![[OpenVMS documentation]](../../images/openvms_doc_banner_top.gif)
|
![[Site home]](../../images/buttons/bn_site_home_off.gif)
![[Send comments]](../../images/buttons/bn_comments_off.gif)
![[Help with this site]](../../images/buttons/bn_site_help_off.gif)
![[How to order documentation]](../../images/buttons/bn_order_docs_off.gif)
![[OpenVMS site]](../../images/buttons/bn_openvms_off.gif)
![[Compaq site]](../../images/buttons/bn_compaq_off.gif)
|
| Updated: 11 December 1998 |
|
|
|
|
| Updated: 11 December 1998 |
VAX MACRO and Instruction Set Reference Manual
| Previous | Contents | Index |
There are alignment, stride, address specifier context, and access mode
considerations for the vector memory access instructions.
10.10.1 Alignment Considerations
Vector memory access instructions require their vector operands to be naturally aligned in memory. Longwords must be aligned on longword boundaries. Quadwords must be aligned on quadword boundaries. If any vector element is not naturally aligned in memory, an access control violation occurs. For further details, see Section 10.6.1, Vector Memory Management Exception Handling.
The scalar operands need not be naturally aligned in memory.
10.10.2 Stride Considerations
A vector's stride is defined as the number of memory locations (bytes)
between the starting address of consecutive vector elements. A
contiguous vector that has longword elements has a stride of four; a
contiguous vector that has quadword elements has a stride of eight.
10.10.3 Context of Address Specifiers
The base address specifier used by the vector memory access
instructions is of byte context, regardless of the data type. Arrays
are addressed as byte strings. Index values in array specifiers are
multiplied by one, and the amount of autoincrement or autodecrement,
when either of these modes is used, is one.
10.10.4 Access Mode
A vector memory access instruction is executed using the access mode in
effect when the instruction is issued by the scalar processor.
10.10.5 Memory Instructions
This section describes VAX vector architecture memory instructions.
Load Memory Data into Vector Register
ArchitectureVLDL [/M[0|1]] base, stride, Vc
VLDQ [/M[0|1]] base, stride, Vc
Format
opcode cntrl.rw, base.ab, stride.rl
Opcodes
| 34FD | VLDL | Load Longword Vector from Memory to Vector Register |
| 36FD | VLDQ | Load Quadword Vector from Memory to Vector Register |
Vector Control Word
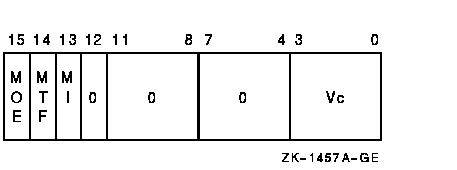
Exceptions
The source operand vector is fetched from memory and is written to vector destination register Vc. The length of the vector is specified by VLR. The virtual address of the source vector is computed using the base address and the stride. The address of element i (0 LEQU i LEQU (VLR-1)) is computed as {base+{i*stride}}. The stride can be positive, negative, or zero.In VLDL, bits <31:0> of each destination vector element receive the memory data and bits <63:32> are UNPREDICTABLE.
If any vector element operated upon is not naturally aligned in memory, a vector alignment exception occurs.
The results of VLD are unaffected by the setting of cntrl<MI>. For more details about the use of cntrl<MI>, see Section 10.3.3, Modify Intent bit.
If the addressing mode of the BASE operand is immediate, the results of the instruction are UNPREDICTABLE.
An implementation may load the elements of the vector in any order, and more than once. When a vector processor memory management exception occurs, the contents of the destination vector elements are UNPREDICTABLE.
Gather Memory Data into Vector Register
ArchitectureVGATHL [/M[0|1]] base, Vb, Vc
VGATHQ [/M[0|1]] base, Vb, Vc
Format
opcode cntrl.rw, base.ab
Opcodes
| 35FD | VGATHL | Gather Longword Vector from Memory to Vector Register |
| 37FD | VGATHQ | Gather Quadword Vector from Memory to Vector Register |
vector_control_word

Exceptions
The source operand vector is fetched from memory and is written to vector destination register Vc. The length of the vector is specified by VLR. The virtual address of the vector is computed using the base address and the 32-bit offsets in vector register Vb. The address of element i (0 LEQU i LEQU (VLR-1)) is computed as {base+Vb[i]}. The 32-bit offset can be positive, negative, or zero.In VGATHL, bits <31:0> of each destination vector element receive the memory data and bits <63:32> are UNPREDICTABLE.
