![[OpenVMS documentation]](../../images/openvms_doc_banner_top.gif)
|
![[Site home]](../../images/buttons/bn_site_home_off.gif)
![[Send comments]](../../images/buttons/bn_comments_off.gif)
![[Help with this site]](../../images/buttons/bn_site_help_off.gif)
![[How to order documentation]](../../images/buttons/bn_order_docs_off.gif)
![[OpenVMS site]](../../images/buttons/bn_openvms_off.gif)
![[Compaq site]](../../images/buttons/bn_compaq_off.gif)
|
| Updated: 11 December 1998 |
|
|
|
|
| Updated: 11 December 1998 |
Guide to OpenVMS File Applications
| Previous | Contents | Index |
To sequentially retrieve indexed records, your program must specify the key for the first access. RMS then uses the index for that key to retrieve successive records. For example, assume an index file with three records, having primary keys of A, B, and C, respectively. To retrieve these records sequentially in ascending sort order, your program must provide the key A on the first access; RMS accesses the next two records without further key inputs from your program.
To randomly retrieve records in an index file, your program must
provide the appropriate key value for each access. Now assume an index
file with three records having primary keys A, B, and C that are
retrieved in C, A, B order. On the first access, your program must
provide the key C, on the next access the key A, and
on the final access the key B.
2.2.3.2 Index Keys
In an indexed file, each record includes one or more key fields (or simply keys) that RMS uses to build related indexes. Each key is identified by its location, its length, and whether it is a simple or a segmented key.
A simple key may be any one of the following data types:
RMS--11 cannot process 8-byte numeric keys. |
For an indexed file, you must define at least one key, the primary key,
and you can optionally define one or more alternate keys. RMS uses
alternate keys to build indexes that identify records in alternate sort
orders. As with the primary key, each alternate key is defined by
location and length.
2.2.3.3 Other Key Characteristics
In addition to defining keys, you can specify various key characteristics (FDL secondary key attributes) including the following:
| Duplicate keys | This characteristic permits you to use the key value in more than one record. However, only the first record having the key value can be accessed randomly; other records having the same key value can be accessed only sequentially. |
| Changeable keys | This characteristic applies to alternate keys only. When you specify changeable alternate keys, the alternate keys in a record can be changed when the record is updated. When an alternate key value changes, RMS automatically adjusts the appropriate index to reflect the new key value. |
| Null keys | This characteristic applies to alternate keys only. When you fill an alternate key field with null characters, RMS does not insert the record in the related index. |
RMS excludes from the related index any record not long enough to contain a complete alternate key. |
Key characteristics can be defined separately for each key.
When you do not allow duplicate key values, RMS rejects any attempt to put a record into a file if it contains a key value that duplicates a key value already present in another record. Similarly, when alternate key values cannot be changed, RMS does not allow your program to update a record by changing the alternate key value. If you disallow a null value for a key, RMS inserts an entry for the record in the associated alternate index.
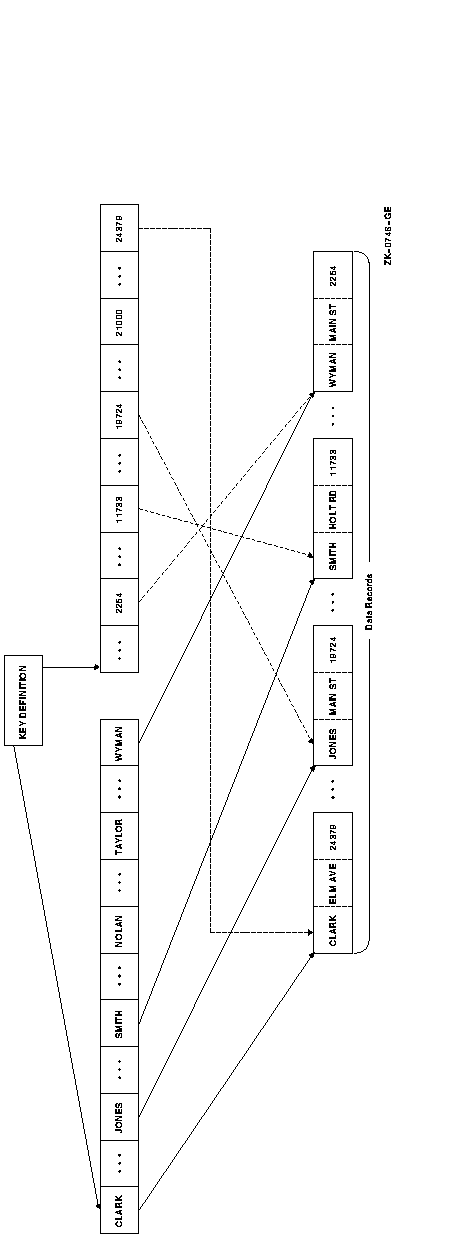
Figure 2-12 illustrates the general structure of an indexed file containing only a primary key: the employee name in an employment record file. Figure 2-13 illustrates the general structure of an indexed file in which the primary key and one alternate key are defined. The primary key is the name of the employee; the alternate key is the employee badge number in an employment record file.
