,SORTWORK1がデバイスWORK$2:として定義され, SORTWORK2がデバイスWORK$3:として定義される。論理名についての詳細は, 第13章を参照。
作業ファイルをデバイスに割り当てるとき,次の事項に注意します。
Sortが作業ファイルを必要とする場合(たとえば,大きなファイルをソートする場合) には,ワーキング・セットを大きくすると,ソート効率が向上します。 ただし,システムの負荷が大き過ぎると,ワーキング・セット拡張領域の全ページをプロセスに割り当てられないこともあります。 このような場合, オペレーティング・システムが物理メモリとページング・デバイス上のメモリの間でプロセスの一部を転送するときに, ページングが起こることがあります。 そのため,プロセスのアクティブな部分だけが物理メモリ内に残ります。 過度なページングの発生を避けるためには,プロセスのワーキング・ セット拡張領域を小さくします。ワーキング・セット拡張領域を小さくするときは,SET WORKING_SET コマンドを使用します。
ここでは,SORTコマンドとMERGEコマンドで使用されるコマンド修飾子について説明します。 コマンド修飾子を使用するには,SORTまたはMERGEコマンドのすぐ後に修飾子を指定します。
/[NO]CHECK_SEQUENCE
また/CHECK_SEQUENCE修飾子を使用すると,1つまたは複数(最高で10ファイル, 高性能Sort/Mergeユーティリティの場合は12ファイルまでサポート) のファイルのレコードがソートされているかどうかチェックすることができる。 この場合もレコードは出力ファイルに送られるが, そのファイルは指定する必要がある。レコードが,レコード全体以外のキー・ フィールドでソートされているかどうかチェックする場合, 順序の他に,キー情報も指定する必要がある。
マージ操作で,レコードの順序をチェックしないようにするには, /NOCHECK_SEQUENCE修飾子を使用する。
例
$ MERGE/KEY=(SIZE:4,POSITION:3)/NOCHECK_SEQUENCE -
_$ PRICE1.DAT,PRICE2.DAT PRICE.LIS
/NOCHECK_SEQUENCE修飾子により,入力ファイルPRICE1.DATおよびPRICE2.DAT の順序についてはチェックする必要のないことが指定されている。
/COLLATING_SEQUENCE=sequence
例
$ SORT/COLLATING_SEQUENCE=MULTINATIONAL -
_$ NAMES.DAT,NOM.DAT LIST.LIS
このSORTコマンドでは,MULTINATIONAL照合順序で入力ファイルNAMES.DAT およびNOM.DATが整列され,出力ファイルLIST.LISが作成される。
/[NO]DUPLICATES
/STABLE修飾子と/NODUPLICATES修飾子は,相互に排他的な関係にある。
例
$ SORT/KEY=(POSITION:3,SIZE:5,DECIMAL)/NODUPLICATES -
_$ ACCT1,ACCT2 ACCT.LIS
このSORTコマンドにより,指定されたキーに従って,2つの入力ファイルが整列され, 同一のキーを持つ複数レコードは,1つのレコードを除いてすべて消去される。
/KEY=(POSITION:n,SIZE:n[,field,...])