If any vector element operated upon is not naturally aligned in memory, a vector alignment exception occurs.
The results of VGATH are unaffected by the setting of cntrl<MI>. For more details about the use of cntrl<MI>, see Section 10.3.3, Modify Intent bit.
If the addressing mode of the BASE operand is immediate, the results of the instruction are UNPREDICTABLE.
An implementation may load the elements of the vector in any order, and more than once. When a vector processor memory management exception occurs, the contents of the destination vector elements are UNPREDICTABLE.
If the same vector register is used as both source and destination, the result of the VGATH is UNPREDICTABLE.
Store Vector Register Data into Memory
ArchitectureVSTL [/0|1] Vc, base, stride
VSTQ [/0|1] Vc, base, stride
Format
opcode cntrl.rw, base.ab, stride.rl
Opcodes
| 9CFD | VSTL | Store Longword Vector from Vector Register to Memory |
| 9EFD | VSTQ | Store Quadword Vector from Vector Register to Memory |
vector_control_word

Exceptions
The source operand in vector register Vc is written to memory. The length of the vector is specified by the Vector Length Register (VLR). The virtual address of the destination vector is computed using the base address and the stride. The address of element i (0 LEQU i LEQU (VLR-1)) is computed as {base+{i*stride}}. The stride can be positive, negative, or zero.If any vector element operated upon is not naturally aligned in memory, a vector alignment exception occurs.
For a nonzero stride value, an implementation may store the vector elements in parallel; therefore the order in which these elements are stored is UNPREDICTABLE. Furthermore, if the nonzero stride causes result locations in memory to overlap, then the values stored in the overlapping result locations are also UNPREDICTABLE.
For a stride value of zero, the highest numbered register element destined for the single memory location becomes the final value of that location.
When a vector processor memory management exception occurs, it is UNPREDICTABLE whether the vector processor writes any result location for which an exception did not occur. If the fault condition can be eliminated by software and the instruction restarted, then the vector processor will ensure that all destination locations are written.
If the destination vector overlaps the vector instruction control word, base, or stride operand, the result of the instruction is UNPREDICTABLE.
If the addressing mode of the BASE operand is immediate, the results of the instruction are UNPREDICTABLE.
Scatter Vector Register Data into Memory
ArchitectureVSCATL [/0|1] Vc, base, Vb
VSCATQ [/0|1] Vc, base, Vb
Format
opcode cntrl.rw, base.ab
Opcodes
| 9DFD | VSCATL | Scatter Longword Vector from Vector Register to Memory |
| 9FFD | VSCATQ | Scatter Quadword Vector from Vector Register to Memory |
vector_control_word
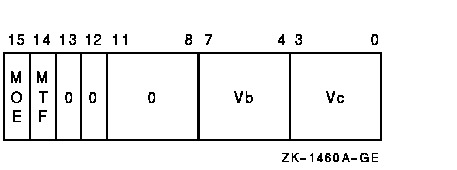
Exceptions
The source vector operand Vc is written to memory. The length of the vector is specified by the Vector Length Register (VLR) register. The virtual address of the destination vector is computed using the base address operand and the 32-bit offsets in vector register Vb. The address of element i (0 LEQU i LEQU (VLR-1)) is computed as {base+Vb[i]}. The 32-bit offset can be positive, negative, or zero.If any vector element operated upon is not naturally aligned in memory, a vector alignment exception occurs.
An implementation may store the vector elements in parallel; therefore, the order in which elements are stored to different memory locations is UNPREDICTABLE. In the case where multiple elements are destined for the same memory location, the highest numbered element among them becomes the final value of that location.
When a vector processor memory management exception occurs, it is UNPREDICTABLE whether the vector processor writes any result location for which an exception did not occur. If the fault condition can be eliminated by software and the instruction restarted, then the vector processor will ensure that all destination locations are written.
If the destination vector overlaps the vector instruction control word or base operand, the result of the instruction is UNPREDICTABLE.
If the addressing mode of the BASE operand is immediate, the results of the instruction are UNPREDICTABLE.
This section describes VAX vector architecture integer instructions.
