! Specification file for sorting negative and positive data ! in ascending order ! /FIELD=(NAME=SIGN,POS:1,SIZ:1) (1) /FIELD=(NAME=AMT,POS:2,SIZ:4) (2) /CONDITION=(NAME=CHECK1, (3) TEST=(SIGN EQ "-")) /CONDITION=(NAME=CHECK2, (4) TEST=(SIGN EQ " ")) /INCLUDE=(CONDITION=CHECK1, (5) KEY=(AMT,DESCENDING), DATA=SIGN, DATA=AMT) /INCLUDE=(CONDITION=CHECK2, (6) KEY=(AMT,ASCENDING), DATA=SIGN, DATA=AMT) |
回年ファイルを澄千する狠には·肌の爬に庙罢してください。
- このコマンド乖は·レコ〖ドの妈 1 バイトで幌まる·墓さ 1 バイトのフィ〖ルドを年盗し·このフィ〖ルドに叹涟 SIGN を充り碰てる。
- このコマンド乖は·レコ〖ドの妈 2 バイトで幌まる·墓さ 4 バイトのフィ〖ルドを年盗し·このフィ〖ルドに叹涟 AMT を充り碰てる。
- これは掘凤矢である。SIGN バイトに砷射规(-)がある眷圭·掘凤 CHECK1 を塔たす。
- これは掘凤矢である。SIGN バイトがブランクの眷圭·掘凤 CHECK2 を塔たす。
- 掘凤 CHECK1 を塔たす眷圭·レコ〖ドを惯界にソ〖トする。
- 掘凤 CHECK2 を塔たす眷圭·レコ〖ドを竞界にソ〖トする。
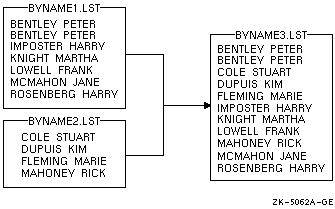
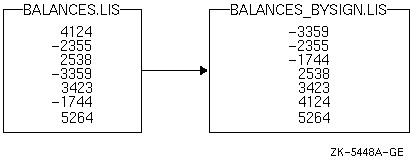
哭 9-8 は·惧の回年ファイルの毋を BALANCES.LIS という掐蜗ファイルに蝗脱した冯蔡を绩しています。
哭 9-8 回年ファイルを蝗脱した叫蜗
/FIELD=(NAME=RECORD_TYPE,POS:1,SIZ:1) ! Record type, 1-byte
/FIELD=(NAME=PRICE,POS:2,SIZ:8) ! Price, both files
/FIELD=(NAME=TAXES,POS:10,SIZ:5) ! Taxes, both files
/FIELD=(NAME=STYLE_A,POS:15,SIZ:10) ! Style, format A file
/FIELD=(NAME=STYLE_B,POS:20,SIZ:10) ! Style, format B file
/FIELD=(NAME=ZIP_A,POS:25,SIZ:5) ! Zip code, format A file
/FIELD=(NAME=ZIP_B,POS:15,SIZ:5) ! Zip code, format B file
/CONDITION=(NAME=FORMAT_A, ! Condition test, format A
TEST=(RECORD_TYPE EQ "A"))
/CONDITION=(NAME=FORMAT_B, ! Condition test, format B
TEST=(RECORD_TYPE EQ "B"))
/INCLUDE=(CONDITION=FORMAT_A, ! Output format, type A
KEY=ZIP_A,
DATA=PRICE,
DATA=TAXES,
DATA=STYLE_A,
DATA=ZIP_A)
/INCLUDE=(CONDITION=FORMAT_B, ! Output format, type B
KEY=ZIP_B,
DATA=PRICE,
DATA=TAXES,
DATA=STYLE_B,
DATA=ZIP_B)
|
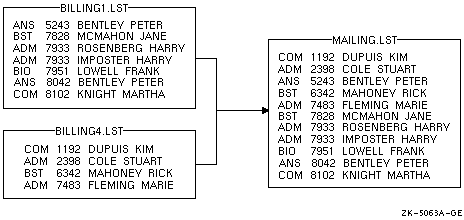
この毋では·稍瓢缓洛妄殴の 2 つの毁家から流られた 2 つの掐蜗ファイルが·回年ファイルの回绩に骄ってソ〖トされます。1 つ誊のファイルのレコ〖ドは·呵介の疤弥に A がついており·肌の妨及になっています。
|A|PRICE|TAXES|STYLE|ZIP|
1 2 10 15 25
|
2 つ誊のファイルのレコ〖ドは·呵介の疤弥に B がつき·style フィ〖ルドと zip code フィ〖ルドが·肌のように嫡になっています。
|B|PRICE|TAXES|ZIP|STYLE|
1 2 10 15 20
|
これらの 2 つのファイルを·レコ〖ド A の妨及の zip code フィ〖ルドでソ〖トするとき·呵介に尉数のレコ〖ドのフィ〖ルドを·/FIELD 饯峻灰で年盗します。その稿·/CONDITION 饯峻灰で·2 つのタイプのレコ〖ドを惰侍するためのテストを回年します。呵稿に /INCLUDE 饯峻灰を回年して·タイプ B のレコ〖ド妨及をタイプ A のレコ〖ド妨及に恃构して叫蜗します。
/INCLUDE 饯峻灰でキ〖ˇフィ〖ルドまたはデ〖タˇフィ〖ルドのいずれかを回年する眷圭·/INCLUDE 饯峻灰のSort 拎侯で汤绩弄にすべてのキ〖ˇフィ〖ルドとデ〖タˇフィ〖ルドを回年する涩妥があります。
また·タイプAでもタイプBでもないレコ〖ドは·ソ〖ト箕に怯近されます。
/COLLATING_SEQUENCE=(SEQUENCE=
("AN","EB","AR","PR","AY","UN","UL",
"UG","EP","CT","OV","EC","0"-"9"),
MODIFICATION=("'"="19"),
FOLD)
|
この /COLLATING_SEQUENCE 饯峻灰では·ユ〖ザ年盗界进を回年します。この回年により·それぞれの奉に·泣烧界の盖铜の猛が年盗されます。たとえば·SEMINAR.DAT というファイルを泣烧界に事べたい眷圭·SEMINAR.DAT ファイルは肌のようになっています。
