![[OpenVMS documentation]](../../images/openvms_doc_banner_top.gif)
|
![[Site home]](../../images/buttons/bn_site_home_off.gif)
![[Send comments]](../../images/buttons/bn_comments_off.gif)
![[Help with this site]](../../images/buttons/bn_site_help_off.gif)
![[How to order documentation]](../../images/buttons/bn_order_docs_off.gif)
![[OpenVMS site]](../../images/buttons/bn_openvms_off.gif)
![[Compaq site]](../../images/buttons/bn_compaq_off.gif)
|
| Updated: 11 December 1998 |
|
|
|
|
| Updated: 11 December 1998 |
Guide to OpenVMS File Applications
| Previous | Contents | Index |
Sequential files consist of a file header and a series of data records. Records are stored in the order in which they are written to the file.
The following sections provide guidelines for improving the performance
of sequential file processing using various tuning options.
3.3.1 Block Span Option
You should always specify that records in a sequential file are permitted to span blocks, that is, to cross block boundaries. In this way, RMS can pack the records efficiently and avoid wasted space at the end of a block. Note that you cannot turn off this option for STREAM formatted files.
By default, the FDL editor activates block spanning
for files organized sequentially by setting the RECORD
secondary attribute BLOCK_SPAN to YES. If you are using a low-level
language, you activate the block span option directly in the FAB by
resetting the FAB$V_BLK bit in the FAB$L_RAT field.
3.3.2 Multiblock Size Option
A multiblock is an I/O unit that includes up to 127 blocks but can be used only with sequential files. When a program instructs RMS to fetch data within a multiblock, the entire multiblock is copied from disk to memory.
You specify the number of blocks in a multiblock using the multiblock count, a run-time option. If you are using the FDL editor, specify the multiblock count option using the secondary CONNECT attribute, MULTIBLOCK_COUNT. From a lower-level language, you may set the value into the RAB$B_MBC field, directly. Another alternative is to establish the count using a DCL command of the following form:
SET RMS_DEFAULT/BLOCK_COUNT=n |
The variable n represents the specified number of blocks. Here, the specified multiblock count is limited to your process unless you specify the /SYSTEM qualifier.
In most cases, the largest practical multiblock value to specify is the
number of blocks in one track of the disk, a number that varies with
the various types of disks. (See the OpenVMS I/O User's Reference Manual for the supported
track sizes). However, the most efficient number of blocks for your
application may be more or less than the number of blocks in a track.
You should try various sizes of multiblocks until you find the optimum
value.
3.3.3 Number of Buffers
For sequential files, you can specify the number of buffers at run time. From FDL, you can set the number of buffers with the secondary CONNECT attribute MULTIBUFFER_COUNT. From an assembler language, you can set the value directly into the RAB$B_MBF field in the RAB, or you can set the count using the XAB$_MULTIBUFFER_COUNT XABITM if you want to specify more than 127 buffers. From the DCL interface, you can establish the number of buffers using a DCL command in the following form:
SET RMS_DEFAULT/SEQUENTIAL/DISK/BUFFER_COUNT=n |
The variable n represents the number of buffers.
In simple operations with sequential files, one I/O buffer is sufficient. Increasing the number of buffers uses space in the process working set and could degrade performance.
With nonshared sequential files, particularly if you want to perform sequential access, you can use read-ahead and write-behind processing. With this type of processing, a buffer contains the next record to be read or written to the disk while a separate buffer completes the current I/O operation.
The length of the buffers used for sequential files is determined by
the specified multiblock count. The optimal number of blocks per buffer
depends on the record size for sequential access to a sequential file,
but a value such as 16 may be appropriate.
3.3.4 Global Buffer Option
If a file is shareable, you may want to allocate it global buffers. A global buffer is an I/O buffer that two or more processes can access. If two or more processes are requesting the same information from a file, I/O can be minimized because the data is already in the global buffer. This is especially true for program sequences in which all of the processes are reading data.
