![[OpenVMS documentation]](../../images/openvms_doc_banner_top.gif)
|
![[Site home]](../../images/buttons/bn_site_home_off.gif)
![[Send comments]](../../images/buttons/bn_comments_off.gif)
![[Help with this site]](../../images/buttons/bn_site_help_off.gif)
![[How to order documentation]](../../images/buttons/bn_order_docs_off.gif)
![[OpenVMS site]](../../images/buttons/bn_openvms_off.gif)
![[Compaq site]](../../images/buttons/bn_compaq_off.gif)
|
| Updated: 11 December 1998 |
|
|
|
|
| Updated: 11 December 1998 |
VAX MACRO and Instruction Set Reference Manual
| Previous | Contents | Index |
All vector floating-point exception conditions occur asynchronously with respect to the scalar processor. These exception conditions do not interrupt the scalar processor. If the exception condition is enabled, then the exception condition type and destination register number are recorded in the Vector Arithmetic Exception Register (VAER), and a reserved operand in the format of the instruction's data type is written into the destination register element. Encoded in this reserved operand is the exception condition type. After recording the exception and writing the appropriate result into the destination register element, the instruction encountering the exception continues executing to completion.
If a vector convert floating to integer instruction encounters a source element that is a reserved operand, an UNPREDICTABLE result rather than a reserved operand is written into the destination register element.
Figure 10-13 shows the encoding of the reserved operand that is written for vector floating-point exceptions. Consistent with the definition of a reserved operand, the sign bit (bit <15>) is one and the exponent (bits <14:7> for F_floating and D_floating, and bits <14:4> for G_floating) is zero. When the reserved operand is written in F_floating or D_floating format, bits <6:4> are also zero. The exception condition type (ETYPE) is encoded in bits <3:0>, as shown in Table 10-16. If a reserved operand is divided by zero, both ETYPE bits may be set. The state of all other bits in the result (denoted by shading) is UNPREDICTABLE.
If the floating underflow exception condition is suppressed by cntrl<EXC>, a zero result is written to the destination register element and no further action is taken. Floating overflow, floating divide by zero, and floating reserved operand are always enabled.
Figure 10-13 Encoding of the Reserved Operand
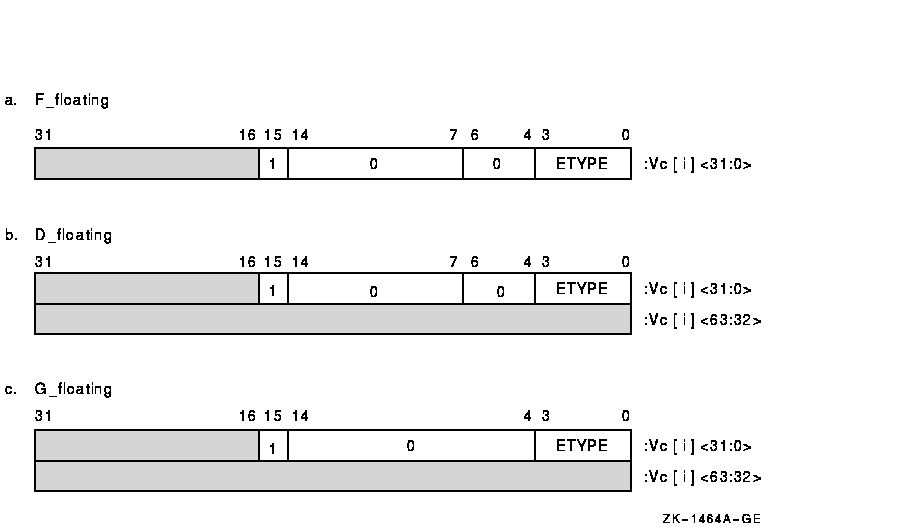
| Bit | Exception Condition Type |
|---|---|
| <0> | Floating underflow |
| <1> | Floating divide by zero |
| <2> | Floating reserved operand |
| <3> | Floating overflow |
This section describes VAX vector architecture floating-point instructions.
