![[OpenVMS documentation]](../../images/openvms_doc_banner_top.gif)
|
![[Site home]](../../images/buttons/bn_site_home_off.gif)
![[Send comments]](../../images/buttons/bn_comments_off.gif)
![[Help with this site]](../../images/buttons/bn_site_help_off.gif)
![[How to order documentation]](../../images/buttons/bn_order_docs_off.gif)
![[OpenVMS site]](../../images/buttons/bn_openvms_off.gif)
![[Compaq site]](../../images/buttons/bn_compaq_off.gif)
|
| Updated: 11 December 1998 |
|
|
|
|
| Updated: 11 December 1998 |
VAX MACRO and Instruction Set Reference Manual
| Previous | Contents | Index |
In general, processes are expected to use the vector processor in only one mode. However, multimode use of the vector processor by a process is allowed. Software decides whether to allow vector processor exceptions from vector instructions executed in a previous access mode to be reported in the current mode. The preferred method is to report all vector processor exceptions in the access mode where they occurred. This is achieved by requiring a process that uses the vector processor to execute a SYNC instruction before changing to an access mode where additional vector instructions are executed.
For correct access checking of vector memory references, the vector
processor must know the access mode in effect when a vector memory
access instruction is issued by the scalar processor.
10.5.2 Scalar Context Switching
With the addition of a vector processor, the required steps in performing a scalar context switch change. The following procedure outlines the required method software should use for scalar context switching:
Although not required by the architecture, software may wait for VPSR<BSY> to be clear after disabling the vector processor when performing a scalar context switch, which provides the following advantages:
If software does not wait for VPSR<BSY> to be clear, it is possible that while a normal scalar context switch to a new process is being performed, the vector processor may still be executing non-memory-access instructions from the previous process.
The required steps for Vector Context Switching are discussed in
Section 10.6.4, Handling Disabled Faults and Vector Context Switching.
10.5.3 Overlapped Instruction Execution
To improve performance, the vector processor may overlap the execution of multiple instructions---that is, execute them concurrently. Further, when no data dependencies are present, the vector processor may complete instructions out of order relative to the order in which they were issued. A vector processor implementation can perform overlapped instruction execution by having separate function units for such operations as addition, multiplication, and memory access. Both data-dependent and data-independent instructions can be overlapped; the former by a technique known as chaining, which is described in the next section. In many instances, overlapping allows an operation from one instruction to be performed in any order with respect to an operation of another instruction.
When vector arithmetic exceptions occur during overlapped instruction execution, exception handling software may not see the same instruction state and exception information that would be returned from strictly sequential execution. Most notably, the VAER could indicate the exception conditions and destination registers of a number of vector instructions that were executing concurrently and encountered exceptions. Exception reporting during chained execution is discussed further in Section 10.5.3.1.
To ensure correct program results and exception reporting, the architecture does place requirements on the ordering among the operations of one vector instruction and those of another. The primary goal of these requirements is to ensure that the results obtained from both the overlapped and strictly sequential execution of data-dependent instructions are identical. A secondary goal is to establish places within the instruction stream where software is guaranteed to receive the reporting of exceptions from a chain of data-dependent instructions.
In many cases, these requirements ensure the obvious: for example, an output vector register element of one arithmetic instruction must be computed before it can be used as an input element to a subsequent instruction. But, a number of the things ensured are not obvious: for example, a Memory Instruction Synchronization (MSYNC) instruction must report exceptions encountered in generating a value of Vector Mask Register (VMR) that is used in a previously issued masked store instruction.
To precisely define the requirements on the ordering among operations,
Section 10.5.3.3 discusses the "dependence" among their results
(the vector register elements and control register bits produced by the
operations).
10.5.3.1 Vector Chaining
The architecture allows vector chaining, where the results of one vector instruction are forwarded (chained) to another before the input vector of the first instruction has been completely processed. In this way, the execution of data-dependent vector instructions may be overlapped. Thus, chaining is an implementation-dependent feature that is used to improve performance.