For shared sequential file operations, the first accessor of the file uses the multiblock count to establish the global buffer size for all subsequent accessors.
Note that RMS also provides each process with local I/O buffers to
attain efficient buffering capacity.
3.3.5 Read-Ahead and Write-Behind Options
Specifying the read-ahead and write-behind options for sequential files can improve performance. The read-ahead and write-behind options require at least two I/O buffers and the multibuffer attribute. Note that using more than two I/O buffers usually does not improve performance. (See Section 3.3.3.)
Most languages incorporate the read-ahead and write-behind options by default. With some languages, you must specify the read-ahead and write-behind options explicitly using a clause in the language. If a VMS language does not have a clause for specifying the read-ahead and write-behind options, you must use a VAX MACRO routine to select these options when you open the file.
At the VAX MACRO level, you can select these options by setting the RAB$V_RAH bit in the RAB$L_ROP field for read-ahead processing and the RAB$V_WBH bit for write-behind processing prior to requesting the Connect service.
You can also use FDL to select these options by using the secondary
CONNECT attributes READ_AHEAD and WRITE_BEHIND respectively.
3.4 Tuning a Relative File
A relative file consists of a file header, file attributes, a prolog, and a series of fixed-length cells. Each cell contains one record that includes a deleted-record byte followed by the data portion of the record, which may or may not be blank.
RMS assigns each cell a sequential number, called the relative record number, that can be used to randomly access the record.
A relative file can contain fixed-length records, variable-length records, or VFC records. Fixed-length records are particularly useful in relative files because of the fixed cell size.
The maximum size for fixed-length records in a relative file is 32,255
bytes. For variable-length records the maximum size is 32,253 bytes.
The maximum size for VFC records is 32,253 bytes minus the size of the
fixed-length control field, which may be up to 255 bytes long.
3.4.1 Bucket Size
With relative files, buckets are used as the unit of transfer between the disk and memory. You specify bucket size when you create the file, but you can change the size later by converting the file (see Chapter 10.) Note that the Convert utility processes relative files by sequentially reading records from the input file, then writing them to the output file. As a result, the relative record numbers (RRN) change when the input file contains deleted or unused records.
You can specify the bucket size using the FDL FILE secondary attribute BUCKET_SIZE or by inserting the value directly into the RMS control block fields FAB$B_BKS and XAB$B_BKZ. Although the size can be as large as 63 blocks, a bucket size larger than one disk track usually does not improve performance.
If you choose to select the bucket size, you should also consider how your application accesses the file. For random access, you may want to choose a small bucket size; for sequential access, a large bucket size; and for mixed access, a medium bucket size.
One way to improve performance for a relative file is to align the file on a cylinder boundary and specify the size of one disk track as the bucket size. However, this requires that you can perform an exact alignment on the file.
If you use the FDL editor to establish the bucket size (this is recommended), the editor fixes the size at the optimum value based on your script inputs.
If you intend to access the file randomly, EDIT/FDL sets the bucket size equal to four records because it assumes that four records are a reasonable amount of data for a random access. If you intend to access records sequentially, EDIT/FDL sets the bucket size equal to 16 records because it assumes that 16 records is a reasonable amount of data for one sequential access.
If you find that your application needs more data per access, then use
the EDIT/FDL command MODIFY to change the assigned values.
3.4.2 Number of Buffers
The multibuffer count is a run-time option that you can set with the DCL command SET RMS_DEFAULT/RELATIVE/BUFFER_COUNT=n, the FDL attribute CONNECT MULTIBUFFER_COUNT, the RMS control block field RAB$B_MBF or the XAB$_MULTIBUFFER_COUNT XABITM. The type of record access determines the best use of buffers.
The two extremes of record access are when records are processed either completely randomly or completely sequentially. Also, there are cases in which records are accessed randomly but may be reaccessed (random with temporal locality) and cases where records are accessed randomly but adjacent records are likely to be accessed (random with spatial locality).