Figure 2-12 Single-Key Indexed File Organization
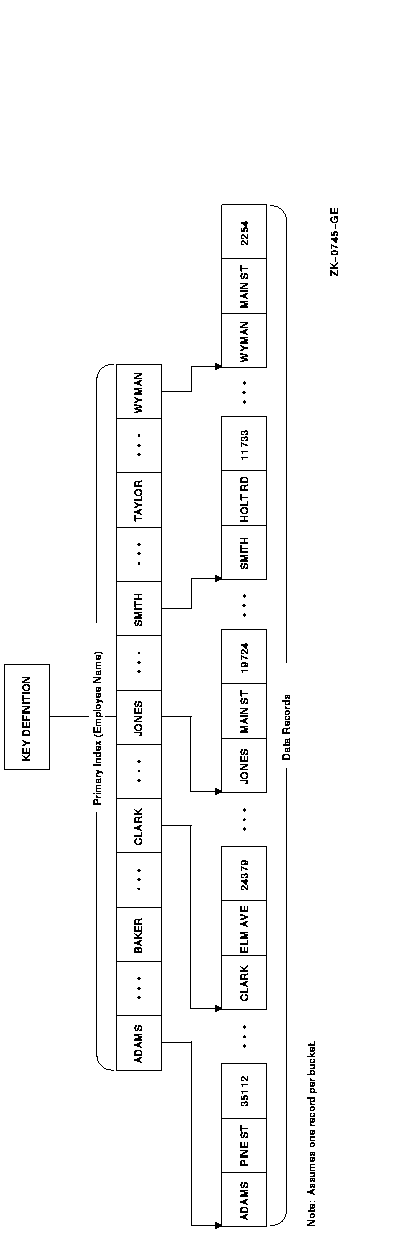
Figure 2-13 Multiple-Key Indexed File Organization
RMS lets you specify either ascending sort order or descending sort order for each key. At the VAX MACRO level, you encode sort order within the key data type field (XAB$B_DTP) of the associated key XAB; you use the attribute KEY TYPE at the FDL level. For example, if you want to build an index of string data type keys in ascending sort order using VAX MACRO, you enter the following line in the associated key XAB:
DTP = STG |
To build an index of string data type keys in descending sort order, you enter this line in the associated key XAB:
DTP = DSTG |
See the OpenVMS Record Management Services Reference Manual for a complete listing of key data types used to
specify ascending and descending sort order.
2.2.3.5 Using Collated Keys
The RMS multinational key feature lets you assign alternative (non-ASCII) collating sequences to a key. For example, a program can sort records using a key that accesses a collating sequence based on French or alternatively accesses a collating sequence based on Spanish.
The basis for this feature is the National Character Set utility (NCS). When an application program creates an index file with an alternative collating sequence, it calls NCS. NCS responds by retrieving the collating sequence from the NCS library, storing it in local memory and providing the calling program with a pointer to it. In addition to naming the collating sequence, the calling program must provide NCS with a location for storing the pointer (CS_ID) to the memory location of the collating sequence. (For information about NCS, see the OpenVMS National Character Set Utility Manual.)
When the application program creates the data file, it uses the pointer to copy the collating sequence from local memory into the data file's prolog space. A collating sequence is typically 1 block long.
The application program may specify a collated key from either the RMS interface or the FDL interface.
From the RMS interface, the application program identifies the collating sequence using an appropriate string descriptor and includes a symbolic reference to the location of the pointer. As with all other keys, the application program may specify either ascending or descending sort order. From the RMS interface, you specify the key data type COL for an ascending sort order or the key data type DCOL for descending sort order.
From FDL, you specify a collated key by selecting one of the collated key data types (collated for ascending sort order, decollated for descending sort order) from the INDEXED file script. FDL responds by prompting for the name of the collating sequence. If you enter an invalid collating sequence, any attempt to use the FDL file for creating a data file will be unsuccessful, and NCS generates the following error message:
%NCS-F-NOT_CS, name or id is not a CS |
| Example 2-1 Creating a File Containing Collated Keys |
|---|
.