With some restrictions stated below, the vector processor may chain a number of instructions. Usually, each instruction is performed by a separate function unit. The number and types of instructions allowed within a chained sequence (often referred to as a "chain") are implementation dependent. Typically, implementations will attempt to chain sequences of two or three instructions such as: operate-operate, operate-store, load-operate, operate-operate-store, and load-operate-store. Load-operate-operate-store may also be possible.
The following is an example of a sequence that an implementation will often chain:
VVADDF V0, V1, V2 VVMULF V2, V3, V4 |
The destination of the VVADDF is a source of the succeeding VVMULF. The VVMULF begins executing when the first sum element of the VVADDF is available.
A number of instructions within a chained sequence can encounter exceptions. For each instruction that encounters an exception, the vector processor records the exception condition type and destination register number in the Vector Arithmetic Exception Register (VAER). When the last instruction within the chain completes, the VAER will show the exception condition type and destination register number of all instructions that encountered exceptions within the chain. Furthermore, when the vector processor disabled fault is finally generated for the exceptions, the VAER may also indicate exception state for instructions issued after the last instruction within the chain. This effect is possible due to the asynchronous exception-reporting nature of the vector processor.
Furthermore, for each instruction that encounters an exception within a chain, the default result, as defined in Section 10.6.2, is forwarded as the source operand to the next instruction. This has the effect that default results and exceptions can propagate down through a chain. Note that the default result of one instruction may be overwritten by another instruction before the exception is taken.
Consider the following:
VVADDG V1, V2, V3 ;gets Floating Overflow VVGEQG V3, V4 ;gets Floating Reserved Operand VVMULG V4, V5, V3 ;overwrites V3 |
For the previous example, assume that an exception is taken after the completion of the VVMULG. The VAER will indicate: Floating Overflow and Floating Reserved Operand exception condition types; and V3 as a destination register. However, no default result will be found in the appropriate element of V3 because it has been overwritten by the VVMULG.
The architecture allows a vector load to be chained into a vector operate instruction provided the operate instruction can be suspended and resumed to produce the correct result if the vector load gets a memory management exception. Consider this example:
VLDL A, #4, V0 VVADDF V0, V1, V1 |
In synchronous memory management mode, the VVADDF cannot be chained into the VLDL until the VLDL is ensured to complete without a memory management exception. This occurs because the scalar processor is not even allowed to issue the VVADDF to the vector processor until the memory management checks for the VLDL have been completed. In asynchronous memory management mode, the VVADDF may be chained into the VLDL prior to the completion of memory management exception checking. This is possible because a memory management exception in asynchronous memory management mode provides sufficient state to restart both the VLDL and the VVADDF when the memory management exception is corrected.
The architecture allows a vector operate instruction to be chained into
a store instruction. If the vector operate instruction encounters an
arithmetic exception, the exception condition type and destination
register number are recorded in the Vector Arithmetic Exception
Register (VAER). The default result generated by that instruction (in
some cases an encoded reserved operand) may be written to memory by the
store instruction before the exception is reported.
10.5.3.2 Register Conflict
When overlapping the execution of instructions, the vector processor must deal with register conflict. This occurs when one instruction is intending to write a register while previously issued instructions are reading from that register. The following is an example of vector register conflict:
VVADDF V1, V2, V3 VVMULF V4, V5, V1 |
In the example, the VVADDF and VVMULF cannot both begin execution simultaneously because the elements of V1 generated by the VVMULF would overwrite the original elements of V1 required as input by the VVADDF. However, a vector processor implementation can still overlap the execution of these two instructions in a number of ways. One way would be by not starting the VVMULF until the first element of V1 has been read by the VVADDF. In this manner, as the VVADDF reads the next elements from V1 and V2, the VVMULF writes its product into the previous element of V1. This process continues until all the elements have been processed by both instructions. The VVADDF will finish execution while the VVMULF still has at least one product to store.