Vector Floating Add
Architecturevector + vector:
{VVADDF|VVADDD|VVADDG} [/U[0|1]] Va, Vb, Vc
scalar + vector:
{VSADDF|VSADDD|VSADDG [/U[0|1]] scalar, Vb, Vc
Format
vector + vector:
opcode cntrl.rw
scalar + vector (F_floating):
opcode cntrl.rw, addend.rl
scalar + vector (D_ and G_floating):
opcode cntrl.rw, addend.rq
Opcodes
| 84FD | VVADDF | Vector Vector Add F_Floating |
| 85FD | VSADDF | Vector Scalar Add F_Floating |
| 86FD | VVADDD | Vector Vector Add D_Floating |
| 87FD | VSADDD | Vector Scalar Add D_Floating |
| 82FD | VVADDG | Vector Vector Add G_Floating |
| 83FD | VSADDG | Vector Scalar Add G_Floating |
vector_control_word
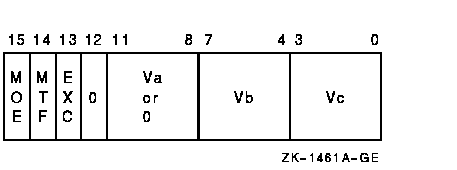
Exceptions
The source addend or vector operand Va is added, elementwise, to vector register Vb and the sum is written to vector register Vc. The length of the vector is specified by the Vector Length Register (VLR).In VxADDF, only bits <31:0> of each vector element participate in the operation. Bits <63:32> of the destination vector elements are UNPREDICTABLE.
If a floating underflow occurs when cntrl<EXC> is set or if a floating overflow or floating reserved operand occurs, an encoded reserved operand is stored as the result and the exception condition type and destination register number are recorded in the Vector Arithmetic Exception Register (VAER). The vector operation is then allowed to complete. If cntrl<EXC> is clear, zero is written to the destination element when an exponent underflow occurs and no other action is taken.
Vector Floating Compare
vector--vector:
{VVGTRF|VVGTRD|VVGTRG|VVEQLF|VVEQLD| VVEQLG|VVLSSF|VVLSSD|VVLSSG|VVLEQF|VVLEQD| VVLEQG|VVNEQF|VVNEQD|VVNEQG|VVGEQF|VVGEQD|VVGEQG} [/U[0|1]] Va, Vb
scalar--vector:
{VSGTRF|VSGTRD|VSGTRG|VSEQLF|VSEQLD| VSEQLG|VSLSSF|VSLSSD|VSLSSG|VSLEQF|VSLEQD| VSLEQG|VSNEQF|VSNEQD|VSNEQG|VSGEQF|VSGEQD|VSGEQG} [/U[0|1]] src, Vb
Architecture
Format
vector--vector:
opcode cntrl.rw
scalar--vector (F_floating):
opcode cntrl.rw, src.rl
scalar--vector (D_ and G_floating):
opcode cntrl.rw, src.rq
Opcodes
| C4FD | VVCMPF | Vector Vector Compare F_floating |
| C5FD | VSCMPF | Vector Scalar Compare F_floating |
| C6FD | VVCMPD | Vector Vector Compare D_floating |
| C7FD | VSCMPD | Vector Scalar Compare D_floating |
| C2FD | VVCMPG | Vector Vector Compare G_floating |
| C3FD | VSCMPG | Vector Scalar Compare G_floating |
vector_control_word
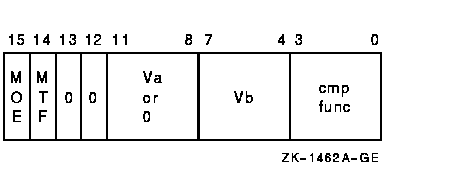
The condition being tested is determined by cntrl<2:0>, as follows:
| Value of cntrl<2:0> | Meaning |
|---|---|
| 0 | Greater than |
| 1 | Equal |
| 2 | Less than |
| 3 | Reserved 1 |
| 4 | Less than or equal |
| 5 | Not equal |
| 6 | Greater than or equal |
| 7 | Reserved 1 |
Cntrl<3> should be zero; if it is set, the results of the instruction are UNPREDICTABLE. |
Exceptions