/KEY修飾子についての詳細は,第11.2.1 項を参照。
/PROCESS=type
/PROCESS修飾子についての詳細は,第11.2.6 項を参照。
例
$ SORT/KEY=(POS:40,SIZ:2,DESC)/PROCESS=TAG YRENDAVG.DAT -
_$ DESCYRAVG.LIS
このSort操作では,タグ・ソート・プロセスが使用され,出力ファイルDESCYRAVG.LIS が作成される。
/SPECIFICATION=filespec
(高性能Sort/Mergeユーティリティでは,この修飾子はサポートされていない。 この機能は,OpenVMS Alphaの将来のリリースでサポートされる予定。)
/[NO]STABLE
/STABLE修飾子と/NODUPLICATES修飾子は,相互に排他的な関係にある。
例
$ SORT/KEY=(POS:1,SIZ:5,DECIMAL)/STABLE PRICESA.DAT, -
_$ PRICESB.DAT,PRICESC.DAT SUMMARY.LIS
このSort操作では,同一のキーを持つレコードは,PRICESA.DATにあるものが最初にリストされ, その後PRICESB.DATのレコード,さらにPRICESC.DAT のレコードがリストされる。
/[NO]STATISTICS
$ DEFINE/USER SYS$ERROR output-file
統計情報の要約には,次の情報が含まれる。
| 統計情報 | 説明 |
|---|---|
| Records read | Sort操作またはMerge操作によって読み込まれたレコードの数。 |
| Records sorted | Sortを使用したときに処理されたレコードの数。Sort 操作またはMerge操作で,指定ファイルを使用して特定のレコードのみを選択した場合, この数値が,読み込まれたレコードの数より少なくなることもある。 |
| Records output | 出力ファイルに書き込まれたレコードの数。/NODUPLICATES が選択された場合や,出力レコードが書き込まれたときに入出力エラーが発生した場合, この数値が,ソートされたレコードの数より少なくなることもある。 |
| Working set extent | プロセスのワーキング・ セット拡張領域のページの数。この値は,ソート・データ構造体のサイズの上限に使用される。 この値を調節することにより, Sort操作の効率を向上させることができる。 |
| Virtual memory | データを保持するソート・イメージに追加される仮想記憶のページ数。 |
| Direct I/O + buffered I/O | この合計値は,データの読み込みおよび書き込みに必要な入出力移動の数になる。 この合計値を小さくするほど, 整列操作の効率は向上する。 |
| Page faults | データがメモリに収まる度合いを示す値。 この値が大きいほど,整列操作の効率は低下する。 |
| Elapsed time | Sort操作またはMerge操作で使用される,時間,分,秒,1/100秒単位の合計クロック時間。 |
| Input record length | この値は,ユーザが指定しない場合レコード管理サービス(OpenVMS RMS) から取得される。 |
| Internal length | 内部フォーマット・ノードの, バイト単位のサイズ。これには,キー,データ,長さを保管するワード, 長さ,レコード・ファイル・アドレス(RFA),変換されたキーなどが含まれる。 |
| Output record length | 出力レコードの長さ。この長さは入力レコードの長さ, ソート・プロセス,必要なレコードの再フォーマットにより計算される。 |
| Sort tree size | Sortの内部データ構造体に収まるレコードの数。 |
| Number of initial runs | データがメモリに収まる程度を示す1 つの指針。 |
| Maximum merge order | 同時にマージされるソート文字列の最大数。 |
| Number of merge passes | ソートされた出力文字列が作成されるまで, Sortユーティリティが文字列をマージする回数。Number of initial runsとNumber of merge passesにより,データがメモリに収まる程度が示される。 これらの値が大きいほど,ワーキング・セットのサイズにデータが収まらなくなり, 同時にソートに時間がかかるようになる。 |
| Work file allocation | 作業ファイルに使用されるブロックの数。マージ・パスが複数必要な場合, このサイズは,入力ファイル割り当てのサイズの約2倍になる。 |
| Elapsed CPU | 整列操作で使用されるCPU 時間。入出力オペレーションが終了するのを待つ時間や, 別のプロセスが動作しているときにそれを待っている時間などは含まれない。 |
例
$ SORT/STATISTICS PRICE1.DAT,PRICE2.DAT PRICE.LIS
SORT /STATISTICSコマンドを使用すると,次のような統計情報が表示される。
OpenVMS Sort/Merge Statistics
