| 前へ | 次へ | 目次 | 索引 |
システムの可用性は,多くのコンピューティング環境にとって,重要な課題です。信頼できる環境であれば,ユーザはいつでも好きな方法でシステムにアクセスすることができます。
システム全体の可用性にとって重要な要素は,データの可用性,あるいはアクセス可能性です。Volume Shadowing for OpenVMS は高度なデータ可用性を実現し,シャドウ・セットを 1 つのノードに,あるいは OpenVMS Cluster システムに構成することができるため,ディスク媒体,ディスク・ドライブ,ディスク・コントローラなどに障害が発生しても,データへのアクセスが中断されることはありません。メンバが複数の OpenVMS Cluster ノードにローカルに接続されているシャドウ・セットでは,シャドウ・セット・メンバをサービスしている 1 つのノードがシャットダウンしても,そのデータは別のノードを通じてアクセスすることができます。
1 つのディスク・ボリュームで構成された仮想ユニット ( シャドウ・セットのシステム表現 ) を作成することはできますが,シャドウ ( 同一データの複数のコピーを持つこと ) を可能にするためには,複数のディスク・ボリュームをマウントしなくてはなりません。このように構成すれば,1 つのディスク・ドライブが故障したり, 1 つのボリュームが劣化しただけで,システムダウンになることが避けられるようになります。たとえば,シャドウ・セットの 1 つのメンバが故障しても,残りのメンバはソース・ディスクとして使うことができ,そのデータはアプリケーションからアクセスできると同時に新しくマウントされるターゲット・ディスクへコピーするためにも使うことができます。データのコピーが完了すれば,両方のディスクには同じ情報が入っているので,ターゲット・メンバが今度はシャドウ・セットのソース・メンバになります。
2 つのコントローラを使うと,1 つのコントローラが故障しても,もう一方のコントローラが使用できるので,データ可用性が大幅に向上します。システムにボリューム・シャドウイングを設定する場合は,各々のディスク・ドライブを,できるかぎり,異なるコントローラの入出力チャネルに接続します。接続を分離させれば,1 つのコントローラの障害や,それにアクセスする通信パスの障害を保護することができます。
単一ノード環境の代わりに,OpenVMS Cluster システムを使って,複数のコントローラを使うと,データ可用性は大幅に向上します。複数のローカル・コントローラに接続された複数のディスクと,他の OpenVMS Cluster システムの MSCP でサービスされるディスクは,統合して単一のシャドウ・セットにすることができます。このとき,これらのディスクに互換性があり,結合するディスクは 3 台以下である必要があります。
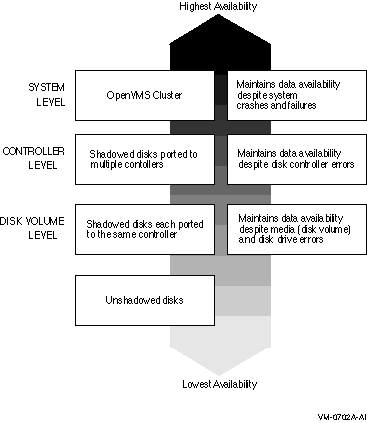
図 2-1 では,物理的なデータ可用性を実現する方法を,構成の種類別に低いレベルから高いレベルまで,定性的に分類しています。
図 2-1 可用性のレベル
第 2.1 節 では,物理的な障害に耐えることができる高度なデータ可用性を実現するシャドウ・システムを構成する方法を説明します。