.
.
.TITLE Example
;
; Define key type as COL or DCOL
;
KEY0: $XABKEY
.
.
.
DTP=COL
;
; Descriptor for collating sequence name
;
CS_DESC: .ASCID /Spanish/
.EXTRN NCS$GET_CS
.
.
.
; Collating sequence name descriptor
;
PUSHAL CS_DESC
;
; Where to store address of collating sequence
;
PUSHAL KEY0+XAB$L_COLTBL
;
; Fetch collating sequence
;
CALLS #2,G^NCS$GET_CS
BLBC R0,ERROR
;
; Create file
;
$CREATE FAB=OUTFAB
BLBC R0,ERROR
|
Some advantages and disadvantages of the indexed file organization are outlined in Table 2-5.
| Advantages | Disadvantages |
|---|---|
| Most flexible random access: by any one of multiple keys or RFA; key access by generic or approximate value | Highest overhead on disk and in memory |
| Duplicate key values possible | Restricted to disk |
| Automatic sort of records by primary and alternate keys; available during sequential access | Most complex programming |
| Record location is transparent to user | Longest record access times |
| Potential range of key values not physically present as in relative file organization | |
| Variety of data formats for keys | |
| Transparent data compression |
When you design a file, your decisions regarding record access mode,
record format, and file organization should be aimed at achieving
optimum data processing performance for your application. This chapter
discusses general performance considerations and specific trade-offs
you can make in the design of your data files. In Section 3.3,
Section 3.4, and Section 3.5, these trade-offs are discussed in the
contexts of the three file organizations: sequential, relative, and
indexed.
3.1 Design Considerations
In designing files for optimum data processing performance, you should emphasize the following performance factors:
The first guideline you can apply to the design process is to decrease the amount of program I/O time.
Storing data on, and retrieving data from, mass storage devices is the most time-consuming OpenVMS RMS (hereafter referred to as RMS) operation. For example, when an application needs data, the disk controller must first search for the data on the disk. The disk controller must then transfer the data from the disk to main memory. After processing the data, the program must provide for returning the results to mass storage via the I/O subsystem.
One way to reduce I/O time is to have the data in memory so that you can minimize search and transfer operations. If data must be transferred to memory for processing, you should consider design variables that reduce transfer time.
The first variable you might consider is the set of file attributes that may affect I/O time:
The second variable is the file size as measured by the number of records in the file. File size affects the time it takes to scan a file sequentially or to access records using an index.
A third variable is the storage device on which your program and data files reside. Crucial to I/O performance are the type of device chosen (moving-head, fixed-head, and so on) and the amount of I/O activity for that device within the system.
To make your applications run faster, consider the following:
When you run your application, you need space to buffer data in memory. You can reduce data processing time by increasing the size of the I/O buffers RMS uses; however, avoid exceeding the space limitations imposed by the working set.
In addition to the data buffers themselves, the space required to store data can vary depending on the file organization you choose.
For example, sequential file organization requires RMS to add an empty byte to a record when the record has an odd number of bytes but must be aligned on an even-numbered byte boundary. At the record level, you should consider the added space required to prefix a two-byte count field to each variable-length record.
For the relative file organization, RMS constructs a series of record storage cells based on the maximum length of the records. The record cells are 1 byte longer than the size of fixed-length records or 3 bytes longer than the maximum size specified for variable-length records.
For the indexed sequential file organization, RMS must add the following informational components to your data files:
You should also consider the effects of compression on the size of your indexed files. You can compress keys in data buckets and in index buckets, and you can compress data in the primary buckets. If you use key, index, or data compression, the file requires less space on the disk, and each I/O buffer can hold more information. Compression may even eliminate one index level thereby reducing the number of disk transfers needed for random access.
You cannot use key compression or index compression with the collated key data type. |
A file management technique that allows more than one user to simultaneously access a file or a group of files is called shared access or file sharing. When you try to adjust the performance of shared files, you need to pay particular attention to record locking options and the use of global buffers. Avoid assigning sharing attributes to files that are not actually shared.
There are essentially three sharing conditions: no sharing, sharing
without interlocking, and sharing with interlocking. Chapter 7
discusses each of these in detail.
3.1.4 Impact on Applications Design
The impact on applications design increases as file design complexity
increases. That is, your application programs require more design
effort for processing indexed files than for processing sequential
files. The primary consideration here should be to evaluate whether the
benefits derived by having direct access to records is worth the added
cost of the application program design needed to interface with the
file management system.
3.2 Tuning
The process of designing your files to achieve better processing performance is called tuning.