Records read: 793 Input record length: 80
Records sorted: 793 Internal length: 80
Records output: 793 Output record length: 80
Working set extent: 100 Sort tree size: 412
Virtual memory: 433 Number of initial runs: 2
Direct I/O: 22 Maximum merge order: 2
Buffered I/O: 9 Number of merge passes: 1
Page faults: 3418 Work file allocation: 114
Elapsed time: 00:00:05.98 Elapsed CPU: 00:00:03.63
/WORK_FILES[=n]
作業ファイルは,必要にならない限り作成されない。作業ファイルが必要になった場合は, 省略時の設定として,2つのファイル(SORTWORK0 ,SORTWORK1)が作成され,SYS$SCRATCHディレクトリに置かれる。
例
$ ASSIGN DRA5: SORTWORK0
$ ASSIGN DB0: SORTWORK1
$ ASSIGN DB1: SORTWORK2
$ SORT/KEY=(POS:1,SIZ:80)/WORK_FILES=3 -
_$ STATS1,STATS2,STATS3,STATS4 SUMMARY.LIS
このSort操作では,入力ファイルが大きなファイルであるため,作業ファイルを3 つ指定することにより,ソート操作の効率を向上させることができる。
ディレクトリ名を中に含めることにより,作業ファイルをデバイス上の特定のディレクトリに割り当てることもできる。 たとえば, SORTWORK0をDRA5の[WORKSPACE]ディレクトリに割り当てるとき,次のコマンドを入力する。
$ ASSIGN DRA5:[WORKSPACE] SORTWORK0
次の入力修飾子は,SORTまたはMERGEコマンド行に入力ファイル指定を指定した直後に指定しなければなりません。
/FORMAT=(RECORD_SIZE:n,FILE_SIZE:n)
Sortでは,必要なメモリ量を判断するとき,Sort操作に使用する作業ファイルのサイズの他に, 入力ファイル・サイズの情報が使用される。 このファイル・サイズが未知の場合(たとえばディスクや標準ANSI 磁気テープ上にないファイルをソートしている場合),非常に大きなファイル・ サイズが想定される。
次の修飾子の値を指定することができる。
| RECORD_SIZE:n | 入力ファイルの最長レコード長(LRL)
をバイト単位で指定する。指定できる最長のレコード長は,
ファイル編成により異なる。
| ||||||
| これらの値には,固定長制御付き可変(VFC)形式レコードの制御バイトが含まれる。 | |||||||
| FILE_ SIZE:n | 入力ファイル・サイズをブロック単位で指定する。 指定できる最大ファイル・サイズは,4,294,967,295ブロックになる。 |
出力ファイルの修飾子としても/FORMATを使用することができる。詳細は 第11.9.2項を参照。
例
$ SORT/KEY=(POS:40,SIZ:2,DESC) -
_$CRA0:YRENDAVG.DAT/FORMAT=(RECORD_SIZE:41,FILE_SIZE:3) -
_$DESCYRAVG.LIS
入力ファイルYRENDAVG.DATは,ディスク・デバイス上にもANSI磁気テープ上にもないため, ファイル編成を/FORMAT修飾子で記述する必要がある。
次の出力修飾子は,SORTおよびMERGEコマンドに対して使用できます。出力ファイル修飾子を使用するには,SORT またはMERGEコマンド行の出力ファイル指定の直後に指定します。
/ALLOCATION=n
/CONTIGUOUS修飾子が使用されている場合,/ALLOCATION修飾子が必要になる。
例
$ SORT/KEY=(POS:1,SIZ:80) STATS.DAT -
_$ SUMMARY.LIS/ALLOCATION=1000/CONTIGUOUS
このSORTコマンドにより,出力ファイルSUMMARY.LISに1000の連続ブロックが割り当てられる。
/BUCKET_SIZE=n
出力ファイルの編成が入力ファイルと同じ場合,省略時の値は,最初の入力ファイルのバケット・ サイズと同じ値になる。出力ファイルの編成が異なる場合, 省略時の値は1になる。
例
$ SORT/KEY=(POS:1,SIZ:80) STATS1.DAT,STATS2.DAT -
_$ SUMMARY.LIS/BUCKET_SIZE=16/RELATIVE
このSORTコマンドにより,バケット・サイズが16の出力ファイルSUMMARY.LIS が,相対編成で作成される。
/CONTIGUOUS
例
$ SORT/KEY=(POS:1,SIZ:80) STATS.DAT -
_$ SUMMARY.LIS/ALLOCATION=1000/CONTIGUOUS
このSORTコマンドにより,出力ファイルSUMMARY.LISに1,000の連続ブロックを割り当てる。
/FORMAT=(type:n[,...])