In the case of the Vector Mask Register (VMR), the vector processor
ensures that register conflict does not occur. This is often
accomplished by making a copy of the VMR value under which a pending
vector instruction is to execute, and using this copy when execution
begins. This allows the vector processor to begin executing an
instruction that writes VMR before it completes prior instructions that
read VMR.
10.5.3.3 Dependencies Among Vector Results
To achieve correct results and exception reporting during overlapped execution, the vector processor must maintain certain dependencies among the register elements and control register bits produced by various vector instructions. Because of the vector processor's asynchronous exception reporting nature and out-of-order completion of instructions, these dependencies differ from those ensured by the VAX scalar processor. In addition, these dependencies are at the level of vector register elements and vector control register bits; rather than at the level of vector registers and vector control registers.
Among other things, these dependencies determine the exception reporting nature of the MFVP instruction. The value of the vector control register (VCR, VLR, VMR<31:0>, VMR<63:32>) delivered by an MFVP depends upon the value of certain vector register elements and vector control register bits. Unreported exceptions that occur in the production of these elements and control register bits are reported by the vector processor prior to the completion of the MFVP from the vector control register.
The dependencies are expressed formally for the various classes of vector instructions by the tables of pseudo-code in this section. These are the only dependencies that software should rely upon the vector processor to ensure.
A vector processor implementation is allowed to ensure more than just these dependencies providing that this larger set of dependencies yields correct results and exception reporting.
Note the implications of the following sequence for Table 10-7, Table 10-8, Table 10-9, Table 10-10, Table 10-11, Table 10-12, Table 10-13, and Table 10-14:
Implicit in statements of the form: "result DEPENDS on B" is the requirement that the result depends only on the value of "B" generated by the most immediate previously issued instruction relative to the result's own generating instruction. For instance, in the following example, the V3 produced by the VVMULF has the dependence: "V3[i] DEPENDS on V7[i]". This means that the value of V3[i] produced by the VVMULF depends only on the value of V7[i] produced by the VVADDF. |
| Instructions | Dependence |
|---|---|
| VVADDx, VSADDx, VVSUBx, VSSUBx, VVMULx, VSMULx, VVDIVx, VSDIVx, VVCVTxy, VVBICL, VSBICL, VVBISL, VSBISL, VVXORL, VSXORL, VVSLLL, VSSLLL, VVSRLL, VSSRLL |
for i = 0 to VLR-1 |
| Instructions | Dependence |
|---|---|
| VLDx, VGATHx |
for i = 0 to VLR-1 |
| Instructions | Dependence |
|---|---|
| VSTx, VSCATx |
j = 0; |
| Instructions | Dependence |
|---|---|
| VVCMPx, VSCMPx |
for i = 0 to VLR-1 |
| Instructions | Dependence |
|---|---|
| VVMERGE, VSMERGE |
for i = 0 to VLR-1 |
| Instruction | Dependence |
|---|---|
| IOTA |
j = 0; |
| Instructions | Dependence |
|---|---|
| MSYNC |
DEPENDS on the following:
|
| SYNC | DEPENDS on the vector register elements and vector control register bits produced and stored by all previous vector instructions |
| MFVMRLO | DEPENDS on VMR<0..31> |
| MFVMRHI | DEPENDS on VMR<32..63> |
| MFVCR | DEPENDS on VCR |
| MFVLR | DEPENDS on VLR |
| Item | Dependence |
|---|---|
| VSYNC | Depends on nothing, but for each memory location, x forces all subsequent LOAD_COMPLETED(x) and STORE_COMPLETED(x) to DEPEND on all previous LOAD_COMPLETED(x) and STORE_COMPLETED(x). |
| MTVP | DEPENDS on nothing. |
| Value of a memory location | The value of a memory location DEPENDS on nothing and is not DEPENDED on by any vector instruction. |
| Transitive dependence |
if {a DEPENDS on b} AND {b DEPENDS on c} then a DEPENDS on c
|
There are two major classes of vector processor exceptions as follows:
Vector processor arithmetic exceptions cause the vector processor to
disable itself (see Section 10.6.3, Vector Processor Disabled). The
vector processor does not disable itself for vector processor memory
management exceptions.
