


| 前へ | 次へ | 目次 | 索引 |
この節では,漢字コード変換ユーティリティの使用例を示します。
この章では,DEC 漢字コード変換ユーティリティ (KCONVERT) について説明します。
7.1 機能概要
DEC 漢字セットとASCII 文字セットで記述された日本語文書内の特定の漢字コードを,変換指定テーブルにしたがって変換します。日本語 Compaq OpenVMS オペレーティング・システムでは DEC 漢字 1978 年版とDEC 漢字 1983 年版間の変換指定テーブルが提供されます。変換指定テーブルはエディタなどを用いて利用者が作成/ 変更することもできます。
漢字コード変換ユーティリティ(KCODE)は他社の漢字コード系との変換を行いますが,このDEC漢字コード変換ユーティリティ(KCONVERT) は,入力ファイルも出力ファイルも DEC 漢字コード系であることを前提にしています。
DCL コマンドですぐに利用できるユーティリティと,プログラムから呼びだすルーチンの 2種類があります。
7.2 KCONVERT コマンド
この節では,KCONVERT コマンドの形式,パラメータ,修飾子について説明します。
DEC 漢字コード変換ユーティリティを起動します。
KCONVERT/TABLE = 変換テーブル・ファイル指定 [ /修飾子 ] 入力ファイル指定 [ 出力ファイル指定 ]
入力ファイル指定
変換するファイル名を指定します。RMS が日本語モードの場合には,最大 118 文字までの日本語ファイル名を指定できます。ワイルドカードも指定できます。出力ファイル指定
変換したファイルの出力先を指定します。RMS が日本語モードの場合には,最大 118 文字までの日本語ファイル名を指定できます。省略時には,入力ファイルと同じ名前で,バージョンを更新したファイルに出力します。
/CHECK
/TABLE で指定された変換テーブルに記述された漢字コードが入力ファイルにあるかどうかのみを検査し,その情報を /LOG_FILE で指定された出力先に出力します。漢字コード変換された出力ファイルは生成されません。 /NOCHECK が指定された場合は,実際の変換を行い,コード変換された出力ファイルが生成されます。
/NOCHECK (省略時設定)/FIELD = (...)
1レコード内の変換・検査の範囲を指定します。 /FIELD 修飾子は 16 個まで記述できますが,各々の /FIELD 修飾子で指定する範囲が重なってはいけません。/FIELD 修飾子の指定がない場合は,1レコード全体が変換・検査の対象になります。以下の項目が指定できます。
START: i 変換・検査の開始位置をバイト・オフセットで指定します。レコードの先頭は1です。省略時設定値は1です。 END: j 変換・検査の終了位置をバイト・オフセットで指定します。 LENGTH と同時には指定できません。END も LENGTH も指定されていない場合は,レコードの最後まで変換・検査を行います。 LENGTH:k 変換・検査する範囲を START で指定した位置からのバイト数で指定します。END と同時には指定できません。END も LENGTH も指定されていな場合は,レコードの最後まで変換・検査を行います。 KANJI 半角カタカナ混じりの文章の場合,最初が漢字で始まっていることを指定します。 KATAKANA 半角カタカナ混じりの文章の場合,最初が半角カタカナで始まっていることを指定します。KANJI と KATAKANA のいずれの指定もない場合は, /MODE 修飾子で指定された文字で開始しているものとみなします。
/INQUIRE
変換テーブルで指定された(変換指定の)漢字コードがあった際,変換するかどうかを問い合わせます。/CHECK と同時には指定できません。
/NOINQUIRE (省略時設定)省略時は問い合わせを行わず,指定のコードに変換します。
/LOG_FILE = 出力先名
変換・検査の情報を指定の出力先に出力します。RMS が日本語モードの場合には,最大 118 文字までの日本語ファイル名を指定できます。省略時は SYS$OUTPUT に出力します。
/NOLOG_FILE/NOLOG_FILE を指定した場合には,変換・検査の情報は出力されません。
/MODE = 文字コード指定
文書が DEC 漢字コードと半角カタカナ混じりの場合,最初が漢字で始まっているか半角カタカナで始まっているかを指定します。以下の2つを指定できます。
/MODE = KANJI (省略時設定)
KANJI 漢字で始まる KATAKANA 半角カタカナで始まる
KCONVERTユーティリティは,文書中にエスケープ・シーケンス (LS2R,LS3R) があると自動的に
LS2R (〈ESC〉} ).....この制御コード以後は半角カタカナとみなし, 次に LS3R がみつかるまで変換・検査を行わない LS3R (〈ESC〉| ).....この制御コード以後は漢字とみなし,変換・検査を行う
注意
〈ESC〉は 16 進数の 1B,‘ } ’は 7D,| は 7C です。
として処理し,漢字の部分のみを変換・検査の対象にします。
- 文書が LS3R なしの漢字コードで始まり,途中に半角カタカナが混じっている場合

この場合は漢字で始まっていますから /MODE 修飾子を省略できます。
$ KCONVERT/TABLE=... Input_file Output_file
- 文書が LS2R コードなしの半角カタカナで始まっている場合

