| 前へ | 次へ | 目次 | 索引 |
表 8-3 は,HP が可用性を強化するために提供しているさまざまな関連 OpenVMS Cluster ソフトウェア製品です。
| 製品 | 説明 |
|---|---|
| Availability Manager | 複数ノードのデータを同時に収集,解析し,すべての出力を一元された DECwindows 表示に送信します。解析時に可用性の問題を検出し,対処方法を提示します。 |
| RTR | 分散環境においてスケーラビリティと位置透過性を備えた連続的で耐障害性のあるトランザクション転送サービスを提供します。実行中のトランザクションは 2 フェーズのコミット・プロトコルにより保証され,データベースは全体に分配することが可能であるとともに,性能の改善のために分割することができます。 |
| Volume Shadowing for OpenVMS | OpenVMS Cluster システム上の任意のディスクを,そのOpenVMS Cluster システム内にある他の同じサイズ (同じ物理ブロック数) のディスクとで冗長構成にします。 |
8.3 高い可用性を備えた OpenVMS Cluster 構成の実現手法
選択するハードウェアとその構成方法は, OpenVMS Cluster システムの可用性に重要な影響があります。この節では,可用性強化を目的とした OpenVMS Cluster 構成設計の基本手法を説明します。
8.3.1 可用性の強化手法
表 8-4 は,高可用性 OpenVMS Cluster の構成方法をまとめたものです。これらの方法は,重要度の高い順に並んでいます。以下の方法のうち多くは,この章で紹介する最適構成の例で取り上げています。
| 強化手法 | 説明 |
|---|---|
| 単一点障害 (Single point of failure (単一機器の障害がシステム全体の障害になる))の要因を排除 | 構成要素に冗長性を与え,ある構成要素に障害が発生しても他の構成要素で対応します。 |
| システム・ディスクのシャドウ化 | システム・ディスクは,ノード操作にきわめて重要です。Volume Shadowing for OpenVMS で,システム・ディスクを冗長化できます。 |
| 基本データ・ディスクのシャドウ化 | Volume Shadowing for OpenVMS でデータ・ディスクを冗長化してデータの可用性を強化します。 |
| ストレージ領域までの共用直接アクセスを提供 | 可能な場合,すべてのノードにストレージ領域の共用直接アクセスを与えます。これにより,ストレージ領域へのアクセス時に MSCP サーバ・ノードに対する依存度を緩和できます。 |
| 環境上のリスクを最小化 | 以下の手順により,環境上の問題のリスクを最小限に抑えます。
|
| 最低 3 ノードを構成 | OpenVMS Cluster ノードには,操作を続行するための定足数が定められています。最適構成では,最低 3 ノードを使用し,どれか 1 ノードが使用できなくなっても,残り 2 ノードで定足数を満たして処理を続行します。
関連項目: 定足数の実現手法の詳細については, 第 11.5 節 と『OpenVMS Cluster システム』を参照してください。 |
| 予備キャパシティを構成 | 構成要素ごとに,キャパシティの処理に必要な数に加え,少なくとも 1 つは予備の構成要素を構成します。構成要素の使用パーセンテージは,キャパシティの 80% 未満になるようにします。重要な構成要素については,リソースの使用パーセンテージがキャパシティの 80% を 十分に下まわるように構成します。これは構成要素のどれかに障害が発生しても残りの構成要素に余裕をもって作業負荷を分散するためです。 |
| 予備構成要素をスタンバイ | 構成要素ごとに,予備構成要素を 1 つまたは 2 つ用意しておき,構成要素の障害発生に備えます。予備構成要素は定期的にチェックして正しく機能するか確認します。予備構成要素を 1 つまたは 2 つを超えて用意しても複雑になるだけでなく,必要なときに予備構成要素が正しく機能しなくなる可能性も高くなります。 |