10.6.1 Vector Memory Management Exception Handling
Vector processor memory management exceptions are taken through the system control block (SCB) vector for their scalar counterparts. Figure 10-12 illustrates the memory management fault stack frame that contains the memory management fault parameter.
Figure 10-12 Memory Management Fault Stack Frame (as Sent by the Vector Processor)
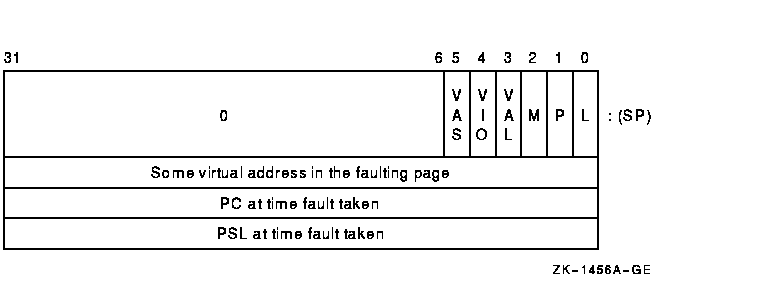
If more than one kind of memory management exception could occur on a reference to a single page, then access control violation takes precedence over both translation not valid and modify. If more than one kind of access control violation could occur, the precedence of vector access control violation, vector alignment exception, and vector I/O space reference is UNPREDICTABLE.
The architecture allows an implementation to choose one of two methods for dealing with vector processor memory management exceptions. The two methods are as follows:
With the synchronous method, no new instructions are processed by the vector or the scalar processor until the vector memory access instruction is guaranteed to complete without incurring memory management exceptions. In such an implementation, the vector memory access instruction is backed up when a memory management exception occurs and a normal VAX memory management (access control violation, translation not valid, modify) fault taken with the program counter (PC) pointing to the faulting vector memory access instruction. If the synchronous method is implemented, VSAR is omitted. After fixing the vector processor memory management exception, software may REI back to the faulting vector instruction. Alternately, software may context switch to another process. For further details, see Section 10.6.4.
With the asynchronous method, vector memory management exceptions set VPSR<PMF> and VPSR<MF>. The vector processor does not inform the scalar processor of the exception condition; the scalar processor continues processing instructions. All pending vector instructions that have started execution are allowed to complete if their source data is valid. The scalar processor is notified of an exception condition or conditions when it sends the next vector instruction to the vector processor and a normal VAX memory management fault is taken. The saved PC points to this instruction, which is not the vector memory access instruction that incurred the memory management exception. At this point, the vector processor clears VPSR<PMF>. After fixing the vector processor memory management exception, software may allow the current scalar/vector process to continue. Before vector processor instruction execution resumes using state that already exists in the vector processor, the vector processor clears VPSR<MF> and the faulting memory reference is retried. Alternately, software may context switch to another process. For further details, see Section 10.6.4.
When a vector processor memory management exception is encountered by a VLD or VGATH instruction, the contents of the destination vector register elements are UNPREDICTABLE. When a vector processor memory management exception is encountered by a VSTL or VSCAT instruction, it is UNPREDICTABLE whether the vector processor writes any result location for which an exception did not occur. In either case, if the fault condition can be eliminated by software and the instruction restarted, then the vector processor will ensure that all destination register elements or result locations are written.
| Previous | Next | Contents | Index |
|
|
![[OpenVMS documentation]](../../images/openvms_doc_banner_bottom.gif) |
|
Copyright © Compaq Computer Corporation 1998. All rights reserved. Legal |
4515PRO_032.HTML
|