Sort操作がレコード・ソートまたはタグ・ソートの場合,省略時の出力レコードの形式は, 最初の入力ファイル・レコードの形式と同じになる。Sort 操作がアドレス・ソートまたは索引ソートの場合,省略時の出力レコードの形式は, 固定レコード形式になる。入力ファイルにさまざまなレコード形式がある場合, 出力レコード・サイズは,入力ファイルにある最大のレコードを収められるだけの大きさになる。
次の修飾子の値を指定することができる。
| BLOCK_SIZE:n | ファイルを磁気テープに出力する場合, 出力ファイルのブロック・サイズをバイト単位で指定する。 入力ファイルがテープ・ファイルの場合,出力ファイルのブロック・ サイズは,省略時の設定で入力ファイルと同じサイズになる。 それ以外の場合,出力ファイルのブロック・サイズは, 省略時の設定でテープがマウントされたときに使用されるサイズになる。 |
| nの値は,20 から65,532のいずれかになる。ただし,他のコンパックのシステムとデータ交換を正しく行えるようにするためには,512 バイト以上のブロック・ サイズは指定できない。またコンパック製以外のシステムと互換性を保つためには, そのブロック・サイズに, 2,048バイト以下の値を指定するようにする。 | |
| CONTROLLED:n | 出力ファイルに, 固定長制御付き可変(VFC)レコードを指定する。 |
| FIXED:n | 出力ファイルに固定長レコードを指定する。 |
| SIZE:n | VFC (CONTROLLED)レコードの固定部分のサイズを,255 バイト以下のバイト数で指定する。 SIZEを指定していない場合,省略時の値として,最初の入力ファイルの固定部分のサイズになる。 サイズに0を指定した場合,OpenVMSRMS は,省略時の値として,2バイトになる。 |
| VARIABLE:n | 出力ファイルに可変長レコードを指定する。 |
オプションとして,上記の修飾子の値に,出力レコードの最大レコード・ サイズnを(バイト単位で)指定することができる。指定できる最大レコード・ サイズは,ファイル編成によって異なる。
| 順次ファイル | 32,767 |
| 相対ファイル | 16,383 |
| 索引順次ファイル | 16,362 |
これらの最大レコード・サイズの値には,固定長制御付き可変(VFC)形式レコードの制御バイトが含まれる。
例
$ SORT/KEY=(POS:1,SIZ:80) STATS.DAT SUMMARY.LIS/FORMAT=FIXED:80
入力ファイルSTATS.DATは,長さ80バイトの可変長のレコードで構成される。/FORMAT 修飾子には,固定長レコードで構成される出力ファイルSUMMARY.LIS を指定する。
/INDEXED_SEQUENTIAL
例
$ CREATE/FDL=NEW.FDL AVERAGE.DAT
$ SORT/KEY=(POS:1,SIZ:80) DATA.DAT,STATS.DAT -
_$ AVERAGE.DAT/INDEXED_SEQUENTIAL/OVERLAY
CREATE/FDLコマンドを使用することにより,空のファイルAVERAGE.DAT が作成される。SORTコマンドは,出力ファイルが索引順次編成になり, 空のファイルAVERAGE.DATに書き出されることを指定する。
/OVERLAY
入力ファイル編成が索引順次になっている場合,出力ファイルがすでに存在しており, 空になっている必要がある。出力ファイルが空でない場合も,/OVERLAY により,そのファイルが上書きされることはない。 その代わり,ソートの結果が既存の出力ファイルに追加される。
CREATE/FDLユーティリティを使用すると,空のデータ・ファイルを作成することができる。 空のファイルを作成するときに指定する属性は, その後Sortの出力ファイルの属性になる。
例
$ CREATE/FDL=NEW.FDL AVERAGE.DAT
$ SORT/KEY=(POS:1,SIZ:80) STATS.DAT AVERAGE.DAT/OVERLAY
FDLファイルNEW.FDLは,ファイルAVERAGE.DATに対して特殊な属性を指定する。 そのファイルに出力が書き込まれるとき,Sortの出力ファイルは,FDL ファイルによって指定された属性になる。
/RELATIVE
例
$ SORT/KEY=(POS:1,SIZ:80) STATS.DAT SUMMARY.LIS/RELATIVE
入力ファイルSTATS.DATが相対ファイルでなく,出力ファイルSUMMARY.LIS が相対ファイルになるため,/RELATIVEで,出力ファイル指定を修飾する。
/SEQUENTIAL
例
$ SORT/KEY=(POS:1,SIZ:80) STATS.DAT SUMMARY.LIS/SEQUENTIAL
入力ファイルSTATS.DATが順次ファイルでなく,出力ファイルSUMMARY.LIS が順次ファイルになるため,/SEQUENTIALで,出力ファイル指定を修飾する。
次の修飾子は指定ファイルの中で使用されます。(高性能Sort/Mergeユーティリティでは, 指定ファイルはサポートされていません。この機能は, OpenVMS Alphaの将来のリリースでサポートされる予定です。)これらの修飾子はSort/Merge 指定ファイルの中でのみ有効であることに注意してください。