この場合は半角カタカナで始まっていることを /MODE=KATAKANA で指定します。
$ KCONVERT/MODE=KATAKANA/TABLE=... Input_file Output_file
- 文書に LS2R または LS3R コードがある場合
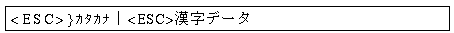
または

この場合は /MODE=KANJI を指定しても /MODE=KATAKANA を指定しても,変換・検査の結果は同じですから,/MODE の指定は不要です。
$ KCONVERT/TABLE=... Input_file Output_file
/RANGE 修飾子の指定がないときは,すべてのレコードが変換・検査の対象になります。以下の項目が指定できます。
| START:i | 変換・検査する開始レコード番号を指定します。最初のレコード番号は1です。省略時設定値は1です。 |
| END:j | 変換・検査する終了レコード番号を指定します。LENGTH と同時には指定できません。END も LENGTH も指定されていないときは,最後のレコードまで変換・検査を行います。 |
| LENGTH:k | 変換・検査するレコード数を指定します。END と同時には指定できません。END も LENGTH も指定されていないときは,最後のレコードまで変換・検査を行います。 |
| KANJI | 半角カタカナ混じりの文章のとき,最初が漢字で始まっていることを指定します。 |
| KATAKANA | 半角カタカナ混じりの文章のとき,最初が半角カタカナで始まっていることを指定します。KANJI と KATAKANA のいずれの指定も無いときは,/MODE 修飾子で指定された文字で開始しているものとみなします。 |
$ KCONVERT/TABLE=JSY$SYSTEM:KCV78TO83.TABLE Input_file Output_file
|
$ KCONVERT/TABLE=JSY$SYSTEM:KCV83TO78.TABLE Input_file Output_file
|
$ KCONVERT/TABLE=CONVERT.TABLE Input_file Output_file
|
変換テーブルの形式については 第 7.3 節 を参照してください。
7.3 変換指定テーブル
変換・検査で使用する変換指定テーブルの形式を説明します。利用者定義による漢字コード変換を行う場合は,KCONVERT ユーティリティを使用する前に,変換テーブルを日本語エディタなどで作成します。
! KCONVERT 変換指定テーブルの例
!
C XB1B1 XC1C1 ! 臼を疏に変換する
C XB1B2 XC1C2 ! 渦を疎に変換する
I XD1D1 ! 冪があれば通知する
...................
...................
END ! 変換指定テーブル終り
|
半角の感嘆符 '!' で始まる行はコメント行です。変換・検査には使用されません。

先頭が半角の 'C' で始まる行は変換指定になります。

XB0A1 ...... 亜 J1601 ...... 亜 XA2A1 ...... ◆ J0201 ...... ◆
|
DEC漢字1区1点の文字コードはJ0101と記述します。拡張領域の文字コードは'J1'で始まる4けたの区点番号で記述します。 DEC拡張漢字1区1点の文字は先頭に 1 をつけ J10101 と記述でき,これは XA121 と同じ文字コードを示します。
|
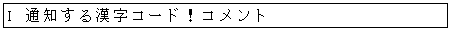
先頭が 'END' で始まる行までが変換テーブルとして扱われます。この行以降は何が記述されていても無視されます。

使用例として,DEC 漢字 1978 年版漢字コードと DEC 漢字 1983 年版の相互変換方法を説明します。
7.4.1 1978 年版から 1983 年版への変換
DEC 漢字 1978 年版のファイルをDEC 漢字 1983 年版に変換する場合は,以下の変換テーブルを使用します。
JSY$SYSTEM:KCV78TO83.TABLE
|
このテーブルでは,次の項目が指定されています。
変換を行うには,次のようにします。
$ KCONVERT/TABLE=JSY$SYSTEM:KCV78TO83.TABLE[/修飾子] 入力ファイル名
[出力ファイル名]
|
DEC 漢字1983 年版の漢字コードを DEC 漢字 1978 年版に変換する場合は,以下の変換テーブルを使用します。
JSY$SYSTEM:KCV83TO78.TABLE |
このテーブルでは,次の項目が指定されています。
変換を行うには,次のようにします。
$ KCONVERT/TABLE=JSY$SYSTEM:KCV83TO78.TABLE [/修飾子] 入力ファイル名
[出力ファイル名]
|
日本語 Compaq OpenVMS が標準として提供するのは上の2つのテーブルのみです。変換を罫線コードに限定するなど変換内容を変える場合は,新たに変換テーブルを作成してください。
7.5 コード変換ライブラリ
KCONVERT ユーティリティが使用しているルーチンがランタイム・ライブラリとして JSY$LIBRARY:JSYLIB.OLB に入っています。また,ステータス定義ファイルとしては JSY$SYSTEM:JSYDEF.* (* は FOR,H など各言語用) があります。
KCONVERT ユーティリティでは処理できない場合は,コード変換ルーチンを用いて専用の変換プログラムを作成してください。
各ルーチンについては『日本語ライブラリ 利用者の手引き』を参照してください。
| 前へ | 次へ | 目次 | 索引 |