![[OpenVMS documentation]](../../images/openvms_doc_banner_top.gif)
|
![[Site home]](../../images/buttons/bn_site_home_off.gif)
![[Send comments]](../../images/buttons/bn_comments_off.gif)
![[Help with this site]](../../images/buttons/bn_site_help_off.gif)
![[How to order documentation]](../../images/buttons/bn_order_docs_off.gif)
![[OpenVMS site]](../../images/buttons/bn_openvms_off.gif)
![[Compaq site]](../../images/buttons/bn_compaq_off.gif)
|
| Updated: 11 December 1998 |
|
|
|
|
| Updated: 11 December 1998 |
Guide to OpenVMS File Applications
| Previous | Contents | Index |
To maintain your files properly, you must occasionally tune them. Tuning involves adjusting and readjusting the characteristics of the file, generally to make the file run faster or more efficiently, and then reorganizing the file to reflect those changes.
There are two ways to tune files. You can redesign your FDL file to change file characteristics or parameters. You can change these characteristics either interactively with the Edit/FDL utility (the preferred method) or by using a text editor. With the redesigned FDL file, then, you can create a new data file.
You can also optimize your data file by using ANALYZE/RMS_FILE with the /FDL qualifier. This method, rather than actually redesigning your FDL file, produces an FDL file containing certain statistics about the file's use that you can then use to tune your existing data file.
Figure 10-8 shows how to use the RMS utilities to perform the tuning cycle.
Figure 10-8 RMS Tuning Cycle
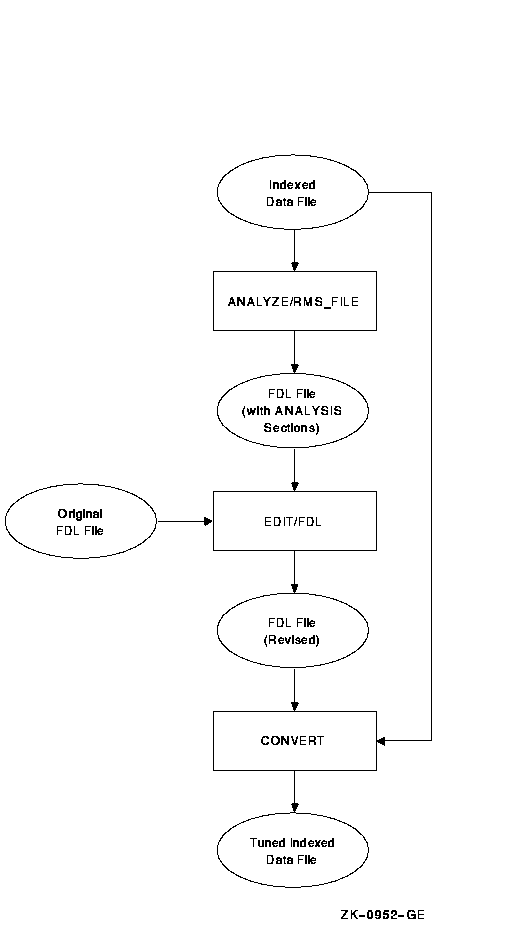
Section 10.3.1 describes how to redesign an FDL file, and Section 10.3.2
explains how to optimize the run-time performance of a data file.
10.3.1 Redesigning an FDL File
There are many ways to redesign an FDL file. If you want to make small changes, you can use the ADD, DELETE, and MODIFY commands at the main menu (main editor) level.
| Command | Function |
|---|---|
| ADD |
Allows you to add one or more new lines to the FDL file. When you give
the ADD command at the main menu level, the Edit/FDL utility prompts
you with a menu displaying all legal primary attributes; your FDL file
does not necessarily have to contain all these attributes. You can add
a new primary attribute to your file, or you can add a new secondary
attribute to an existing primary attribute.
When you type in a primary attribute, the Edit/FDL utility displays all the legal secondary attributes for that primary attribute with their possible values. You can then select the secondary attribute that you want to add to your FDL file and supply the appropriate value for the secondary attribute. |
| DELETE |
Allows you to delete one or more lines from the FDL file. When you give
the DELETE command at the main menu level, the Edit/FDL utility prompts
you with a menu displaying the current primary attributes of your FDL
file.
