![[OpenVMS documentation]](../../images/openvms_doc_banner_top.gif)
|
![[Site home]](../../images/buttons/bn_site_home_off.gif)
![[Send comments]](../../images/buttons/bn_comments_off.gif)
![[Help with this site]](../../images/buttons/bn_site_help_off.gif)
![[How to order documentation]](../../images/buttons/bn_order_docs_off.gif)
![[OpenVMS site]](../../images/buttons/bn_openvms_off.gif)
![[Compaq site]](../../images/buttons/bn_compaq_off.gif)
|
| Updated: 11 December 1998 |
|
|
|
|
| Updated: 11 December 1998 |
Guidelines for OpenVMS Cluster Configurations
| Previous | Contents | Index |
The following sections describe troubleshooting tips for solving common
problems in an OpenVMS Cluster system that uses a SCSI interconnect.
A.7.4.1 Termination Problems
Verify that two terminators are on every SCSI interconnect (one at each
end of the interconnect). The BA350 enclosure, the BA356 enclosure, the
DWZZx, and the KZxxx adapters have internal
terminators that are not visible externally (see Section A.4.4.)
A.7.4.2 Booting or Mounting Failures Caused by Incorrect Configurations
OpenVMS automatically detects configuration errors described in this
section and prevents the possibility of data loss that could result
from such configuration errors, either by bugchecking or by refusing to
mount a disk.
A.7.4.2.1 Bugchecks During the Bootstrap Process
For versions prior to OpenVMS Alpha Version 7.2, there are three types of configuration errors that can cause a bugcheck during booting. The bugcheck code is VAXCLUSTER, Error detected by OpenVMS Cluster software.
When OpenVMS boots, it determines which devices are present on the SCSI bus by sending an inquiry command to every SCSI ID. When a device receives the inquiry, it indicates its presence by returning data that indicates whether it is a disk, tape, or processor.
Some processor devices (host adapters) answer the inquiry without assistance from the operating system; others require that the operating system be running. The adapters supported in OpenVMS Cluster systems require the operating system to be running. These adapters, with the aid of OpenVMS, pass information in their response to the inquiry that allows the recipient to detect the following configuration errors:
In OpenVMS Alpha Version 7.2, SCSI devices on a misconfigured bus (as
described in Section A.7.4.2.1) are not configured. Instead, error messages
that describe the incorrect configuration are displayed.
A.7.4.2.3 Mount Failures
There are two types of configuration error that can cause a disk to fail to mount.
First, when a system boots from a disk on the shared SCSI bus, it may fail to mount the system disk. This happens if there is another system on the SCSI bus that is already booted, and the other system is using a different device name for the system disk. (Two systems will disagree about the name of a device on the shared bus if their controller names or allocation classes are misconfigured, as described in the previous section.) If the system does not first execute one of the bugchecks described in the previous section, then the following error message is displayed on the console:
%SYSINIT-E- error when mounting system device, retrying..., status = 007280B4 |
The decoded representation of this status is:
VOLALRMNT, another volume of same label already mounted |
This error indicates that the system disk is already mounted in what appears to be another drive in the OpenVMS Cluster system, so it is not mounted again. To solve this problem, check the controller letters and allocation class values for each node on the shared SCSI bus.
Second, SCSI disks on a shared SCSI bus will fail to mount on both systems unless the disk supports tagged command queuing (TCQ). This is because TCQ provides a command-ordering guarantee that is required during OpenVMS Cluster state transitions.
OpenVMS determines that another processor is present on the SCSI bus during autoconfiguration, using the mechanism described in Section A.7.4.2.1. The existence of another host on a SCSI bus is recorded and preserved until the system reboots.
This information is used whenever an attempt is made to mount a non-TCQ device. If the device is on a multihost bus, the mount attempt fails and returns the following message:
%MOUNT-F-DRVERR, fatal drive error. |
If the drive is intended to be mounted by multiple hosts on the same SCSI bus, then it must be replaced with one that supports TCQ.
Note that the first processor to boot on a multihost SCSI bus does not
receive an inquiry response from the other hosts because the other
hosts are not yet running OpenVMS. Thus, the first system to boot is
unaware that the bus has multiple hosts, and it allows non-TCQ drives
to be mounted. The other hosts on the SCSI bus detect the first host,
however, and they are prevented from mounting the device. If two
processors boot simultaneously, it is possible that they will detect
each other, in which case neither is allowed to mount non-TCQ drives on
the shared bus.