Tuning requires you to make a number of trade-offs and design decisions. For example, if a process had sole access to the processor, it could keep all of its data in memory and tuning would be unnecessary, but this situation is unlikely. Instead, several processes are usually running simultaneously and are competing for the memory resource. If all processes demand large amounts of memory, the system responds by paging and swapping, which slows down system performance.
The way you intend to use your programs and data files can determine some of the basic tuning decisions. For example, if you know that three files are accessed 80 percent of the time, you might consider locating the files in a common area on the disk to speed up access to them. The performance of programs that use the other files is slower, but the system as a whole runs faster.
In tuning your file management system, you implement these trade-offs
and design decisions by specifying file design attributes together with
various file-processing options and record-processing options.
3.2.1 File Design Attributes
The following file design attributes control how the file is arranged on the disk and how much of the file is transferred to main memory when needed. These file design attributes generally apply to all three types of file organization; other file design attributes that specifically pertain to the various file organizations are described under the appropriate heading.
When you create a file, you should allocate enough space to store it in one contiguous section of the disk. If the file is contiguous on the disk, it requires only one retrieval pointer in the header; this reduces disk head motion.
You should also consider allocating additional space in anticipation of file growth to reduce the number of required extensions.
You can allocate space either by using the FDL attribute FILE
ALLOCATION or by using the file access control block field FAB$L_ALQ.
3.2.1.2 Contiguity
Use the FILE secondary attribute CONTIGUOUS to arrange the file contiguously on the disk, if you have sufficient space. If you assign the CONTIGUOUS attribute and there is not enough contiguous space on the disk, RMS does not create the file. To avoid this, consider using the FDL attribute BEST_TRY_CONTIGUOUS instead of the CONTIGUOUS attribute. The BEST_TRY_CONTIGUOUS attribute arranges the file contiguously on the disk if there is sufficient space or noncontiguously if the space is not available for a contiguous file.
You can make this choice by accepting the FDL default values for both
attributes---NO for CONTIGUOUS, YES for BEST_TRY_CONTIGUOUS or by
taking the RMS FAB$V_CBT option in the FAB$L_FOP field.
3.2.1.3 Extending a File
An extend operation (file extend) adds unused disk blocks to an RMS file when the free space within a file is exhausted. If the unused disk blocks are not contiguous to the previously allocated disk blocks of the file, the file becomes fragmented. As a file becomes fragmented, access time increases and processing performance can degrade. Appropriate use of extend operations can minimize file fragmentation.
If you intend to add large amounts of data to a file over a short time, using large extends will minimize file fragmentation and the overhead of extend operations. Conversely, if you intend to add small amounts of data to a file over a long time, smaller file extends can avoid wasted disk space.
There are two methods for extending files. One method is for an application program to call the $EXTEND service (see the OpenVMS Record Management Services Reference Manual for details). When it calls the $EXTEND service, the application must specify an explicit extend size in disk blocks because no defaults are used to determine the extend size.
The other method is for RMS to automatically extend (auto extend) a
file when free space is needed. You can specify the size of auto
extends using various default extension quantities, or you can have RMS
supply a default extend size. However, when RMS supplies a default, it
uses an algorithm that allocates a minimal extend. Repeated minimal
extends can increase file fragmentation.
3.2.1.3.1 Auto Extend Size Selection
This section describes the factors used to determine the size of auto extends. These include:
Sequential File and Block I/O Accessed File Extend Size
The auto extend size used for sequential files is used also for all file organizations when accessed by block I/O. The extend size is selected from the following ordered list of default extension quantities. Generally, if a default extension quantity does not exist, it is set to zero. RMS processes this list until it finds a nonzero value.
A relative file can be viewed as an accessible series of fixed-sized cells (or records) ranging from one to the maximum number of cells. Writing new cells that are located substantially beyond the allocated space of the relative file is permitted.
The size of a relative file auto extend is initially set to the minimum number of disk blocks that must be allocated to reference the new cell. The extend size is then rounded to the next bucket boundary so that the entire bucket containing the new record can be accessed. This value is then maximized against the file default extension quantity. If no file default exists, this value is maximized against the volume default extension quantity.
The process and system default extension quantities are not applicable to auto extending a relative file.
Indexed files are auto extended by adding space to a particular area of the indexed file. The extend size is always rounded to a multiple of the bucket size for the area being extended.
| Previous | Next | Contents | Index |
|
|
![[OpenVMS documentation]](../../images/openvms_doc_banner_bottom.gif) |
|
Copyright © Compaq Computer Corporation 1998. All rights reserved. Legal |
4506PRO_006.HTML
|