The scalar or vector operand Va is compared, elementwise, with vector register Vb. The length of the vector is specified by the Vector Length Register (VLR). For each element comparison, if the specified relationship is true, the Vector Mask Register bit (VMR<i>) corresponding to the vector element is set to one, otherwise it is cleared. If cntrl<MOE> is set, VMR bits corresponding to elements that do not match cntrl<MTF> are left unchanged. VMR bits beyond the vector length are left unchanged. If an element being compared is a reserved operand, VMR<i> is UNPREDICTABLE. In VxCMPF, only bits <31:0> of each vector element participate in the operation.If a floating reserved operand exception occurs, the exception condition type is recorded in the Vector Arithmetic Exception Register (VAER) and the vector operation is allowed to complete.
Note that for this instruction, no bits are set in the VAER destination register mask when an exception occurs.
Vector Convert
Architecture
{VVCVTLF|VVCVTLD|VVCVTLG|VVCVTFL|VVCVTRFL| VVCVTFD|VVCVTFG|VVCVTDL|VVCVTDF| VVCVTRDL|VVCVTGL|VVCVTGF|VVCVTRGL} [/U[0|1]] Vb, Vc
Format
opcode cntrl.rw
Opcodes
| ECFD | VVCVT | Vector Convert |
vector_control_word
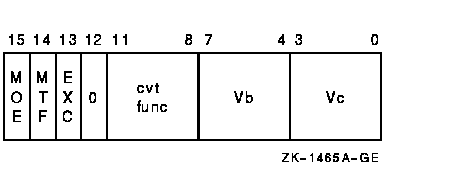
Cntrl<11:8> specifies the conversion to be performed, as follows:
| cntrl<11:8> | Meaning |
|---|---|
| 1 1 1 1 | CVTRGL (Convert Rounded G_Floating to Longword) |
| 1 1 1 0 | Reserved 1 |
| 1 1 0 1 | CVTGF (Convert Rounded G_Floating to F_Floating) |
| 1 1 0 0 | CVTGL (Convert Truncated G_Floating to Longword) |
| 1 0 1 1 | Reserved 1 |
| 1 0 1 0 | CVTRD (Convert Rounded D_Floating to Longword) |
| 1 0 0 1 | CVTDF (Convert Rounded D_Floating to F_Floating) |
| 1 0 0 0 | CVTDL (Convert Truncated D_Floating to Longword) |
| 0 1 1 1 | CVTFG (Convert F_Floating to G_Floating (exact)) |
| 0 1 1 0 | CVTFD (Convert F_Floating to D_Floating (exact)) |
| 0 1 0 1 | CVTRF (Convert Rounded F_Floating to Longword) |
| 0 1 0 0 | CVTFL (Convert Truncated F_Floating to Longword) |
| 0 0 1 1 | CVTLG (Convert Longword to G_Floating (exact)) |
| 0 0 1 0 | CVTLD (Convert Longword to D_Floating (exact)) |
| 0 0 0 1 | CVTLF (Convert Rounded Longword to F_Floating) |
| 0 0 0 0 | Reserved 1 |
Exceptions
The vector elements in vector register Vb are converted and results are written to vector register Vc. Cntrl<11:8> specifies the conversion to be performed. The length of the vector is specified by the Vector Length Register (VLR). Bits <63:32> of Vc are UNPREDICTABLE for instructions that convert from D_floating or G_floating to F_floating or longword. When CVTRGL, CVTRDL, and CVTRFL round, the rounding is done in sign magnitude, before conversion to two's complement.If an integer overflow occurs when cntrl<EXC> is set, the low-order 32 bits of the true result are written to the destination element as the result, and the exception condition type and destination register number are recorded in the Vector Arithmetic Exception Register (VAER). The vector operation is then allowed to complete. If integer overflow occurs when cntrl<EXC> is clear, the low-order 32 bits of the true result are written to the destination element, and no other action is taken.
