![[OpenVMS documentation]](../../images/openvms_doc_banner_top.gif)
|
![[Site home]](../../images/buttons/bn_site_home_off.gif)
![[Send comments]](../../images/buttons/bn_comments_off.gif)
![[Help with this site]](../../images/buttons/bn_site_help_off.gif)
![[How to order documentation]](../../images/buttons/bn_order_docs_off.gif)
![[OpenVMS site]](../../images/buttons/bn_openvms_off.gif)
![[Compaq site]](../../images/buttons/bn_compaq_off.gif)
|
| Updated: 11 December 1998 |
|
|
|
|
| Updated: 11 December 1998 |
OpenVMS Cluster Systems
| Previous | Contents | Index |
To configure cluster disks, you can create command procedures to mount them. You may want to include commands that mount cluster disks in a separate command procedure file that is invoked by a site-specific SYSTARTUP procedure. Depending on your cluster environment, you can set up your command procedure in either of the following ways:
With either method, each computer can invoke the common procedure from the site-specific SYSTARTUP procedure.
Example:
The MSCPMOUNT.COM file in the SYS$EXAMPLES directory on your system is
a sample command procedure that contains commands typically used to
mount cluster disks. The example includes comments explaining each
phase of the procedure.
6.5.4 Disk Rebuild Operation
To minimize disk I/O operations (and thus improve performance) when files are created or extended, the OpenVMS file system maintains a cache of preallocated file headers and disk blocks.
If a disk is dismounted improperly---for example, if a system fails or
is removed from a cluster without running
SYS$SYSTEM:SHUTDOWN.COM---this preallocated space becomes temporarily
unavailable. When the disk is remounted, MOUNT scans the disk to
recover the space. This is called a disk rebuild
operation.
6.5.5 Rebuilding Cluster Disks
On a nonclustered computer, the MOUNT scan operation for recovering preallocated space merely prolongs the boot process. In an OpenVMS Cluster system, however, this operation can degrade response time for all user processes in the cluster. While the scan is in progress on a particular disk, most activity on that disk is blocked.
Note: User processes that attempt to read or write to files on the disk can experience delays of several minutes or longer, especially if the disk contains a large number of files or has many users.
Because the rebuild operation can delay access to disks during the startup of any OpenVMS Cluster computer, Compaq recommends that procedures for mounting cluster disks use the /NOREBUILD qualifier. When MOUNT/NOREBUILD is specified, disks are not scanned to recover lost space, and users experience minimal delays while computers are mounting disks.
Reference: Section 6.5.6 provides information about
rebuilding system disks. Section 9.5.1 provides more information about
disk rebuilds and system-disk throughput techniques.
6.5.6 Rebuilding System Disks
Rebuilding system disks is especially critical because most system activity requires access to a system disk. When a system disk rebuild is in progress, very little activity is possible on any computer that uses that disk.
Unlike other disks, the system disk is automatically mounted early in the boot sequence. If a rebuild is necessary, and if the value of the system parameter ACP_REBLDSYSD is 1, the system disk is rebuilt during the boot sequence. (The default setting of 1 for the ACP_REBLDSYSD system parameter specifies that the system disk should be rebuilt.) Exceptions are as follows:
| Setting | Comments |
|---|---|
| ACP_REBLDSYSD parameter should be set to 0 on satellites. | This setting prevents satellites from rebuilding a system disk when it is mounted early in the boot sequence and eliminates delays caused by such a rebuild when satellites join the cluster. |
| ACP_REBLDSYSD should be set to the default value of 1 on boot servers, and procedures that mount disks on the boot servers should use the /REBUILD qualifier. | While these measures can make boot server rebooting more noticeable, they ensure that system disk space is available after an unexpected shutdown. |
Once the cluster is up and running, system managers can submit a batch procedure that executes SET VOLUME/REBUILD commands to recover lost disk space. Such procedures can run at a time when users would not be inconvenienced by the blocked access to disks (for example, between midnight and 6 a.m. each day). Because the SET VOLUME/REBUILD command determines whether a rebuild is needed, the procedures can execute the command for each disk that is usually mounted.