A.7.4.3 Grounding
Having excessive ground offset voltages or exceeding the maximum SCSI
interconnect length can cause system failures or degradation in
performance. See Section A.7.8 for more information about SCSI
grounding requirements.
A.7.4.4 Interconnect Lengths
Adequate signal integrity depends on strict adherence to SCSI bus
lengths. Failure to follow the bus length recommendations can result in
problems (for example, intermittent errors) that are difficult to
diagnose. See Section A.4.3 for information on SCSI bus lengths.
A.7.5 SCSI Arbitration Considerations
Only one initiator (typically, a host system) or target (typically, a peripheral device) can control the SCSI bus at any one time. In a computing environment where multiple targets frequently contend for access to the SCSI bus, you could experience throughput issues for some of these targets. This section discusses control of the SCSI bus, how that control can affect your computing environment, and what you can do to achieve the most desirable results.
Control of the SCSI bus changes continually. When an initiator gives a command (such as READ) to a SCSI target, the target typically disconnects from the SCSI bus while it acts on the command, allowing other targets or initiators to use the bus. When the target is ready to respond to the command, it must regain control of the SCSI bus. Similarly, when an initiator wishes to send a command to a target, it must gain control of the SCSI bus.
If multiple targets and initiators want control of the bus simultaneously, bus ownership is determined by a process called arbitration, defined by the SCSI standard. The default arbitration rule is simple: control of the bus is given to the requesting initiator or target that has the highest unit number.
The following sections discuss some of the implications of arbitration
and how you can respond to arbitration situations that affect your
environment.
A.7.5.1 Arbitration Issues in Multiple-Disk Environments
When the bus is not very busy, and bus contention is uncommon, the simple arbitration scheme is adequate to perform I/O requests for all devices on the system. However, as initiators make more and more frequent I/O requests, contention for the bus becomes more and more common. Consequently, targets with lower ID numbers begin to perform poorly, because they are frequently blocked from completing their I/O requests by other users of the bus (in particular, targets with the highest ID numbers). If the bus is sufficiently busy, low-numbered targets may never complete their requests. This situation is most likely to occur on systems with more than one initiator because more commands can be outstanding at the same time.
The OpenVMS system attempts to prevent low-numbered targets from being
completely blocked by monitoring the amount of time an I/O request
takes. If the request is not completed within a certain period, the
OpenVMS system stops sending new requests until the tardy I/Os
complete. While this algorithm does not ensure that all targets get
equal access to the bus, it does prevent low-numbered targets from
being totally blocked.
A.7.5.2 Solutions for Resolving Arbitration Problems
If you find that some of your disks are not being serviced quickly enough during periods of heavy I/O, try some or all of the following, as appropriate for your site:
Another method that might provide for more equal servicing of lower and higher ID disks is to set the host IDs to the lowest numbers (0 and 1) rather than the highest. When you use this method, the host cannot gain control of the bus to send new commands as long as any disk, including those with the lowest IDs, need the bus. Although this option is available to improve fairness under some circumstances, this configuration is less desirable in most instances, for the following reasons:
Any active device, such as a DWZZx, that connects bus segments introduces small delays as signals pass through the device from one segment to another. Under some circumstances, these delays can be another cause of unfair arbitration. For example, consider the following configuration, which could result in disk servicing problems (starvation) under heavy work loads:
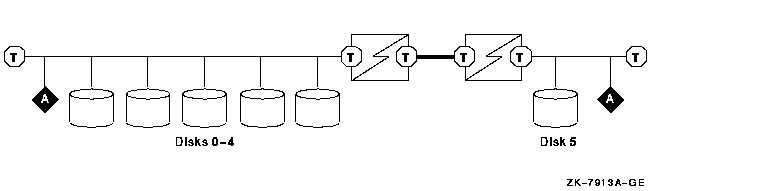
Although disk 5 has the highest ID number, there are some circumstances under which disk 5 has the lowest access to the bus. This can occur after one of the lower-numbered disks has gained control of the bus and then completed the operation for which control of the bus was needed. At this point, disk 5 does not recognize that the bus is free and might wait before trying to arbitrate for control of the bus. As a result, one of the lower-numbered disks, having become aware of the free bus and then submitting a request for the bus, will gain control of the bus.