In completely sequential processing, the first record may be located randomly and the following records accessed sequentially (records are usually not referenced more than once). For best performance, you should specify one buffer with a large bucket size unless you use the read-ahead option, which requires two buffers.
Large buckets hold more records, so you can access a greater number of records before performing I/O operations. However, a small multibuffer count, such as the default of 1 buffer, is sufficient.
When you want to improve sequential access performance, you may get better results by tuning the bucket size rather than changing the number of buffers.
Completely random processing means that records are not accessed again, and adjacent records are not likely to be accessed. You should use one buffer with a minimal bucket size. You do not need to build a memory cache because the records are likely to be scattered throughout the file. New requests for records most likely result in an I/O operation, and caching extra buckets wastes space in your working set.
In random with temporal locality processing (reaccessed records), records are processed randomly, but the same records may be accessed again. You should use multiple small buffers to cache records that are to be reaccessed. The bucket size can be small for this type of access because the records near the record currently accessed are not likely to be accessed. Caching reaccessed records in large buckets wastes space in memory. Multiple buffers allow the previously accessed records to remain in memory for subsequent access.
In random with spatial locality processing (adjacent records), records are processed randomly, but the next or previous record has a good chance of being accessed. You should use a large buffer and bucket size to improve the probability that the next record to be processed is in the same bucket as the record most recently processed. One or two buffers should be sufficient.
If you process your data file with a combination of these patterns, you should compromise between the processing strategies. An application illustrating both temporal and spatial access uses the first record in the file as a pointer to the last record accessed. The program reads the first record to find the location of the next record to be processed, processes the record, and updates the pointer in the first record. Because the application accesses the first record frequently, the access pattern exhibits temporal locality, but because it adds records sequentially to the end of the file, the access pattern also exhibits spatial locality.
When you add records to a relative file, you might consider choosing the deferred write option (FDL attribute FILE DEFERRED_WRITE, FAB$L_FOP field FAB$V_DFW). With this option, the contents of the write buffer are not transferred from memory to disk until the buffer is needed for another purpose or until the file is closed. Note, however, that the possibility of losing data during a system crash increases when you use the deferred write option.
To see what the current default buffer count is, give the DCL command
SHOW RMS_DEFAULT. To set the default buffer count, use the DCL command
SET RMS_DEFAULT/RELATIVE/BUFFER_COUNT=n, where n is the number
of buffers.
3.4.3 Global Buffer Option
If several processes share a relative file, you may want to specify that the file use the global buffer option. A global buffer is an I/O buffer that two or more processes can access. If two or more processes simultaneously request the same information from a file, each process can use the global buffers instead of allocating its own dedicated buffers. Only one copy of the buffers resides at any time in memory, although the buffers are charged against each process's working set size.
Using the global buffer option to form a memory cache may not reduce the number of I/O operations necessary to process the file in all cases. Regardless of how many global buffers you allocate, RMS always allocates one I/O buffer per process, which provides efficient buffering capacity.
If your application has several processes sharing the file and
accessing the same records in a transaction sequence, then you may
benefit from allocating enough global buffers to cache these shared
records.
3.4.4 Deferred-Write Option
The deferred-write option is a run-time option that can improve performance. It is the default operation for some high-level languages and can be specified by clauses in other high-level languages.
If there is no language support, you can use a VAX MACRO subroutine to set the FAB$V_DFW bit in the FAB$L_FOP field before opening the file.
When you select the deferred-write option, RMS delays writing a modified bucket to disk until the buffer is needed for another purpose or until another process needs to use the bucket. This delay improves performance because it reduces the number of disk I/O operations. You achieve the largest performance gains using the deferred-write option with sequential access file operations.
For example, in a relative file with 100-byte records and 2-block buckets, 10 records fit in one bucket. Without the deferred-write option, writing records 1 through 10 in order results in eleven I/O operations---one for the initial file access and one for each of the records.