Vector Integer Add
Architecturevector + vector:
VVADDL [/0|1] Va, Vb, Vc
scalar + vector:
VSADDL [/0|1] scalar, Vb, Vc
Format
vector + vector: opcode cntrl.rw
scalar + vector: opcode cntrl.rw, addend.rl
Opcodes
| 80FD | VVADDL | Vector Vector Add Longword |
| 81FD | VSADDL | Vector Scalar Add Longword |
vector_control_word
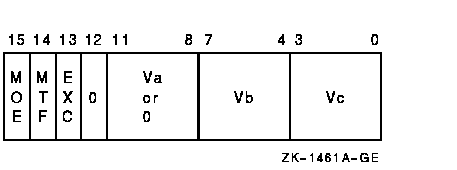
Exceptions
The scalar addend or Va operand is added, elementwise, to vector register Vb and the 32-bit sum is written to vector register Vc. Only bits <31:0> of each vector element participate in the operation. Bits <63:32> of the elements of vector register Vc are UNPREDICTABLE. The length of the vector is specified by the Vector Length Register (VLR).If integer overflow is detected and cntrl<EXC> is set, the exception type and destination register number are recorded in the Vector Arithmetic Exception Register (VAER) and the vector operation is allowed to complete. On integer overflow, the low-order 32 bits of the true result are stored in the destination element.
Vector Integer Compare
Architecturevector--vector:
{VVGTRL | VVEQLL |VVLSSL |VVLEQL|VVNEQL|VVGEQL} [/0|1] Va, Vb
scalar--vector:
{VSGTRL|VSEQLL|VSLSSL|VSLEQL|VSNEQL|VSGEQL} [/0|1] src, Vb
Format
vector--vector: opcode cntrl.rw
scalar--vector: opcode cntrl.rw, src.rl
Opcodes
| C0FD | VVCMPL | Vector Vector Compare Longword |
| C1FD | VSCMPL | Vector Scalar Compare Longword |
vector_control_word
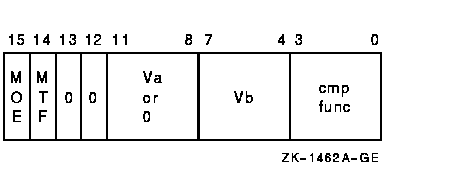
The condition being tested is determined by cntrl<2:0>, as follows:
| Value of cntrl<2:0> | Meaning |
|---|---|
| 0 | Greater than |
| 1 | Equal |
| 2 | Less than |
| 3 | Reserved 1 |
| 4 | Less than or equal |
| 5 | Not equal |
| 6 | Greater than or equal |
| 7 | Reserved 1 |
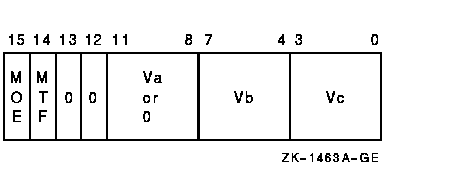
The scalar or Va operand is compared, elementwise, with vector register Vb. The length of the vector is specified by the Vector Length Register (VLR). For each element comparison, if the specified relationship is true, the Vector Mask Register bit (VMR<i>) corresponding to the vector element is set to one; otherwise, it is cleared. If cntrl<MOE> is set, VMR bits corresponding to elements that do not match cntrl<MTF> are left unchanged. VMR bits beyond the vector length are left unchanged. Only bits <31:0> of each vector element participate in the operation.
Vector Integer Multiply
Architecturevector * vector:
VVMULL [/V[0|1]] Va, Vb, Vc
scalar * vector:
VSMULL [/V[0|1]] scalar, Vb, Vc
Format
vector * vector: opcode cntrl.rw
scalar * vector: opcode cntrl.rw, mulr.rl
Opcodes
| A0FD | VVMULL | Vector Vector Multiply Longword |
| A1FD | VSMULL | Vector Scalar Multiply Longword |
vector_control_word
Exceptions
The scalar multiplier or vector operand Va is multiplied, elementwise, by vector operand Vb and the least significant 32 bits of the signed 64-bit product are written to vector register Vc. Only bits <31:0> of each vector element participate in the operation. Bits <63:32> of the elements of vector register Vc are UNPREDICTABLE. The length of the vector is specified by the Vector Length Register (VLR).If integer overflow is detected and cntrl<EXC> is set, the exception condition type and destination register number are recorded in the Vector Arithmetic Exception Register (VAER) and the vector operation is allowed to complete. On integer overflow, the low-order 32 bits of the true result are stored in the destination element.