If you see this type of problem, the following suggestions can help you reduce its severity:
With proper procedures, certain SCSI devices can be removed from or inserted onto an active SCSI bus without disrupting the ongoing operation of the bus. This capability is referred to as hot plugging. Hot plugging can allow a suitably configured OpenVMS Cluster system to continue to run while a failed component is replaced. Without hot plugging, it is necessary to make the SCSI bus inactive and remove power from all the devices on the SCSI bus before any device is removed from it or inserted onto it.
In a SCSI OpenVMS Cluster system, hot plugging requires that all devices on the bus have certain electrical characteristics and be configured appropriately on the SCSI bus. Successful hot plugging also depends on strict adherence to the procedures described in this section. These procedures ensure that the hot-plugged device is inactive and that active bus signals are not disturbed.
This section describes hot-plugging procedures for devices that are on the same SCSI bus as the host that is running OpenVMS. The procedures are different for SCSI buses that are behind a storage controller, such as the HSZxx. Refer to the storage controller documentation for the procedures to hot plug devices that they control. |
The terms shown in bold in this section are used in the discussion of hot plugging rules and procedures.
Follow these rules when planning for and performing hot plugging:
Figure A-13 SCSI Bus Topology
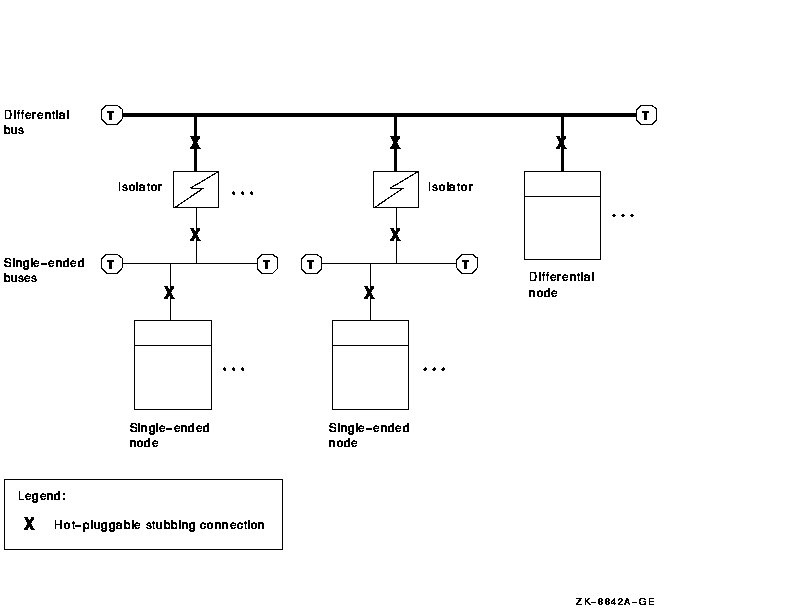
Ideally, a device will also be inactive whenever its power is removed, for the same reason. |
Figure A-14 Hot Plugging a Bus Isolator
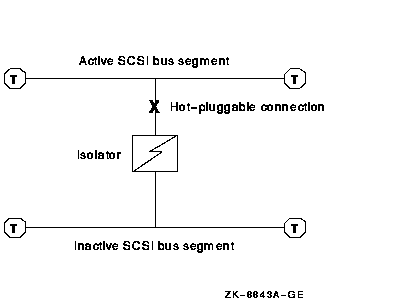
Use the following procedures to ensure that a device or a segment is inactive:
1 Referring to this draft standard is necessary because the SCSI--2 standard does not adequately specify the requirements for hot plugging.2 OpenVMS will eventually detect a hung bus and reset it, but this problem may first temporarily disrupt OpenVMS Cluster operations. |
| Previous | Next | Contents | Index |
|
|
![[OpenVMS documentation]](../../images/openvms_doc_banner_bottom.gif) |
|
Copyright © Compaq Computer Corporation 1998. All rights reserved. Legal |
6318PRO_018.HTML
|