![[OpenVMS documentation]](../../images/openvms_doc_banner_top.gif)
|
![[Site home]](../../images/buttons/bn_site_home_off.gif)
![[Send comments]](../../images/buttons/bn_comments_off.gif)
![[Help with this site]](../../images/buttons/bn_site_help_off.gif)
![[How to order documentation]](../../images/buttons/bn_order_docs_off.gif)
![[OpenVMS site]](../../images/buttons/bn_openvms_off.gif)
![[Compaq site]](../../images/buttons/bn_compaq_off.gif)
|
| Updated: 11 December 1998 |
|
|
|
|
| Updated: 11 December 1998 |
VAX MACRO and Instruction Set Reference Manual
| Previous | Contents | Index |
The Vector Memory Activity Check (VMAC) register, shown in Figure 10-7, is used to guarantee the completion of all prior vector memory accesses. For more information on this function of VMAC, refer to Section 10.7.2.2. An MFPR from VMAC also ensures that all hardware errors encountered by previous vector memory instructions are reported before the MFPR completes. For more information on this function of VMAC, refer to Section 10.9, Hardware Errors. The value returned by MFPR from VMAC is UNPREDICTABLE.
Figure 10-7 Vector Memory Activity Check (VMAC) Register

The Vector Translation Buffer Invalidate All (VTBIA) register, shown in Figure 10-8, is a write-only register that may be omitted in some implementations. If the vector processor contains its own translation buffer, moving zero into VTBIA using the MTPR instruction invalidates the entire vector translation buffer. For more information, refer to Section 10.8, Memory Management.
Figure 10-8 Vector Translation Buffer Invalidate All (VTBIA) Register
The Vector State Address Register (VSAR), shown in Figure 10-9, is a read/write register that contains a quadword-aligned virtual address of memory assigned by software for storing implementation-specific vector hardware state when the asynchronous method of handling memory management exceptions is implemented. The length of this memory area is implementation specific. Software must guarantee that accessing the memory pointed to by the address does not result in a memory management exception. If the synchronous method of handling memory management exceptions is implemented, this register is omitted. For more information, refer to Section 10.6.1, Vector Memory Management Exception Handling.
Figure 10-9 Vector State Address Register (VSAR)

With the exception of VPSR (and VAER), an MTPR to any other writable vector internal processor register (IPR) ensures that the new state of the IPR affects the execution of all subsequently issued vector instructions. Vector instructions issued before an MTPR to any writable vector IPR are unaffected by the new state of the IPR (and any implicitly changed vector IPR) except in one case: when the MTPR sets VPSR<RST> while VPSR<BSY> is set. (See Table 10-1 for more details.)
Except for the following two cases, the operations of the scalar and vector processors are UNDEFINED after execution of MTPR to a read-only vector IPR, MTPR to a nonexistent vector IPR, MTPR of a nonzero value to a MBZ field, or MTPR of a reserved value to a vector IPR. The preferred implementation is to cause reserved-operand fault.
In each of these cases, MTPR is implemented as a no-op.
Except for the following two cases, the operations of the scalar and vector processors are UNDEFINED after execution of MFPR from a nonexistent vector IPR, or MFPR from a write-only vector IPR. The preferred implementation is to cause reserved-operand fault.
The internal processor register (IPR) assignments for these registers are found in Table 10-5.
| Offset (Hex) | IPR |
|---|---|
| 90 | VPSR |
| 91 | VAER |
| 92 | VMAC |
| 93 | VTBIA |
| 94 | VSAR |
| 95--9B | Reserved for vector architecture use |
| 9C--9F | Reserved for vector implementation use |
Vector instructions use 2-byte opcodes and normal VAX operand specifiers. For more information on VAX operand specifiers, refer to the VAX Architecture Reference Manual. The vector registers to be used by a vector instruction are specified by the vector control word operand. The MFVP, MTVP, and Synchronize Vector Memory Access (VSYNC) instructions do not use a vector control word operand. The general format of the vector control word operand is shown in Figure 10-10. Table 10-6 describes the fields of the vector control word operand (cntrl). The actual format of the vector control word operand is instruction dependent. (Refer to the instruction descriptions later in this chapter for more detail.) The vector control word operand is passed by the VAX scalar processor to the vector processor.