For vector convert floating to integer, where the source element is a reserved operand, the value written to the destination element is UNPREDICTABLE. In addition, the exception type and destination register number are recorded in the VAER. The vector operation is then allowed to complete.
For vector convert floating to floating instructions, if floating underflow occurs when cntrl<EXC> is clear, zero is written to the destination element, and no other action is taken. The vector operation is then allowed to complete.
For vector convert floating to floating instructions, if floating underflow occurs with cntrl<EXC> set or if a floating overflow or reserved operand occurs, an encoded reserved operand is written to the destination element, and the exception condition type and destination register number are recorded in the VAER. The vector operation is then allowed to complete.
Vector Floating Divide
Architecturevector/vector:
{VVDIVF|VVDIVD|VVDIVG} [/U[0|1]] Va, Vb, Vc
scalar/vector:
{VSDIVF|VSDIVD|VSDIVG} [/U[0|1]] scalar, Vb, Vc
Format
vector/vector:
opcode cntrl.rw
scalar/vector (F_floating):
opcode cntrl.rw, divd.rl
scalar/vector (D_ and G_floating):
opcode cntrl.rw, divd.rq
Opcodes
| ACFD | VVDIVF | Vector Vector Divide F_floating |
| ADFD | VSDIVF | Vector Scalar Divide F_floating |
| AEFD | VVDIVD | Vector Vector Divide D_floating |
| AFFD | VSDIVD | Vector Scalar Divide D_floating |
| AAFD | VVDIVG | Vector Vector Divide G_floating |
| ABFD | VSDIVG | Vector Scalar Divide G_floating |
vector_control_word
Exceptions
The scalar dividend or vector register Va is divided, elementwise, by the divisor in vector register Vb and the quotient is written to vector register Vc. The length of the vector is specified by the Vector Length Register (VLR).In VxDIVF, only bits <31:0> of each vector element participate in the operation; bits <63:32> of the destination vector elements are UNPREDICTABLE.
If a floating underflow occurs when cntrl<EXC> is set or if a floating overflow, divide by zero, or reserved operand occurs, an encoded reserved operand is stored as the result and the exception condition type and destination register number are recorded in the Vector Arithmetic Exception Register (VAER). The vector operation is then allowed to complete. If cntrl<EXC> is clear, zero is written to the destination element when an exponent underflow occurs and no other action is taken.
Vector Floating Multiply
Architecturevector * vector:
{VVMULF|VVMULD|VVMULG} [/U[0|1]] Va, Vb, Vc
scalar * vector:
{VSMULF|VSMULD|VSMULG} [/U[0|1]] scalar, Vb, Vc
Format
vector * vector:
opcode cntrl.rw
scalar * vector (F_floating):
opcode cntrl.rw, mulr.rl
scalar * vector (D_ and G_floating):
opcode cntrl.rw, mulr.rq
Opcodes
| A4FD | VVMULF | Vector Vector Multiply F_floating |
| A5FD | VSMULF | Vector Scalar Multiply F_floating |
| A6FD | VVMULD | Vector Vector Multiply F_floating |
| A7FD | VSMULD | Vector Scalar Multiply D_floating |
| A2FD | VVMULG | Vector Vector Multiply G_floating |
| A3FD | VSMULG | Vector Scalar Multiply G_floating |
vector_control_word
Exceptions
The multiplicand in vector register Vb is multiplied, elementwise, by the scalar multiplier or vector operand Va and the product is written to vector register Vc. The length of the vector is specified by the Vector Length Register (VLR).In VxMULF, only bits <31:0> of each vector element participate in the operation. Bits <63:32> of the destination vector elements are UNPREDICTABLE.