When you select the primary attribute for the attribute you want to remove from your FDL definition, the Edit/FDL utility displays the current values for all of the FDL file's secondary attributes. When you select the appropriate secondary from this list, the Edit/FDL utility removes it from the FDL definition. If you delete all of the secondary attributes of a primary attribute, the Edit/FDL utility removes the primary attribute from the current definition. |
| MODIFY |
Allows you to change an existing line in the FDL definition. When you
issue the MODIFY command at the main menu level, the Edit/FDL utility
prompts you with a menu displaying the current primary attributes of
your FDL file.
When you type in a primary attribute, the Edit/FDL utility displays all the existing secondary attributes for that primary attribute with their current values. You can then select the secondary attribute of which you want to change the value and then supply the appropriate value for the secondary attribute. |
However, if you want to make substantial changes to an FDL file, you should invoke the Touch-up script. Because sequential and relative files are simple in design, the Touch-up script works only with FDL files that describe indexed files. If you want to redesign sequential and relative files, you can use the command listed above (ADD, DELETE, or MODIFY), or you can go through the design phase again, using the scripts for those organizations.
To completely redesign an existing FDL file that describes an indexed sequential file, use the following command syntax:
EDIT/FDL/SCRIPT=TOUCHUP fdl-filespec |
To improve the performance of a data file, use a 3-step procedure that includes analysis, FDL optimization, and conversion of the file. If used periodically during the life of a data file, this procedure yields a file that performs optimally.
For the analysis, use the ANALYZE/RMS_FILE/FDL command to create an output file (analysis-fdl-file) that reflects the current state of the data file. The command syntax for creating the analysis-fdl-file follows:
ANALYZE/RMS_FILE/FDL/OUTPUT=analysis-fdl-file original-data-file |
The output file analysis-fdl-file contains all of the information and statistics about the data file, including create-time attributes and information that reflects changes made to the structure and contents of the data file over its life.
For FDL optimization, use the Edit/FDL utility to produce an optimized output file (optimized-fdl-file). You can do this by modifying either the orginal FDL file (original-fdl-file) if available, or the FDL output of the file analysis analysis-fdl-file.
Modification of an FDL file can be performed either interactively using a terminal dialogue or noninteractively by allowing the Edit/FDL utility to calculate optimal values based on analysis information.
To optimize the file interactively using an OPTIMIZE script, use a command with the following format:
EDIT/FDL/ANALYSIS=analysis-fdl-file/SCRIPT=OPTIMIZE-
/OUTPUT=optimized-fdl-file original-fdl-file To optimize the file
noninteractively, use a command with the following format:
EDIT/FDL/ANALYSIS=analysis-fdl-file/NOINTERACTIVE-
/OUTPUT=optimized-fdl-file original-fdl-file The
optimized-fdl-file parameter is the optimized version
of the original FDL file.
Conversion is the process of applying the optimized FDL file to the original data file. You use the Convert utility to do this using a command with the following syntax:
CONVERT/FDL=optimized-fdl-file original-data-file new-data-file |
If your file has been used for some time or if it is extremely volatile, the numerous deletions and insertions of records may have caused the optimal design of the file to deteriorate. For example, numerous extensions will degrade performance by causing window-turn operations. In indexed files, deletions can cause empty but unusable buckets to accumulate.
If additions or insertions to a file cause too many extensions, the file's performance will also deteriorate. To improve performance, you could increase the file's window size, but this uses an expensive system resource and at some point may itself hurt performance. A better method is to make the file contiguous again.
This section presents techniques for cleaning up your files. These
techniques include using the Copy utility, the Convert utility, and the
Convert/Reclaim utility.
10.4.1 Using the Copy Utility
You can use the COPY command with the /CONTIGUOUS qualifier to copy the file, creating a new contiguous version. The /CONTIGUOUS qualifier can be used only on an output file.
To use the COPY command with the /CONTIGUOUS qualifier, use the following command syntax:
COPY input-filespec output-filespec/CONTIGUOUS |
If you do not want to rename the file, use the same name for input-filespec and output-filespec.
By default, if the input file is contiguous, COPY likewise tries to create a contiguous output file. By using the /CONTIGUOUS qualifier, you ensure that the output file is copied to consecutive physical disk blocks.
The /CONTIGUOUS qualifier can only be used when you copy disk files; it
does not apply to tape files. For more information, see the COPY
command in the OpenVMS DCL Dictionary.