Suggestion: The procedures run more quickly and cause less delay in disk access if they are executed on:
Moreover, several such procedures, each of which rebuilds a different set of disks, can be executed simultaneously.
Caution: If either or both of the following conditions are true when mounting disks, it is essential to run a procedure with SET VOLUME/REBUILD commands on a regular basis to rebuild the disks:
Failure to rebuild disk volumes can result in a loss of free space and
in subsequent failures of applications to create or extend files.
6.6 Shadowing Disks Across an OpenVMS Cluster
Volume shadowing (sometimes referred to as disk mirroring) achieves
high data availability by duplicating data on multiple disks. If one
disk fails, the remaining disk or disks can continue to service
application and user I/O requests.
6.6.1 Purpose
Volume Shadowing for OpenVMS software provides data availability across the full range of OpenVMS configurations---from single nodes to large OpenVMS Cluster systems---so you can provide data availabililty where you need it most.
Volume Shadowing for OpenVMS software is an implementation of RAID 1
(redundant arrays of independent disks) technology. Volume Shadowing
for OpenVMS prevents a disk device failure from interrupting system and
application operations. By duplicating data on multiple disks, volume
shadowing transparently prevents your storage subsystems from becoming
a single point of failure because of media deterioration, communication
path failure, or controller or device failure.
6.6.2 Shadow Sets
You can mount one, two, or three compatible disk volumes to form a shadow set, as shown in Figure 6-9. Each disk in the shadow set is known as a shadow set member. Volume Shadowing for OpenVMS logically binds the shadow set devices together and represents them as a single virtual device called a virtual unit. This means that the multiple members of the shadow set, represented by the virtual unit, appear to operating systems and users as a single, highly available disk.
Figure 6-9 Shadow Set With Three Members
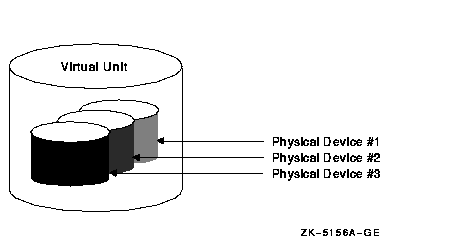
Applications and users read and write data to and from a shadow set using the same commands and program language syntax and semantics that are used for nonshadowed I/O operations. System managers manage and monitor shadow sets using the same commands and utilities they use for nonshadowed disks. The only difference is that access is through the virtual unit, not to individual devices.
Reference: Volume Shadowing for OpenVMS describes the shadowing
product capabilities in detail.
6.6.4 Supported Devices
For a single workstation or a large data center, valid shadowing configurations include:
You can shadow data disks and system disks. Thus, a system disk need not be a single point of failure for any system that boots from that disk. System disk shadowing becomes especially important for OpenVMS Cluster systems that use a common system disk from which multiple computers boot.
There are no restrictions on the location of shadow set members beyond
the valid disk configurations defined in the Volume Shadowing for
OpenVMS Software Product Description (SPD 27.29.xx).
6.6.5 Unsupported Devices
Devices that cannot be shadowed include MicroVAX 2000 RD disks and older disk devices (such as MASSBUS, RK07, RL02).
Volume Shadowing for OpenVMS does not support the shadowing of quorum
disks. This is because volume shadowing makes use of the OpenVMS
distributed lock manager, and the quorum disk must be utilized before
locking is enabled.
6.6.6 Mounting
You can mount a maximum of 250 shadow sets (up to 500 disks) in a
standalone or OpenVMS Cluster system. The number of shadow sets
supported is independent of controller and device types. The shadow
sets can be mounted as public or private volumes. A bound volume set
can be created from several shadow sets. A stripe set can be created
from several shadow sets.