/CDD_PATH_NAME="cdd-path-name"
/CDD_PATH_NAMEは,/FIELD文の代わりに使用したり,/FIELD文と一緒に使用したりすることができる。
"cdd-path-name"の値は,CDD/Plus内のCDD/Plusレコード定義になる。/CDD_PATH_NAME 修飾子は,システムにCDD/Plusがインストールされている場合のみ使用できる。
例
/CDD_PATH_NAME="customer"
/CDD_PATH_NAME修飾子は,前にCDD/Plusで定義されているcustomerレコードを識別する。
/[NO]CHECK_SEQUENCE
例
/NOCHECK_SEQUENCE
/NOCHECK_SEQUENCE修飾子は,Mergeユーティリティの省略時の動作を指定変更する。
/COLLATING_SEQUENCE=(SEQUENCE=sequence-type [,MODIFICATION=("char1" operator "char2")] [,IGNORE=文字または文字範囲,...] [,FOLD] [,[NO]TIE_BREAK])
ASCII,EBCDIC,MULTINATIONALの各照合順序についての詳細は,第11.3節を参照。
次の修飾子の値を指定することができる。
| SEQUENCE | 指定ファイルは,ASCII, EBCDIC,MULTINATIONALの各照合順序の他,ユーザ定義照合順序もサポートする。 これらの照合順序についての詳細は,第11.3節を参照。 | ||||||||||
| MODIFICATION | SEQUENCEオプションで指定した照合順序を変更するよう指定する。ASCII
,EBCDIC,
MULTINATIONALの各照合順序の他,ユーザ定義照合順序も変更することができる。
たとえ順序が省略時の値(ASCII)であっても,変更する順序は,SEQUENCE
修飾子で指定されているものでなければならない。
| ||||||||||
MODIFICATIONオプションでは,次の種類の変更が認められている。
| |||||||||||
| IGNORE | 最初に比較を行うとき,照合順序内の1つまたは複数の文字が無視されるよう指定する。 タイブレークが発生するとき, IGNORE値で指定されている文字についても考慮される。 | ||||||||||
| FOLD | すべての小文字に対して,大文字に相当する照合値が定義されるよう指定する。ASCII ,EBCDIC,ユーザ定義順序の場合, 小文字はaからzになる。 | ||||||||||
| MULTINATIONAL順序の小文字には,大文字に相当する照合値がすでにあるため,FOLD を使用する必要はない。 | |||||||||||
| [NO]TIE_ BREAK | 同等の値を持つ文字でタイブレークの比較を行うとき, 数値を使用するかどうか指定する。省略時の場合,MULTINATIONAL 順序ではタイブレークが発生する。NOTIE_BREAKを指定すると,この省略時の設定が指定変更され, 最初の比較が行われた後は比較が行われなくなる。 | ||||||||||
| ASCII,EBCDIC,ユーザ定義順序でタイブレークが発生するようにしたい場合,TIE_BREAK オプションを指定する必要がある。 これらの順序でFOLD値またはMODIFICATION値を指定するとき,TIE_BREAK を使用する。 |
例
/CONDITION=(NAME=condition-name, TEST=(field-name operator test-condition [logical-operator...]))
出力ファイルのレコードの順序を変更したい場合,最初に/CONDITION 修飾子で条件名を指定し,その条件に適合するかどうかを試すテストを設定する。 次にその形式の/KEY修飾子で相対順序を指定する。
/KEY=(IF condition-name THEN value ELSE value)
レコードの相対順序を指定するとき,任意の値を使用することができる。
/CONDITION修飾子を使用すると,出力レコードのフィールドの内容も変更することができる。 最初に条件名を指定し,次にその条件に適合するかどうかを試すテストを設定する。 その形式の/DATA修飾子で,フィールドに入れる内容を指定する。
/DATA=(IF condition-name THEN "new-contents"
ELSE "new-contents")
次の修飾子の値を指定することができる。
| NAME | テストする条件の名前を指定する。 この条件名は,/CONDITION修飾子で定義した後,/KEY, /DATA,/OMIT,/INCLUDEのそれぞれの修飾子で使用することができる。 | ||||||||
| TEST | 条件テストを指定する。
|
例
指定ファイルにおける/CONDITION修飾子の使用例については,第11.7節を参照。
/DATA=field-name /DATA=(IF condition THEN "new contents" ELSE "new contents")