Figure 10-10 Vector Control Word Operand (cntrl)
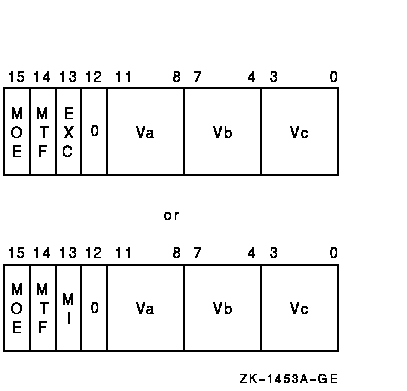
| Extent | Description |
|---|---|
| <3:0> | Vc. This field selects the vector register to be used as the Vc operand. For the Vector Floating Compare (VCMP) instruction, it specifies the compare function. |
| <7:4> | Vb. This field selects the vector register to be used as the Vb operand. |
| <11:8> | Va. This field selects the vector register to be used as the Va operand. For the Vector Convert (VVCVT) instruction, it specifies the convert function. |
| <12> | 0 |
| <13> | Modify Intent (MI). Used only in Load Memory Data into Vector Register (VLD) and VGATH instructions. instructions to indicate that a majority of the memory locations being loaded by the VLD or VGATH will later be stored into by VST/VSCAT instructions. This bit is optional to implement. See Section 10.3.3, Modify Intent bit, for more details. |
| <13> | Exception Enable (EXC). Used only in vector integer and floating-point instructions to enable integer overflow and floating underflow, respectively. |
| <14> | Match True/False (MTF). When masked operations have been enabled (cntrl<MOE> EQL 1), only elements for which the corresponding VMR bit matches cntrl<MTF> are operated on. See previous description. Cntrl<MTF> is also used by the VMERGE and IOTA instructions. |
| <15> | Masked Operation Enable (MOE). This bit enables operations under the control of the Vector Mask Register (VMR) for vector instructions. When set, masked operations are enabled, and only elements for which the corresponding VMR bit matches cntrl<MTF> are operated on. If cntrl<MOE> is clear, all elements are operated upon. In either case, the Vector Length Register (VLR) limits the highest element operated upon. |
The vector control word operand may determine some or all of the following:
Masked operations are enabled by the use of cntrl<15:14> of the vector control word operand. Cntrl<15> is the Masked Operation Enable (MOE) bit, and cntrl<14> is the Match True/False (MTF) bit. When cntrl<MOE> is set, masked operations are enabled. Only elements for which the corresponding Vector Mask Register (VMR) bit matches cntrl<MTF> are operated upon. If cntrl<MOE> is clear, all elements are operated upon. In either case, the Vector Length Register (VLR) limits the highest element operated upon.
Cntrl<MOE> should be zero for VMERGE and IOTA instructions;
otherwise the results are UNPREDICTABLE. Both the Vector Mask Register
(VMR) and the Match True/False bit (cntrl<MTF>) are always used
by these instructions. VMERGE and IOTA operate upon vector register
elements up to the value specified in VLR.
10.3.2 Exception Enable Bit
The vector processor does not use the IV and FU bits in the processor
status longword (PSL) to enable integer overflow and floating underflow
exception conditions. These exception conditions are enabled or
disabled on a per instruction basis for vector integer and
floating-point instructions by bit <13> in the vector control
word operand (cntrl<EXC>). When cntrl<EXC> is set, floating
underflow is enabled for vector floating-point instructions, and
integer overflow is enabled for vector integer instructions. When
cntrl<EXC> is clear, floating underflow and integer overflow are
disabled. Note that for VLD/VGATH instructions bit<13> is used
and labeled differently.
10.3.3 Modify Intent Bit
The Modify Intent (MI) bit is used by the software to indicate to the vector processor that a majority of the memory locations being loaded by VLD/VGATH instructions will later be stored into, and so become modified, by VST/VSCAT instructions. When informed of software's intent to modify, some vector processor implementations can optimize the vector loads and stores performed on these locations.
The MI bit resides in bit<13> of the vector control word operand (cntrl<MI>) and is used only in VLD and VGATH instructions. A vector processor implementation is not required to implement cntrl<MI>.
For vector processors that implement cntrl<MI>, software uses the bit in a VLD or VGATH instruction in the following way:
Vector processors that do not implement cntrl<MI> ignore the setting of this bit in the control word for VLD and VGATH.