Vector Integer Subtract
Architecturevector--vector:
VVSUBL [/V[0|1]] Va, Vb, Vc
scalar--vector:
VSSUBL [/V[0|1]] scalar, Vb, Vc
Format
vector--vector: opcode cntrl.rw
scalar--vector: opcode cntrl.rw, min.rl
Opcodes
| 88FD | VVSUBL | Vector Vector Subtract Longword |
| 89FD | VSSUBL | Vector Scalar Subtract Longword |
vector_control_word
Exceptions
The vector operand Vb is subtracted, elementwise, from the scalar minuend or vector operand Va. The 32-bit difference is written to vector register Vc. Only bits <31:0> of each vector element participate in the operation. Bits <63:32> of the elements of vector register Vc are UNPREDICTABLE. The length of the vector is specified by the Vector Length Register (VLR).If integer overflow is detected and cntrl<EXC> is set, the exception condition type and destination register number are recorded in the Vector Arithmetic Exception Register (VAER) and the vector operation is allowed to complete. On integer overflow, the low-order 32 bits of the true result are stored in the destination element.
This section describes VAX vector architecture logical and shift instructions.
Vector Logical Functions
Architecturevector op vector:
{VVBISL|VVXORL|VVBICL} [/V[0|1]] Va, Vb, Vc
vector op scalar:
{VSBISL|VSXORL|VSBICL} [/V[0|1]] scalar, Vb, Vc
Format
op vector: opcode cntrl.rw
op scalar: opcode cntrl.rw, src.rl
Opcodes
| C8FD | VVBISL | Vector Vector Bit Set Longword |
| E8FD | VVXORL | Vector Vector Exclusive-OR Longword |
| CCFD | VVBICL | Vector Vector Bit Clear Longword |
| C9FD | VSBISL | Vector Scalar Bit Set Longword |
| E9FD | VSXORL | Vector Scalar Exclusive-OR Longword |
| CDFD | VSBICL | Vector Scalar Bit Clear Longword |
vector_control_word
Exceptions
The scalar src or vector operand Va is combined, elementwise, using the specified Boolean function, with vector register Vb and the result is written to vector register Vc. Only bits <31:0> of each vector element participate in the operation. Bits <63:32> of the elements of Vb are written into bits <63:32> of the corresponding elements of Vc. The length of the vector is specified by the Vector Length Register (VLR).
Vector Shift Logical
Architecturevector shift count:
{VVSRLL|VVSLLL [/V[0|1]] Va, Vb, Vc
scalar shift count:
{VSSRLL|VSSLLL [/V[0|1]] cnt, Vb, Vc
Format
vector shift count: opcode cntrl.rw
scalar shift count: opcode cntrl.rw, cnt.rl
Opcodes
| E0FD | VVSRLL | Vector Vector Shift Right Logical Longword |
| E4FD | VVSLLL | Vector Vector Shift Left Logical Longword |
| E1FD | VSSRLL | Vector Scalar Shift Right Logical Longword |
| E5FD | VSSLLL | Vector Scalar Shift Left Logical Longword |
vector_control_word
Exceptions
Each element in vector register Vb is shifted logically left or right 0 to 31 bits as specified by a scalar count operand or vector register Va. The shifted results are written to vector register Vc. Zero bits are propagated into the vacated bit positions. Only bits <4:0> of the count operand and bits <31:0> of each Vb element participate in the operation. Bits <63:32> of the elements of vector register Vc are UNPREDICTABLE. The length of the vector is specified by the Vector Length Register (VLR).
The VAX vector architecture provides instructions for operating on F_floating, D_floating, and G_floating operand formats. The floating-point arithmetic instructions are add, subtract, compare, multiply, and divide. Data conversion instructions are provided to convert operands between D_floating, G_floating, F_floating, and longword integer.
Rounding is performed using standard VAX rounding rules. The accuracy of the vector floating-point instructions matches that of the scalar floating-point instructions. Refer to the section on floating-point instructions in the VAX Architecture Reference Manual for more information.
| Previous | Next | Contents | Index |
|
|
![[OpenVMS documentation]](../../images/openvms_doc_banner_bottom.gif) |
|
Copyright © Compaq Computer Corporation 1998. All rights reserved. Legal |
4515PRO_035.HTML
|