If a floating underflow occurs when cntrl<EXC> is set or if a floating overflow or reserved operand occurs, an encoded reserved operand is stored as the result and the exception condition type and destination register number are recorded in the Vector Arithmetic Exception Register (VAER). The vector operation is then allowed to complete. If cntrl<EXC> is clear, zero is written to the destination element when an exponent underflow occurs and no other action is taken.
Vector Floating Subtract
Architecturevector--vector:
{VVSUBF|VVSUBD|VVSUBG} [/U[0|1]] Va, Vb, Vc
scalar--vector:
{VSSUBF|VSSUBD|VSSUBG} [/U[0|1]] scalar, Vb, Vc
Format
vector--vector:
opcode cntrl.rw
scalar--vector (F_floating):
opcode cntrl.rw, min.rl
scalar--vector (D_ and G_floating):
opcode cntrl.rw, min.rq
Opcodes
| 8CFD | VVSUBF | Vector Vector Subtract F_floating |
| 8DFD | VSSUBF | Vector Scalar Subtract F_floating |
| 8EFD | VVSUBD | Vector Vector Subtract D_floating |
| 8FFD | VSSUBD | Vector Scalar Subtract D_floating |
| 8AFD | VVSUBG | Vector Vector Subtract G_floating |
| 8BFD | VSSUBG | Vector Scalar Subtract G_floating |
vector_control_word
Exceptions
Vector register Vb is subtracted, elementwise, from the scalar minuend or vector register Va and the difference is written to vector register Vc. The length of the vector is specified by the Vector Length Register (VLR).In VxSUBF, only bits <31:0> of each vector element participate in the operation; bits <63:32> of the destination vector elements are UNPREDICTABLE.
If a floating underflow occurs when cntrl<EXC> is set or if a floating overflow or reserved operand occurs, an encoded reserved operand is stored as the result and the exception condition type and destination register number are recorded in the Vector Arithmetic Exception Register (VAER). The vector operation is then allowed to complete. If cntrl<EXC> is clear, zero is written to the destination element when an exponent underflow occurs and no other action is taken.
This section describes VAX vector architecture edit instructions.
Vector Merge
Architecturevector vector merge:
VVMERGE [/0|1] Va, Vb, Vc
vector scalar merge:
VSMERGE|VSMERGEF|VSMERGED|VSMERGEG} [/0|1] src, Vb, Vc
Format
vector-vector: opcode cntrl.rw
vector-scalar: opcode cntrl.rw,src.rq
Opcodes
| EEFD | VVMERGE | Vector Vector Merge |
| EFFD | VSMERGE | Vector Scalar Merge |
vector_control_word
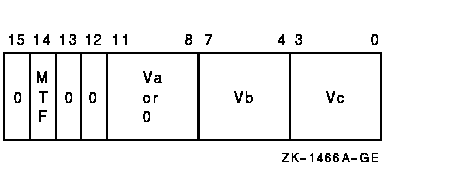
Exceptions
The scalar src or vector operand Va is merged, elementwise, with vector register Vb and the resulting vector is written to vector register Vc. The length of the vector operation is specified by the Vector Length Register (VLR).For each vector element, i, if the corresponding Vector Mask Register bit (VMR<i>) matches cntrl<MTF>, src or Va[i] is written to the destination vector element Vc[i]. If VMR<i> does not match cntrl<MTF>, Vb[i] is written to the destination vector element.
| Previous | Next | Contents | Index |
|
|
![[OpenVMS documentation]](../../images/openvms_doc_banner_bottom.gif) |
|
Copyright © Compaq Computer Corporation 1998. All rights reserved. Legal |
4515PRO_036.HTML
|