/CONDITION修飾子で設定した条件を指定することにより,出力レコードのフィールドの内容を条件によって変更することができる。/DATA 修飾子のフィールドに設定したい内容を指定する。
/DATA=(IF condition-name THEN "new-contents" ELSE "new-contents")
次のような修飾子の値を設定できる。
| field-name | レコードのフィールド名を指定する。 フィールド名は事前に/FIELD修飾子で定義されていなければならない。 |
| condition-name | 事前に/CONDITION修飾子で定義されている条件名を指定する。 |
| new-contents | レコードをどのように変更するかを指定する。 定数値でも/FIELD修飾子で定義されたフィールド名でも可。 |
例
指定ファイル内での/DATA修飾子の使用例については,第11.7節を参照。
/FIELD=(NAME=field-name,POSITION:n,SIZE:N,[DIGITS:n,]data-type /FIELD=(NAME=field-name,VALUE:n,SIZE:N,[DIGITS:n,]data-type)
フィールド名は一意でなければならない。また,フィールド定義の数は255 以内でなければいけない。
また, /FIELD修飾子を使用して定数値を定義し, /CONDITION, /DATA,および/KEY文で使用するデータ・タイプの値に割り当てることができる。
次のような修飾子の値を指定できる。
| NAME | フィールド名を指定する。フィールド名にはスペースを含めることはできない。 英字で始まり,31 文字以内でなければいけない。 | ||||||
| POSITION:n | レコード内でのこのフィールドの位置を指定する。 | ||||||
| VALUE:n | /CONDITION, /DATA,/KEY文で使用される定数フィールドに値を割り当てる。VALUE: nを指定した場合,/POSITION: nを指定してはいけない。 これは,このフィールドは定数フィールドであり,入力レコードのフィールドではないからである。 | ||||||
| SIZE:n | 文字あるいはバイナリ・
データを含むフィールドのサイズをバイト数で指定する。データ・タイプにより,
以下のように指定可能なサイズが決まっている。
| ||||||
| DIGITS:n | 10進データを含むフィールドのサイズを指定する。 ここで指定するサイズは31以内でなければいけない。DIGITS:n は10進データを含んだフィールドを表現するときのみ使用する。 | ||||||
| data-type | データ・ タイプを指定する。文字型の場合は指定する必要はない。省略時の設定では,Sort は文字データ・タイプを想定する。Sort/Mergeにより認識されるデータのタイプについては 第11.2.1項を参照。 |
例
/FIELD=(NAME=SALARY,POSITION:10,DIGITS:8,DECIMAL)
この/FIELD修飾子により,レコード内のこのフィールドはSALARYにより認識され, フィールドは10バイト目から8桁の長さ,10進データであることが指定される。
/INCLUDE=(CONDITION=condition[,KEY=...] [,DATA=...])
1つのファイルに対して,複数の/INCLUDE,/OMIT修飾子を指定することができる。 それらを指定した順序により,入力レコードがテストされる。 最後の/INCLUDE修飾子のあとで,選択対象とならなかったレコードまたは明示的に削除されたレコードがすべて削除される。
事前に削除されなかったレコード,または条件を指定せずに/INCLUDE 修飾子を指定することにより選択されたレコードを,出力に含めることもできます。
複数の形式のレコードをソートする場合は,ソートするそれぞれの形式のレコード形式に対して/INCLUDE 修飾子を指定する。/INCLUDE修飾子でKEY オプションを指定しない場合は, Sortは省略時のキー定義を使用する。/INCLUDE 修飾子でKEYオプションを指定した場合は,省略時のキー定義は使用されない。/INCLUDE 修飾子のKEYフィールドの順序により, ソートのための内部キーが作成される。/INCLUDE修飾子のDATA フィールドの順番により,出力レコードのフォーマットが決定される。/INCLUDE 修飾子で1つでもKEYフィールドまたはDATAフィールドを指定した場合は, 出力したいすべてのKEYフィールドまたはDATAフィールドを指定する必要がある。
以下のような修飾子の値を指定できる。
| CONDITION | /CONDITION修飾子で既に定義されている条件名を指定する。 |
| KEY | /KEY修飾子で定義された省略時のレコード・タイプが使用されないので, キー・フィールドを定義する。 |
| DATA | /DATA修飾子で定義された省略時のレコード・ タイプが使用されないので,データ・フィールドを定義する。 |
例
/FIELD=(NAME=ZIP,POSITION:20,SIZE:6)