With the deferred-write option, you need only two I/O operations---one for the initial file access and one to write the bucket.
A larger cache might be useful in situations in which the accesses are
not
strictly sequential but follow some local pattern.
3.5 Tuning an Indexed File
This section discusses the structure of indexed files and ways to
optimize their performance.
3.5.1 File Structure
An indexed file consists of a file header, a prolog, and one or more
index structures. The primary index structure contains the data
records. If the file has alternate keys, it has an alternate index
structure for each alternate key. The alternate index structures
contain secondary index data records (SIDRs) that provide pointers to
the data records in the primary index structure. The index structures
also contain the values of the keys by which RMS accesses the records
in the indexed file.
3.5.1.1 Prologs
RMS places information concerning file attributes, key descriptors, and area descriptors in the prolog. You can examine the prolog with the Analyze/RMS_File utility described in Chapter 10.
There are three types of prologs: Prolog 1, Prolog 2, and Prolog 3.
Any indexed file created with a version of the operating system lower than Version 3.0 is either a Prolog 1 file or a Prolog 2 file. Prolog 1 files and Prolog 2 files operate identically.
If an indexed file uses only string data-type keys, the file is a Prolog 1 file.
The string data-type keys include STRING, DSTRING, COLLATED, and DCOLLATED keys. |
You cannot use the Convert/Reclaim utility on a Prolog 1 file or a Prolog 2 file to reclaim empty buckets. If your file undergoes a large number of deletions (resulting in empty, unusable buckets), you must use the Convert utility (CONVERT) to reorganize the file. (Note that CONVERT establishes new RFAs for the records.)
The compression allowed with Prolog 3 files is not possible with Prolog 1 or Prolog 2 files.
Prolog 3 files can accept multiple (or alternate) keys and all data types (including the nonstring 8-byte BIN8 and INT8 types). They also give you the option of saving space by compressing your data, indexes, and keys.
Key compression compresses the key values in the data buckets. Likewise, index compression compresses the key values in index buckets, and data compression compresses the data portion of the records in the data buckets.
Key or index compression is restricted to the string key data type and the string must be at least 6 bytes in length.
You cannot use key compression or index compression with any numeric or collated key data types. |
With rear key compression, any repeating characters at the end of the key are compressed to a single character. For instance, the key JOHNSON00000 appears as JOHNSON0.
Enabling index compression results in RMS doing a sequential search in index buckets rather than its default binary search, since each index key value must be expanded until a match is found.
With data compression, RMS can compress sequences of up to 255 repeating characters in the data portion of the user data records. For optimal performance, RMS does not compress sequences having less than five repeating characters.
Compression has a direct effect on CPU time and disk space. Compression increases CPU time, but the keys are smaller, so your application can scan more quickly through the data and index buckets.
The disk space saved by using Prolog 3 indexed files can significantly improve performance. With compression, each I/O buffer can hold more information to improve buffer space efficiency. Compression can also decrease the number of index levels, which decreases the number of I/O operations per random access.
Prolog 3 files can have segmented primary keys, but the segments cannot overlap. If you want to use a Prolog 3 file in this case, consider defining the overlapping segmented key as an alternate key and choosing a different key to be the primary key. If you want to use overlapping primary key segments, you must use a Prolog 2 file.
If record deletions result in empty buckets in Prolog 3 files, you can use the Convert/Reclaim utility to make the buckets usable again. Because CONVERT/RECLAIM does not create a new file, RFAs remain the same.
Note that RMS--11 does not support Prolog 3 files. To use a Prolog 3
file with RMS--11 you must first use the Convert utility to transform
the file into a Prolog 1 file or into a Prolog 2 file.
3.5.1.2 Primary Index Structure
The primary index structure consists of the file's data records and a key pathway based on the primary key (key 0). The base of a primary index structure is the data records themselves, arranged sequentially according to the primary key value. The data records are called level 0 of the index structure.