10.4.2 Using the Convert Utility
The Convert utility can also make a file contiguous if contiguity is an original attribute of the file.
To use the Convert utility to make a file contiguous, use the following command syntax:
CONVERT input-filespec output-filespec |
If you do not want to rename the file, use the same name for
input-filespec and output-filespec.
10.4.3 Reclaiming Buckets in Prolog 3 Files
If you delete a number of records from a Prolog 3 indexed file, it is possible that you deleted all of the data entries in a particular bucket. RMS generally cannot use such empty buckets to write new records.
With Prolog 3 indexed files, you can reclaim such buckets by using the Convert/Reclaim utility. This utility allows you to reclaim the buckets without incurring the overhead of reorganizing the file with CONVERT.
As the data buckets are reclaimed, the pointers to them in the index buckets are deleted. If as a result any of the index buckets become empty, they too are reclaimed.
Note that RFA access is retained after bucket reclamation. The only effect that CONVERT/RECLAIM has on a Prolog 3 indexed file is that empty buckets are reclaimed.
To use CONVERT/RECLAIM, use the following command syntax, in which filespec specifies a Prolog 3 indexed file:
CONVERT/RECLAIM filespec |
Please note that the file cannot be open for shared access at the time
that you give the CONVERT/RECLAIM command.
10.5 Reorganizing a File
Using the Convert utility is the easiest way to reorganize a file. In addition, CONVERT cleans up split buckets in indexed files. Also, because the file is completely reorganized, buckets in which all the records were deleted will disappear. (Note that this is not the same as bucket reclamation. With CONVERT, the file becomes a new file and records receive new RFAs.)
To use the Convert utility to reorganize a file, use the following command syntax:
CONVERT input-filespec output-filespec |
If you do not want to rename the file, use the same name for
input-filespec and output-filespec.
10.6 Making Archive Copies
Another part of maintaining files is making sure that you protect the data in them. You should keep duplicates of your files in another place in case something happens to the originals. In other words, you need to back up your files. Then, if something does happen to your original data, you can restore the duplicate files.
The Backup utility (BACKUP) allows you to create backup copies of files and directories, and to restore them as well. These backup copies are called save sets, and they can reside on either disk or magnetic tape. Save sets are also written in BACKUP format; only BACKUP can interpret the data.
Unlike the DCL command COPY, which makes new copies of files (updating the revision dates and assigning protection from the defaults that apply), BACKUP makes copies that are identical in all respects to the originals, including dates and protection.
To use the Backup utility to create a save set of your file, use the following command syntax:
BACKUP input-filespec output-filespec[/SAVE_SET] |
You have to use the /SAVE_SET qualifier only if the output file will be backed up to disk. You can omit the qualifier for magnetic tape.
For more information about BACKUP, see the description of the Backup utility in the OpenVMS System Management Utilities Reference Manual.
This appendix lists the algorithms used by the Edit/FDL utility to
determine the optimum values for file attributes.
A.1 Allocation
For sequential files with block spanning, the Edit/FDL utility allocates enough blocks to hold the specified number of records of mean size. If you do not allow block spanning, the Edit/FDL utility factors in the potential wasted space at the end of each block.
For relative files, the Edit/FDL utility calculates the total number of buckets in the file and then allocates enough blocks to hold the required number of buckets and associated overhead. The Edit/FDL utility calculates the total number of buckets by dividing the total number of records in the file by the bucket record capacity. The overhead consists of the prolog which is equal to one block and is stored in VBN 1.
For indexed files, the Edit/FDL utility calculates the depth to determine the actual bucket size and number of buckets at each level of the index. It then allocates enough blocks to hold the required number of buckets. Areas for the data level (Level 0) have separate allocations from the areas for the index levels of each key.
In all cases, allocations are rounded up to a multiple of bucket size.
A.2 Extension Size
For sequential files, the Edit/FDL utility sets the extension size to
one-tenth of the allocation size and truncates any fraction. For
relative files and indexed files, the Edit/FDL utility extends the file
by 25 percent rounded up to the next multiple of the bucket size.
A.3 Bucket Size
Because most records that the Edit/FDL utility accesses are close to each other, it makes the buckets large enough to hold 16 records or the total record capacity of the file, whichever is smaller. The maximum bucket size is 63 blocks.
For indexed files, the Edit/FDL utility permits you to decide the bucket size for any particular index. The data and index levels get the same bucket size but you can use the MODIFY command to change these values.