6.6.7 Distributing Shadowed Disks
The controller-independent design of shadowing allows you to manage shadow sets regardless of their controller connection or location in the OpenVMS Cluster system and helps provide improved data availability and very flexible configurations.
For clusterwide shadowing, members can be located anywhere in an OpenVMS Cluster system and served by MSCP servers across any supported OpenVMS Cluster interconnect, including the CI, Ethernet, DSSI, and FDDI. For example, OpenVMS Cluster systems using FDDI can be up to 40 kilometers apart, which further increases the availability and disaster tolerance of a system.
Figure 6-10 shows how shadow set member units are on line to local controllers located on different nodes. In the figure, a disk volume is local to each of the nodes ATABOY and ATAGRL. The MSCP server provides access to the shadow set members over the Ethernet. Even though the disk volumes are local to different nodes, the disks are members of the same shadow set. A member unit that is local to one node can be accessed by the remote node over the MSCP server.
Figure 6-10 Shadow Sets Accessed Through the MSCP Server
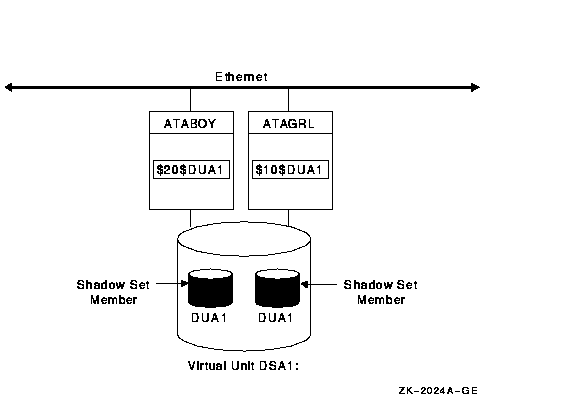
The shadowing software maintains virtual units in a distributed fashion on each node that mounts the shadow set in the OpenVMS Cluster system. Volume shadowing can provide distributed shadowing because the virtual unit is maintained and managed by each node that has the shadow set mounted.
For shadow sets that are mounted on an OpenVMS Cluster system, mounting or dismounting a shadow set on one node in the cluster does not affect applications or user functions executing on other nodes in the system. For example, you can dismount the virtual unit from one node in an OpenVMS Cluster system and leave the shadow set operational on the remaining nodes on which it is mounted.
This chapter discusses queuing topics specific to OpenVMS Cluster systems. Because queues in an OpenVMS Cluster system are established and controlled with the same commands used to manage queues on a standalone computer, the discussions in this chapter assume some knowledge of queue management on a standalone system, as described in the OpenVMS System Manager's Manual.
Note: See the OpenVMS System Manager's Manual for information about
queuing compatibility.
7.1 Introduction
Users can submit jobs to any queue in the OpenVMS Cluster system, regardless of the processor on which the job will actually execute. Generic queues can balance the work load among the available processors.
The system manager can use one or several queue managers to manage batch and print queues for an entire OpenVMS Cluster system. Although a single queue manager is sufficient for most systems, multiple queue managers can be useful for distributing the batch and print work load across nodes in the cluster.
Note: OpenVMS Cluster systems that include both VAX
and Alpha computers must use the queue manager described in this
chapter.
7.2 Controlling Queue Availability
Once the batch and print queue characteristics are set up, the system manager can rely on the distributed queue manager to make queues available across the cluster.