2.1 障害からの修復と復旧
ボリューム・シャドウイングの障害 (一部の障害はボリューム・シャドウイング・ソフトウェアで自動的に復旧させることができる) は,次のカテゴリに分類できます。
シャドウ・セットの修復と復旧の処理は,発生した障害の種類とハードウェア構成によって異なります。一般に,デバイスにアクセスできないときには,できる限り別のコントローラへフェールオーバする方法を取ります。それができなければ,シャドウ・セットから削除します。媒体の欠陥によって発生するエラーは,ボリューム・シャドウイング・ソフトウェアで自動的に修復できることがあります。
表 2-1 は,これらの障害の種類と復旧メカニズムを説明しています。
| 種類 | 説明 |
|---|---|
| コントローラのエラー | コントローラの障害によって発生するエラーです。障害が復旧可能であれば,処理は継続し,データ可用性に影響は与えません。障害が復旧可能でなければ,そのコントローラに接続されているシャドウ・セット・メンバはシャドウ・セットから削除され,残りのメンバで処理が継続されます。ディスクが 2 台のコントローラにデュアル・パスで接続された構成で, 1 つのコントローラに障害が発生した場合は,シャドウ・セット・メンバは残りのコントローラにフェールオーバし,処理を継続します。 |
| デバイスのエラー | デバイスの機械部分や電子部分で障害が発生した場合です。障害が復旧可能であれば,処理は継続します。障害が復旧可能でなければ,エラーを検出したノードはそのデバイスをシャドウ・セットから削除します。 |
| データのエラー |
壊れたデータをデバイスが検出した場合です。データ・エラーは媒体の欠陥によって発生しますが,媒体の欠陥では通常,デバイスをシャドウ・セットから削除する必要はありません。データ・エラーの深刻さ ( あるいは,媒体劣化の程度 ) に応じて,コントローラは次の手段を取ります。
データがコントローラで訂正できない場合,ボリューム・シャドウイングによって,失われたデータを別のシャドウ・セット・メンバから読み出したデータで置き換え,誤ったデータを持っていたメンバの別の LBN に書き込みます。この修復操作はクラスタ内のアプリケーション入出力ストリームと同期を取って行われます。 |
| 接続障害 | 接続障害が発生した場合,障害を検出した最初のノードは,データの可用性や整合性に対する影響が最も小さい,障害からの復旧方法を決定しなくてはなりません。各々のノードでは,修復可能なデバイス障害を検出すると,以下のような手順を実行します。
|
Volume Shadowing for OpenVMS によって実現できる各種のレベルのデータ可用性の例を示すために,この節では代表的なハードウェア構成の例を示します。図 2-2 〜 2-7 は,可能なシャドウ・セットのシステム構成です。システム例を説明するために使われているハードウェアは,代表的なものを示していますが,仮定にすぎません。つまり,可用性の説明のために示しているだけで,実際の構成や製品を提案しているわけではありません。
以下の例では,シャドウ・セット・メンバには, $allocation-class$ddcu: という名前を付けます。仮想ユニットには,DSAn: という形式を使いますが, n は 0 〜 9999 の数です。これらの名前の付け方の詳細は,第 4.2 節 を参照してください。