The Edit/FDL utility calculates the default bucket size by first finding the most common index depth produced by the various bucket sizes. If you specify smaller buffers rather than fewer levels, the Edit/FDL utility establishes the default bucket size as the smallest size needed to produce the most common depth. On Surface_Plot graphs, these values are shown on the leftmost edge of each bucket size.
If you specify a separate bucket size for the Level 1 index, it should match the bucket size assigned to the rest of the index. |
The bucket size is always a multiple of disk cluster size. The
ANALYZE/RMS_FILE primary attribute ANALYSIS_OF_KEY now has a new
secondary attribute called LEVEL1_RECORD_COUNT that represents the
index level immediately above the data. It makes the tuning algorithm
more accurate when duplicate key values are specified.
A.4 Global Buffers
The global buffer count is the number of I/O buffers that two or more
processes can access. This algorithm tries to cache or "map"
the whole Key 0 index (at least up to a point) into memory for quicker
and more efficient access.
A.5 Index Depth
The indexed design routines simulate the loading of data buckets with records based on your data regarding key sizes, key positions, record sizes (mean and maximum), compression values, load method, and fill factors.
When the Edit/FDL utility finds the number of required data buckets, it can determine the actual number of index records in the next level up (each of which points to a data bucket). The process is repeated until all the required index records for a level can fit in one bucket, the root bucket. When a file exceeds 32 levels, the Edit/FDL utility issues an error message.
With a line_plot, the design calculations are performed up to 63 times---once for each legal bucket size. With a surface_plot, each line of the plot is equivalent to a line_plot with a different value for the variable on the Y-axis.
This glossary defines terms used in this manual.
accessor: A process that accesses a file or a record
stream that accesses a record.
alternate key: An optional key within the data records
in an indexed file; used by RMS to build an alternate index. See also
key (indexed file) and primary key.
area: Areas are RMS-maintained regions of an indexed
file. They allow you to specify placement or specific bucket sizes, or
both, for particular portions of a file. An area consists of any number
of buckets, and there may be from 1 to 255 areas in a file.
asynchronous record operation: An operation in which
your program may possibly regain control before the completion of a
record retrieval or storage request. Completion ASTs and the Wait
service are the mechanisms provided by RMS for programs to synchronize
with asynchronous record operations. See also synchronous record
operation.
bits per inch: The recording density of a magnetic
tape. Indicates how many characters can fit on one inch of the
recording surface. See also density.
block: The smallest number of consecutive bytes that
RMS transfers during read and write operations. A block is 512 8-bit
bytes on a Files--11 On-Disk Structure disk; on magnetic tape, a block
may be anywhere from 8 to 8192 bytes.
block I/O: The set of RMS procedures that allows you
direct access to the blocks of a file regardless of file organization.
block spanning: In a sequential file, the option for
records to cross block boundaries.
bootstrap block: A block in the index file of a system
disk. Can contain a program that loads the operating system into memory.
bucket: A storage structure, consisting of 1 to 32
blocks, used for building and processing relative and indexed files. A
bucket contains one or more records or record cells. Buckets are the
units of contiguous transfer between RMS buffers and the disk.
bucket split: The result of inserting records into a
full bucket. To minimize bucket splits, RMS attempts to keep half of
the records in the original bucket and transfer the remaining records
to a newly created bucket.
buffer: A memory area used to temporarily store data.
Buffers are generally categorized as being either user buffers or I/O
buffers.
cluster: The basic unit of space allocation on a
Files--11 On-Disk Structure volume. Consists of one or more contiguous
blocks, with the number being specified when the volume is initialized.
contiguous area: A group of physically adjacent blocks.
count field: A 2-byte field prefixed to a
variable-length record that specifies the number of data bytes in the
record. This field may be formatted in either LSB or MSB format.
cylinder: The tracks at the same radius on all
recording surfaces of a disk.
density: The number of bits per inch (bpi) of magnetic
tape. Typical values are 800 bpi and 1600 bpi. See also bits per
inch.
directory: A file used to locate files on a volume. A
directory file contains a list of files and their unique internal
identifications.
directory tree: The subdirectories created beneath a
directory and the subdirectories within the subdirectories (and so
forth).
disk: See volume (disk).
extent: One or more adjacent clusters allocated to a
file or to a portion of a file.