The results of VLD/VGATH and VST/VSCAT are unaffected by the setting of
cntrl<MI>. This includes memory management, where access-checking
is done with read intent for VLD/VGATH even if cntrl<MI> is set.
However, incorrectly setting cntrl<MI> can prevent the
optimization of these instructions.
10.3.4 Register Specifier Fields
The Va (cntrl<11:8>), Vb (cntrl<7:4>), and Vc
(cntrl<3:0>) fields of the vector control word operand are
generally used to select vector registers. Some vector instructions use
these fields to encode other instruction-specific information as shown
later in this section.
10.3.5 Vector Control Word Formats
Depending on the instruction, the vector control word can specify up to two vector registers as sources, and one vector register as a destination. Other information may be encoded in the vector control word, as shown in Figure 10-11a to Figure 10-11n. Bits that are shown as "0" should be zero (SBZ). Execution of vector instructions with illegal, inconsistent, or unspecified control word fields produces UNPREDICTABLE results.
Figure 10-11a depicts the vector control word for VLDL and VLDQ.
Figure 10-11b depicts the vector control word for VSTL and VSTQ.
Figure 10-11c depicts the vector control word for VGATHL and VGATHQ.
Figure 10-11d depicts the vector control word for VSCATL and VSCATQ.
Figure 10-11e depicts the vector control word for VVADDL/F/D/G, VVSUBL/F/D/G, VVMULL/F/D/G, and VVDIVF/D/G.
Figure 10-11f depicts the vector control word for VVSLLL, VVSRLL, VVBISL, VVXORL, and VVBICL. Cntrl<EXC> should always be zero for these instructions, otherwise the results are UNPREDICTABLE.
Figure 10-11g depicts the vector control word for VVCMPL/F/D/G. The Vc field (cntrl<3:0>) is used to specify the compare function.
Figure 10-11h depicts the vector control word for VVCVT. The Va field (cntrl <11:8>) is used to specify the convert function.
Figure 10-11i depicts the vector control word for VVMERGE.
Figure 10-11j depicts the vector control word for VSADDL/F/D/G, VSSUBL/F/D/G, VSMULL/F/D/G, and VSDIVF/D/G.
Figure 10-11k depicts the vector control word for VSSLLL, VSSRLL, VSBISL, VSXORL, and VSBICL. Cntrl<EXC> should be zero for these instructions; otherwise, the results are UNPREDICTABLE.
Figure 10-11l depicts the vector control word for VSCMPL/F/D/G. The Vc field (cntrl<3:0>) is used to specify the compare function.
Figure 10-11m depicts the vector control word for VSMERGE.
Figure 10-11n depicts the vector control word for IOTA.
Figure 10-11 Vector Control Word Format


Certain restrictions are placed on the addressing mode combinations usable within a single vector instruction. These combinations involve the logically inconsistent simultaneous use of a value as both a source operand (that is, a .rw, .rl, or .rq operand) and an address. Specifically, if within the same instruction the contents of register Rn is used as both a part of a source operand and as an address in an addressing mode that modifies Rn (that is, autodecrement, autoincrement, or autoincrement deferred), the value of the scalar source operand is UNPREDICTABLE.
Use of short literal mode for the scalar source operand of a vector floating-point instruction causes UNPREDICTABLE results.
If a Store Vector Register Data into Memory (VST) or Scatter Memory Data into Vector Register (VSCAT) instruction overwrites anything needed for calculation of the memory addresses to be written, the result of the VST or VSCAT is UNPREDICTABLE.
If the same vector register is used as both source and destination in a Gather Memory Data into Vector Register (VGATH) instruction, the result of the VGATH is UNPREDICTABLE.
When the addressing mode of the BASE operand used in a VLD, VST, VGATH,
or VSCAT instruction is immediate, the results of the instruction are
UNPREDICTABLE.
10.3.7 VAX Condition Codes
The vector instructions do not affect the condition codes in the
processor status longword (PSL) of the associated scalar processor.
10.3.8 Illegal Vector Opcodes
An illegal vector opcode is defined as a vector opcode to which no vector processor function is currently assigned. Opcodes that are not identified in Appendix D as vector opcodes are neither decoded nor executed by the vector processor.
An implementation is permitted to report an illegal vector opcode in one of the following ways:
The way in which a particular illegal vector opcode is reported is
implementation specific.