図 2-2 は 1 つのホスト・ベース・アダプタ (HBA) を備えた 1 台のシステムです。シャドウ・セットは 3 台のディスクで構成されています。この構成では,媒体エラーと,2 台までのディスクの障害に対する耐性があります。
図 2-2 シャドウ・セットの構成 (1 システム,1 アダプタ)
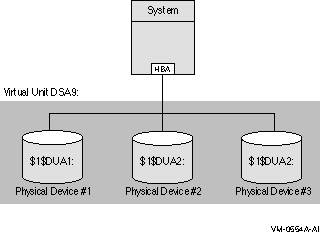
図 2-3 は,2 つのアダプタを備えた 1 台のシステムです。この構成では,シャドウ・セットの各々のディスクは,異なるアダプタに接続されています。
媒体エラーと,ディスクの障害に対する耐性の他に,この種の構成では,アダプタのどちらかが故障しても,データ・アクセスの継続性が保証されます。
図 2-3 シャドウ・セットの構成 (1 システム,2 アダプタ)
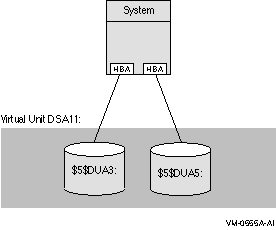
図 2-4 は,同じ 3 メンバ・シャドウ・セットに接続された 2 台のシステムです。各々のシャドウ・セット・メンバはデュアル・パスを通じて 2 つのアダプタに接続されています。シャドウ・セットは動作している 1 台または 2 台のシステムからアクセスできます。この構成では,ディスクは一時期に 1 つのアダプタに対してのみオンラインになります。たとえば,$2$DKA5 が System A に対してオンラインになっているとします (プライマリ・パス)。この場合,System B が $2$DKA5 にアクセスするには, System A の MSCP サーバを経由して行う必要があります。System A が障害を起こした場合は,$2$DKA5 は System B のアダプタにフェールオーバされます。
シャドウ・セットの各メンバは互いに独立にアダプタ間でフェールオーバすることができます。サテライト・ノードは,各システムの MSCP サーバを経由してシャドウ・セット・メンバにアクセスします。サテライトからのアクセスはプライマリ・パスを経由して行われるため,フェールオーバは自動的に行われます。
図 2-4 シャドウ・セットの構成 (OpenVMS Cluster, デュアル・アダプタ)
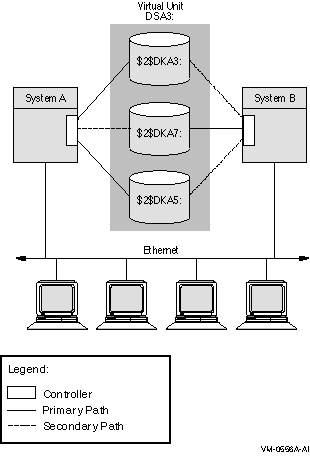
図 2-5 は,複数のディスクが接続された 2 台のシステムから構成される OpenVMS Cluster システムです。仮想ユニットの DSA1: と DSA2: が 2 つのシャドウ・セットを表し,いずれのシステムからもアクセス可能です。この構成では,可用性と性能が向上します。この構成のシャドウ・セットは,サテライト・ノードがいずれのシステム経由でもアクセスできるため,高度の可用性を確保できます。すなわち,1 台のシステムが障害を起こしても,サテライト・ノードは別のシステムを経由してシャドウ・ディスクにアクセスできます。
また,この構成では入出力トラフィックに Ethernet とは別のインターコネクトが使われるので,性能上の利点もあります。一般に,このような構成であれば, Ethernet だけの OpenVMS Cluster システムより,高い入出力スループットが得られます。