FDL: See File Definition Language.
file: An organized collection of related items
(records) maintained in an accessible storage area, such as disk or
tape.
File Definition Language: A special-purpose language
used to write file creation and run-time specifications for data files.
These specifications are written in text files called FDL files; they
are then used by the RMS utilities and library routines to create the
actual data files.
file header: A block in the index file describing a
file on a Files--11 On-Disk Structure disk, including the location of
the file's extents. There is at least one file header for every file on
the disk.
file organization: The physical arrangement of data in
the file. You select the specific organization from those offered by
RMS, based on your individual needs for efficient data storage and
retrieval. See also indexed file organization, relative
file organization, and sequential file organization.
Files--11 On-Disk Structure: The standard physical
disk structure used by RMS.
fixed-length control field: A fixed-size area,
prefixed to a VFC record, containing additional information that can be
processed separately and that may have no direct relationship to the
other contents of the record. For example, the fixed-length control
field might contain line sequence numbers for use in editing operations.
fixed-length record format: Property of a file in
which all records are the same length. This format provides simplicity
in determining the exact location of a record in the file and
eliminates the need to prefix a record size field to each record.
global buffer: A buffer that many processes share.
home block: A block in the index file, normally next
to the bootstrap block, that identifies the volume as a Files--11
On-Disk Structure volume and provides specific information about the
volume, such as volume label and protection.
index: The structure that allows retrieval of records
in an indexed file by key value. See also key (indexed file).
index file: A file on each Files--11 On-Disk Structure
volume that provides the means for identification and initial access to
the volume. Contains the access information for all files (including
itself) on the volume: bootstrap block, home block, file headers.
indexed file organization: A file organization that
allows random retrieval of records by key value and sequential
retrieval of records in sorted order by key value. See also key
(indexed file).
interrecord gap (IRG): An interval of blank space
between data records on the recording surface of a magnetic tape. The
IRG enables the tape unit to decelerate, stop if necessary, and
accelerate between record operations.
I/O buffer: A buffer used for performing input/output
operations.
IRG: See interrecord gap.
key (indexed file): A character string, a packed
decimal number, a 2- or 4-byte unsigned binary number, or a 2- or
4-byte signed integer within each data record in an indexed file. You
define the length and location within the records; RMS uses the key to
build an index. See also primary key, alternate key,
and random access by key value.
key (relative file): The relative record number of
each data record cell in a data file; RMS uses the relative record
numbers to identify and access data records in a relative file in
random access mode. See also relative record number.
local buffer: A buffer that is dedicated to one
process.
locate mode: Technique used for a record input
operation in which the data records are not copied from the I/O buffer,
but a pointer is returned to the record in the I/O buffer. See also
move mode.
move mode: Technique used for a record transfer in
which the data records are copied between the I/O buffer and your
program buffer for calculations or operations on the record. See also
locate mode.
multiblock: An I/O unit that includes up to 127
blocks. Use is restricted to sequential files.
multiple-extent file: A disk file having two or more
extents.
native mode: The processor's primary execution mode in
which the programmed instructions are interpreted as byte-aligned,
variable-length instructions that operate on the following data types:
byte, word, longword, and quadword integers; floating and double
floating character strings; packed decimals; and variable-length bit
fields. The other instruction execution mode is compatibility mode.
OpenVMS RMS: See RMS (Record Management
Services).
primary key: The mandatory key within the data records
of an indexed file; used to determine the placement of records within
the file and to build the primary index. See also key (indexed
file) and alternate key.
random access by key (indexed file): Retrieval of a
data record in an indexed file by either a primary or alternate key
within the data record. See also key (indexed file).
random access by key (relative file): Retrieval of a
data record in a relative file by the relative record number of the
record. See also key (relative files).
random access by record file address (RFA): Retrieval
of a record by the record's unique address, which RMS returns to you.
This record access mode is the only means of randomly accessing a
sequential file containing variable-length records.
random access by relative record number: Retrieval of
a record by its relative record number. For relative files and
sequential files (on disk devices) that contain fixed-length records,
random access by relative record number is synonymous with random
access by key. See also random access by key (relative files
only) and relative record number.
| Previous | Next | Contents | Index |
|
|
![[OpenVMS documentation]](../../images/openvms_doc_banner_bottom.gif) |
|
Copyright © Compaq Computer Corporation 1998. All rights reserved. Legal |
4506PRO_028.HTML
|