10.4 Assembler Notation
The assembler notation uses a format that is different from the operand specifiers for the vector instructions. The number and order of operands is not the same as the instruction-stream format. For example, vector-to-vector addition is denoted by the assembler as "VVADDL V1, V2, V3" instead of "VVADDL X123". The assembler always generates immediate addressing mode (I#constant) for vector control word operands. The assembler notation for vector instructions uses opcode qualifiers to select whether vector processor exception conditions are enabled or disabled, and to select the value of cntrl<MTF> in masked, VMERGE, and IOTA operations. The appropriate opcode is followed by a slash (/). The following qualifiers are supported:
The following examples use several of these qualifiers:
VVADDF/1 V0, V1, V2 ;Operates on elements with mask bit set
VVMULD/0 V0, V1, V2 ;Operates on elements with mask bit clear
VVADDL/V V0, V1, V2 ;Enables exception conditions
(integer overflow here)
VVSUBG/U0 V0, V1, V2 ;Enables floating underflow and
;Operates on elements with mask bit clear
|
VLDL/M base,#4,V1 ;Indicates Modify Intent |
10.5 Execution Model
A typical processor consists of a VAX scalar processor and its
associated vector processor, which contains vector registers and vector
function units. The scalar and vector processors may execute
asynchronously. The VAX scalar processor decodes both scalar and vector
instructions following the operand specifier evaluation rules stated in
the VAX Architecture Reference Manual, but executes only the scalar instructions. The
scalar processor passes the information required to execute a vector
instruction to the vector processor. This information may include the
vector opcode, scalar source operands, and vector control words. The
vector processor performs the required operation, such as loading data
from memory, storing data to memory, or manipulating data already
loaded into its vector registers.
The scalar processor may decode a vector instruction before checking whether the vector processor should receive it. Exceptions on vector instruction operands may occur during this decoding and may be taken before the attempt to send the decoded instruction to the vector processor. The scalar processor performs one of the following operations when sending a decoded vector instruction to the vector processor. Recall that because the vector and scalar processors can execute asynchronously, a VPSR state transition may not be seen immediately by the scalar processor.
The following flow details how vector instruction decode proceeds from the scalar processor:
DO WHILE (the scalar processor has a decoded vector instruction for
the vector processor)
IF (the vector processor is viewed as disabled -- the scalar processor
sees VPSR<VEN> as clear) THEN
enter the vector processor disabled fault handler.
ELSE
IF (asynchronous memory management handling is implemented
AND VPSR<PMF> is set) THEN
enter the memory management exception handler.
{The vector processor clears VPSR<PMF>.}
ELSE
BEGIN
{If asynchronous memory management handling is
implemented and VPSR<MF> is set, the vector processor
clears VPSR<MF>, and retries the faulting memory
reference before any new vector instructions in the
queue are executed.}
IF (the vector processor instruction queue is not full) THEN
BEGIN
Send the decoded instruction to the vector processor
for execution.
IF (the decoded instruction is a vector memory access
instruction AND synchronous memory management
handling is implemented) THEN
ensure instruction completion without the occurrence
of memory management exceptions.
END
END
END
|
If asynchronous memory management handling is implemented, and VPSR<MF> is set when the scalar processor sends the vector processor an instruction, the vector processor clears VPSR<MF>, and retries the faulting memory reference before any new vector instructions in the queue are executed.
The VAX scalar processor need not wait for the vector processor to complete its operation before processing other instructions. Thus, the scalar processor could be processing other VAX instructions while the vector processor is performing vector operations. However, if the scalar processor issues an MFVP instruction to the vector processor, the scalar processor must wait for the MFVP result to be written before processing other instructions.
Because the scalar and vector processors may execute asynchronously, it is possible to context switch the scalar processor before the vector processor is idle. Software is responsible for ensuring that scalar and vector memory management remains synchronized, and that all exceptions get reported in the context of the process where they occurred. This is achieved by making sure all vector memory accesses complete, and then disabling the vector processor before any scalar context switch.
The vector processor may have its own translation buffer (TB) and cache and may have separate paths to memory, or it may share these resources with the scalar processor.
| Previous | Next | Contents | Index |
|
|
![[OpenVMS documentation]](../../images/openvms_doc_banner_bottom.gif) |
|
Copyright © Compaq Computer Corporation 1998. All rights reserved. Legal |
4515PRO_031.HTML
|