/CONDITION=(NAME=LOCATION,
TEST=(ZIP EQ "01863"))
/INCLUDE=(CONDITION=LOCATION)
/CONDITIONおよび/INCLUDE修飾子を使用して,出力ファイルにzipコードが01863 のレコードを含めることを指定している。
/KEY=field-name /KEY=(field-name,order) /KEY=([IF condition THEN value ELSE]...) value [,order]
3種類の/KEY修飾子の使用方法がある。
/KEY=(IF condition-name THEN value ELSE value)
レコードの相対順序を指定するするためには,任意の値を使用することができる。
以下の修飾子の値を指定できる。
| field-name | キー・フィールド名を指定する。 フィールド名は,事前に/FIELD修飾子で定義されている。 |
| order | ソート順を指定する。ASCENDING は昇順,DESCENDINGは降順にソートする。省略時の設定はASCENDING 。 |
| value | キーを指定する。値は,定数値でも/FIELD修飾子で定義されたフィールド名でも可。 |
例
/FIELD=(NAME=SALARY,POSITION:10,DIGITS:8,DECIMAL)
/KEY=(SALARY,DESCENDING)
この/KEY修飾子は,キーはSALARYで,降順にソートすることを示す。
/FIELD=(NAME=ZIP,POSITION:20,SIZE:6)
/CONDITION=(NAME=LOCATION,
TEST=(ZIP EQ "01863"))
/KEY=(IF LOCATION THEN 1
ELSE 2)
この例では,zipコードが01863のすべてのレコードがソート済みの出力ファイルの最初にくる。/CONDITION で定義された条件LOCATION は, ZIPフィールドが判定の対象であることを示す。この/KEY句における1 と2は,この条件を満たすレコードとそうでないレコードの順序を明示する。
/OMIT=(CONDITION=condition-name)
はじめに/CONDITION修飾子で条件を定義しなければならない。 ソート処理から除外される条件を満たすレコードを指定するために,/OMIT 修飾子を指定する。省略時の設定では,条件に該当しないすべてのレコードは出力ファイルに出力される。
指定ファイルで,複数の/OMITと/INCLUDE修飾子を指定できる。指定の順序により, 除外のための入力レコードのチェックの順序が決定される。 まだ出力されていないすべてのレコード,または最後の/OMIT 修飾子の後まで除外されていないすべてのレコードが出力される。/OMIT 修飾子のみを指定することにより,除外されていなかったレコードを無条件に取り除くこともできる。
例
/FIELD=(NAME=ZIP,POSITION:20,SIZE:6)
/CONDITION=(NAME=LOCATION,
TEST=(ZIP EQ "01863"))
/OMIT=(CONDITION=LOCATION)
この/CONDITIONと/OMIT修飾子は,zipコードが01863のレコードを出力ファイルに出力しないことを指定している。
/PAD=single-character
埋めこみ文字は以下のように指定する。
例
/PAD="."
この/PAD修飾子の例では,レコードをピリオドで埋め込むことを指定している。
/PROCESS=type
4タイプのプロセスの比較については第11.8.1項を参照。
例
/PROCESS=tag
この/PROCESS修飾子の例では,タグ・ソート・プロセスを使用することを指定している。
/[NO]STABLE
省略時の設定では,同一キーでレコードがソートされた場合,出力ファイルでのレコードの順序は, 必ずしも入力ファイルでの順序と同じではない。 指定ファイルで/STABLE修飾子を指定すると,キーの同じレコードがあった場合, 入力ファイルの順序で出力ファイルに出力される。 複数の入力ファイルがある場合にこの修飾子を使用した場合, キーが同じレコードは,1番目の入力ファイルが最初に, 次に2番目の入力ファイルのレコードが出力される。
例
/STABLE
この/STABLE修飾子の例では,キーが同じレコードがあった場合, 出力ファイルには入力ファイルと同じ順序で整列されることが保証される。
/WORK_FILES=(device[,...])
DCLでの修飾子/WORK_FILES=nと異なり,指定ファイル修飾子/WORK_ FILES=(device[,...])は,作業ファイルの数ではなく作業ファイルの割り当てを指定する。
作業ファイルについての詳細は,第11.8.3項を参照。
例
/WORK_FILES=("WRKD$:")
この/WORK_FILES修飾子の例では,ソートの作業ファイルの1つをデバイスWRKD$ を割り当てる。これは,このデバイスがもっとも使用可能スペースが多いからである。
[ 前のページ ]
[ 次のページ ]
[ 目次 ]
[ 索引 ]
[ DOC Home ]