The distributed queue manager prevents the queuing system from being affected when a node enters or leaves the cluster during cluster transitions. The following table describes how the distributed queue manager works.
| WHEN... | THEN... | Comments |
|---|---|---|
| The node on which the queue manager is running leaves the OpenVMS Cluster system | The queue manager automatically fails over to another node. | This failover occurs transparently to users on the system. |
| Nodes are added to the cluster | The queue manager automatically serves the new nodes. | The system manager does not need to enter a command explicitly to start queuing on the new node. |
| The OpenVMS Cluster system reboots | The queuing system automatically restarts by default. | Thus, you do not have to include commands in your startup command procedure for queuing. |
| The operating system automatically restores the queuing system with the parameters defined in the queuing database. | This is because when you start the queuing system, the characteristics you define are stored in a queue database. |
To control queues, the queue manager maintains a clusterwide queue
database that stores information about queues and jobs. Whether you use
one or several queue managers, only one queue database is shared across
the cluster. Keeping the information for all processes in one database
allows jobs submitted from any computer to execute on any queue
(provided that the necessary mass storage devices are accessible).
7.3 Starting a Queue Manager and Creating the Queue Database
You start up a queue manager using the START/QUEUE/MANAGER command as you would on a standalone computer. However, in an OpenVMS Cluster system, you can also provide a failover list and a unique name for the queue manager. The /NEW_VERSION qualifier creates a new queue database.
The following command example shows how to start a queue manager:
$ START/QUEUE/MANAGER/NEW_VERSION/ON=(GEM,STONE,*) |
The following table explains the components of this sample command.
Running multiple queue managers balances the work load by distributing
batch and print jobs across the cluster. For example, you might create
separate queue managers for batch and print queues in clusters with CPU
or memory shortages. This allows the batch queue manager to run on one
node while the print queue manager runs on a different node.
7.4.1 Command Format
To start additional queue managers, include the /ADD and /NAME_OF_MANAGER qualifiers on the START/QUEUE/MANAGER command. Do not specify the /NEW_VERSION qualifier. For example:
$ START/QUEUE/MANAGER/ADD/NAME_OF_MANAGER=BATCH_MANAGER |
Multiple queue managers share one QMAN$MASTER.DAT master file, but an additional queue file and journal file is created for each queue manager. The additional files are named in the following format, respectively:
By default, the queue database and its files are located in
SYS$COMMON:[SYSEXE]. If you want to relocate the queue database files,
refer to the instructions in Section 7.6.
7.5 Stopping the Queuing System
When you enter the STOP/QUEUE/MANAGER/CLUSTER command, the queue manager remains stopped, and requests for queuing are denied until you enter the START/QUEUE/MANAGER command (without the /NEW_VERSION qualifier).
The following command shows how to stop a queue manager named PRINT_MANAGER:
$ STOP/QUEUE/MANAGER/CLUSTER/NAME_OF_MANAGER=PRINT_MANAGER |
Rule: You must include the /CLUSTER qualifier on the
command line whether or not the queue manager is running on an OpenVMS
Cluster system. If you omit the /CLUSTER qualifier, the command stops
all queues on the default node without stopping the queue manager.
(This has the same effect as entering the STOP/QUEUES/ON_NODE command.)
7.6 Moving Queue Database Files
The files in the queue database can be relocated from the default
location of SYS$COMMON:[SYSEXE] to any disk that is mounted clusterwide
or that is accessible to the computers participating in the clusterwide
queue scheme. For example, you can enhance system performance by
locating the database on a shared disk that has a low level of activity.
7.6.1 Location Guidelines
The master file QMAN$MASTER can be in a location separate from the queue and journal files, but the queue and journal files must be kept together in the same directory. The queue and journal files for one queue manager can be separate from those of other queue managers.
The directory you specify must be available to all nodes in the cluster. If the directory specification is a concealed logical name, it must be defined identically in the SYS$COMMON:SYLOGICALS.COM startup command procedure on every node in the cluster.
Reference: The OpenVMS System Manager's Manual contains complete information about creating or relocating the queue database files. See also Section 7.12 for a sample common procedure that sets up an OpenVMS Cluster batch and print system.
| Previous | Next | Contents | Index |
|
|
![[OpenVMS documentation]](../../images/openvms_doc_banner_bottom.gif) |
|
Copyright © Compaq Computer Corporation 1998. All rights reserved. Legal |
4477PRO_011.HTML
|