The data records are grouped into buckets, which is the I/O unit for indexed files. Because the records are arranged according to their primary key values, no other record in the bucket has a higher key value than the last record in that bucket. This high key value, along with a pointer to the data bucket, is copied to an index record on the next level of the index structure, known as level 1.
The index records are also placed in buckets. The last index record in a bucket itself has the high key value for its bucket; this high key value is then copied to an index record on the next higher level. This process continues until all of the index records on a level fit into one bucket. This level is then known as the root level for that index structure.
Figure 3-1 is a diagram of an index structure.
Figure 3-2 illustrates a primary index structure. (For simplicity,
the records are assumed to be uncompressed, and the contents of the
data records are not shown.) The records are 132 bytes long (including
overhead), with a primary key field of 6 bytes. Bucket size is one
block, which means that each bucket on Level 0 can contain three
records. You calculate the number of records per bucket as shown by the
following algorithm:
Block Size-Bytes of Overhead Record Size
(Including Overhead)
= Records Per Bucket
Substituting
the values in this instance:
512-15 132
= 3.77
Note that you must round the result down to the next lower integer, in this case, the integer 3.
Figure 3-1 RMS Index Structure
 Because the key size is small and the database in this example consists
of only 27 records, the index records can all fit in one bucket on
level 1. The index records in this example are 6 bytes long. Each index
record has one byte of control information. In this example, the size
of the pointers is 2 bytes per index record, for a total index record
size of 9 bytes. You calculate the number of records per bucket in this
case as follows:
Because the key size is small and the database in this example consists
of only 27 records, the index records can all fit in one bucket on
level 1. The index records in this example are 6 bytes long. Each index
record has one byte of control information. In this example, the size
of the pointers is 2 bytes per index record, for a total index record
size of 9 bytes. You calculate the number of records per bucket in this
case as follows: Figure 3-2 Primary Index Structure
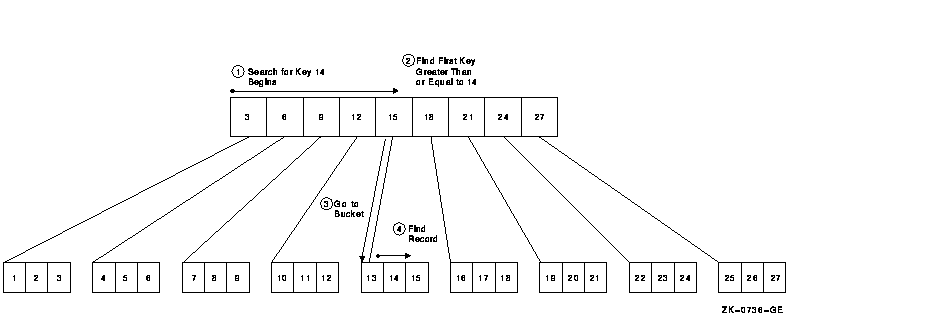
 To read the record with the primary key 14, RMS begins by scanning the
root level bucket, looking for the first index record with a key value
greater than or equal to 14. This record is the index record with key
15. The index record contains a pointer to the level 0 data bucket that
contains the records with the keys 13, 14, and 15. Scanning that
bucket, RMS finds the record (see Figure 3-3).
To read the record with the primary key 14, RMS begins by scanning the
root level bucket, looking for the first index record with a key value
greater than or equal to 14. This record is the index record with key
15. The index record contains a pointer to the level 0 data bucket that
contains the records with the keys 13, 14, and 15. Scanning that
bucket, RMS finds the record (see Figure 3-3).
Figure 3-3 Finding the Record with Key 14
| Previous | Next | Contents | Index |
|
|
![[OpenVMS documentation]](../../images/openvms_doc_banner_bottom.gif) |
|
Copyright © Compaq Computer Corporation 1998. All rights reserved. Legal |
4506PRO_008.HTML
|