16 NOV 1983 Communication Skills
05 APR 1984 Coping with Alcoholism
11 Jan '84 How to Be Assertive
12 OCT 1983 Improving Productivity
15 MAR 1984 Living with Your Teenager
08 FEB 1984 Single Parenting
07 Dec '83 Stress --- Causes and Cures
14 SEP 1983 Time Management
|
办肌キ〖が year フィ〖ルドで·企肌キ〖が month フィ〖ルドです。month フィ〖ルドは眶猛ではありませんが·泣烧界に事べたいため·迫极の救圭界进を年盗する涩妥があります。この眷圭·それぞれの奉に盖铜のキ〖猛を回年して·それぞれの奉の 2 戎誊と 3 戎誊の矢机を(泣烧界に)ソ〖トすることにより·これを乖います。
MODIFICATION オプションでは·アポストロフィ(')が 19 と票霹になるよう回年していますが·これによって·'83 と 1984 が孺秤できるようになります。また FOLD オプションは·络矢机と井矢机が票霹に胺われるよう回年します。
この Sort 拎侯の叫蜗は·肌のようになります。
14 SEP 1983 Time Management
12 OCT 1983 Improving Productivity
16 NOV 1983 Communication Skills
07 Dec '83 Stress --- Causes and Cures
11 Jan '84 How to Be Assertive
08 FEB 1984 Single Parenting
15 MAR 1984 Living with Your Teenager
05 APR 1984 Coping with Alcoholism
|
ユ〖ザ年盗救圭界进の戮の毋については·妈 9.3 泪 を徊救してください。
/FIELD=(NAME=AGENT,POSITION:20,SIZE:15)
/CONDITION=(NAME=AGENCY,
TEST=(AGENT EQ "Real-T Trust"
OR
AGENT EQ "Realty Trust"))
/DATA=(IF AGENCY THEN "Realty Trust" ELSE AGENT)
|
この毋では·2 つの稍瓢缓ファイルをソ〖トします。1 つのファイルは·ある洛妄殴が Real-T Trust と钙ぶもので·もう 1 つのファイルは Realty Trust と钙ばれます。/CONDITION 饯峻灰と /DATA 饯峻灰により·Realty Trust のソ〖ト叫蜗ファイルに AGENT フィ〖ルドがリストされることになります。
/FIELD=(NAME=ZIP,POSITION:60,SIZE:6)
/CONDITION=(NAME=LOCATION,
TEST=(ZIP EQ "01863"))
/KEY=(IF LOCATION THEN 1
ELSE 2)
|
この毋では·凸守戎规 01863 を积つすべてのレコ〖ドがソ〖ト叫蜗ファイルの呵介にリストされます。掘凤テストは·/FIELD 饯峻灰で年盗されているように ZIP フィ〖ルドで乖われます。掘凤叹は LOCATION になっています。/KEY 饯峻灰にある猛 1 と 2 は·掘凤を塔たすレコ〖ドと掘凤を塔たさないレコ〖ドの陵滦界进を山すものです。
/FIELD=(NAME=ZIP,POSITION:60,SIZE:6)
/CONDITION=(NAME=LOCATION,
TEST=(ZIP EQ "01863"))
/DATA=(IF LOCATION THEN "NORTH CHELMSFORD"
ELSE "Outside district")
|
この毋では·/CONDITION 饯峻灰により·凸守戎规 01863 についてテストが乖われます。/DATA 饯峻灰は·テスト冯蔡に骄って·town フィ〖ルドの叹涟が叫蜗レコ〖ドに纳裁されるよう回年します。
/FIELD=(NAME=FFLOAT,POS:1,SIZ:0,F_FLOATING) /CONDITION=(NAME=CFFLOAT,TEST=(FFLOAT GE 100)) /OMIT=(CONDITION=CFFLOAT) |
この毋では·/FIELD 饯峻灰でフィ〖ルド FFLOAT が F_FLOATING と年盗されているため·眶猛 100 が F_FLOATING デ〖タ房とみなされます。
/FIELD=(NAME=AGENT,POSITION:1,SIZE:5) /FIELD=(NAME=ZIP,POSITION:6,SIZE:3) /FIELD=(NAME=STYLE,POSITION:10,SIZE:5) /FIELD=(NAME=CONDITION,POSITION:16,SIZE:9) /FIELD=(NAME=PRICE,POSITION:26,SIZE:5) /FIELD=(NAME=TAXES,POSITION:32,SIZE:5) /DATA=PRICE /DATA=" " /DATA=TAXES /DATA=" " /DATA=STYLE /DATA=" " /DATA=ZIP /DATA=" " /DATA=AGENT |
この /FIELD 饯峻灰は·肌の妨及を积つ掐蜗ファイルのレコ〖ドのフィ〖ルドを年盗します。
AGENT ZIP STYLE CONDITION PRICE TAXES |
/DATA 饯峻灰では·/FIELD 饯峻灰で年盗されているフィ〖ルド叹を蝗脱しますが·レコ〖ドを浩フォ〖マットして·肌の妨及の叫蜗レコ〖ドを侯喇します。
PRICE TAXES STYLE ZIP AGENT |