図 2-5 シャドウ・セットの構成 (高度な可用性を備えた OpenVMS Cluster)
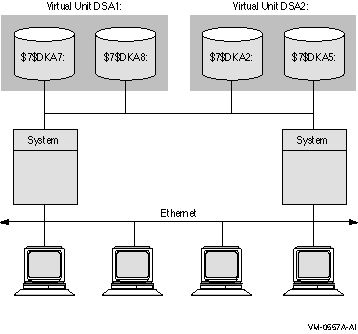
図 2-6 は,シャドウ・ディスクを OpenVMS Cluster システムのさまざまな位置に配置する方法を示しています。この図では,3 台のノード,複数の HSJ コントローラ,どのノードからもアクセスできる複数のシャドウ・セットからなるクラスタ・システムを示しています。シャドウ・セットは 1 〜 3 台のノードが動作しているときにアクセス可能です。ただし,System A と System B が障害を起こし,System C だけが動作しているときは例外です。この場合, 2 台目のスター・カプラーへアクセスすることができなくなり, DSA2: シャドウ・セットにはアクセスできなくなります。DSA1: にはアクセスできますが,1 メンバのシャドウ・セットに縮退されることに注意してください。
図 2-6 シャドウ・セットの構成 (複数のスター・カプラー,複数の HSJ コントローラ)
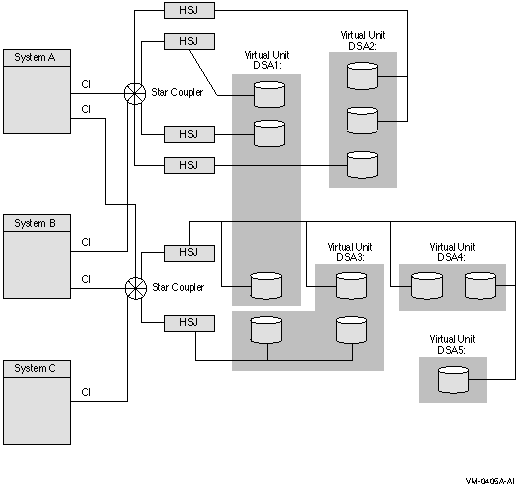
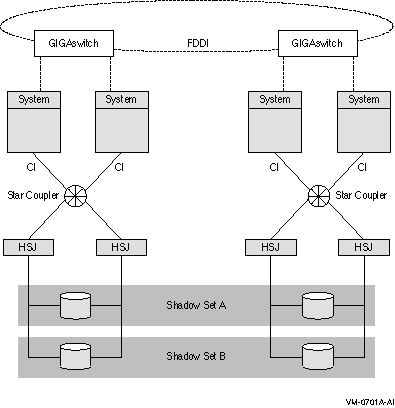
図 2-7 は, FDDI (Fiber Distributed Data Interface) インターコネクトによって,どのように遠隔地間でデータ・ディスクがシャドウ化されるかを示しています。各々のシャドウ・セットのメンバは 2 ヶ所の大きく離れたサイト間で構成されます ( マルチサイト OpenVMS Cluster システム )。双方のサイトに設置された OpenVMS システムとシャドウ・ディスクは,単一の OpenVMS Cluster システムとシャドウ・セット構成として動作します。いずれかのサイトで障害が発生しても,重要なデータはもう一方のサイトに保持されています。
図 2-7 FDDI を使ってシャドウ化するマルチサイト・クラスタの構成
|
サテライト・ノード以外のシステムは,Ethernet や FDDI LAN を経由してリモートのディスクからブートすることはできません。したがって,これらのシステムは,システム・ディスクにローカルにアクセスする必要があります。この制限は,システム・ディスク・シャドウ・セットを FDDI や Ethernet LAN を経由して作成するときの制約になることに注意してください。 |
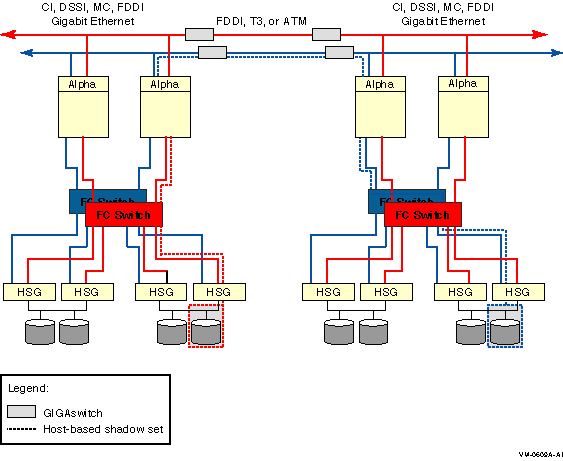
図 2-8 は,シャドウ・ディスクを持つマルチサイトの OpenVMS Cluster システムで共用 Fibre Channel ストレージを使う方法を示しています。シャドウ・セットのメンバは遠く離れた 2 つのサイト間に構成されます。この構成は, 図 2-7 に似ていますが,各々のサイトのシステムが Fibre Channel ストレージを使っているところが異なります。
図 2-8 Fibre Channel を使ってシャドウ化するマルチサイト・クラスタの構成
| 前へ | 次へ | 目次 | 索引 |