| 共通環境ノードの使用 | 似たようなサイズ,パフォーマンスのノードを構成してフェールオーバ時のキャパシティの過剰負荷を避けます。サイズの大きなノードに障害が発生すると,サイズの小さいノードでは転化された負荷に対応できないことがあります。それによるボトルネックで OpenVMS Cluster のパフォーマンスが低下することがあります。 |
| 信頼性の高いハードウェアを使用 | ハードウェア・デバイスの障害の可能性を考慮します。MTBF (平均故障間隔) に関する製品の記述を確認してください。一般に,テクノロジが新しいほど信頼性が高くなります。 |
8.4 高い可用性を備えた OpenVMS Cluster の保守
可用性の強化プロセスは現在進行中です。OpenVMS Cluster システムの管理方法は,その構成方法と同様に重要です。この節では,OpenVMS Cluster 構成の可用性の保守の方法を紹介します。
8.4.1 可用性の保守の手法
初期構成のセットアップ後, 表 8-5 の方法に従って,OpenVMS Cluster システムの可用性を保守します。
| 方法 | 説明 |
|---|---|
| フェールオーバ方法の計画 | OpenVMS Cluster システムでは,ハードウェア構成要素間のフェールオーバをソフトウェア・サポートします。どのようなフェールオーバ機能があり,またニーズに応じたカスタマイズができるのはどれなのか,よく確認してください。障害時に回復すべき構成要素はどれか,また,フェールオーバで生じた余分な作業負荷に構成要素が対応できるか確認します。
関連項目: 表 8-2 は,OpenVMS Cluster フェールオーバ機能と,それによる回復レベルをまとめたものです。 |
| 分散アプリケーションのコーディング | OpenVMS Cluster システムの複数のノードでアプリケーションを同時に実行できるようコーディングします。ノードに障害が発生しても,OpenVMS Cluster システムの残ったメンバは利用でき,ディスク,テープ,プリンタ,その他必要な周辺機器のアクセスを維持します。 |
| 変更を最小限にする | 実行中のノードに対するハードウェアやソフトウェアの変更は,実装する前に,その必要性をよく検討してください。変更する場合は,生産環境で実施する前に,重要度の低い環境でテストします。 |
| サイズと複雑さを抑制 | 冗長性を実現できたら,構成の要素数と複雑さを抑制してください。構成が簡潔であれば,ハードウェアやソフトウェアによるエラーだけでなく,ユーザやオペレータによるエラーも減ります。 |
| 全ノードに同一ポーリング・タイマを設定 | OpenVMS Cluster システムの維持管理に使用するポーリング・タイマは,決められたシステム・パラメータで制御します。これらのシステム・パラメータの値は,すべての OpenVMS Cluster メンバ・ノードで同じ値に設定してください。
関連項目: これらのシステム・パラメータの詳細については,『OpenVMS Cluster システム』を参照してください。 |
| 管理のための事前対策 | システム管理者の熟練度は高いほど適しています。アクセス権限はそれを必要とするユーザやオペレータだけに設定してください。 OpenVMS Cluster システムの管理とセキュリティ保持のポリシーは厳密に定義してください。 |
| AUTOGEN の有効活用 | 通常の AUTOGEN フィードバックでは,システム・パラメータの設定に影響を与えるリソースの使用法が解析できます。 |
| 単独サーバやディスクに対する依存度の抑制 | 複数のシステムやディスクにデータを分散すれば,システムやディスクによる単一点障害を防げます。 |
| バックアップ・ストラテジの実装 | 定期的に,そして頻繁にバックアップを実行すれば,障害後にデータを確実に回復できます。この表にある方法のどれも確実なバックアップにはなりません。 |
8.5 LAN OpenVMS Cluster における可用性
図 8-1 は,スモール・キャパシティで可用性の高い LAN OpenVMS Cluster システムの最適な構成です。 図 8-1 の後の項で,以下の構成を検討します。
図 8-1 LAN OpenVMS Cluster システム
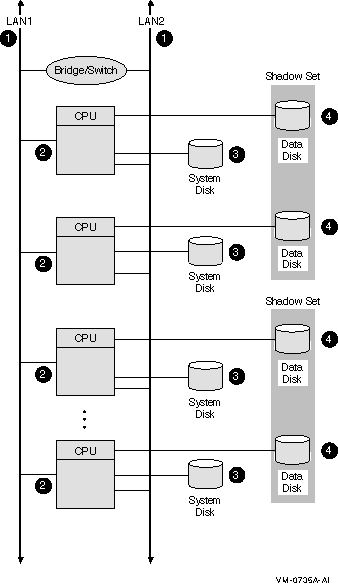
8.5.1 構成要素
図 8-1 に示す LAN OpenVMS Cluster 構成の構成要素は以下のとおりです。
| 構成要素 | 説明 |
|---|---|
| 1 | 2 本の Ethernet インターコネクト。ネットワーク・キャパシティを強化するには, Ethernet ではなく FDDI インターコネクトを使用します。
解説: 冗長化のためには,最低 2 本の LAN インターコネクトを使用し,全ノードを全 LAN インターコネクトに接続します。 インターコネクトが 1 本だけでは,単一点障害 (Single point of failure (単一機器の障害がシステム全体の障害になる)) の要因になります。 |
| 2 | 3 個から 8 個の Ethernet 対応の OpenVMS ノード
各ノードには,別のディスクに依存しないよう専用のシステム・ディスクが備えられます。 解説: 少なくとも 3 個のノードを使用し,定足数を維持します。 8 つのシステム・ディスクを管理するのは大変なので,ノード数は 8 個未満にしてください。 代替法 1: サテライト・ノードが必要な場合は,1 個または 2 個のノードをブート・サーバとして構成します。ただし,サテライト・ノードの可用性は,サーバ・ノードの可用性に依存します。 代替法 2: 第 8.10 節 にあるように,8 ノードを超える場合,LAN OpenVMS Cluster 構成を使用します。 |
| 3 | システム・ディスク
ブート順序の制約上,システム・ディスクは,通常は LAN OpenVMS Clusterではシャドウイングしません。 代替法 1: 2 つのローカル・コントローラ間でシステム・ディスクをシャドウイングします。 代替法 2: 2 個のノード間でシステム・ディスクをシャドウイングします。2 番めのノードでは,ディスクは非システム・ディスクとしてマウントされます。 関連項目: ブート順序とサテライトの依存内容については, 第 11.2.4 項 を参照してください。 |
| 4 | 重要データ・ディスク
すべての重要データ・ディスクには,ボリューム・シャドウイングでコピーを複数作成しておきます。シャドウ・セット・メンバは,少なくとも 2 個のノードに配置して,単一点障害の要因にならないようにします。 |
この構成には,以下のような長所があります。
この構成には,以下のような短所があります。
図 8-1 の構成では,以下の手法により可用性を強化しています。
高い可用性を備えたマルチ LAN クラスタを構成するには,以下のガイドラインに従ってください。
関連項目: 拡張 LAN (ELAN) の詳細については, 第 10.7.7 項 を参照してください。
8.6.1 MOP サーバの選択
マルチ LAN アダプタとマルチ LAN セグメントを併用するときは,MOP サービスを提供する LAN セグメントまでの接続を分散してください。分散することで,ネットワーク構成要素に障害が発生しても,MOP サーバからサテライトにダウンライン・ロードをすることができます。
サテライトをブートするためのダウンライン・ロードをサポートするには,VAX ノードと Alpha ノードに十分なキャパシティの MOP サーバが必要です。ネットワーク上で,各 MOP サーバに適した LAN 接続 (必要に応じて Alpha または VAX) を選択すれば,ネットワーク障害が発生しても MOP サービスを続行できます。
8.6.2 2 つの LAN セグメントの構成
図 8-2 は,異なる 2 つの LAN セグメントに接続した OpenVMS Cluster システムの構成例です。この構成には,Alpha ノードと VAX ノード,サテライト,2 個のブリッジがあります。
図 8-2 2 LAN セグメントの OpenVMS Cluster構成
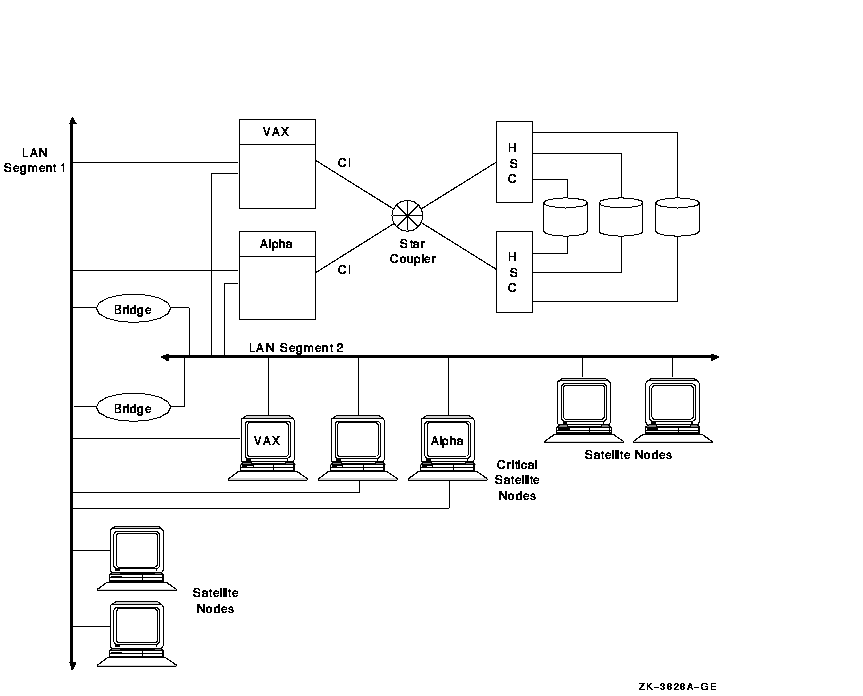
この図では,以下の点に着目してください。
| 前へ | 次へ | 目次 | 索引 |